7.生产者是如何获取元数据的?
Kafka生产者获取元数据的过程是自动的,通常在以下几种情况下触发:
启动时:当生产者首次启动时,它会尝试从集群中的某个Broker(通常是配置文件中指定的
bootstrap.servers列表中的一个)获取初始元数据。主题或分区未知:如果生产者尝试发送消息到一个未知的主题或分区(即不在当前缓存的元数据中),它会自动发起一次元数据请求来获取最新的元数据信息。
元数据过期:Kafka生产者会定期刷新元数据(默认每5分钟),以确保使用的元数据是最新的。这个刷新间隔可以通过配置项
metadata.max.age.ms进行调整。Leader变更:如果Broker检测到某个分区的Leader发生变更,它会通知生产者更新元数据。
具体过程
以下是Kafka生产者获取元数据的具体步骤:
初始化:
生产者在启动时会连接到配置文件中指定的一个或多个Bootstrap Broker。
通过这些Bootstrap Broker,生产者可以发现集群中的其他Broker,并获取集群的基本信息。
发送元数据请求:
当需要获取元数据时,生产者会构造一个
MetadataRequest并将其发送给其中一个Bootstrap Broker。MetadataRequest中可以包含需要获取元数据的主题列表。如果为空,则表示请求所有主题的元数据。
接收元数据响应:
Bootstrap Broker接收到
MetadataRequest后,会返回一个MetadataResponse。MetadataResponse包含了集群中所有主题的详细信息,包括每个主题的分区、每个分区的Leader Broker、ISR (In-Sync Replicas) 列表等。
更新内部状态:
生产者接收到
MetadataResponse后,会更新其内部的元数据缓存。更新后的元数据缓存会被用于后续的消息路由决策,确保消息能够被正确地发送到相应的Broker和分区。
处理错误:
如果在获取元数据的过程中遇到网络问题或其他错误,生产者会根据配置的重试策略进行重试。
如果多次重试仍然失败,生产者可能会抛出异常或记录错误日志。
配置项
bootstrap.servers:指定一组初始Broker地址,生产者通过这些地址连接到Kafka集群。metadata.max.age.ms:设置元数据的最大有效期。超过这个时间,即使没有变化也会强制刷新元数据。request.timeout.ms:设置元数据请求的超时时间。retries:设置重试次数,用于在网络问题或其他错误情况下的重试。
示例代码
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 创建生产者实例
Producer<String, String> producer = new KafkaProducer<>(props);
// 发送消息
producer.send(new ProducerRecord<>("my-topic", "key", "value"));
// 关闭生产者
producer.close();在这个示例中,生产者会在启动时自动从localhost:9092获取元数据,并在需要时自动刷新元数据。
通过这种方式,Kafka生产者能够动态地获取和更新元数据,确保消息能够被正确地发送到集群中的相应Broker和分区。
元数据的获取对生产者有什么用呢?比如,主题迁移到别的服务端节点,这时生产者需要及时知道主题都分布在哪些服务端节点上,不然向错误的服务端节点发送消息会失败,所以及时的元数据获取对生产者正常工作是很有必要的。
元数据的获取涉及到的组件是比较多的,大致分为:主线程KafkaProducer负责的加载元数据、子线程Sender负责的拉取元数据。
确实,元数据的获取对Kafka生产者来说是非常重要的,它确保了消息能够被正确地路由到集群中的适当Broker和分区。以下是元数据获取的具体用途以及涉及的主要组件:
元数据获取的用途
主题和分区信息:
生产者需要知道每个主题有哪些分区,以便将消息均匀地分配到各个分区中。
通过元数据,生产者可以了解每个分区的Leader Broker,从而将消息直接发送到正确的Broker。
Leader Broker信息:
每个分区都有一个Leader Broker,负责处理该分区的所有读写请求。
如果某个分区的Leader发生变更(例如由于Broker故障或重新平衡),生产者需要及时更新元数据以确保消息能够发送到新的Leader。
ISR (In-Sync Replicas) 列表:
ISR列表包含了与Leader保持同步的所有副本Broker。
生产者可以通过ISR列表来判断某个分区的可用性和可靠性。
Broker地址:
元数据提供了所有Broker的地址信息,使得生产者能够在启动时连接到集群,并在后续操作中选择合适的Broker进行通信。
错误处理和重试:
如果生产者尝试向一个不可达的Broker发送消息,元数据可以帮助生产者快速识别问题并选择其他可用的Broker进行重试。
主要组件及其职责
1. KafkaProducer(主线程)
初始化:当创建
KafkaProducer实例时,它会初始化一些内部组件,包括Metadata对象。加载元数据:
KafkaProducer会在首次发送消息之前尝试从配置的bootstrap.servers获取初始元数据。触发元数据刷新:如果生产者尝试发送消息到未知的主题或分区,或者元数据过期,
KafkaProducer会触发元数据刷新。
2. Sender(子线程)
定期刷新元数据:
Sender线程会定期(默认每5分钟)检查元数据是否过期,并在必要时发起元数据请求。拉取元数据:
Sender通过调用NetworkClient发送MetadataRequest到Broker,并接收MetadataResponse来更新元数据缓存。处理响应:
Sender处理来自Broker的元数据响应,并更新内部的元数据缓存。异常处理:如果在获取元数据的过程中遇到网络问题或其他错误,
Sender会根据配置的重试策略进行重试。
示例流程
初始化:
创建
KafkaProducer实例时,初始化Metadata对象。KafkaProducer尝试从bootstrap.servers获取初始元数据。
发送消息:
当调用
send()方法时,KafkaProducer会将消息放入RecordAccumulator。Sender线程会从RecordAccumulator中拉取消息,并准备发送。
元数据检查:
Sender检查当前的元数据是否包含目标主题和分区的信息。如果缺少相关信息或元数据已过期,
Sender会发起元数据请求。
元数据请求:
Sender通过NetworkClient发送MetadataRequest到Broker。NetworkClient等待并接收MetadataResponse。
更新元数据:
Sender处理MetadataResponse,更新内部的元数据缓存。更新后的元数据用于后续的消息路由决策。
发送消息:
使用最新的元数据信息,
Sender将消息发送到正确的Broker和分区。
通过这种方式,Kafka生产者能够动态地获取和更新元数据,确保消息能够被正确地发送到集群中的相应Broker和分区。这不仅提高了系统的可靠性和性能,还减少了因元数据不准确导致的消息发送失败的情况。
加载元数据
首先,我们先学习主线程是如何加载元数据的。
元数据一开始初始化的时候是在KafkaProducer主流程里,你可以看一下相关源代码:
KafkaProducer(Map<String, Object> configs,
Serializer<K> keySerializer,
Serializer<V> valueSerializer,
ProducerMetadata metadata,
KafkaClient kafkaClient,
ProducerInterceptors<K, V> interceptors,
Time time) {
......忽略
if (metadata != null) {
this.metadata = metadata;
} else {
、 //初始化MetaData
this.metadata = new ProducerMetadata(retryBackoffMs,
//元数据过期时间:默认5分钟
config.getLong(ProducerConfig.METADATA_MAX_AGE_CONFIG),
config.getLong(ProducerConfig.METADATA_MAX_IDLE_CONFIG),
logContext,
clusterResourceListeners,
Time.SYSTEM);
//启动metadata的引导程序
this.metadata.bootstrap(addresses);
}
......忽略
}
在KafkaProducer的构造方法中初始化了元数据类MetaData,然后启动metadata.bootstrap的引导程序,这个时候metaData对象里并没有具体的元数据信息,因为客户端还没发送元数据更新的请求。
下图是Metadata类以及Metadata类相关的类。
Metadata类是元数据类,里面封装了元数据的具体信息以及元数据的版本控制、更新等方法。
元数据的信息保存在MetadataCache里,MetadataCache里最核心信息是Cluster,保存了元数据的基础信息。
ProducerMetadata和ConsumerMetadata是Metadata类的两个子类。ConsumerMetadata我会在后面消费者模块给你讲解,其他的类这节课都有涉及。
Metadata类
这个类封装了元数据具体的数据和元数据的操作,会被生产端的主线程和Sender子线程使用,所以它是个线程安全的类。元数据类仅仅维护着主题子集的相关元数据,并不是全部的主题元数据,这样的好处是能够减少网络传输的数据量,如果集群中有几千个主题网络传输的量肯定是惊人的,生产者只获取自己发送的主题集合的元数据就可以了。同时,如果有一个新的主题需要发送会触发元数据请求。
介绍源码之前,我们先了解下元数据请求和响应的字段。
元数据的请求。对应类MetadataRequest。MetadataRequest请求的格式比较简单,消息体包含了要获取相关元数据的Topic集合。如果Topic集合为Null,就意味着要请求全部的Topic元数据。
元数据的响应。对应类MetadataResponse。MetadataResponse的结构比较复杂,如下图所示:
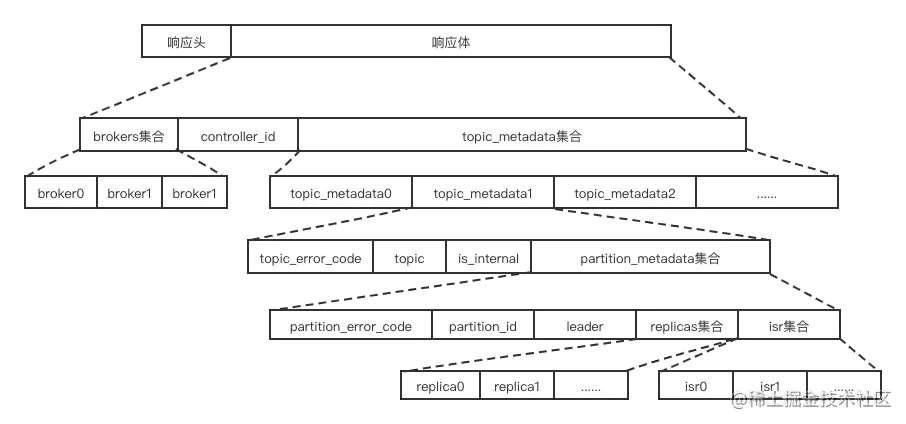
其每个字段的含义我汇总到了下面的列表里:
为了更好地了解源码,我们还是需要讲解下Metadata类的相关字段和方法。
字段
public class Metadata implements Closeable {
private final Logger log;
private final long refreshBackoffMs;//请求退避时间,默认100ms
private final long metadataExpireMs;//元数据过期时间,默认5分钟
private int updateVersion; // 每次更新元数据时加一
private int requestVersion; // 每次添加一个新的主题都会加一
private long lastRefreshMs;//最后一次更新时间
private long lastSuccessfulRefreshMs;//最后一次成功更新时间戳
private Set<String> invalidTopics;//无效的主题
private Set<String> unauthorizedTopics;//没有权限的主题
private MetadataCache cache = MetadataCache.empty();//元数据
private boolean needFullUpdate;//是否需要全部主题更新
private boolean needPartialUpdate;//是否需要部分主题更新
这些字段的含义和关键点如下。
