分布式一致性解决方案产生背景
1、集中式服务
2、分布式系统
3、扩展模式:横向扩展 纵向扩展 去IOE 摩尔定律
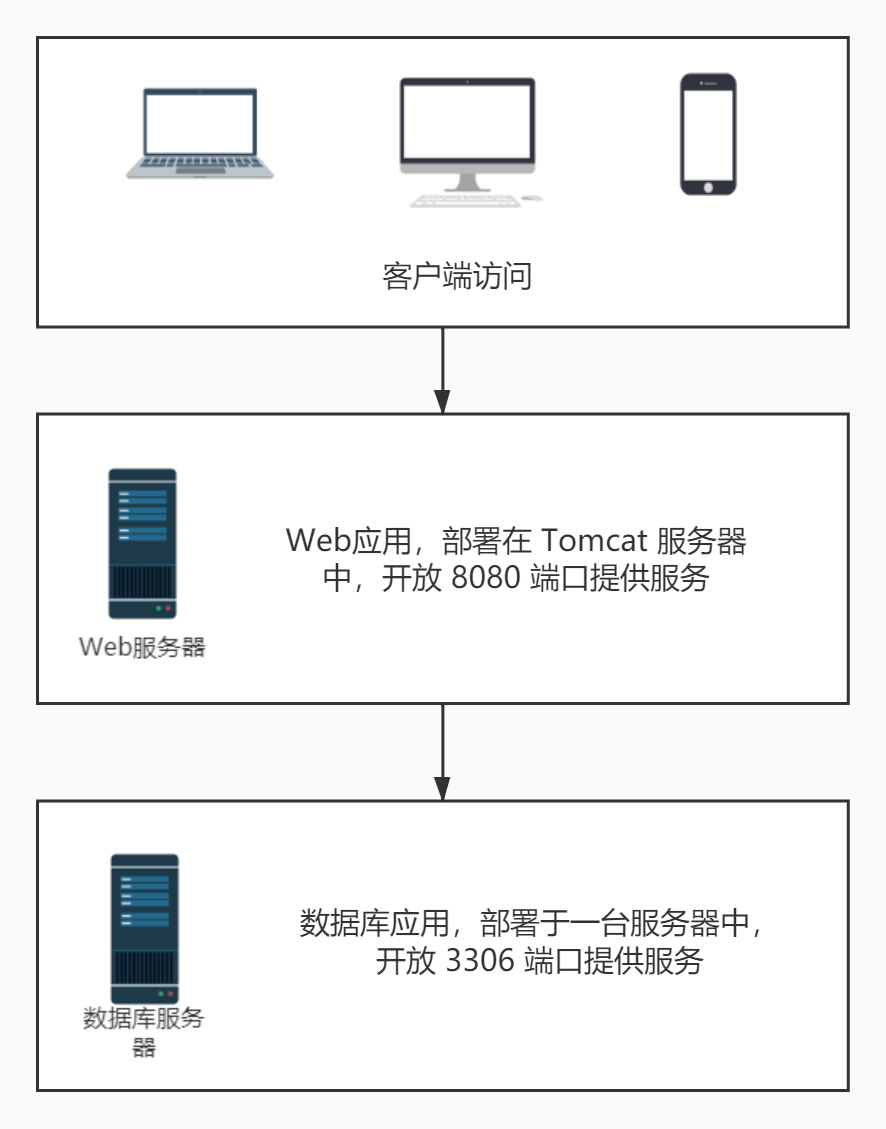
4.1. 集中式服务
一台服务器搞定所有事情:mysql + tomcat
所谓集中式系统就是指由一台或多台主计算机组成中心节点,数据集中存储于这个中心节点中,并且整个系统的所有业务单元都集中部署在这个中心节点上,系统所有的功能均由其集中处理。也就是说,集中式系统中,每个终端或客户端及其仅仅负责数据的录入和输出,而数据的存储与控制处理完全交由主机来完成。
集中式服务优点:
1、结构简单 2、部署简单 3、项目架构简单
集中式服务缺点:
1、大型主机的研发人才和维护人才培养成本非常高
2、大型主机非常昂贵
3、单点故障问题,主机一挂,所有服务终止
4、大型主机的性能扩展受限于摩尔定律
补充一下摩尔定律:
摩尔定律是由英特尔(Intel)创始人之一戈登·摩尔(Gordon Moore)提出来的。其内容为:当价格不变时,集成电路上可容纳的元器件的数目,约每隔18-24个月便会增加一倍,性能也将提升一倍。换言之,每一美元所能买到的电脑性能,将每隔18-24个月翻一倍以上。
摩尔定律告诉我们:纵向扩展理论上是受限,所以只能考虑横向扩展,而且理论上来说,横向扩展理论上不受限!
纵向扩展:提升服务器性能,上限的
横向扩展:提升服务器数量(分布式)简单说:一台高性能机器搞定所有事情!集中式架构的主机就是战斗力为 1亿 的浩克!
4.2. 发展趣事
不得不提阿里巴巴发起的 "去IOE" 运动(IOE 指的是 IBM 小型机、Oracle 数据库、EMC 的高端存储)。为什么要去IOE?
1、企业成本越来越高,升级单机处理能力的性价比越来越低
2、单机处理能力存在瓶颈
3、稳定性和可用性这两个指标很难达到
既然硬件的扩展不可靠,就只能靠软件来做!所以各种分布式系统大为流行!
"去IOE" 是一个在中国IT行业内广为人知的概念,它最初由阿里巴巴提出并推广,旨在减少对中国企业特别是互联网公司在IT基础设施方面对外部技术(尤其是美国技术)的依赖。这里的IOE指的是IBM的小型机(用于关键业务应用)、Oracle数据库(用于数据管理和处理)以及EMC的高端存储设备(用于数据存储)。这些技术产品长期以来被认为是高质量和可靠的代名词,并在很多企业的数据中心占据主导地位。
去IOE运动的背后有几个主要的原因:
成本考虑:使用IBM小型机、Oracle数据库和EMC存储等高端设备需要支付高昂的采购费用、维护费用及服务费用。而通过采用开放架构和开源软件,企业可以大大降低IT基础设施的成本。
技术自主性:过度依赖国外的技术供应商可能会限制公司的技术选择和发展空间。去IOE有助于推动企业向更加开放的技术架构转型,从而提高自身的研发能力和技术自主性。
安全性与可控性:随着云计算和大数据的发展,对于数据安全和隐私保护的要求越来越高。使用国产化的软硬件可以更好地控制数据的安全风险,并符合国家关于信息安全的相关法律法规要求。
促进本土产业发展:支持国内自主研发的IT产品和服务,有助于推动中国本土IT产业的发展,形成具有竞争力的生态系统。
灵活性与扩展性:传统的IOE架构可能在面对快速变化的市场需求时显得不够灵活。而基于X86服务器、开源数据库、分布式存储等技术构建的新一代IT架构,能够提供更好的弹性伸缩能力,以适应不断增长的数据量和计算需求。
总之,去IOE不仅是为了降低成本,更是为了实现技术上的独立自主,增强企业的竞争力,同时也有利于推动整个IT行业的创新和发展。
4.3. 分布式服务
在《分布式系统概念与设计》注 一书中,对分布式系统做了如下定义:分布式系统是一个硬件或软件组件分布在不同的网络计算机上,彼此之间仅仅通过消息传递进行通信和协调的系统。
简单来说就是一群独立计算机集合共同对外提供服务,但是对于普通的用户来说,就像是一台计算机在提供服务一样。
1、由多台服务器组成
2、肯定是用来解决单台服务器解决不了的复杂需求。
集群:
1、业务集群:nginx + tomcat 请求多,单台服务器的并发不够,所以需要增加服务器来均摊巨量的请求处理压力,但是每个请求的处理其实不复杂。
2、架构集群:无论如何,给多长时间,单台服务器都没法在有限时间内解决。只有多台服务器联合解决才能实现
一个皇帝管理国家做不到 ---> 实行郡县制,管理省部级官员即可
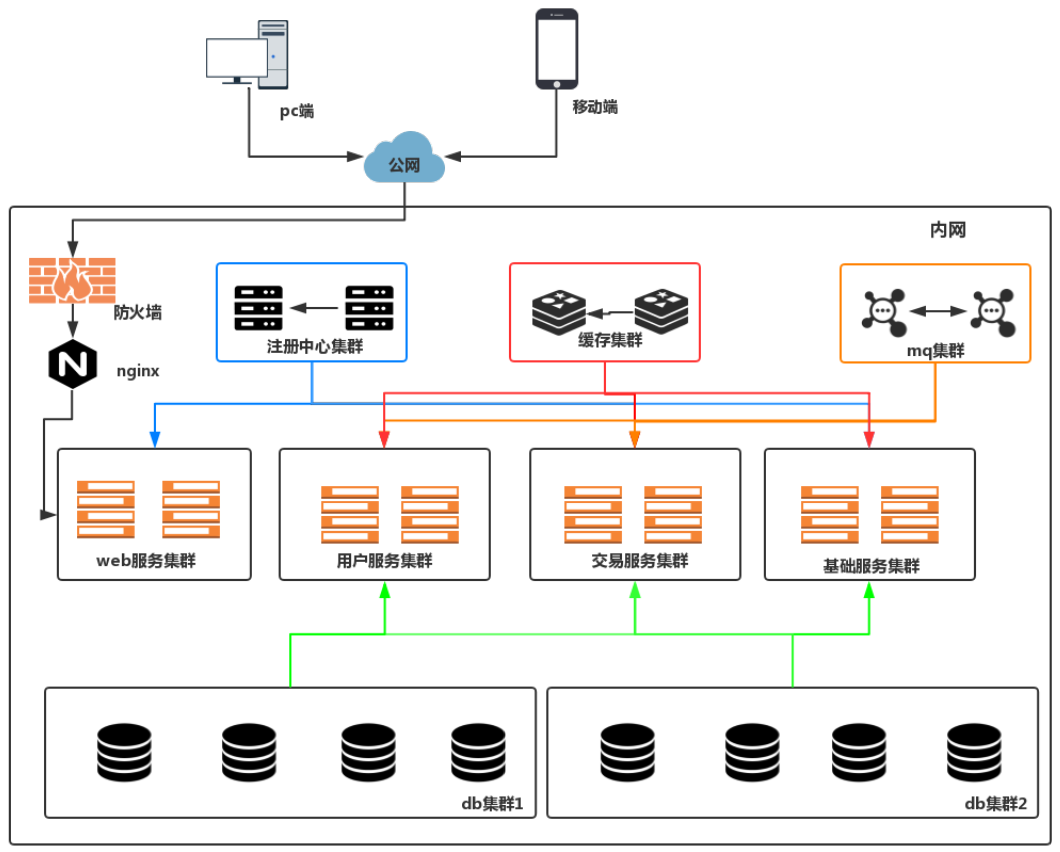
3、内部必然会有联系, 从而达成处理事情的一致性分布式意味着可以采用更多的普通计算机(相对于昂贵的大型机)组成分布式集群对外提供服务。计算机越多,CPU、内存、存储资源等也就越多,能够处理的并发访问量也就越大。
一个由分布式系统实现的电子商城,在功能上可能被拆分成多个应用,分别提供不同的功能,组成一个分布式系统对外提供服务。而系统内的各个子系统之间通过网络进行通信和协调,如异步消息或者 RPC/HTTP 请求调用等。
所以,分布式系统中的计算机在空间上几乎没有任何限制,这些计算机可能被放在不同的机柜上,也可能被部署在不同的机房中,还可能在不同的城市中,对于大型的网站甚至可能分布在不同的国家和地区
分布式系统的特点:
分布性:分布式系统中的多台计算机都会在空间上随意分布,同时,它们的分布情况也会随时变动
对等性:集群中的每个工作节点的角色是一样的。注意副本这个概念
并发性:多个机器可能同时操作一个数据库或者存储系统,可能引发数据不一致的问题(串行,并行,并发)
缺乏全局时钟:分布式系统中的多个主机上的事件的先后顺序很难界定(分布式场景中最复杂的一个问题之一)
故障总发生(服务器宕机,网络拥堵和延迟):组成分布式系统的所有计算机,都有可能发生任何形式的故障。先注意两个概念的区别:
传统集群:大量兄弟组成团队,大家做一样的事,只是这些事的数量比较大
分布式:大量兄弟组成团队,每个成员完成其中的一部分,大家做的是不同的事情。和集中式系统相比,分布式系统的性价比更高、处理能力更强、可靠性更高、也有很好的扩展性。
但是,分布式在解决了网站的高并发问题的同时也带来了一些其他问题。
首先,分布式的必要条件就是网络,这可能对性能甚至服务能力造成一定的影响。其次,一个集群中的服务器数量越多,服务器宕机的概率也就越大。
另外,由于服务在集群中分布式部署,用户的请求只会落到其中一台机器上,所以,一旦处理不好就很 容易产生数据一致性问题。
简单说:分布式集群发挥人多力量的优势,分布式集群就是一个每个兵的战斗力都为 10000 但是有 10000 个兵的军队!