refreshBackoffMs:请求元数据失败重试间隔时间,默认100ms。metadataExpireMs:元数据过期时间,默认5分钟,过期时间一到就会发送更新元数据的请求。updateVersion:生产者本地内存元数据版本,每次从服务端获取到元数据就加1。requestVersion:每次元数据要加入新的主题都会加一。lastRefreshMs:最后一次更新元数据的时间。lastSuccessfulRefreshMs:最后一次成功更新全部主题元数据的时间。invalidTopics:无效的主题集合。unauthorizedTopics:没有权限的主题集合。cache:MetadataCache 类对象。元数据缓存,客户端真正存储元数据的对象。needFullUpdate:是否需要全部主题的更新。对应生产者,这里的整体是指生产者最近发送的主题集合。needPartialUpdate:是否部分主题更新。对于生产者,这里的部分主题指新发送的主题。
方法
下面再来解析Metadata类重要方法的源代码。
bootstrap(),这个方法是引导方法,负责在第一次使用前的一些初始化工作。
public synchronized void bootstrap(List<InetSocketAddress> addresses) {
this.needFullUpdate = true;
this.updateVersion += 1;
this.cache = MetadataCache.bootstrap(addresses);
}
因为是生产者刚启动,本地缓存中的元数据是空的,所以是否全部主题更新赋为true。版本更新为1。最后,初始化元数据缓存。你可以看一下元数据缓存的初始化代码:
static MetadataCache bootstrap(List<InetSocketAddress> addresses) {
Map<Integer, Node> nodes = new HashMap<>();
int nodeId = -1;
for (InetSocketAddress address : addresses) {
nodes.put(nodeId, new Node(nodeId, address.getHostString(), address.getPort()));
nodeId--;
}
return new MetadataCache(null, nodes, Collections.emptyList(),
Collections.emptySet(), Collections.emptySet(), Collections.emptySet(),
null, Cluster.bootstrap(addresses));
}
因为还没获取到元数据,这时的元数据缓存都是空的数据和集合组成。
向服务器请求元数据在元数据更新器中,元数据类只有解析响应的方法,我们就先看看元数据类是如何解析的,这里又涉及到两个方法——update()和handleMetadataResponse()。
确实,Metadata类在Kafka生产者中扮演着重要的角色,负责管理和更新集群的元数据信息。让我们详细解析一下你提到的方法和相关代码。
bootstrap() 方法
bootstrap()方法是用于初始化元数据缓存的引导方法。这个方法通常在生产者启动时调用,确保在首次使用之前完成必要的初始化工作。
public synchronized void bootstrap(List<InetSocketAddress> addresses) {
this.needFullUpdate = true; // 标记需要完整的元数据更新
this.updateVersion += 1; // 更新版本号
this.cache = MetadataCache.bootstrap(addresses); // 初始化元数据缓存
}this.needFullUpdate = true;:设置标志位,表示需要一次完整的元数据更新。this.updateVersion += 1;:增加更新版本号,以便跟踪元数据的变化。this.cache = MetadataCache.bootstrap(addresses);:初始化元数据缓存,传入初始的Bootstrap Broker地址列表。
MetadataCache.bootstrap() 方法
MetadataCache.bootstrap()方法用于创建一个初始的、空的元数据缓存对象。
static MetadataCache bootstrap(List<InetSocketAddress> addresses) {
Map<Integer, Node> nodes = new HashMap<>();
int nodeId = -1;
for (InetSocketAddress address : addresses) {
nodes.put(nodeId, new Node(nodeId, address.getHostString(), address.getPort()));
nodeId--;
}
return new MetadataCache(null, nodes, Collections.emptyList(),
Collections.emptySet(), Collections.emptySet(), Collections.emptySet(),
null, Cluster.bootstrap(addresses));
}Map<Integer, Node> nodes:创建一个节点映射,其中键是节点ID(这里使用负数作为临时ID),值是Node对象,包含主机名和端口。Collections.emptyList()和Collections.emptySet():创建空的集合,用于存储主题、分区等信息。Cluster.bootstrap(addresses):创建一个初始的集群对象,包含Bootstrap Broker地址列表。
update() 方法
update()方法用于处理从Broker接收到的元数据响应,并更新本地的元数据缓存。
public synchronized void update(Cluster cluster, long now) {
if (cluster == null || !this.needFullUpdate && this.updateVersion != cluster.version()) {
return;
}
this.cache = new MetadataCache(cluster, now);
this.needFullUpdate = false;
this.lastSuccessfulUpdate = now;
this.lastSuccessfulVersion = cluster.version();
this.updateVersion = cluster.version() + 1;
log.debug("Updated cluster metadata version {} to {}", this.lastSuccessfulVersion, this.updateVersion);
}检查是否需要更新:如果接收到的
cluster为空或不需要完整更新且版本不匹配,则直接返回。更新元数据缓存:创建新的
MetadataCache对象,并更新当前缓存。重置标志位:将
needFullUpdate设为false,表示不再需要完整的更新。记录最后成功更新的时间和版本:更新
lastSuccessfulUpdate和lastSuccessfulVersion。增加更新版本号:增加
updateVersion,以便跟踪最新的元数据版本。
handleMetadataResponse() 方法
handleMetadataResponse()方法用于处理从Broker接收到的元数据响应,并更新元数据缓存。
public synchronized void handleMetadataResponse(MetadataResponse response, long now) {
Errors error = response.error();
switch (error) {
case NONE:
// 处理正常的元数据响应
this.update(response.cluster(), now);
break;
case LEADER_NOT_AVAILABLE:
// 领导者不可用
log.warn("Error while fetching metadata with correlation id {}: {}", response.requestHeader().correlationId(), error.message());
this.needFullUpdate = true; // 标记需要完整的元数据更新
break;
case GROUP_AUTHORIZATION_FAILED:
case CLUSTER_AUTHORIZATION_FAILED:
case TOPIC_AUTHORIZATION_FAILED:
// 授权失败
throw new KafkaException(error.message());
default:
// 其他错误
log.warn("Error while fetching metadata with correlation id {}: {}", response.requestHeader().correlationId(), error.message());
this.needFullUpdate = true; // 标记需要完整的元数据更新
break;
}
}检查响应中的错误:根据响应中的错误类型进行不同的处理。
Errors.NONE:表示没有错误,正常处理元数据响应并更新缓存。Errors.LEADER_NOT_AVAILABLE:领导者不可用,标记需要完整的元数据更新。授权失败:抛出异常,因为这是客户端无法解决的问题。
其他错误:记录日志并标记需要完整的元数据更新。
通过这些方法,Metadata类能够有效地管理Kafka集群的元数据,确保生产者能够在正确的时间向正确的Broker发送消息。这种机制保证了系统的可靠性和性能。
update()方法具体情况:
public synchronized void update(int requestVersion, MetadataResponse response, boolean isPartialUpdate, long nowMs) {
Objects.requireNonNull(response, "Metadata response cannot be null");
if (isClosed())
throw new IllegalStateException("Update requested after metadata close");
//1.判断是否是部分主题更新,以及更新几个字段
this.needPartialUpdate = requestVersion < this.requestVersion;
this.lastRefreshMs = nowMs;
this.updateVersion += 1;
if (!isPartialUpdate) {
this.needFullUpdate = false;
this.lastSuccessfulRefreshMs = nowMs;
}
String previousClusterId = cache.clusterResource().clusterId();
//2.解析元数据响应
this.cache = handleMetadataResponse(response, isPartialUpdate, nowMs);
......忽略
}
可分析为如下。
根据requestVersion参数和元数据里的requestVersion比较判断是否是更新部分主题的响应。如果是更新全部主题的响应,说明更新全部主题的响应已经收到了,首先把needFullUpdate标记为零,目的是不要再更新全部主题了,然后把lastSuccessfulRefreshMs 更新为当前时间。
解析响应,并缓存。
我们接下来解析下元数据响应的解析方法handleMetadataResponse()。
handleMetadataResponse(),该方法解析元数据并根据元数据实例化新的MetadataCache对象。
private MetadataCache handleMetadataResponse(MetadataResponse metadataResponse, boolean isPartialUpdate, long nowMs) {
// All encountered topics.