4.4. 分布式系统常见异常问题
1、通信异常:网络不可用(消息延迟或者丢失),会导致分布式系统内部无法顺利进行一次网络通信,所以可能造成多节点数据丢失和状态不一致,还有可能造成数据乱序。解决方案:重试机制
2、网络分区:网络不连通,但各个子网络的内部网络是正常的,从而导致整个系统的网络环境被切分成了若干个孤立的区域,分布式系统就会出现局部小集群造成数据不一致。解决方案:把数据状态不是最新的给下线掉
3、节点故障/机器宕机:服务器节点出现的宕机或"僵死"现象,这是常态,而不是异常。解决方案:数据副本,异步复制
4、分布式三态:即成功、失败和超时,分布式环境中的网络通信请求发送和结果响应都有可能丢失,所以请求发起方无法确定消息是否处理成功。分布式系统的可用性:在用户能忍受的时间范围内,一定给出响应!
5、存储数据丢失:对于有状态节点来说,数据丢失意味着状态丢失,通常只能从其他节点读取、恢复存储的状态。解决方案:副本协议
补充:
异常处理原则:被大量工程实践所检验过的异常处理黄金原则是:任何在设计阶段考虑到的异常情况一定会在系统实际运行中发生,但在系统实际运行遇到的异常却很有可能在设计时未能考虑,所以,除非需求指标允许,在系统设计时不能放过任何异常情况。4.5. 衡量分布式系统的性能指标
1、性能:下面三个性能指标往往会相互制约,追求高吞吐的系统,往往很难做到低延迟;系统平均响应时间较长时,也很难提高QPS。(并行,串行,并发)
系统的吞吐能力,指系统在某一时间可以处理的数据/请求总量,通常可以用系统每秒处理的总数据/总请求量来衡量;
系统的响应延迟,指系统完成某一功能需要使用的时间;
系统的并发能力,指系统可以同时完成某一功能的能力,通常也用QPS(query per second)来衡量。2、可用性:系统的可用性(availability)指系统在面对各种异常时可以正确提供服务的能力。系统的可用性可以用系统停服务的时间与正常服务的时间的比例来衡量,也可以用某功能的失败次数与成功次数的比例来衡量。可用性是分布式的重要指标,衡量了系统的鲁棒性,是系统容错能力的体现。(5个9的可靠性:一年只有5分钟的宕机时间!6个9的可靠性,也就是31秒)99.999%
3、可扩展性:系统的可扩展性(scalability)指分布式系统通过扩展集群机器规模 提高 系统性能(吞吐、延迟、并发)、存储容量、计算能力的特性。好的分布式系统总在追求 “线性扩展性”,也就是使得系统的某一指标可以随着集群中的机器数量线性增长。最期望的情况:动态热部署
4、一致性:分布式系统为了提高可用性,总是不可避免的使用副本的机制,从而引发副本一致性的问题。越是强的一致性的模型,对于用户使用来说使用起来越简单。
总结一下:
串行:只有一个线程,所有的请求,都由着一个线程排队执行
并发:现在有多个线程,但是使用到了临界资源,同时只能有一个线程拿到这个资源在执行
并行:分布式系统,总结来说,就是并行系统!分布式并发!同步 和 异步, 阻塞 和 非阻塞4.6. 一致性理解
1、强一致性 :写操作完成之后,读操作一定能读到最新数据。在分布式场景中,很难实现,后续的 Paxos 算法,Quorum 机制,ZAB 协议等能实现!
2、弱一致性 :不承诺立即可以读到写入的值,也不承诺多久之后数据能够达到一致, 但会尽可能地保证到某个时间级别(比如秒级别)后,数据能够达到一致状态。
3、读写一致性 :用户读取自己写入结果的一致性,保证用户永远能够第一时间看到自己更新的内容。比如我们发一条朋友圈,朋友圈的内容是不是第一时间被朋友看见不重要,但是一定要显示在自己的列表上。
解决方案:
1、一种方案是对于一些特定的内容我们每次都去主库读取。(问题主库压力大)
2、我们设置一个更新时间窗口,在刚更新的一段时间内,我们默认都从主库读取,过了这个窗口之后,我们会挑选最近更新的从库进行读取
3、我们直接记录用户更新的时间戳,在请求的时候把这个时间戳带上,凡是最后更新时间小于这个时间戳的从库都不予以响应4、单调读一致性 : 本次读到的数据不能比上次读到的旧。多次刷新返回旧数据出现灵异事件。解决方案:通过 hash 映射到同一台机器。
5、因果一致性 :如果节点 A 在更新完某个数据后通知了节点 B,那么节点 B 之后对该数据的访问和修改都是基于 A 更新后的值。于此同时,和节点 A无因果关系的节点 C 的数据访问则没有这样的限制。
6、最终一致性 :是所有分布式一致性模型当中最弱的。不考虑中间的任何状态,只保证经过一段时间之后,最终系统内数据正确。它最大程度上保证了
系统的并发能力,也因此,在高并发的场景下,它也是使用最广的一致性模型。
4.7. 分布式一致性的作用
分布式一致性的作用:
为了提高系统的可用性,以防止单点故障引起的系统不可用
提高系统的整体性能,通过负载均衡技术,能够让分布在不同地方的数据副本,都能够为用户提供服务
其实上面这么多的内容组中只有一个用处:引出一个问题:分布式系统的数据一致性的问题!
解决方案:
1、事务 + 分布式事务
2、分布式一致性算法 + 分布式共识算法
3、Quorum机制 + NWR机制分布式系统的核心设计指导思想:CAP 和 BASE 理论
5. 分布式事务
事务:单机存储系统中。用来保证存储系统的数据状态的一致性的
广义上的概念:一个事务中的所有操作,要么都成功,要么都不成功,没有中间状态
狭义上的事务: 数据库的事务特征:
ACID : 原子性,一致性,持久性, 隔离性对于单机事务,大家比较熟悉。此处重点讲解 分布式事务!
在讲解分布式事务之前,先搞清楚一个前提:分布式系统中,每个节点都能知道自己的事务操作是否成功,但是没法知道系统中的其他节点的事务是否成功。这就有可能会造成分布式系统中的各节点的状态出现不一致。因此当一个事务需要跨越服务器节点,并且要保证事务的ACID特性时,就必须引入一个 "协调者" 的角色。那么其他的各个进行事务操作的节点就都叫做 "参与者"。
典型的两种分布式事务的提交模式:2PC 和 3PC
2PC: 两阶段提交 操作简单,事务的一致性保证就没那么好,事务的操作效率就会低一些
3PC: 三阶段提交 数据一致性或者事务的执行效率必然会好一些5.1. 2PC两阶段提交
5.1.1. 执行过程解析
第一阶段:请求/表决阶段
1、在分布式事务发起者向分布式事务协调者发送请求的时候,事务协调者向所有参与者发送事务预处理请求(vote request)
2、这个时候参与者会开启本地事务并开始执行本地事务,执行完成后不会commit,而是向事务协调者报告是否可以处理本次事务第二阶段:提交/执行/回滚阶段
分布式事务协调者收到所有参与者反馈后,所有参与者节点均响应可以提交,则通知参与者和发起者执行commit,否则rollback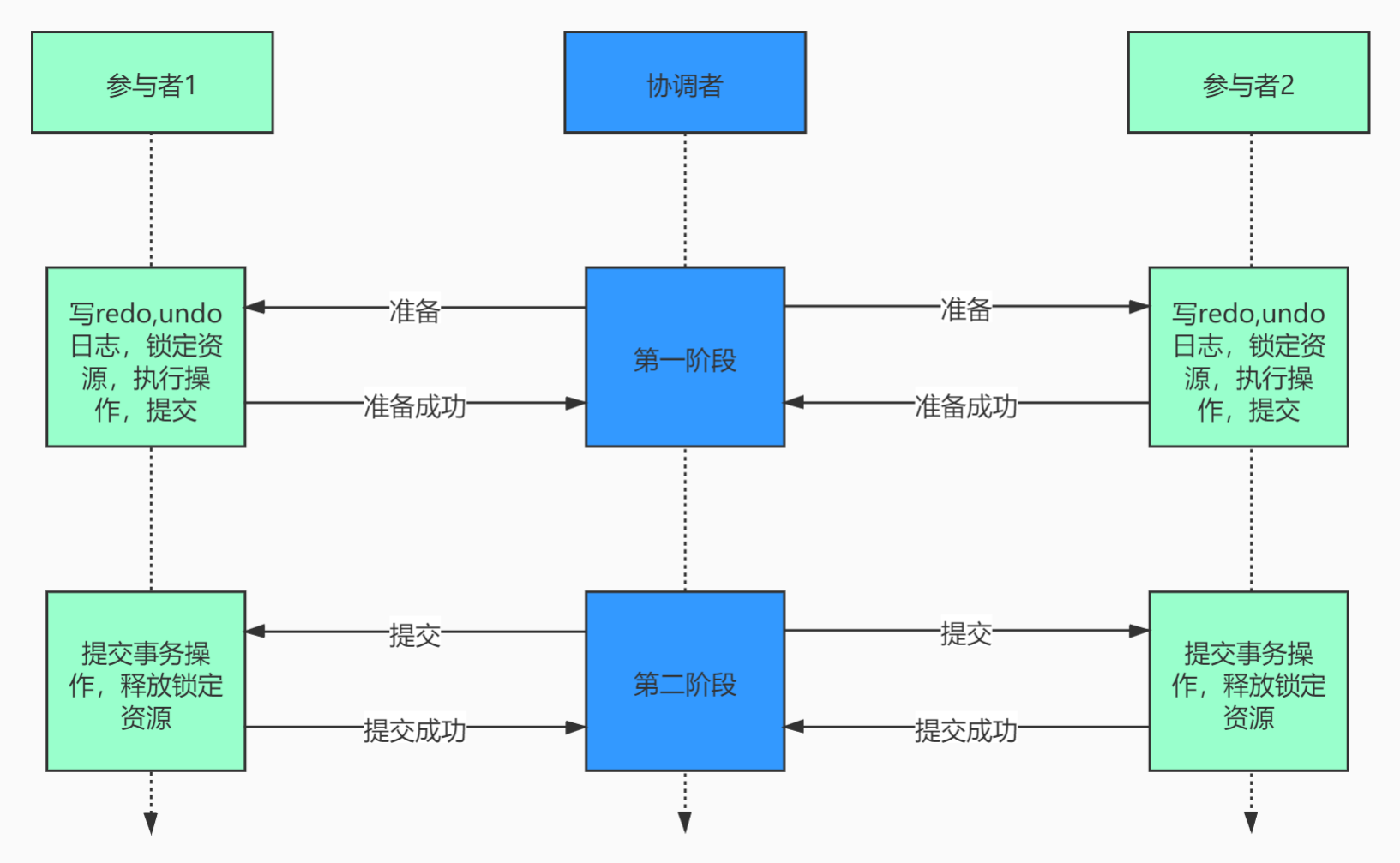
5.1.2. 2PC的问题
第一点:性能问题(同步阻塞)
从流程上面可以看出,最大的缺点就是在执行过程中节点都处于阻塞状态。各个操作数据库的节点都占用着数据库资源,只有当所有节点准备完毕,事务协调者才会
通知进行全局commit/rollback,参与者进行本地事务commit/rollback之后才会释放资源,对性能影响较大。第二点:单点故障问题(协调者可能宕机)
事务协调者是整个分布式事务的核心,一旦事务协调者出现故障,会导致参与者收不到commit/rollback的通知,从而导致参与者节点一直处于事务无法完成的中间状态。第三点:数据不一致(消息丢失问题)
在第二阶段的时候,如果发生局部网络问题,一部分事务参与者收不到 commit/rollback 消息,那么就会导致节点间数据不一致。第四点:太过保守(没有容错机制)悲观
必须收到所有参与者的正反馈才提交事务:如果有任意一个事务参与者的响应没有收到,则整个事务失败回滚。5.2. 3PC三阶段提交
3PC(three-phase commit)即三阶段提交,是2阶段提交的改进版,其将二阶段提交协议的 "提交事务请求" 一分为二,形成了cancommit,
precommit,docommit 三个阶段。
除了在 2PC 的基础上 增加了CanCommit阶段,还引入了超时机制。一旦事务参与者指定时间没有收到协调者的 commit/rollback 指令,就会自动本地commit,这样可以解决协调者单点故障的问题。
5.2.1. 执行过程解析
第一阶段:CanCommit阶段(提交询问):先问问事务参与者能不能执行
分布式事务协调者询问所有参与者是否可以进行事务操作,参与者根据自身健康情况,是否可以执行事务操作响应Y/N。第二阶段:PreCommit阶段(预提交):发送命令让事务参与者执行事务
1、如果参与者返回的都是同意,协调者则向所有参与者发送预提交请求,并进入prepared阶段。
2、参与者收到预提交请求后,执行事务操作,并保存Undo和Redo信息到事务日志中。
3、参与者执行完本地事务之后(uncommitted),会向协调者发出Ack表示已准备好提交,并等待协调者下一步指令。
4、如果协调者收到预提交响应为拒绝或者超时,则执行中断事务操作,通知各参与者中断事务(abort)。
5、参与者收到中断事务(abort)或者等待超时,都会主动中断事务/直接提交。第三阶段:doCommit阶段(最终提交):提交事务
1、协调者收到所有参与者的Ack,则从预提交进入提交阶段,并向各参与者发送提交请求。
2、参与者收到提交请求,正式提交事务(commit),并向协调者反馈提交结果Y/N。
3、协调者收到所有反馈消息,完成分布式事务。
4、如果协调者超时没有收到反馈,则发送中断事务指令(abort)。
5、参与者收到中断事务指令后,利用事务日志进行rollback。
6、参与者反馈回滚结果,协调者接收反馈结果或者超时,完成中断事务。
5.2.2. 3PC的问题
第一点:降低阻塞范围
相对于二级段提交协议,三阶段提交协议的最大的优点就是降低了事务参与者的阻塞的范围,并且能够在出现单点故障后继续达成一致。对于协调者和参与者都设置了超时机制(在2PC中,只有协调者拥有超时机制,即如果在一定时间内没有收到参与者的消息则默认失败),主要是避免了参与者在长时间无法与协调者节点通讯(协调者挂掉了)的情况下,无法释放资源的问题,因为参与者自身拥有超时机制会在超时后,自动进行本地commit从而进行释放资源。而这种机制也侧面降低了整个事务的阻塞时间和范围。第二点:最后提交以前状态一致
通过CanCommit、PreCommit、DoCommit三个阶段的设计,相较于2PC而言,多设置了一个缓冲阶段保证了在最后提交阶段之前各参与节点的状态是一致的。第三点:依然可能数据不一致
三阶段提交协议在去除阻塞的同时也引入了新的问题,那就是参与者接收到 precommit 消息后,如果出现网络分区,此时协调者所在的节点和参与者无法进行正常的网络通信,在这种情况下,该参与者依然会进行事务的提交,这必然出现数据的不一致性。5.2.3. 3PC 和 2PC 最大的区别
1、执行事务之前,先进行询问,查看所有事务参与者是否具备执行事务的条件,如果协调者收到所有事务参与者的正反馈,则执行第二阶段,否则发送rollback 命令回滚事务
2、第二阶段如果执行 precommit 命令,意味着,所有的事务参与者都具备执行事务的条件,所以在第二阶段中,所有事务参与者都会执行事务
3、当第二阶段中的所有事务参与者都发回正反馈,则协调者发送 docommit 命令来提交事务。如果此时协调者宕机,则不能发送命令,则第二阶段执行事务成功的 参与者会在超时时间到达的时候,自动提交事务。
6. 分布式一致性算法详解
在分布式系统中,网络通信的异常情况是一定存在的(通信的延迟和中断,消息的丢失和延迟)
网络分区一定存在!(消息的延迟和丢失的可能性一定是有的!)就需要在就算发生了网络分区,也能保证分布式数据一致!
6.1. Paxos算法
1991年的发表了一篇论文, 因为这个算法非常复杂,不好理解,所以他发表论文的时候,举了个例子:paxos
Paxos 算法是 Lesile Lamport 提出的一种基于消息传递且具有高度容错特性的一致性算法。如何证明的具有高度容错,可以详解"拜占庭将军问题"。
分布式系统中的节点通信存在两种模型: 共享内存和消息传递。
基于消息传递通信模型的分布式系统,不可避免会发生进程变慢被杀死,消息延迟、丢失、重复等问题,Paxos算法就是在存在以上异常的情况下仍能保持一致性的协议。
Paxos 算法使用一个希腊故事来描述,在 Paxos 中,存在三种角色,分别为
1、Proposer(提议者,用来发出提案 proposal),
2、Acceptor(接受者,可以接受或拒绝提案),
3、Learner(学习者,学习被选定的提案,当提案被超过半数的 Acceptor 接受后为被批准)。映射到 zookeeper 集群:
leader:发起提案 主席,单点故障(解决方案:leader 选举机制)
follower:参与投票 人大代表
observer:被动接受 全国所有人议会制:当部分节点宕机之后,最终仍然能够投票通过。在一定时间之后,在重启之后就会找 proposal 来同步数据
弱一致性:少数服从多数,保证超过半数达成一致即可的协议下面更精确的定义 Paxos 要解决的问题:
1、决议(value)只有在被 proposer 提出后才能被批准
2、在一次 Paxos 算法的执行实例中,只批准 (choose) 一个value, multi-paxos
3、learner 只能获得被批准 (chosen) 的 value在 ZooKeeper 的内部,所有事务请求必须由一个全局唯一的服务器来协调处理,这样的服务器被称为 Leader 服务器,而余下的其他服务器则成为Follower 服务器。Leader 服务器负责将一个客户端事务请求转换成一个事务 proposal,并将该 proposal 分发给集群中所有的 Follower 服务器。之后Leader 服务器需要等待所有 Follower 服务器的反馈,一旦超过半数的 Follower 服务器进行了正确的反馈后,那么 leader 就会再次向所有的 Follower服务器分发 commit 消息,要求其将前一个 proposal 进行提交。
Paxos 算法: 分布式一致性算法。其他的所有分布式一致性算法,都是 paxos 的不完美版本!
ZooKeeper 基于 ZAB 来实现的, ZAB 的底层是封装了 Paxos
Etcd 基于 Raft 来实现的。
6.2. Raft算法
Etcd 的底层实现: Raft 算法。想要了解 Raft 算法,给你一个九阳神功密卷:http://thesecretlivesofdata.com/raft/,只要花费不到10分钟的时间就可以搞定这个算法了!
follower: 跟随者 没有线条
candidate:候选人 虚线
leader: 领导者 实线Leader Election 选主!