Set<String> topics = new HashSet<>();
// 1.初始化相关集合Retained topics to be passed to the metadata cache.
Set<String> internalTopics = new HashSet<>();
Set<String> unauthorizedTopics = new HashSet<>();
Set<String> invalidTopics = new HashSet<>();
List<MetadataResponse.PartitionMetadata> partitions = new ArrayList<>();
//2.轮询响应中的主题元数据。
for (MetadataResponse.TopicMetadata metadata : metadataResponse.topicMetadata()) {
topics.add(metadata.topic());
//3.判断是否保留主题元数据。
if (!retainTopic(metadata.topic(), metadata.isInternal(), nowMs))
continue;
//4.判断是否是内部主题。
if (metadata.isInternal())
internalTopics.add(metadata.topic());
//5.如果元数据响应没有错误就更新本地元数据缓存
if (metadata.error() == Errors.NONE) {
//6.遍历分区信息
for (MetadataResponse.PartitionMetadata partitionMetadata : metadata.partitionMetadata()) {
updateLatestMetadata(partitionMetadata, metadataResponse.hasReliableLeaderEpochs())
.ifPresent(partitions::add);
//分区数据有问题
if (partitionMetadata.error.exception() instanceof InvalidMetadataException) {
log.debug("Requesting metadata update for partition {} due to error {}",
partitionMetadata.topicPartition, partitionMetadata.error);
//标记需要更新元数据
requestUpdate();
}
}
//如果元数据响应有错误
} else {
//无效元数据异常
if (metadata.error().exception() instanceof InvalidMetadataException) {
log.debug("Requesting metadata update for topic {} due to error {}", metadata.topic(), metadata.error());
//标记需要更新元数据
requestUpdate();
}
//如果是无效主题的错误
if (metadata.error() == Errors.INVALID_TOPIC_EXCEPTION)
invalidTopics.add(metadata.topic());
//如果是无权限主题的错误
else if (metadata.error() == Errors.TOPIC_AUTHORIZATION_FAILED)
unauthorizedTopics.add(metadata.topic());
}
}
//8.如果是部分主题的响应就和现在的元数据缓存整合在一起,如果不是就重建元数据缓存对象
Map<Integer, Node> nodes = metadataResponse.brokersById();
if (isPartialUpdate)
return this.cache.mergeWith(metadataResponse.clusterId(), nodes, partitions,
unauthorizedTopics, invalidTopics, internalTopics, metadataResponse.controller(),
(topic, isInternal) -> !topics.contains(topic) && retainTopic(topic, isInternal, nowMs));
else
return new MetadataCache(metadataResponse.clusterId(), nodes, partitions,
unauthorizedTopics, invalidTopics, internalTopics, metadataResponse.controller());
}
给你讲解下主流程方法的步骤:
初始化相关集合,包括内部主题集合、无效主题集合、无权限主题集合。
按主题维度轮询元数据响应。
判断是否保留这个主题,因为有可能主题过期了等原因造成没有必要保留这个主题。
判断是否是内部主题,如果是内部主题就放入内部主题集合。
如果主题相关元数据没有error,就开始解析响应。
遍历主题下的分区信息,把分区信息更新到元数据缓存。同时会对异常做处理,如果分区有无效的元数据异常则要打出相应的日志,同时做好需要更新元数据的标记,提醒 Sender 线程去更新元数据。
如果主题元数据有error,则会对不同的error分别做处理。
如果是无效元数据的error,就做好需要更新元数据的标记,提醒 Sender 线程去更新元数据。
如果是无效主题的error,就把主题放入无效主题集合里。
如果是无权限的主题,就把主题放入无权限主题集合里。
如果是部分主题的响应,就和现在的元数据缓存整合在一起,如果不是就重建元数据。
MetaData类是元数据处理的基础,但对于生产者来说还不能满足生产端对元数据的处理需求,还需要MetaData类的子类ProducerMetadata类来进一步满足了生产者对元数据的处理需求。
ProducerMetadata类
我们来分析一下ProducerMetadata类的源码,同样还是从字段和方法维度来分析。
字段
public class ProducerMetadata extends Metadata {
/*
* 主题和主题对应的过期时间。5分钟过期,nowMs+5分钟。
* 这个集合是比较新的主题,过了期就认为不新了,会被删除
* */
private final Map<String, Long> topics = new HashMap<>();
//新的主题集合
private final Set<String> newTopics = new HashSet<>();
public class ProducerMetadata extends Metadata {
private final Map<String, Long> topics = new HashMap<>();
private final Set<String> newTopics = new HashSet<>();
topics:类型是map集合,生产者的刷新主题集合,保存着主题和主题过期时间的对应关系。刷新主题集合的作用是,当5分钟元数据过期,我们要向服务端更新元数据时,我们仅仅需要这个集合里的主题对应的元数据,这样就能大大减少响应的数据量。newTopics:第一次发送的主题会进入这个集合。
重要方法
add() 这个方法的作用是向生产者元数据缓存添加主题。
public synchronized void add(String topic, long nowMs) {
Objects.requireNonNull(topic, "topic cannot be null");
if (topics.put(topic, nowMs + metadataIdleMs) == null) {
newTopics.add(topic);
requestUpdateForNewTopics();
}
}
具体步骤是:往刷新主题集合里添加这个主题及对应的过期时间(当前时间+过期时间段,默认5分钟)。如果集合中原来并不存在这个主题,就再把这个主题放到新主题集合里,然后标记要更新新主题元数据的标记,等待后续Sender线程去请求服务端获取新主题的元数据。
那么刷新主题集合里的数据过期了会如何处理呢?我们接下来再了解下retainTopic()方法。
retainTopic() 这个方法的作用是否元数据中保留这个主题。当解析到元数据响应的时候会调用这个方法。
public synchronized boolean retainTopic(String topic, boolean isInternal, long nowMs) {
Long expireMs = topics.get(topic);
if (expireMs == null) {
return false;
} else if (newTopics.contains(topic)) {
return true;
} else if (expireMs <= nowMs) {
log.debug("Removing unused topic {} from the metadata list, expiryMs {} now {}", topic, expireMs, nowMs);
topics.remove(topic);
return false;
} else {
return true;
}
}
首先在刷新主题集合中找这个主题,如果不存在,说明本来就不在刷新主题集合,就直接返回false。如果在新主题集合里存在这个主题就返回true。
如果超出了过期时间,就从刷新主题集合删除这个主题,说明这个主题很久没有发送消息了,这样在请求元数据时就不用带上这个主题,从而减少了网络传输的数据大小。
update() 方法,生产端更新元数据缓存的方法。
public synchronized void update(int requestVersion, MetadataResponse response, boolean isPartialUpdate, long nowMs) {
super.update(requestVersion, response, isPartialUpdate, nowMs);
// 找出已获得相关元数据的相关主题,并从新主题集合中删除
if (!newTopics.isEmpty()) {
for (MetadataResponse.TopicMetadata metadata : response.topicMetadata()) {
newTopics.remove(metadata.topic());
}
}
notifyAll();
}
先调用父类update()方法,然后遍历响应的主题并从newTopics中删除,最后通过调用notifyAll()唤醒等待元数据更新完成而阻塞的线程。
那notifyAll()唤醒的是什么操作呢?这就引出了下面我要讲解的awaitUpdate()。
awaitUpdate() 方法,当生产者主线程发现没有主题对应的元数据时,主线程会等待sender线程把元数据更新完成。你可以看一下下面的相关源码:
public synchronized void awaitUpdate(final int lastVersion, final long timeoutMs) throws InterruptedException {
long currentTimeMs = time.milliseconds();
long deadlineMs = currentTimeMs + timeoutMs < 0 ? Long.MAX_VALUE : currentTimeMs + timeoutMs;
time.waitObject(this, () -> {
maybeThrowFatalException();
return updateVersion() > lastVersion || isClosed();
}, deadlineMs);