Log Replicatoin
6.3. ZAB协议
ZooKeeper 的底层实现:ZAB 协议
ZooKeeper 的底层工作机制,就是依靠 ZAB 实现的。实现 崩溃恢复 和 消息广播 两个主要功能。
ZAB协议需要确保那些已经在 leader 服务器上提交的事务最终被所有服务器都提交。
ZAB协议需要确保丢弃那些只在 leader 服务器上被提出的事务。
如果让 Leader 选举算法能够保证新选举出来的 Leader 服务器拥有集群中所有机器最高事务编号(ZXID)的事务 proposal,那么就可以保证这个新选举出来的 leader 一定具有所有已经提交的提案。
ZAB两种基本的模式:崩溃恢复 和 消息广播。
64 位长度的 long 类型的数值:前面 32 epoch 后 32 位是 txid
1、epoch: leader的任期代号 康熙 雍正 乾隆
2、txid: 当前 leader 在任期间执行的事务给定的一个全局唯一编号ZooKeeper 底层分布式一致性算法实现: ZAB 分布式一致性协议
Etcd 底层分布式一致性算法实现:raft 分布式共识算法
7. 抽屉原理/鸽巢原理
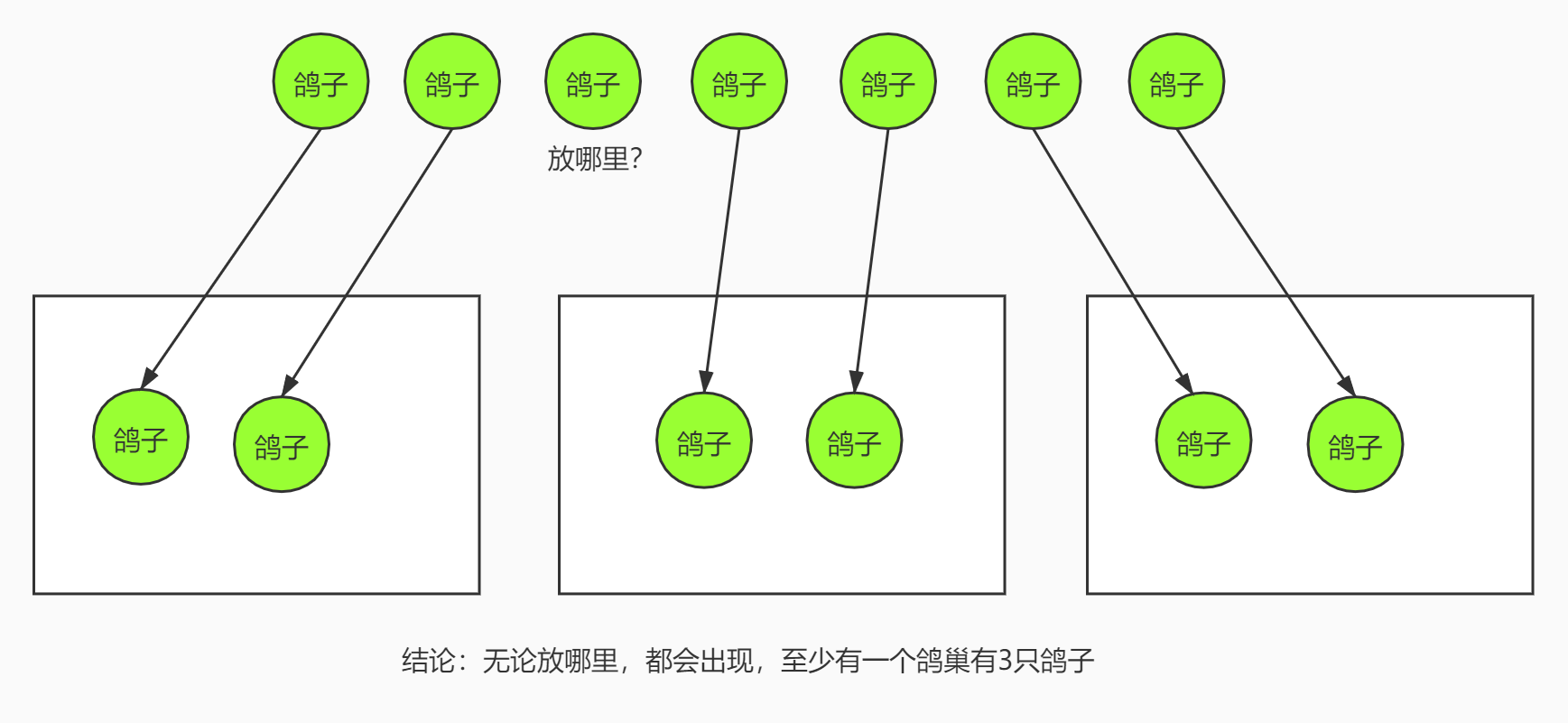
鸽巢原理,又名狄利克雷抽屉原理、鸽笼原理。
其中一种简单的表述法为:
若有 n 个笼子和 n+1 只鸽子,所有的鸽子都被关在鸽笼里,那么至少有一个笼子有至少 2 只鸽子。
另一种为:
若有 n 个笼子和 kn+1 只鸽子,所有的鸽子都被关在鸽笼里,那么至少有一个笼子有至少 k+1 只鸽子。
为什么从抽屉原理说起?一来大家对这个比较熟悉,也容易理解,二来它与 Quorum 机制有异曲同工的地方。
回顾抽屉原理,2个抽屉每个抽屉最多容纳2个苹果,现在有3个苹果无论怎么放,其中的一个抽屉里面肯定会有2个苹果。那么我们把抽屉原理变变型,2个抽屉一个放了2个红苹果,另一个放了2个青苹果,我们取出3个苹果,无论怎么取至少有1个是红苹果,这个理解起来也很简单。我们把红苹果看成更新了的有效数据,青苹果看成未更新的无效数据。便可以看出来,不需要更新全部数据(并非全部是红苹果)我们就可以得到有效数据,当然我们需要读取多个副本完成(取出多个苹果)。
现在有5个节点: 写入数据的时候,成功了3个节点, 失败了2个节点,我怎么获取数据一定能保证获取到最新的数据?
因为失败的节点有2个,那就以为,我无论如何再随便多读取一个节点的数据,那就保证了一定能读取到一个新节点的新数据
假设一下:
总结点:N
写成功节点数:W
需要读取的节点数: R
N - W + 1 = R ====> N - W < R =====> R + W > N8. Quorum NWR 机制
Quorum NWR:Quorum 机制是分布式场景中常用的,用来保证数据安全,并且在分布式环境中实现最终一致性的投票算法。这种算法的主要原理来源于鸽巢原理。它最大的优势,既能实现强一致性,而且还能自定义一致性级别!
Write to all copies with latest version N, wait synchronously for W success Read from all copies, wait for first R responses, pick the highest
version number
N:复制的节点数,即一份数据被保存的副本数。
W:写操作成功的节点数,即每次数据写入写成功的副本数。W 肯定是小于等于 N 的。
R:读操作获取最新版本数据所需的最小节点数,即每次读取成功至少需要读取的副本数。
WARO(Write All Read one) 是一种简单的副本控制协议,当 Client 请求向某副本写数据时(更新数据),只有当所有的副本都更新成功之后,这次写操作才算成功,否则视为失败。
WORA(Write One Read All) 是一种简单的副本控制协议,当 Client 请求向某副本写数据时(更新数据),只要有一个副本更新成功之后,这次写操作就可以算成功,否则视为失败。
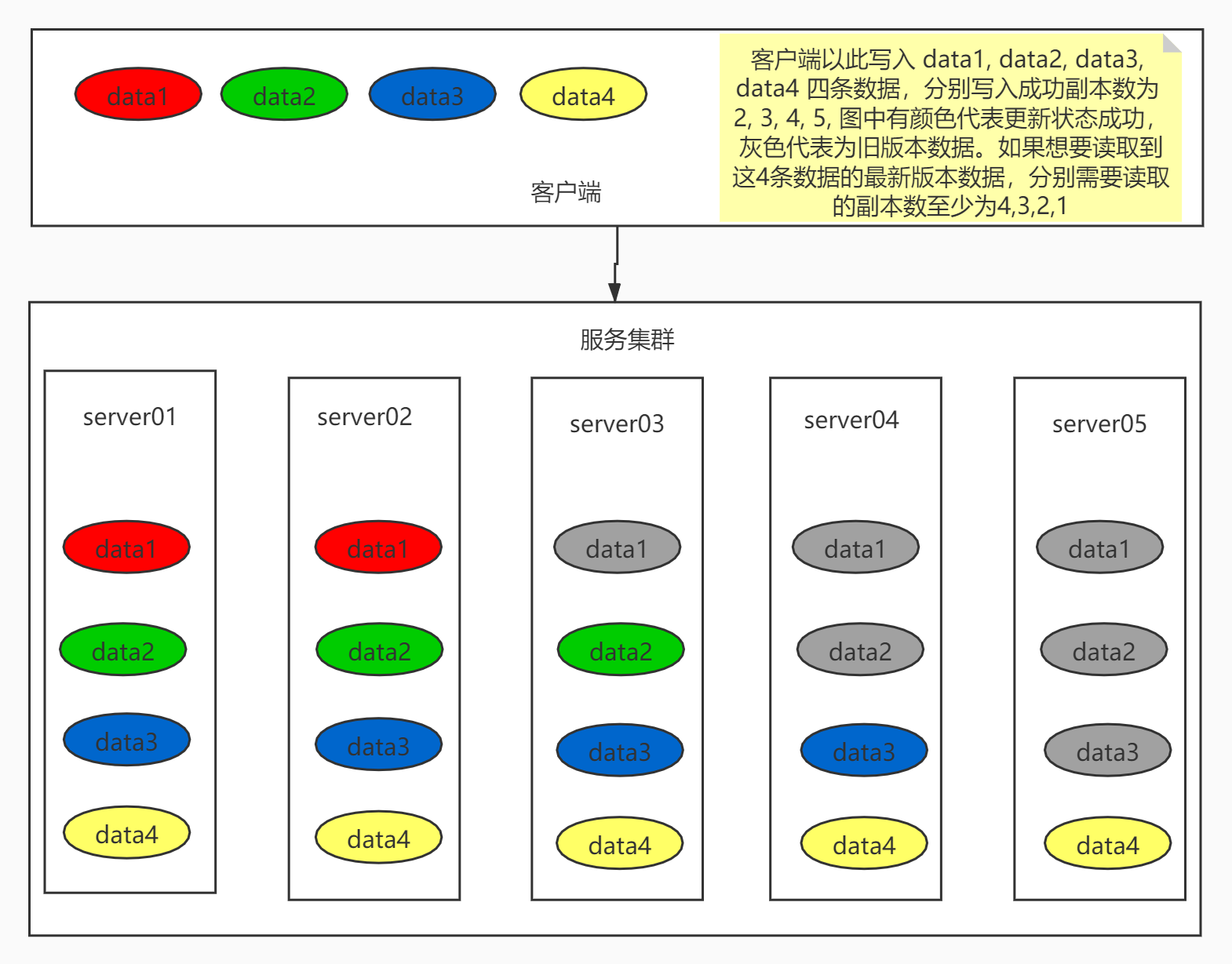
如果你写成功了 R
总结点个数是: N
只需要保证,你至少读取 N -R + 1 个节点一定能读取到最新数据
data1: R=2, n=5 n-r+1 =4 一定能读取到最新数据
data3: R=4, n=5, n-r+1 =2
N: 总结点个数
W: 写入数据成功的副本数
R: 读取读取读取的节点数据
只要满足:R + W > N 即可!在分布式场景中,为了读取到一致性的数据,在读和写的个数中,我可以追求一个平衡
极端情况:
1、如果N=W, 读取效率高,读取任意一个节点即可读取到最新数据,所以:读取效率高,写入效率低
2、如果N=R, 写入效率高,因为数据只要写入任意一个节点即可,所以:写入效率高,读取效率低
3、R = W = N/2 + 1, 写入成功超过一半,读取成功也超过一半。总结:这三个因素决定了可用性,一致性 和 分区容错性。只要保证(W + R > N)就一定能读取到最新的数据,数据一致性级别完全可以根据读写副本数的约束来达到强一致性!
分以下三种情况讨论:前提,当 N 已经固定了。
W = 1, R = N,Write Once Read All
在分布式环境中,写一份副本,那么如果要读取到最新数据,就必须要读取所有节点,然后取最新版本的值了。写操作高效,但是读操作效率低。分区容错性很低,一致性高,分区容错性差,写可用性高,读可用性低
R = 1, W = N, Read Only Write All
在分布式环境中,所有节点都同步完毕,才能读取,所以只要读取任意一个节点就可以读取到最新数据。读操作高效,但是写操作效率低。分区容错性好,一致性差,实现难度更高,读可用性高,写可用性低。
W = Q, R = Q where Q = N/2 + 1
可以简单理解为写超过一半节点,那么读也要超过一半节点,取得读写性能平衡。一般应用适用,读写性能之间取得平衡。如 N=3, W=2, R=2,分区容错性,可用性,一致性都取得一个平衡。
ZooKeeper 就是这么干的!采用了第三种情况!
分布式数据库:
HBase: CP 数据的强一致性
Cassandra: AP 追求高可用性有没有 CA 的分布式系统?没有!如果都不用保证 P,则证明并不是真正意义上的分布式系统。单机系统是 CA 类型! MySQL Oracle
三个要素:无论怎么做,都没法去设计一个系统同时满足这么三个条件:
1、P分区容错性: 分布式系统要满足这个,必然数据有多个副本
2、A可用性:可用性越高
3、C数据一致性:数据副本越多,数据一致性越差9. CAP 理论和 BASE 理论详解
9.1. CAP 理论
CAP 理论:2000 年 7 月份被首次提出,CAP 理论告诉我们,一个分布式系统不可能同时满足 C,A,P 三个需求
C:Consistency,强一致性:分布式环境中多个数据副本保持一致
A:Availability,高可用性:系统提供的服务必须一直处于可用,对于用户的每一个操作请求总是能在有限时间内返回结果
P:Partition Tolerance 分区容错性:分布式系统在遇到任何网络分区故障时,仍然需要能够保证对外提供满足一致性和可用性的服务
1、分布式系统一定要满足P,必然写入多个数据副本
2、为了保证C,保证强一致性,必须保证所有数据副本都写入成功,必然消耗的资源和时间都增大
3、写入的复杂度增加了,系统为了保证数据的多个副本的强一致性,所以系统的可用性没有那么好既然一个分布式系统不能同时满足 C,A,P 三个需求,那么如何抉择呢?
放弃 P:最简单的极端做法,就是放置在一个节点上,也就只有一个数据副本,所有读写操作就集中在一台服务器上,有单点故障问题。放弃 P 也就意味着放弃了系统的可扩展性,所以分布式系统一般来说,都会保证 P
放弃 A:一旦系统遇到网络分区或者其他故障时,服务需要等待一段时间,在等待时间内就无法正常对外提供服务,即服务不可用
放弃 C:事实上,放弃一致性是指放弃数据的强一致性,而保留最终一致性,具体多久达到数据同步取决于存储系统的设计
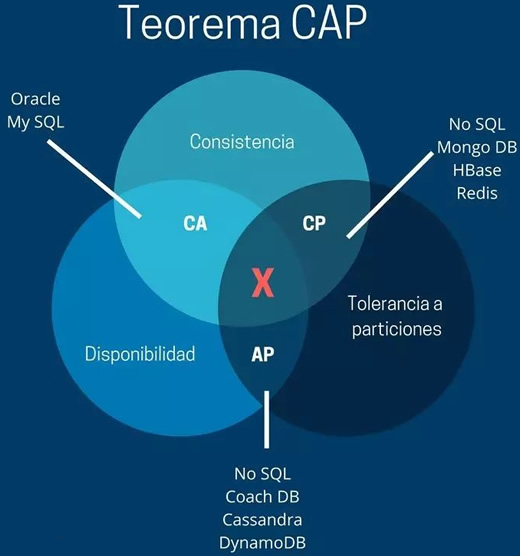
CAP只能3选2,因为在分布式系统中,容错性P肯定是必须有的,所以这时候无非就两种情况,网络问题导致要么错误返回,要么阻塞等待,前者牺牲了一致性,后者牺牲了可用性。
经验总结:
架构师不要花费精力浪费在设计同时满足CAP的分布式系统
分区容错性往往是分布式系统必然要面对和解决的问题。所以架构师应该把精力放在如何根据业务特点在 A 和 C 之间寻求平衡。
对于单机软件,因为不用考虑 P,所以肯定是 CA 型,比如 MySQL
对于分布式软件,因为一定会考虑 P,所以又不能兼顾 A 和 C 的情况下,只能在 A 和 C 做权衡,比如 HBase, Redis 等。做到服务基本可用,并且数据最终一致即可。
所以,就产生了 BASE 理论。
关于分布式锁实现
1、redis AP模型
2、zookeeper CP模型关于分布式数据库:
1、hbase CP模型
2、cassandra AP模型也没有那么绝对! 一定要满足P,在 A 和 C 当中寻求一个平衡!
C A
100 0 强一致
0 100 高可用
70 709.2. BASE 理论
儒家思想的精髓:中庸
多数情况下,其实我们也并非一定要求强一致性,部分业务可以容忍一定程度的延迟一致,所以为了兼顾效率,发展出来了最终一致性理论 BASE,来自ebay 的架构师提出。BASE 理论全称:全称:Basically Available(基本可用),Soft state(软状态),和 Eventually consistent(最终一致性)三个短语的缩写。核心思想是:即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。一句话概括,做事别走极端,BASE 是对 CAP 理论中的 C 和 A 进行权衡得到的结果。
不是高可用,而是基本可用。
不是强一致,而是最终一致Basically Available(基本可用):基本可用是指分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用
响应时间的损失:出现故障或者高峰,查询结果可适当延长,以用户体验上限为主。
功能上的损失:例如淘宝双11,为保护系统稳定性,正常下单,其他边缘服务可暂时不可用。
Soft State(软状态):软状态是指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。分布式存储中一般一份数据至少会有三个副本,允许不同节点间副本同步的延时就是软状态的体现。通俗的讲:允许存在不同节点同步数据时出现延迟,且出现数据同步延迟时存在的中间状态也不会影响系统的整体性能
Eventually Consistent(最终一致):最终一致性是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况,要求最终达到一致,而不是实时强一致
A:100, C:0, P:100
A:0 C:100, P:100
A:70: C:70 P:100 BASE
A:50, C:100, P:100 HBase以上所有理论的总结:
1、问题的引出:集中式 和 分布式服务部署架构的分析
设计分布式系统会遇到的各种难题:最尖锐的就是数据一致性的问题
2、解决方案:分布式事务:2PC 3PC
通用的思路实现,但是无论如何,还是有缺点
3、解决方案:分布式一致性算法:Paxos Raft ZAB
就算出现了分布式网络通信异常等相关棘手的问题,以上这些算法也能实现一致性
拜占庭将军问题:消息丢失 + 消息被恶意更改
4、理论:议会制 Quorum NWR 机制
R + W > N ===> 少数服从多数
一致性 和 可用性的冲突问题
5、理论:CAP 和 BASE
分布式系统一定要满足 P,当然就只能在 C 和 A 中做权衡。!
绝大部分系统都是 BASE 系统(基本可用 + 最终一致)以后,开发分布式系统,根据业务来决定到底追求 高可用 还是追求 强一致性,也是做到平衡!
NWR 中 N : 需要写入成功的总副本个数,甚至可以理解成总节点个数
CAP 中的 P :只要存在副本机制即可,也就是说,这个分布式系统是有副本协议来保证 数据高可用的。能够保证 P 的
10. ZooKeeper介绍
官网地址:http://ZooKeeper.apache.org/
官网快速开始地址:http://zookeeper.apache.org/doc/current/zookeeperStarted.html
官网API地址:http://ZooKeeper.apache.org/doc/r3.4.10/api/index.html
10.1. ZooKeeper 介绍
引用官网介绍:
What is ZooKeeper?
Apache ZooKeeper is an effort to develop and maintain an open-source server which enables highly reliable distributed
coordination
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and
providing group services. All of these kinds of services are used in some form or another by distributed applications. Each time they are
implemented there is a lot of work that goes into fixing the bugs and race conditions that are inevitable. Because of the difficulty of
implementing these kinds of services, applications initially usually skimp on them ,which make them brittle in the presence of change and
difficult to manage. Even when done correctly, different implementations of these services lead to management complexity when the
applications are deployed
ZooKeeper 是一个分布式的,开放源码的分布式应用程序协调服务,是 Google 的 Chubby 一个开源的实现。它提供了简单原始的功能,分布式应用可以基于它实现更高级的服务,比如分布式同步,配置管理,集群管理,命名管理,队列管理。它被设计为易于编程,使用文件系统目录树作为数据模型。服务端跑在 Java 上,提供 Java 和 C 的客户端 API。
GFS HDFS 分布式文件系统
BigTable HBase 分布式数据库
MapReduce MapReduce 分布式计算系统他们都共同提到了一个技术:chubby 服务协调的! ZooKeeper就是用来解决这些分布式系统共同存在的疑难杂症!
通俗总结:ZooKeeper 是分布式系统中的 疑难杂症的开源通用解决方案。
众所周知,协调服务非常容易出错,但是却很难恢复正常,例如,协调服务很容易处于竞态以至于出现死锁。我们设计 ZooKeeper 的目的是为了减轻分布式应用程序所承担的协调任务。
ZooKeeper 是集群的管理者,监视着集群中各节点的状态,根据节点提交的反馈进行下一步合理的操作。最终,将简单易用的接口和功能稳定,性能高效的系统提供给用户。
10.2. ZooKeeper的核心架构设计和工作机制
Zookeeper 是一个分布式一致性的解决方案,分布式应用可以基于它实现诸如数据发布/订阅,负载均衡,命名服务,分布式协调/通知,集群管理,Master选举,分布式锁 和 分布式队列 等功能。Zookeeper 致力于提供一个高性能、高可用、且具有严格的顺序访问控制能力的分布式协调系统。
Zookeeper 分布式集群,当中的所有节点,都保存了这个集群中的所有数据。
任意一条数据,但凡提交成功,都被保存在了 Zookeeper 的所有的服务器节点
例如:Zookeeper 集群有 9 个节点,每条数据写入成功,就被写入了 9 个副本ZooKeeper 集群没有单点故障的!
Hadoop HA 就是基于 ZooKeeper , 那就让这个集群中的所有节点的状态(数据的状态)都是一致的
ZooKeeper 是基于 paxos 实现的, 其实每个 Follower 都可以发起提议的!
proposal
acceptor 中谁发起了提议,谁就是 propersor,
learner如果让 ZooKeeper 集群中的所有节点,都具备发起提议的功能,就会出现一个问题:没法保证全局时钟序列
ZooKeeper 集群会专门选择一个节点用来处理所有的 提议发起(只有一个节点,具备发起提议的权利)
保证严格有序:
1、全局有序:服务端先接收到的请求,也一定会先处理。
2、偏序:客户端先发送的请求,服务端一定会先处理
ZooKeeper 内部的所有的事务,都是串行排队执行ZooKeeper 内部就实现了一个选举算法: 正常来说,所有的节点一上线都是 looking 状态(找 Leader 状态) 必然会有节点发起提议来选 Leader,如果选举成功,则有一个 looking 状态的节点成为 leader,则其他节点自动成为 Follower 节点。
这个 Leader 负责这个 ZooKeeper 集群内部的所有事务操作,也就相当于是一个分布式协调者。
Leader 和所有的 Follower 都是负责处理读数据请求
10.3. ZooKeeper的设计目的/架构特点
最终一致性
client 不论连接到哪个 Server,展示给它都是同一个数据视图,这是 ZooKeeper 最重要的功能特色。可靠性
具有简单、健壮、良好的性能,如果消息 message 被一台服务器接受,那么它将被所有的服务器接受。实时性
ZooKeeper 保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。但由于网络延时等原因,ZooKeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用 sync() 接口。等待无关(wait-free)
慢的或者失效的 client 不得干预快速的 client 的请求,使得每个 client 都能有效的等待。原子性
事务操作只能成功或者失败,没有中间状态。通过 ZAB 协议实现!顺序性
TCP 协议的保证消息的全序特性,先发的消息,服务器先收到。
Leader 的因果顺序,包括全局有序和偏序两种:
1、全局有序:如果在一台服务器上消息 a 在消息 b 前发布,则在所有 Server 上消息 a 都将在消息 b 前被发布;
2、偏序:指如果一个消息 b 在消息 a 后被同一个发送者发布,a 必将排在 b 前面10.4. ZooKeeper 功能性能总结
ZooKeeper 作为一个集群提供数据一致的协调服务,自然,最好的方式就是在整个集群中的各服务节点进行数据的复制和同步。通俗的讲,就是ZooKeeper 以一个集群的方式对外提供协调服务,集群内部的所有节点都保存了一份完整的数据。其中一个主节点用来做集群管理提供写数据服务,其他的从节点用来同步数据,提供读数据服务。这些从节点必须保持和主节点的数据状态一致。
数据复制的好处:
1、容错:一个节点出错,数据不丢失,不至于让整个集群无法提供服务
2、扩展性:通过增加服务器节点能提高 ZooKeeper 系统的负载能力,把读写负载分布到多个节点上
3、高性能:客户端可访问本地 ZooKeeper 节点或者访问就近的节点,依次提高用户的访问速度大白话总结 ZooKeeper 的知识点:
在 ZooKeeper 中,没有沿用 Master/Slave(主备)概念,而是引入了 Leader、Follower、Observer 三种角色。通过 Leader 选举来选定一台
Leader 机器,Leader 机器为客户端提供读写服务,其他角色提供读服务,唯一区别就是 Observer 不参与 Leader 选举过程、写操作过半成功策略,因此 Observer 可以在不影响写性能情况下提高集群性能。
ZooKeeper 集群中的所有节点的数据状态通过 ZAB 协议保持一致。
ZooKeeper 是对等架构,工作的时候,会举行选举,变成 leader + follower 架构
ZooKeeper 中的所有数据,都在所有节点保存了一份完整的。
ZooKeeper 的所有事务操作在 zookeeper 系统内部都是严格有序串行执行的。
ZooKeeper 系统中的 leader 角色可以进行读,写操作
ZooKeeper 系统中的 follower 角色可以进行读操作执行,但是接收到写操作,会转发给 leader 去执行。
ZooKeeper 系统的 leader 就相当于是一个全局唯一的分布式事务发起者,其他所有的 follower 是事务参与者,拥有投票权
ZooKeeper 系统还有一种角色叫做 observer,这个角色和 follower 最大的区别就是 observer 除了没有选举权 和 被选举权 以外,其他的和follower 完全一样
observer 的作用是 分担整个集群的读数据压力,同时又不是增加分布式事务的执行压力,因为分布式事务的执行操作,只会在 leader 和 follower中执行。observer 只是保持跟 leader 的同步,然后帮忙对外提供 读数据服务
ZooKeeper 系统虽然提供了存储系统,但是这个存储,只是为自己实现某些功能做准备的,而不是提供出来,给用户存储大量数据的
ZooKeeper 提供了 znode 节点的常规的增删改查操作,使用这些操作,可以模拟对应的业务操作,使用监听机制,可以让客户端立即感知这种变化。
ZooKeeper 集群和其他分布式集群最大的不同,在于 zookeeper 是不能进行线性扩展的。因为像 HDFS 的集群服务能力是和集群的节点个数成正比,但是 ZooKeeper 系统的节点个数越多,反而性能越差
ZooKeeper 集群的最佳配置:比如 9,11,13 个这样的 follower 节点,observer 若干!follower 切记不宜太多!