if (isClosed())
throw new KafkaException("Requested metadata update after close");
}
这个方法主要是调用time.waitObject()实现了线程阻塞的功能,time.waitObject()底层通过调用Object.wait()方法实现了线程的阻塞。代码如下:
public void waitObject(Object obj, Supplier<Boolean> condition, long deadlineMs) throws InterruptedException {
synchronized (obj) {
while (true) {
//检查更新是否成功,成功后直接返回
if (condition.get())
return;
long currentTimeMs = milliseconds();
if (currentTimeMs >= deadlineMs)
throw new TimeoutException("Condition not satisfied before deadline");
//调用wait()阻塞线程
obj.wait(deadlineMs - currentTimeMs);
}
}
}
当每次元数据响应后元数据处理成功时,会唤醒阻塞的线程然后检查获取的元数据版本是否大于现在的元数据版本,即检查是否元数据更新成功。如果元数据更新成功或生产者关闭了,就解除阻塞;如果没有更新成功,就继续阻塞直到阻塞超时。
好了,元数据管理介绍完了,接下来介绍元数据加载。
元数据同步等待
我们先看一下,主线程类KafkaProducer是如何等待元数据的更新的,源码如下:
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
try {
throwIfProducerClosed();
long nowMs = time.milliseconds();
ClusterAndWaitTime clusterAndWaitTime;
try {
//1.等待元数据更新
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), nowMs, maxBlockTimeMs);
} catch (KafkaException e) {
if (metadata.isClosed())
throw new KafkaException("Producer closed while send in progress", e);
throw e;
}
nowMs += clusterAndWaitTime.waitedOnMetadataMs;
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);
......忽略
生产者主线程在发送消息前先获取元数据,这样才能知道消息要发送到哪里。通过调用waitOnMetadata()方法获取元数据和获取元数据消耗的时间,为下面的发送消息提供数据支持。
我们也具体看一下 waitOnMetadata() 方法的源码:
private ClusterAndWaitTime waitOnMetadata(String topic, Integer partition, long nowMs, long maxWaitMs) throws InterruptedException {
// add topic to metadata topic list if it is not there already and reset expiry
// 1.获取元数据
Cluster cluster = metadata.fetch();
//判断是否是无效的缓存
if (cluster.invalidTopics().contains(topic))
throw new InvalidTopicException(topic);
//2.把主题放入元数据主题列表
metadata.add(topic, nowMs);
//3.从元数据中找到主题对应的分区数。
Integer partitionsCount = cluster.partitionCountForTopic(topic);
// 4.如果客户端缓存中的元数据能找到消息发送对应分区,就不用去服务端请求更新元数据了,直接返回从生产者缓存中的元数据
// 这里会拦截住大部分的消息发送。
// 如果消息的主题有对应的分区,而且消息的分区没有设置或消息指定的发送分区在已知分区范围。就认为
// 生产者元数据缓存中有对应的主题分区,这时就不用再请求最新的元数据了。直接用现在的元数据缓存
if (partitionsCount != null && (partition == null || partition < partitionsCount))
return new ClusterAndWaitTime(cluster, 0);
long remainingWaitMs = maxWaitMs;
long elapsed = 0;
// 5.轮询不断要求Sender更新元数据。
do {
if (partition != null) {
log.trace("Requesting metadata update for partition {} of topic {}.", partition, topic);
} else {
log.trace("Requesting metadata update for topic {}.", topic);
}
//6.把主题和过期时间加入元数据主题列表中
metadata.add(topic, nowMs + elapsed);
//7.标记元数据需要更新,并获得版本
int version = metadata.requestUpdateForTopic(topic);
//8.唤醒sender线程。
sender.wakeup();//因为send()和poll()方法的调用都在sender线程里,需要中断seletor()的阻塞及时把元数据的请求发送出去。
try {
//9.阻塞线程。
metadata.awaitUpdate(version, remainingWaitMs);
} catch (TimeoutException ex) {
throw new TimeoutException(
String.format("Topic %s not present in metadata after %d ms.",
topic, maxWaitMs));
}
//10.获取元数据
cluster = metadata.fetch();
//11.计算等待更新元数据消耗了多少时间。
elapsed = time.milliseconds() - nowMs;
//12.超时抛出异常。
if (elapsed >= maxWaitMs) {
throw new TimeoutException(partitionsCount == null ?
String.format("Topic %s not present in metadata after %d ms.",
topic, maxWaitMs) :
String.format("Partition %d of topic %s with partition count %d is not present in metadata after %d ms.",
partition, topic, partitionsCount, maxWaitMs));
}
metadata.maybeThrowExceptionForTopic(topic);
remainingWaitMs = maxWaitMs - elapsed;
//13.获取元数据分区数
partitionsCount = cluster.partitionCountForTopic(topic);
} while (partitionsCount == null || (partition != null && partition >= partitionsCount));
//14.返回获取的元数据和更新元数据耗费的时间
return new ClusterAndWaitTime(cluster, elapsed);
}
方法步骤可梳理为如下。
获取生产者缓存的元数据,判断主题是否是有效主题,如果不是有效主题就放入无效主题集合里。
把主题放入元数据主题列表里。Sender线程会定时请求服务端更新主题列表里相关元数据。
从生产端缓存的元数据中找到主题对应的分区数。
判断生产端缓存的元数据是否能满足这次发送的需要,判断标准是主题对应的分区数不能为零且指定分区id小于分区数,总的来说就是能够找到要发送消息的主题分区。
轮询不断要求Sender更新元数据,直到获得主题及分区信息或获取元数据阻塞时间超时。解决两个问题:主题的分区数量增加了;元数据版本旧。
把主题和过期时间加入元数据主题列表中。
通过标记元数据需要Sender线程更新,并获得当前元数据的版本号。
唤醒Sender后台子线程。Sender线程一直都是运行的,唤醒的目的是让Sender线程从select()阻塞中立即返回,然后把获取元数据channel的网络事件注册在selector上,这样就可以及时监听获取元数据的网络事件了。
阻塞主线程,等待Sender线程完成更新元数据。
Sender子线程更新成功或阻塞超时唤醒主线程的阻塞,主线程获取内存中的元数据。
计算获取元数据耗时多久。
如果耗时大于最大等待时间(默认1分钟)就抛出超时异常。
获取发送主题的分区数。
判断while继续轮询的条件,判断规则是满足下面两个条件中的一个即可:
从元数据中得到的发送主题的分区数为空;
分区不为空且要发送的分区数大于主题分区数。
这个方法涵盖整个元数据加载流程,流程比较复杂,我在下方画了一个流程图,希望能够帮助你理解:
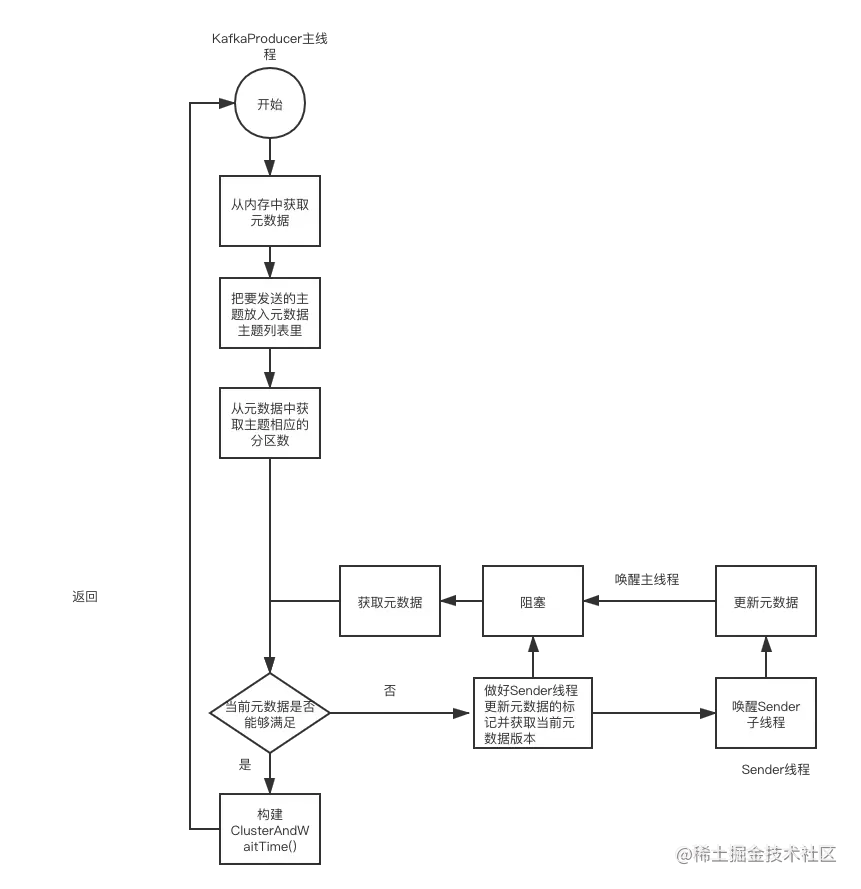
好了,元数据加载我们学习完了,下面学习元数据的拉取流程。
拉取元数据
拉取元数据是Sender子线程负责的工作,具体是调用Sender类的组件NetworkClient的poll()方法,源码在下面:
public List<ClientResponse> poll(long timeout, long now) {
ensureActive();
if (!abortedSends.isEmpty()) {
List<ClientResponse> responses = new ArrayList<>();
handleAbortedSends(responses);
completeResponses(responses);
return responses;
}
//1.尝试更新元数据
long metadataTimeout = metadataUpdater.maybeUpdate(now);
这里涉及到了元数据更新器的组件,下面是元数据更新类的类图关系:
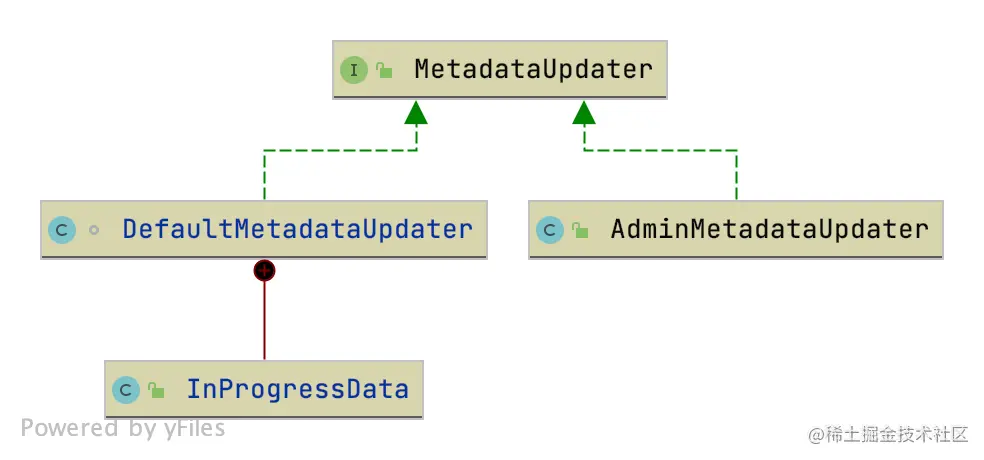 MetadataUpdater是元数据更新操作的接口,AdminMetadataUpdater类是MetadataUpdater在后台管理的实现,元数据更新接口在客户端的实现是DefaultMetadataUpdater类。
MetadataUpdater是元数据更新操作的接口,AdminMetadataUpdater类是MetadataUpdater在后台管理的实现,元数据更新接口在客户端的实现是DefaultMetadataUpdater类。
下面我主要讲解DefaultMetadataUpdater类在客户端的应用。
类DefaultMetadataUpdater
DefaultMetadataUpdater是NetworkClient的内部类。这里我们主要学习下这个类的方法。
maybeUpdate(long now),这个方法用于正式发送元数据请求前的判断,主要是判断发送元数据请求的时机,源代码和注释如下:
public long maybeUpdate(long now) {
// should we update our metadata?