ZooKeeper 系统如果产生了这么一种情况:某个 znode 的数据变化非常的快,每次变化触发一次 Watcher 的 process 回调!由于 zookeeper 执行事务的时候,是串行单节点严格有序执行的。leader 负责这个事务的顺序执行。多个事件来不及执行,上一个事件还没有执行,下个动作触发,zookeeper 会忽略! 影响不大!
10.5. ZooKeeper集群安装
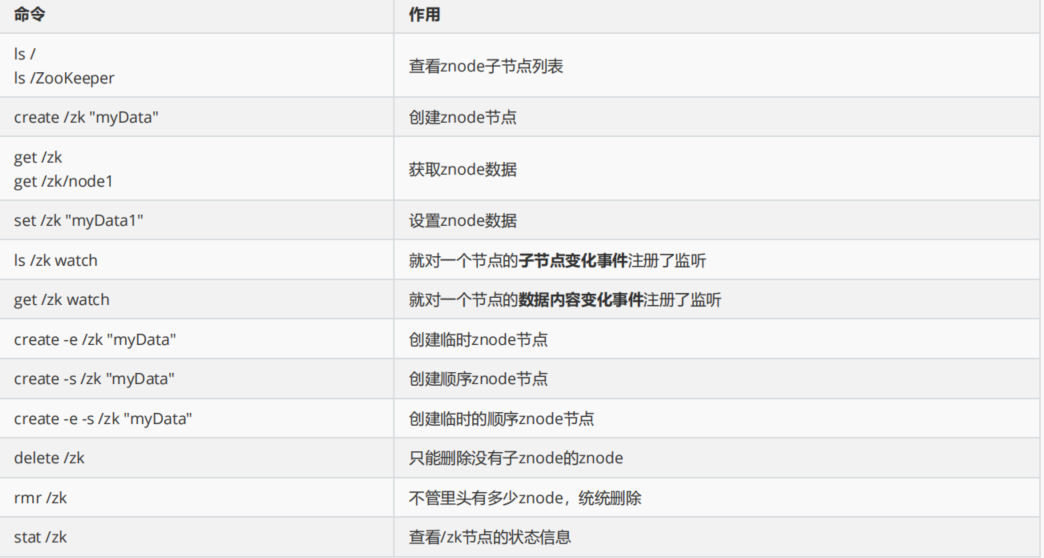
10.6. ZooKeeper Shell 使用
首先,我们可以是用命令 bin/zkCli.sh 进入 ZooKeeper 的命令行客户端,这种是直接连接本机的 ZooKeeper 服务器,还有一种方式,可以连接其他的ZooKeeper 服务器,只需要我们在命令后面接一个参数 -server 就可以了。例如:
[bigdata@bigdata02 ~]# zkCli.sh -server bigdata02:2181进入命令行之后,键入help可以查看简易的命令帮助文档,如下图:
znode数据信息字段解释:
cZxid = 0x400000093 节点创建的时候的zxid
# The zxid of the change that caused this znode to be created.
ctime = Fri Dec 02 16:41:50 PST 2016 节点创建的时间
# The time in milliseconds from epoch when this znode was created.
mZxid = 0x400000093 节点修改的时候的zxid,与子节点的修改无关
# The zxid of the change that last modified this znode.
mtime = Fri Dec 02 16:41:50 PST 2016 节点的修改的时间
# The time in milliseconds from epoch when this znode was last modified.
pZxid = 0x400000093 和子节点的创建/删除对应的zxid,和修改无关,和孙子节点无关
# The zxid of the change that last modified children of this znode.
cversion = 0 子节点的更新次数
# The number of changes to the children of this znode.
dataVersion = 0 节点数据的更新次数
# The number of changes to the data of this znode.
aclVersion = 0 节点(ACL)的更新次数
# The number of changes to the ACL of this znode.
ephemeralOwner = 0x0 如果该节点为ephemeral节点, ephemeralOwner值表示与该节点绑定的session id. 如果该节点不是ephemeral节点,
ephemeralOwner值为0
# The session id of the owner of this znode if the znode is an ephemeral node. If it is not an ephemeral node, it will
be zero.
dataLength = 6 节点数据的字节数
# The length of the data field of this znode.
numChildren = 0 子节点个数,不包含孙子节点
# The number of children of this znode.10.7. ZooKeeper Java API 使用
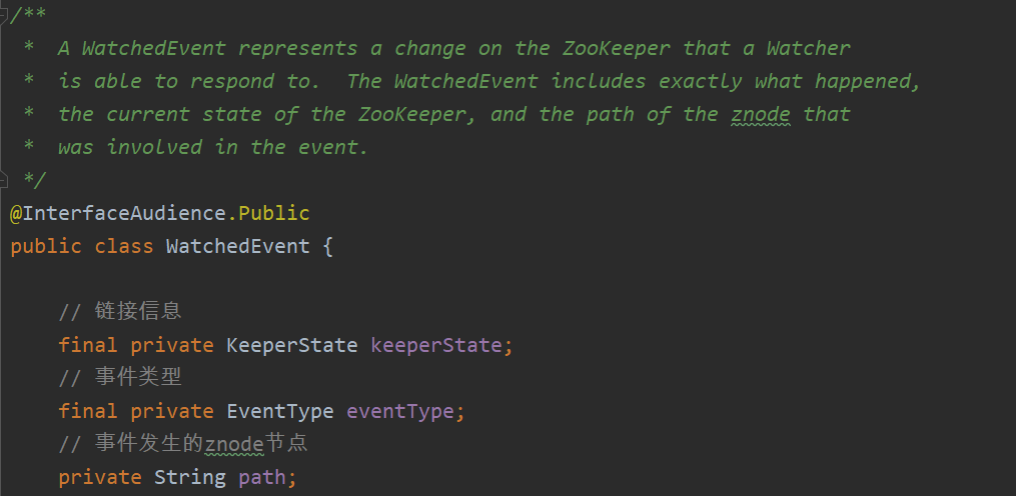
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.EventType;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.data.Stat;
public class ZK_JavaAPI_Demo {
// 客户端去请求链接的时候的服务器链接信息
private static final String connectString = "bigdata02:2181,bigdata03:2181,bigdata04:2181";
// 客户端去请求链接的时候的超时时间
private static final int sessionTimeout = 4000;
static ZooKeeper zk = null;
public static void main(String[] args) throws Exception {
// zookeeper构造方式初始化的时候需要三个参数,
/**
* 1、zookeeper服务器链接信息
* 2、会话超时时间
* 3、监听器
*/
// 不加监听
// zk = new ZooKeeper(connectString, sessionTimeout, null);
// 添加监听
zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent event) {
// System.out.println("event working....");
if (event.getState() == KeeperState.SyncConnected) {
if (event.getType() == EventType.None) {
System.out.println("connected");
} else if (event.getType() == EventType.NodeChildrenChanged) {
System.out.println("%%%%% " + event.getPath() + " -- " + event.getType());
try {
zk.getChildren("/lishuiqiao", true);
} catch (Exception e) {
e.printStackTrace();
}
} else {
System.out.println("@@@@@ " + event.getPath() + " -- " + event.getType());
}
} else {
System.out.println("conncet fail");
}
}
});
// List<ACL> aclist = new ArrayList<ACL>();
// ACL acl = new ACL(perms, id)
// EventType
/**
* 创建znode
*/
// String path = zk.create("/lishuiqiao", new String("huangbo").getBytes(), Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT_SEQUENTIAL);
// System.out.println(path);
/**
* 当前你的getData操作,你加了监听器在上面,下一次有关于/lishuiqiao数据变化的时间就被会被通知到该你加的该监听器
*/
/*zk.getData("/lishuiqiao", new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println("&&&&& "+event.getPath() + " -- "+ event.getType());
}
}, null);*/
/**
* 修改znode数据
* 第三个参数,是数据的版本号,如果你知道,你要传入正确的版本号才能修改,如果不知道,那就用-1代替
*/
// Stat setData = zk.setData("/lishuiqiao", "feiji".getBytes(), -1);
// System.out.println(new Date(setData.getMtime() - 16*3600*1000));
/**
* 获取子节点
*/
// List<String> children = zk.getChildren("/lishuiqiao", true);
// System.out.println(children);
/**
* 获取znode的权限信息
*/
/*List<ACL> acl = zk.getACL("/lishuiqiao", null);
System.out.println(acl.size());
for(ACL ac: acl){
System.out.println(ac.getPerms());
}*/
/**
* 获取节点的数据
*/
// byte[] data = zk.getData("/lishuiqiao", true, null);
// System.out.println(new String(data, "UTF-8"));
/**
* 删除没有子节点的znode
*/
// zk.delete("/lishuiqiao/ditiezhan", -1);
/**
* 判断znode是否存在。如果exists为null, 那就表示该节点不存在
*/
Stat exists = zk.exists("/lishuiqiao/ditiezhan1", true);
System.out.println(exists);
Thread.sleep(Long.MAX_VALUE);
zk.close();
}
}11. 最终总结
第一部分:分布式数据一致性解决方案相关
1、问题的引出:集中式 和 分布式服务部署架构的分析
设计分布式系统会遇到的各种难题:最尖锐的就是数据一致性的问题
2、解决方案:分布式事务:2PC 3PC
通用的思路实现,但是无论如何,还是有缺点
3、解决方案:分布式一致性算法:Paxos Raft ZAB
就算出现了分布式网络通信异常等相关棘手的问题,以上这些算法也能实现一致性
拜占庭将军问题:消息丢失 + 消息被恶意更改
4、理论:议会制 Quorum NWR 机制
R + W > N ===> 少数服从多数
一致性 和 可用性的冲突问题
5、理论:CAP 和 BASE
分布式系统一定要满足 P,当然就只能在 C 和 A 中做权衡。!
绝大部分系统都是 BASE 系统(基本可用 + 最终一致)第二部分:Zookeeper 相关
12. 本次课程作业
利用 ZooKeeper 的 Java API 完成如下作业:
package com.mazh.nx.zookeeper.exercise;
import org.apache.zookeeper.ZooKeeper;
import java.util.Map;
/**
下午11:39:10
*
* 编程思维训练
* 1、级联查看某节点下所有节点及节点值
* 2、删除一个节点,不管有有没有任何子节点
* 3、级联创建任意节点
* 4、清空子节点
*/
public interface ZKHomeWork {
/**
* 级联查看某节点下所有节点及节点值
*/
public Map < String, String > getChildNodeAndValue(String path) throws Exception;
/*** 删除一个节点,不管有有没有任何子节点
*/
public boolean rmr(String path, ZooKeeper zk) throws Exception;
/**
* 级联创建任意节点
* /a/b/c/d/e
*/
public boolean createZNode(String znodePath, String data, ZooKeeper zk) throws Exception;
/**
* 清空子节点
*/
public boolean clearChildNode(String znodePath, ZooKeeper zk) throws Exception;
}上面的代码是预先定义好的一个接口,各位小伙伴,请实现这个接口,并完成所要求的功能实现和测试。最好的作业提交形式:编写一个接口实现类,和一个测试类
为了完成这个作业,我们需要实现ZKHomeWork接口中定义的方法。下面是一个简单的实现示例,以及如何测试这些功能。请注意,这只是一个基本的实现示例,并且为了简化说明,我没有包含异常处理的最佳实践,例如重试机制等。在实际生产环境中,您应该添加更完善的错误处理逻辑。
首先,我们来实现ZKHomeWork接口:
package com.mazh.nx.zookeeper.exercise;
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
import java.util.*;
public class ZKHomeWorkImpl implements ZKHomeWork {
private static final int SESSION_TIMEOUT = 30000; // 单位毫秒
private static final String CONNECT_STRING = "localhost:2181"; // 假设ZooKeeper运行在本地
private ZooKeeper zk;
public ZKHomeWorkImpl() throws IOException {
zk = new ZooKeeper(CONNECT_STRING, SESSION_TIMEOUT, event -> {
if (event.getState() == Watcher.Event.KeeperState.SyncConnected) {
System.out.println("Connected to ZooKeeper");
}
});
}
@Override
public Map<String, String> getChildNodeAndValue(String path) throws KeeperException, InterruptedException {
Map<String, String> result = new HashMap<>();
List<String> children = zk.getChildren(path, false);
for (String child : children) {
String fullPath = path + "/" + child;
byte[] data = zk.getData(fullPath, false, new Stat());
result.put(fullPath, new String(data));
result.putAll(getChildNodeAndValue(fullPath)); // 递归获取子节点信息
}
return result;
}
@Override
public boolean rmr(String path, ZooKeeper zk) throws KeeperException, InterruptedException {
List<String> children = zk.getChildren(path, false);
if (!children.isEmpty()) {
for (String child : children) {
rmr(path + "/" + child, zk); // 递归删除子节点
}
}
zk.delete(path, -1);
return true;
}
@Override
public boolean createZNode(String znodePath, String data, ZooKeeper zk) throws KeeperException, InterruptedException {
try {
if (!zk.exists(znodePath, false) == null) {
int lastSlash = znodePath.lastIndexOf('/');
String parentPath = znodePath.substring(0, lastSlash);
createZNode(parentPath, "", zk); // 递归创建父节点
}
zk.create(znodePath, data.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
return true;
} catch (NodeExistsException e) {
return false;
}
}
@Override
public boolean clearChildNode(String znodePath, ZooKeeper zk) throws KeeperException, InterruptedException {
List<String> children = zk.getChildren(znodePath, false);
for (String child : children) {
rmr(znodePath + "/" + child, zk); // 递归删除子节点
}
return true;
}
}接下来,我们创建一个测试类来验证上述方法的功能:
package com.mazh.nx.zookeeper.exercise;
import org.junit.jupiter.api.Test;
import java.util.Map;
import static org.junit.jupiter.api.Assertions.*;
class ZKHomeWorkImplTest {
@Test
void testZKHomeWorkMethods() throws Exception {
ZKHomeWork zkHomeWork = new ZKHomeWorkImpl();
// 测试创建节点
assertTrue(zkHomeWork.createZNode("/test", "Hello World", null));
// 测试获取节点及其子节点信息
Map<String, String> nodes = zkHomeWork.getChildNodeAndValue("/test");
assertEquals(1, nodes.size());
assertEquals("Hello World", nodes.get("/test"));
// 测试删除节点
assertTrue(zkHomeWork.rmr("/test", null));
// 测试清空子节点
assertTrue(zkHomeWork.createZNode("/test", "", null));
assertTrue(zkHomeWork.createZNode("/test/sub", "Sub Node", null));
assertTrue(zkHomeWork.clearChildNode("/test", null));
assertFalse(zkHomeWork.getChildNodeAndValue("/test").containsKey("/test/sub"));
}
}请注意,这个测试类使用了JUnit框架来进行单元测试。你需要确保你的项目中有JUnit依赖项才能运行这些测试。此外,在实际的测试环境中,你需要将CONNECT_STRING变量设置为指向实际运行中的ZooKeeper服务器的地址。
以上就是一个基本的接口实现和测试类的例子。你可以根据自己的需求调整代码以满足特定的应用场景。
ZooKeeper源码 -ZooKeeper 基础设施和集群启动源码剖析
1. 课程介绍
ZooKeeper 是一款世界级的优秀开源产品,在大数据生态系统中 Hadoop、Storm、HBase、Spark、Flink、Kafka 随处都是 ZooKeeper的应用场景。特别是在粗粒度分布式锁、分布式选主、主备高可用切换等不需要高 TPS 的场景下有不可替代的作用。如果用一句话来评价ZooKeeper 的话,一定是“The King Of Coordination for Big Data“。
2. 本次ZooKeeper内容大纲
Day01:ZooKeeper 基础设施和集群启动源码剖析
1、架构师级ZooKeeper总体架构设计深入剖析;
2、架构师级ZooKeeper基础设施源码深入剖析(序列化/持久化/网络通信/监听等核心机制)
3、架构师级ZooKeeper集群启动源码之集群启动流程深入剖析;
4、架构师级ZooKeeper集群启动源码之QuorumPeerMain启动深入剖析;
5、架构师级ZooKeeper集群启动源码之冷启动数据恢复等核心机制;3. ZooKeeper 基础设施和集群启动源码剖析
在看任何技术源码的时候,都首先要搞清楚两件事:
1、版本选择
2、环境准备3.1. ZooKeeper版本选择
你为什么需要看源码呢?两大看源码的需求支撑:
1、企业需求:你的项目遇到了困难,看源码解决
2、兴趣爱好 + 为了面试zookeeper的大版本:
1、zookeeper-3.4.x 企业最常用,大数据技术组件最常用,基本维持在 3.4.5 3.4.6 3.4.7 这几个版本
2、zookeeper-3.5.x
3、zookeeper-3.6.x最总结论:zookeeper-3.4.14.tar.gz,安装包就是源码包ZooKeeper-3.5 以上,源码 和 安装包就分开了
3.2. ZooKeeper源码环境准备
不需要过多的准备,准备一个 IDE,从官网下载源码包,然后直接用 IDE 打开即可!
1、准备一个IDE:IDEA
2、从官网下载源码包,IDEA去导入这个源码项目即可
3、稍微等待一下,maven去下载一些依赖jar下载源码的方式
1、从官网下载 zookeeper-3.4.14.tar.gz 安装包,该安装包直接包含源码
2、从 github 去拉取源码项目3.3. ZooKeeper序列化机制
到底在那些地方需要使用序列化技术呢
1、当在网络中需要进行消息,数据,等的传输,那么这些数据就需要进行序列化和反序列化
2、当数据需要被持久化到磁盘的时候。ZooKeeper(分布式协调服务组件 + 存储系统)
任何一个分布式系统的底层,都必然会有网络通信,这就必然要提供一个分布式通信框架和序列化机制。所以我们在看 ZooKeeper 源码之前,先搞定 ZooKeeper 网络通信和序列化。
1、Java序列化机制
特点就是比较笨重:(除了实例的属性信息以外,还会序列化这个实例的类型信息)
class Student implements Serializable使用 ObjectInputStream 和 ObjectOutputStream 来进行具体的序列化和反序列化。
2、Hadoop中的序列化:
class Student implements Writable{
// 反序列化
void readFields(DataIn input);
// 序列化
void write(DataOut output);
}3、ZooKeeper 中的序列化机制:
class Student implements Record {
// 反序列化
void deserialize(InputArchive archive, String tag) {
archive.readBytes();
archive.readInt();
}
// 序列化
void serialize(OutputArchive archive, String tag)
}一个自定义类的实现, 都是有多个普通数据类型的属性组成的!
class Student {
private int id;
private String name;
.....