// 1.下次更新的时间
long timeToNextMetadataUpdate = metadata.timeToNextUpdate(now);
// 2.检测是否已经发送了MetadataRequest请求
long waitForMetadataFetch = hasFetchInProgress() ? defaultRequestTimeoutMs : 0;
long metadataTimeout = Math.max(timeToNextMetadataUpdate, waitForMetadataFetch);
if (metadataTimeout > 0) {
return metadataTimeout;
}
//找到最小负载的node。
Node node = leastLoadedNode(now);
//没有node就
if (node == null) {
log.debug("Give up sending metadata request since no node is available");
return reconnectBackoffMs;
}
return maybeUpdate(now, node);
}
首先我们需要计算两个时间戳:
根据当前时间计算下一次 MetaData 更新的时间戳;
根据退避时间(防止服务端连接过于频繁而设置的一个间隔时间)计算下一次重新连接服务器端的时间戳。
然后取这两个时间戳的最大值,作为 metaData 超时时间(metadataTimeout)。同时还要考虑客户端是不是已经发送了更新元数据的请求,如果发送了,返回值就是Integer.MAX_VALUE。如果当metaData 超时时间为 0,也就是 metadataTimeout == 0,这时从 Broker 中找到一个负载最小的节点。这里的负载大小是通过每个Node在InFlightRequests队列中未收到响应的请求决定的,未收到响应的请求越多则认为负载越大。然后设置到把当前时间和找到的节点当作参数调用无返回值的 maybeUpdate(now, node)。
maybeUpdate(long now, Node node),这个方法的功能是向节点发送元数据请求,和普通请求一样,先将请求放入InFlightRequests队列中,然后设置到KafkaChannel的send字段中。我们来看一下具体的发送过程,代码如下所示:
private long maybeUpdate(long now, Node node) {
String nodeConnectionId = node.idString();
// 1.判断是否能够向这个node发送请求
if (canSendRequest(nodeConnectionId, now)) {
//1.1 构建元数据请求
Metadata.MetadataRequestAndVersion requestAndVersion = metadata.newMetadataRequestAndVersion(now);
MetadataRequest.Builder metadataRequest = requestAndVersion.requestBuilder;
log.debug("Sending metadata request {} to node {}", metadataRequest, node);
//1.2 向指定节点发送元数据请求
sendInternalMetadataRequest(metadataRequest, nodeConnectionId, now);
inProgress = new InProgressData(requestAndVersion.requestVersion, requestAndVersion.isPartialUpdate);
return defaultRequestTimeoutMs;
}
......忽略
//2.判断节点是否能连接上。
if (connectionStates.canConnect(nodeConnectionId, now)) {
// We don't have a connection to this node right now, make one
log.debug("Initialize connection to node {} for sending metadata request", node);
//初始化与node的连接
initiateConnect(node, now);
return reconnectBackoffMs;
}
return Long.MAX_VALUE;
}
void sendInternalMetadataRequest(MetadataRequest.Builder builder, String nodeConnectionId, long now) {
ClientRequest clientRequest = newClientRequest(nodeConnectionId, builder, now, true);
doSend(clientRequest, true, now);
}
首先调用方法canSendRequest() 检测选定的这个节点还是否能接收请求的条件(其中canSendRequest()在上节课讲过)。
如果不满足发送条件就去尝试与node连接,然后下次再尝试获取元数据。
如果满足发送条件就构建元数据请求对象,然后调用方法sendInternalMetadataRequest() 向指定的节点发送元数据请求,先构建ClientRequest对象,然后调用我们上节课讲的NetworkClient.doSend()方法,注意我上节课讲过这个方法只是把请求缓存下来,并没有真正发送,真正的网络发送是由NetworkClient.poll()方法完成的。
handleSuccessfulResponse() 方法。元数据的请求过程介绍完了,然后给你介绍下收到元数据后的解析,代码如下所示:
public void handleSuccessfulResponse(RequestHeader requestHeader, long now, MetadataResponse response) {
......忽略
// 1.查看response的错误信息。
Map<String, Errors> errors = response.errors();
if (!errors.isEmpty())
log.warn("Error while fetching metadata with correlation id {} : {}", requestHeader.correlationId(), errors);
//2.如果没有broker相关信息就认为没有获得元数据
if (response.brokers().isEmpty()) {
//更新失败
this.metadata.failedUpdate(now);
} else {
//3.更新meatedata
this.metadata.update(inProgress.requestVersion, response, inProgress.isPartialUpdate, now);
}
inProgress = null;
}
首先查看response返回信息的error。如果response内的brokers是空,那么我们可以判断更新失败了,这时需要调用failedUpdate(now)方法记录更新失败的时间,目的是避免立即重试造成服务端网络过载。如果response数据没有问题,就调用MetaData.update()方法去更新。
总结
这一节课我带你分析了生产者获取元数据的相关代码,现在我们一起来总结下。
KafkaProducer主线程:首先判断是否要更新元数据,然后唤醒Sender线程去更新MetaData,同时阻塞自己等待Sender线程完成更新MetaData。
Sender线程:真正发送消息的线程,这里主要分析了Sender对metaData request的封装以及解析,最后解除对 KafkaProducer 主线程的阻塞。
DefaultMetadataUpdater:这是NetworkClient类的内部类,用于客户端更新元数据,包括发起元数据请求,解析最新的元数据,并更新元数据的操作。
8.客户端网络通信如何实现?