}序列化的 API 主要在 zookeeper-jute 子项目中。
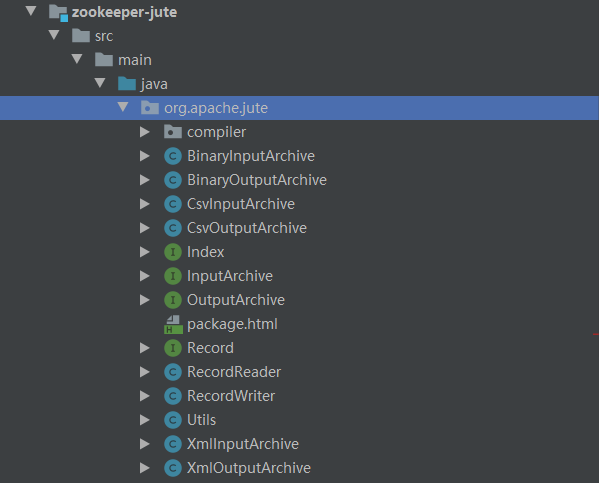
重点API:
org.apache.jute.InputArchive:反序列化需要实现的接口,其中各种 read 开头的方法,都是反序列化方法
实现类有:

org.apache.jute.OutputArchive:所有进行序列化操作的都是实现这个接口,其中各种 write 开头的方法都是序列化方法。
实现类有:

org.apache.jute.Index:用于迭代数据进行反序列化的迭代器实现类有:

org.apache.jute.Record:在 ZooKeeper 要进行网络通信的对象,都需要实现这个接口。里面有序列化和反序列化两个重要的方法
3.4. ZooKeeper持久化机制
ZooKeeper的数据模型主要涉及两类知识:数据模型 和 持久化机制ZooKeeper 本身是一个对等架构(内部选举,从所有 learner 中选举一个 leader, 剩下的成为follower)
1、每个节点上都保存了整个系统的所有数据(leader存储了数据,所有的follower节点都是leader的副本节点)
2、每个节点上的都把数据放在磁盘一份,放在内存一份ZooKeeper的数据模型,抽象出了重要的三个API用来完成数据的管理:
1、DataNode znode 系统中的一个节点的抽象
2、DataTree znode系统的完整抽象
3、ZKDataBase 负责管理 DataTree ,执行 DataTree 的相关 快照和恢复的操作关于 ZooKeeper 中的数据在内存中的组织,其实就是一棵树:
1、这棵树就叫做:DataTree (抽象了一棵树)
2、这棵树上的节点:DataNode (抽象一个节点)
3、关于管理这个 DataTree 的组件就是 ZKDataBase (内存数据库:针对 DataTree 能做各种操作)ZooKeeper 的持久化的一些操作接口,都在:org.apache.zookeeper.server.persistence 包中。
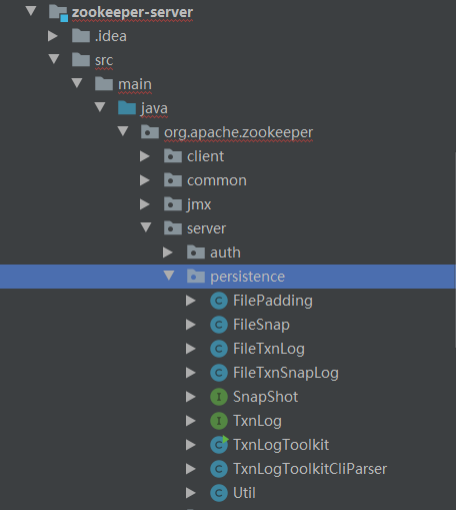
主要的类的介绍:
第一组: 主要是用来操作日志的( 如果客户端往zk中写入一条数据, 则记录一条日志)
TxnLog, 接口, 读取事务性日志的接口。
FileTxnLog, 实现TxnLog接口, 添加了访问该事务性日志的API。
第二组: 拍摄快照( 当内存数据持久化到磁盘)
Snapshot, 接口类型, 持久层快照接口。
FileSnap, 实现Snapshot接口, 负责存储、 序列化、 反序列化、 访问快照。
第三组; 两个成员变量: TxnLog和SnapShot
FileTxnSnapLog, 封装了TxnLog和SnapShot。
第四组: 工具类
Util, 工具类, 提供持久化所需的API。3.5. ZooKeeper网络通信机制
Java IO 有几个种类:(百度搜索;五种IO模型)
1、BIO JDK-1.1(编码简单,效率低) 阻塞模型
2、NIO JDK-1.4(效率有提升,编码复杂) 基于reactor实现的异步非阻塞网络通信模型
通常的IO的选择:
1、原生NIO
2、基于NIO实现的网络通信框架:netty
3、AIO JDK-1.7(效率最高,编码复杂度一般) 真正的异步非阻塞通信模型NIO 的三大API:
1、Buffer
2、Channel
3、SelectorZooKeeper 中的通信有两种方式:
1、NIO,默认使用NIO
2、Netty两个最重要的API:
ServerCnxn 服务端的通信组件
ClientCnxn 客户端的通信组件关于客户端和服务端的一个定义:谁发请求,谁就是客户端,谁接收和处理请求,谁就是服务
1、真正的client给zookeeper发请求
2、zookeeper中的leader给follower发命令
3、zookeeper中的followe给leader发请求ServerCnxn:org.apache.zookeeper.server.ServerCnxn
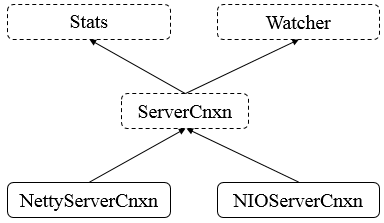
详细说明
Stats,表示ServerCnxn上的统计数据。
Watcher,表示事件处理,监听器
ServerCnxn,表示服务器连接,表示一个从客户端到服务器的连接。
ClientCnxn,存在于客户端用来执行通信的组件
NettyServerCnxn,基于Netty的连接的具体实现。
NIOServerCnxn,基于NIO的连接的具体实现。3.6. Zookeeper的Watcher工作机制
客户端的 Watcher 注册
1、org.apache.zookeeper.ZooKeeper:客户端基础类、存储了ClientCnxn和ZkWatcherManager
2、ZKWatchManager:ZooKeeper的内部类,实现了ClientWatchManager接口,主要用来存储各种类型的Watcher,主要有三种:dataWatches、existWatches、childWatches以及一个默认的defaultWatcher
3、org.apache.zookeeper.ClientCnxn:与服务端的交互类,主要包含以下对象:LinkedListoutgoingQueue、SendThread 和 EventThread,其中outgoingQueue未待发送给服务端的Packet列表,SendThread线程负责和服务端进行请求交互,而EventThread线程则负责客户端Watcher事件的回调执行
4、WatchRegistration:Zookeeper的内容类,包装了Watcher和clientPath,并且负责Watcher的注册
5、Packet:ClientCnxn的内部类,与Zookeeper服务端通信的交互类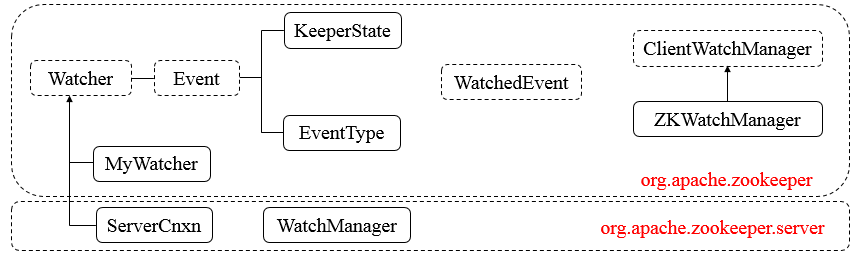
两条主线
1、实现主线:Watcher + WatchedEvent
2、管理主线:WatchManager(负责响应:watcher.process(watchedEvent))+ ZKWatchManager(负责注册等相关管理)interface Watcher {
interface Event {
enum KeeperState 链接状态
enum EventType 事件类型
}
// 这就是回调方法(触发的事件:KeeperState, znodePath, EventType)
void process(WatchedEvent event)
}
// 表示触发了一次监听事件的一个响应对象:链接状态 + znode节点路径 + 操作事件
class WatchedEvent {
KeeperState state 会话连接的状态信息
String path znode节点的绝对路劲
EventType type 事件的类型
}组件说明:
Watcher,接口类型,其定义了process方法,需子类实现。
Event,接口类型,Watcher的内部类,无任何方法。
KeeperState,枚举类型,Event的内部类,表示Zookeeper所处的状态。
EventType,枚举类型,Event的内部类,表示Zookeeper中发生的事件类型。
WatchedEvent,表示对ZooKeeper上发生变化后的反馈,包含了KeeperState和EventType。
ClientWatchManager,接口类型,表示客户端的Watcher管理者,其定义了materialized方法,需子类实现。
ZKWatchManager,Zookeeper的内部类,继承ClientWatchManager。
MyWatcher,ZooKeeperMain的内部类,继承Watcher。
ServerCnxn,接口类型,继承Watcher,表示客户端与服务端的一个连接。
WatchManager,管理Watcher。Watcher类组成:

WatchedEvent构成
Watcher 主要工作流程:
1. 用户调用 Zookeeper 的 getData 方法,并将自定义的 Watcher 以参数形式传入,该方法的作用主要是封装请求,然后调用 ClientCnxn 的 submitRequest 方法提交请求
2. ClientCnxn 在调用 submitRequest 提交请求时,会将 WatchRegistration(封装了我们传入的Watcher 和clientPath )以参数的形式传入,submitRequest 方法主要作用是将信息封装成Packet(ClientCnxn的内部类),并将封装好的 Packet 加入到 ClientCnxn 的待发送列表中
(LinkedList outgoingQueue)
3. SendThread 线程不断地从 outgoingQueue 取出未发送的 Packet 发送给客户端并且将该 Packet加入pendingQueue (等待服务器响应的Packet列表)中,并通过自身的 readResponse 方法接收服务端的响应
4. SendThread 接收到客户端的响应以后,会调用 ClientCnxn 的 finishPacket 方法进行 Watcher方法的注册
5. 在 finishPacket 方法中,会取出 Packet 中的 WatchRegistration 对象,并调用其 register 方法,从ZKWatchManager 取出对应的 ataWatches、existWatches 或者 childWatches 其中的一个Watcher 集合,然后将自己的 Watcher 添加到该 Watcher 集合中
3.7. ZooKeeper的集群启动脚本分析
第一个问题;到底哪些源码流程我们需要关注呢?
1、集群的启动
2、崩溃恢复(leader选举)+ 原子广播(状态同步)
3、读写请求第二个问题:到底从哪个地方入手看源码?入口
启动 ZooKeeper 的时候:
zkServer.sh start底层会转到调用:QuorumPeerMain.main()
具体实现:见文档:ZooKeeper 启动脚本分析
3.8. ZooKeeper的QuorumPeerMain启动
大致流程:
# 入口方法
QuorumPeerMain.main();
# 核心实现, 分三步走
QuorumPeerMain.initializeAndRun(args);
# 第一步; 解析配置
config = new QuorumPeerConfig();
config.parse(args[0]);
Properties cfg = new Properties();
cfg.load(in);
parseProperties(cfg);
# 第二步: 启动一个线程( 定时任务) 来执行关于old snapshot的clean
new DatadirCleanupManager(...).start()
timer = new Timer("PurgeTask", true);
TimerTask task = new PurgeTask(dataLogDir, snapDir,
snapRetainCount);
timer.scheduleAtFixedRate(task, 0,
TimeUnit.HOURS.toMillis(purgeInterval));
PurgeTxnLog.purge(new File(logsDir), new File(snapsDir), ...);
# 第三步: 启动( 有两种模式: standalone, 集群模式) 重点关注集群启动, 分两步走
runFromConfig(config);
# 服务端的通信组件 的初始化, 但是并未启动
factory = ServerCnxnFactory.createFactory();
cnxnFactory.configure(....)
# 抽象一个zookeeper节点, 然后把解析出来的各种参数给配置上, 然后启动
quorumPeer = getQuorumPeer(); + quorumPeer.setXXX() +
quorumPeer.start();
# 第一件事: 把磁盘数据恢复到内存
loadDataBase();
zkDb.loadDataBase();
# 冷启动的时候, 从磁盘恢复数据到内存
snapLog.restore(...., ....)
# 从快照恢复
snapLog.deserialize(dt, sessions);
# 从操作日志恢复
fastForwardFromEdits(dt, sessions, listener);
# 恢复执行一条事务
rocessTransaction(hdr, dt, sessions,
itr.getTxn());
# 第二件事: 服务端的通信组件的真正启动
cnxnFactory.start();
# 第三件事: 准备选举的一些必要操作(初始化一些队列和一些线程)
startLeaderElection();
# 第四件事: 调用 start() 跳转到 run() 方法。 因为 QuorumPeer被封装成
Thread 了
super.start();
# 执行选举
QuorumPeer.run()zoo.cfg 中的内容:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/bigdata/data/zkdata
dataLogDir=/home/bigdata/data/zklog/
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
electionAlg=3
maxClientCnxns=60
peerType=observer
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.2=bigdata02:2888:3888
server.3=bigdata03:2888:3888
server.4=bigdata04:2888:3888
server.5=bigdata05:2888:3888:observer3.9. ZooKeeper的冷启动数据恢复
入口方法:QuorumPeer.loadDataBase();
大致流程

4. 总结
今天讲述的内容,主要是:ZooKeeper的基础设施组件和集群启动源码剖析。