在前面两讲中我们一起学习了Kafka对NIO的封装,这一讲我们继续讲解NetworkClient类。
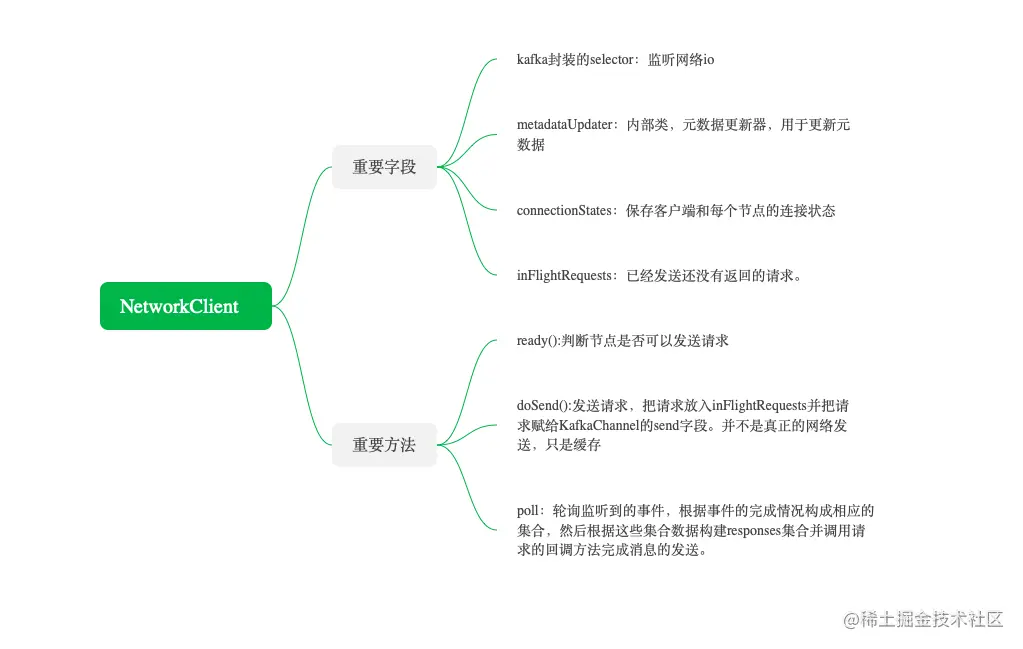
NetworkClient为上层业务提供了网络IO的功能,其中上层业务包括生产者、消费者和服务端。NetworkClient里使用了前面两讲我们介绍的Kafka对NIO的封装组件,同时做了一定的封装,实现了网络IO。NetworkClient类不仅用于客户端与服务端通信,还用于服务端之间的通信。
NetworkClient 类是 Kafka 中用于处理网络 I/O 的核心组件,它基于 Java NIO(非阻塞 I/O)提供了高效且灵活的网络通信功能。NetworkClient 不仅被生产者和消费者使用,还被 Kafka 服务端内部使用,以实现 Broker 之间的通信。下面我们将详细解析 NetworkClient 类及其关键方法。
NetworkClient 类概述
NetworkClient 提供了以下主要功能:
连接管理:负责与 Broker 建立和维护 TCP 连接。
请求发送:将请求通过已建立的连接发送到 Broker。
响应接收:从 Broker 接收响应,并将响应传递给相应的回调函数。
超时管理:处理请求的超时情况,确保请求在合理的时间内得到响应。
重试机制:在网络问题或其他错误情况下,自动重试请求。
关键组件
Selector:Java NIO Selector 用于多路复用 I/O 操作,允许单个线程管理多个通道上的 I/O 事件。
KafkaChannel:封装了 Socket 通道和相关的缓冲区,用于实际的数据读写操作。
InFlightRequests:跟踪所有已经发送但尚未收到响应的请求。
MetadataUpdater:负责更新集群元数据,确保生产者或消费者能够正确地路由消息。
主要方法
initiateConnect()
public void initiateConnect(String host, int port, int connectionTimeoutMs) {
InetSocketAddress address = new InetSocketAddress(host, port);
if (connections.containsKey(address)) {
// 如果已经存在连接,则直接返回
return;
}
// 创建一个新的 KafkaChannel
KafkaChannel channel = new KafkaChannel(selector, address, maxReceiveSize, receiveBufferSize, sendBufferSize);
connections.put(address, channel);
selector.registerChannel(channel, connectionTimeoutMs);
}作用:初始化与指定主机和端口的连接。
逻辑:
检查是否已经存在连接,如果存在则直接返回。
创建一个新的
KafkaChannel对象。将新的
KafkaChannel添加到连接映射中。注册
KafkaChannel到Selector,并设置连接超时时间。
send(ClientRequest request, long now)
public void send(ClientRequest request, long now) {
InetSocketAddress destination = request.destination();
KafkaChannel channel = getExistingConnection(destination);
if (channel == null) {
// 如果没有现成的连接,则发起连接
initiateConnect(destination.getHostString(), destination.getPort(), config.connectionTimeoutMs());
} else {
// 如果已经有连接,则尝试发送请求
doSend(request, channel, now);
}
}作用:发送请求到指定的目标地址。
逻辑:
获取目标地址。
检查是否存在现成的连接。
如果没有现成的连接,则调用
initiateConnect()发起连接。如果有现成的连接,则调用
doSend()方法发送请求。
doSend(ClientRequest request, KafkaChannel channel, long now)
private void doSend(ClientRequest request, KafkaChannel channel, long now) {
NetworkSend send = request.toSend(now);
channel.addSend(send);
inFlightRequests.add(request);
}作用:将请求转换为
NetworkSend对象,并添加到KafkaChannel的发送队列中。逻辑:
将
ClientRequest转换为NetworkSend对象。将
NetworkSend对象添加到KafkaChannel的发送队列中。将
ClientRequest添加到inFlightRequests集合中,表示该请求已经发送但尚未收到响应。
poll(long timeout, long now)
public List<NetworkClient.TransportResponse> poll(long timeout, long now) {
List<NetworkClient.TransportResponse> responses = new ArrayList<>();
while (true) {
// 处理选择器中的I/O事件
handleCompletedSends();
handleCompletedReceives(responses, now);
handleConnections();
handleDisconnections();
handleTimedOutConnections();
// 检查是否有更多的I/O事件需要处理
if (!hasReadyNodes() || !selector.hasReadyKeys()) {
break;
}
}
// 处理超时的请求
handleTimedOutRequests(now);
return responses;
}作用:处理网络 I/O 事件,包括发送、接收、连接和断开连接等。
逻辑:
循环处理选择器中的 I/O 事件。
处理已完成的发送操作。
处理已完成的接收操作,并将响应添加到
responses列表中。处理连接和断开连接的操作。
处理超时的连接。
如果没有更多的 I/O 事件需要处理,则退出循环。
处理超时的请求。
总结
NetworkClient 类通过 Java NIO 提供了高效的网络 I/O 功能,支持生产者、消费者和服务端之间的通信。它的主要职责包括连接管理、请求发送、响应接收、超时管理和重试机制。通过这些功能,NetworkClient 确保了 Kafka 系统的可靠性和性能。
如果你有任何具体的问题或需要更详细的解释,请告诉我!
在正式讲解之前,我们还是先了解一下这一讲的大体内容,思维导图如下:
字段
NetworkClient类是KafkaClient接口的实现,它内部的重要字段有实现网络请求的Selectable、InFlightRequest,以及内部类MetadataUpdate,相关类图如下图所示:
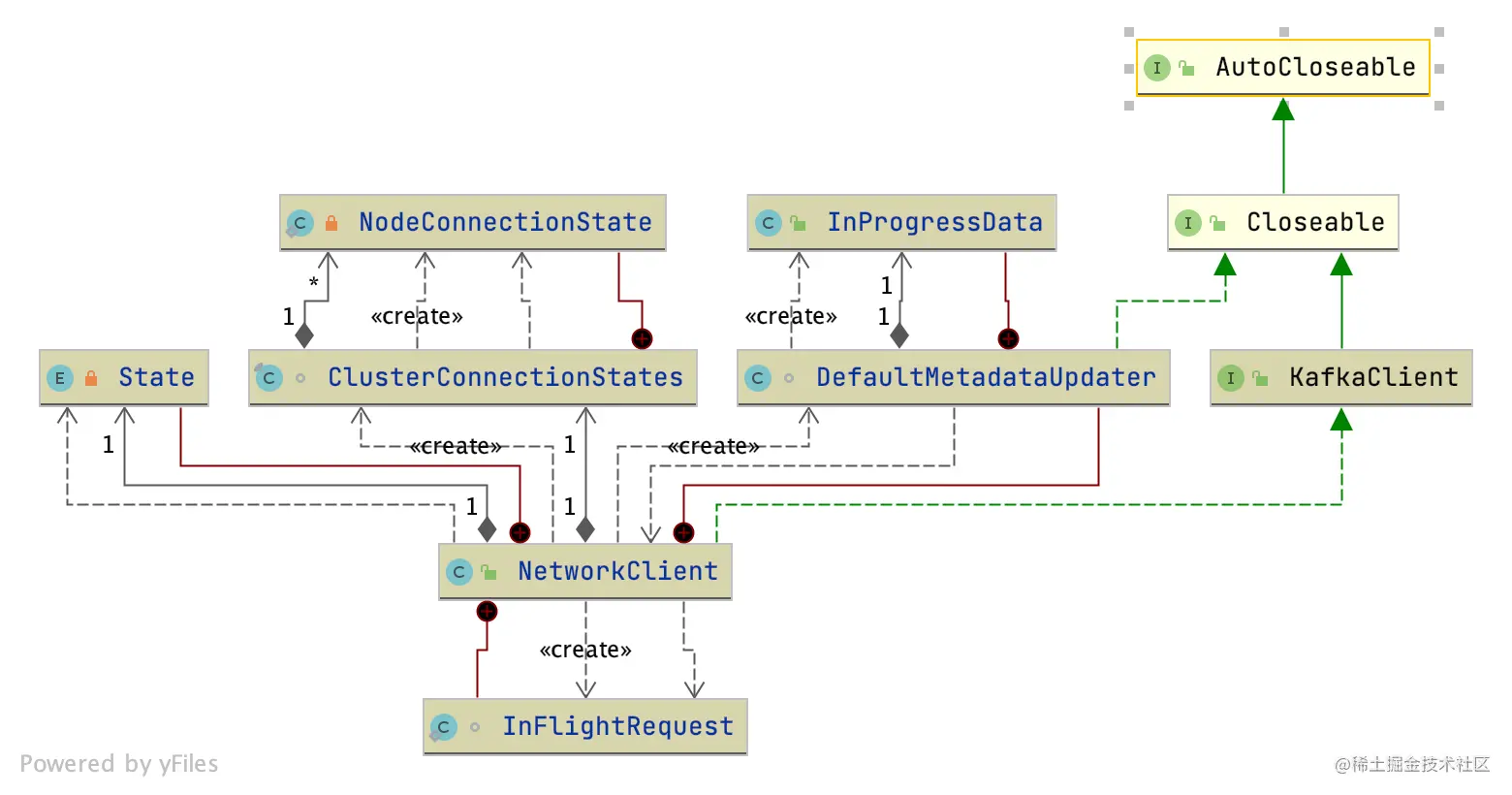
NetworkClient这个类的字段比较多,你可以参考下面的示例代码:
public class NetworkClient implements KafkaClient {
//用于网络IO的选择器
private final Selectable selector;
//用于元数据的更新
private final MetadataUpdater metadataUpdater;
// 集群所有连接的状态都在这里管理
private final ClusterConnectionStates connectionStates;
//发送后还没有响应的请求集合
private final InFlightRequests inFlightRequests;
//表示发送数据的缓冲区的大小
private final int socketSendBuffer;
//表示接收数据的缓冲区的大小
private final int socketReceiveBuffer;
//client端的id
private final String clientId;
//重连的退避时间
private final long reconnectBackoffMs;
/**
* True:当第一次连接一个broker的时候,我们应当发送一个version的请求,用来得知broker的版本
false:不发version的请求
*/
private final boolean discoverBrokerVersions;
//broker的版本
private final ApiVersions apiVersions;
//key为node id,value为ApiVersionsRequest.Builder的键值对
private final Map<String, ApiVersionsRequest.Builder> nodesNeedingApiVersionsFetch = new HashMap<>();
//取消的请求
private final List<ClientResponse> abortedSends = new LinkedList<>();
这里我们介绍几个比较重要的字段。
selector:这个字段就是我们上一讲介绍的Kafka封装的Selector,网络IO的选择器负责监听网络IO事件,以及网络连接、读写等操作。metadataUpdater:对应的是内部类,目的是更新元数据。connectionStates:所有连接的状态都在这里管理。底层使用Map<String,NodeConnectionState>实现,key是node id,value是NodeConnectionState对象,其中使用NodeConnectionState枚举表示连接状态,还记录了最后一次连接的时间戳。inFlightRequests:用以保存已经发出去了但是还没收到响应的Request的集合。socketSendBuffer:表示发送数据的缓冲区的大小。socketReceiveBuffer:表示接收数据的缓冲区的大小。clientId:client 端的 id,用来标识客户端身份。reconnectBackoffMs:重连的退避。为了防止短时间内重连造成的网络压力,设计了一个时间段,在这个时间段内不得重连。
这里我们重点看下NetworkClient的内部类InFlightRequests,InFlightRequests是用来存储和操作待发送消息的缓存区。我们首先看一下它的字段和构造方法:
final class InFlightRequests {
//某个node连接上最多的请求数,默认5个
private final int maxInFlightRequestsPerConnection;
//key是nodeid,value是对于某个node的InFlightRequest集合
private final Map<String, Deque<NetworkClient.InFlightRequest>> requests = new HashMap<>();
private final AtomicInteger inFlightRequestCount = new AtomicInteger(0);
public InFlightRequests(int maxInFlightRequestsPerConnection) {
this.maxInFlightRequestsPerConnection = maxInFlightRequestsPerConnection;
}
那 InFlightRequests 的核心字段又是哪些呢?这里我简单介绍下。
requests:Map<String, Deque<NetworkClient.InFlightRequest>>类对象,是一个 key 为 nodeid、value 为 Deque<NetworkClient.InFlightRequest> 的键值对组成的 map。
maxInFlightRequestsPerConnection:某个node连接上最多的请求数,也就是队列的长度,默认是5。
inFlightRequestCount:所保存请求的个数。
作为待发送请求的缓冲区,InFlightRequests是如何存储请求的呢?其存储结构如下图所示:
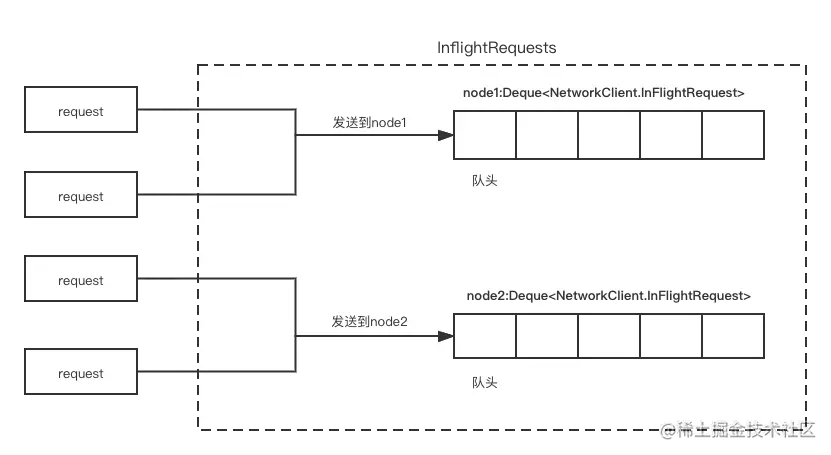
这里我们就结合这张图简单介绍一下inFlightRequests的结构:inFlightRequests是个map集合,每个node会对应一个请求队列;每次请求进入 InFlightRequests前,会先判断请求属于哪个node,然后再进入对应的队列。
不过,这容易出现一个发送消息乱序的问题。我们知道,所谓发送消息就是指真正发送消息成功的顺序,并不是按队列的顺序。
那为什么发送请求会产生乱序呢?因为maxInFlightRequestsPerConnection默认是5,也就是说每个node都可以最多保存5个请求。如果某个请求长时间没有响应,我们会认为响应超时,同时如果我们设置重试次数大于0,就会发生重试,而且重试的请求会重新排在队列的后面,这就破坏了一开始的发送顺序,造成了乱序。
那如何去避免这种乱序呢?这里我总结出两种方式,你可以结合自己实际工作场景选择合适的方案。
把重试次数设置为0,这样即使出现超时情况也不会造成乱序。不过这种方式也有一个弊端:会丢消息。
把maxInFlightRequestsPerConnection设置为1,这样一个请求没有发送成功就会根据重试次数不断地重试。不过,这样会导致发送的效率变低。
重要方法
inFlightRequests这个类的入队、出队的方法比较容易,你可以自己研究,这里我重点讲解以下几个方法。
1. canSendMore()
canSendMore() 方法的示例代码如下:
public boolean canSendMore(String node) {
Deque<NetworkClient.InFlightRequest> queue = requests.get(node);
return queue == null || queue.isEmpty() ||
(queue.peekFirst().send.completed() && queue.size() < this.maxInFlightRequestsPerConnection);
}
canSendMore()方法用来判断是否还能往对应的node发送更多的请求,以下三个条件中满足一个就能满足发送条件。
queue == null,说明这个节点还没有对应的发送队列,也就是客户端对这个节点没有发送过请求。
queue.isEmpty()为true:队列里是空的,请求都发送完了。
queue.peekFirst().send.completed() && queue.size() < this.maxInFlightRequestsPerConnection成立,这个判断条件要想成立,“&&”前后两部分需要同时满足:①queue.peekFirst().send.completed()表示头结点的send必须发送完,如果还没发送完就发送,会覆盖KafkaChannel.send这个字段,进而造成没发送完的请求被覆盖;②queue.size() < this.maxInFlightRequestsPerConnection表示节点的请求数量要小于规定的每个连接的最大请求数,因为堆积过多说明节点的网络有问题,继续发会造成超时。
2. ready()
ready()方法表示某个节点是否可以发送请求,对应的代码如下所示:
public boolean ready(Node node, long now) {
if (node.isEmpty())
throw new IllegalArgumentException("Cannot connect to empty node " + node);
//同时满足三个条件就认为可以连接
if (isReady(node, now))
return true;
// 发起连接同时满足两个条件
// 1.连接必须是isDisconnected。
// 2.由于连接不能太频繁,两次重试之间时间差要大于重试退避时间。
if (connectionStates.canConnect(node.idString(), now))
//发起连接,不一定连接成功了
initiateConnect(node, now);
return false;
}
ready() 方法的执行流程是这样的,第一步先判断节点是否准备好接收请求了,同时满足以下三个条件就说明可以接收请求了。
不能正在更新元数据,而且元数据不能过期;
node的连接处于ready状态;
inFlightRequests里能放更多的请求(上面解释inFlightRequests字段的时候说过,这里就不赘述了)。
如果上步判断没做好接收请求, 会尝试与对应的node连接,与node连接的条件也有两个:
连接必须是isDisconnected,也就是说客户端和服务端的连接状态是没有连接上;
两次重试之间时间差要大于重试退避时间,目的是防止重连过于频繁而造成网络压力过大。
最后一步是初始化连接initiateConnect(node, now),具体细节是修改channel的连接状态为正在连接,然后调用selector的connect()方法进行连接。注意,这时不一定连接上了,selector.poll()会监听连接是否准备好并完成连接。
3. 发送数据相关的方法
这里的发送数据是把数据发送到缓存里,并不是真正的网络发送,相关的方法如下:
public void send(ClientRequest request, long now) {
doSend(request, false, now);
}
private void doSend(ClientRequest clientRequest, boolean isInternalRequest, long now) {
ensureActive();
String nodeId = clientRequest.destination();
if (!isInternalRequest) {
//1.这个服务端节点能不能接收请求。
// 1)连接是否正常。2)channel连接是否建立。3)inFlightRequests.canSendMore(node):inFlightRequests是否还能接收请求。
if (!canSendRequest(nodeId, now))
throw new IllegalStateException("Attempt to send a request to node " + nodeId + " which is not ready.");
}
......忽略
//
doSend(clientRequest, isInternalRequest, now, builder.build(version));
} catch (UnsupportedVersionException unsupportedVersionException) {
......忽略
}
}
private void doSend(ClientRequest clientRequest, boolean isInternalRequest, long now, AbstractRequest request)
......忽略
//1.构建NetworkSend对象
Send send = request.toSend(destination, header);
//2.构建inFlightRequest对象
InFlightRequest inFlightRequest = new InFlightRequest(
clientRequest,
header,
isInternalRequest,
request,
send,
now);
//3.把inFlightRequest加入inFlightRequest的集合里
this.inFlightRequests.add(inFlightRequest);
//4.把NetworkSend对象设置到selector的send字段
selector.send(send);
}
首先,send()方法是最外层的方法,调用了doSend(ClientRequest clientRequest, boolean isInternalRequest, long now)方法,这个方法主要作用是判断inFlightRequests上对应的节点是不是能发送请求,条件有三个,必须同时满足。
客户端和node连接正常。
客户端和node的channel连接建立。
inFlightRequests.canSendMore(node):inFlightRequests对应的node还能接收请求。
最后一步是调用doSend(ClientRequest clientRequest, boolean isInternalRequest, long now, AbstractRequest )这个方法,用于最终的请求发送,步骤如下:
构建NetworkSend对象;
构建inFlightRequest对象;
把inFlightRequest加入inFlightRequests的集合里;
把NetworkSend对象设置到selector的send字段,等待下一步真正的网络发送。
这一发送过程其实是把要发送的请求封装成inFlightRequest放到inFlightRequests的集合,然后放到对应channel的字段NetworkSend里缓存起来,而NetworkSend是对NIOBuffer的封装。总体来看,这个发送过程就是为下一步真正的网络IO发送而服务的。
4. poll()
poll()方法是核心方法,它会对注册在selector上的网络事件进行监听和处理,然后再根据处理后的集合做进一步的整合,最后封装response并调用消息的回调方法,完成一次从request到response的过程。代码如下所示:
public List<ClientResponse> poll(long timeout, long now) {
ensureActive();
if (!abortedSends.isEmpty()) {
List<ClientResponse> responses = new ArrayList<>();
handleAbortedSends(responses);
completeResponses(responses);
return responses;
}
//1.尝试更新元数据
long metadataTimeout = metadataUpdater.maybeUpdate(now);
try {
//2.执行IO操作
this.selector.poll(Utils.min(timeout, metadataTimeout, defaultRequestTimeoutMs));
} catch (IOException e) {
log.error("Unexpected error during I/O", e);
}
// process completed actions
long updatedNow = this.time.milliseconds();
List<ClientResponse> responses = new ArrayList<>();
//3.处理completedSends队列
handleCompletedSends(responses, updatedNow);
//4.处理completedReceives队列
handleCompletedReceives(responses, updatedNow);
// 5.处理 disconnected列表
handleDisconnections(responses, updatedNow);
// 6.处理connected列表
handleConnections();
handleInitiateApiVersionRequests(updatedNow);
//7.处理超时连接:
// 关闭与node连接超时的连接
// 删除InFlightRequests中的超时请求
handleTimedOutConnections(responses, updatedNow);
//8.处理超时请求
handleTimedOutRequests(responses, updatedNow);
//9.调用每个消息自定义的回调
completeResponses(responses);
return responses;
}
poll() 方法的执行步骤还是比较复杂的,下面我们就按照先后顺序讲解下这各个步骤。
第一步,尝试更新元数据。元数据的变化会影响到消息发送的行为,比如有些主题删除了,这些消息就没必要发了。
第二步,调用Selector.select()执行IO操作,这是调用我们上一讲介绍的Selector组件去真正地执行IO操作,这个操作会产生以下 3 个集合。
connected集合:已经完成连接的node集合。
completedReceives集合:接收完成的集合,意味着KafkaChannel上的NetworkReceive写满后放入这个集合里。
completedSends集合:发送完成的集合,channel上的NetworkSend读完后会放入这个集合里。
第三步,调用handleCompletedSends()方法,处理completedSends集合。completedSends 集合与 inFlightRequests集合是协作的关系。completedSends是指发送成功但是没有返回的请求集合,completedSends的元素对应着inFlightRequests里对应队列的最后一个元素,两者关系如下图所示:
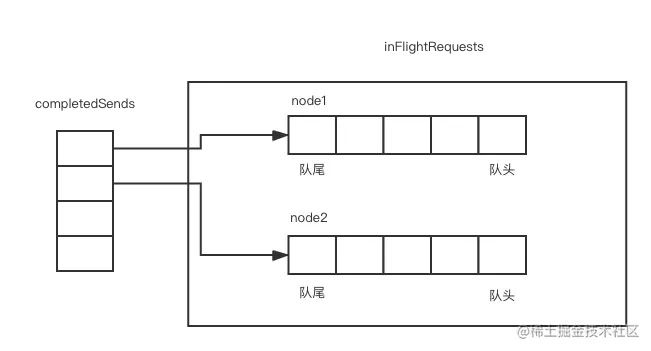
搞清completedSends集合与inFlightRequests的关系后,我们接着分析poll()方法内部调用的handleCompletedSends() 方法代码:
private void handleCompletedSends(List<ClientResponse> responses, long now) {
//1.遍历completedSends集合
for (Send send : this.selector.completedSends()) {
//2.获取队列最后一个元素
InFlightRequest request = this.inFlightRequests.lastSent(send.destination());
//3.是否需要响应
if (!request.expectResponse) {//
//4.不需要响应就删除inFlightRequests对应node请求队列的第一个元素
this.inFlightRequests.completeLastSent(send.destination());
//5.把请求添加到responses集合
responses.add(request.completed(null, now));
}
}
}
可以看到,方法通过遍历completedSends集合,取出对应队列的最后一个元素,然后再判断请求是否需要响应。在Kafka中,有的请求是不需要响应的,对应发送完了不用考虑是否发送成功的场景。如果不需要响应,就构建callback为null的response对象,并把对象加到responses集合中。(需要响应的请求在下面步骤会讲解的。)
第四步,调用handleCompletedReceives()方法,这个方法用来处理CompletedReceives队列。CompletedReceives队列是接收到的响应的集合,CompletedReceives集合与inFlightRequests集合同样有协作的关系,两个集合关系如下图所示:
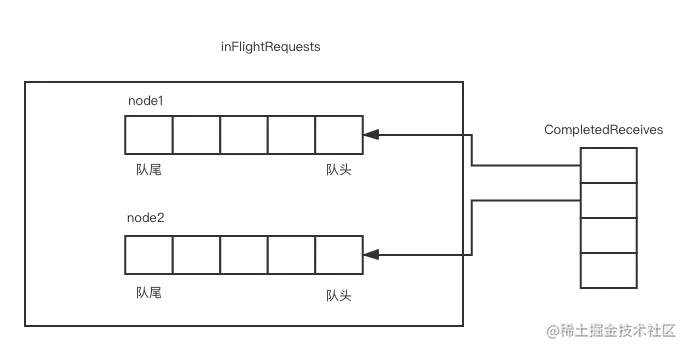
与completedSends正好相反,CompletedReceives集合的元素对应inFlightRequest队列的队头元素。selector.poll()方法会把接收到的响应对应的请求从inFlightRequests集合中删除。对应的handleCompletedReceives()方法代码如下所示:
/**
* 处理CompletedReceives队列,根据返回的响应信息实例化ClientResponse,并加到响应集合里
*/
private void handleCompletedReceives(List<ClientResponse> responses, long now) {
for (NetworkReceive receive : this.selector.completedReceives()) {
//1.取出发送请求的node id
String source = receive.source();
// 2.从inFlightRequests取出对应的InFlightRequest对象,并从inFlightRequests删除
InFlightRequest req = inFlightRequests.completeNext(source);
// 3.解析响应
Struct responseStruct = parseStructMaybeUpdateThrottleTimeMetrics(receive.payload(), req.header,
throttleTimeSensor, now);
AbstractResponse response = AbstractResponse.
parseResponse(req.header.apiKey(), responseStruct, req.header.apiVersion());
......忽略
//流控方法
maybeThrottle(response, req.header.apiVersion(), req.destination, now);
if (req.isInternalRequest && response instanceof MetadataResponse)
// 4.1 判断返回类型,如果是请求元数据的返回调用metadataUpdater,handleSuccessfulResponse处理
metadataUpdater.handleSuccessfulResponse(req.header, now, (MetadataResponse) response);
// 4.2 如果是请求broker api 版本的,调用handleApiVersionsResponse处理
else if (req.isInternalRequest && response instanceof ApiVersionsResponse)
handleApiVersionsResponse(responses, req, now, (ApiVersionsResponse) response);
else
//5.常规的发送消息的响应,ClientResponse并加到response集合中。
responses.add(req.completed(response, now));
}
}
第五步,调用handleDisconnections()方法,处理与node断开连接的请求。大体过程是,遍历disConnections列表删除inFlightRequests里对应node的队列,同时取消对这个node的api version的请求,因为连接断了,请求这个node也就没有意义了。
第六步,调用handleConnections()方法,处理connected列表。主要功能是把node放入connectionStates集合里。
第七步,调用handleTimedOutConnections()方法,处理连接超时的node集合。逻辑和handleDisconnections()方法相似,这里就不详细说明了,你若感兴趣的话,可以看源码了解下。
第八步,调用handleTimedOutRequests()方法,找到inFlightRequests里超时的请求,然后把相应节点连接的状态改为DISCONNECTED。
第九步,调用completeResponses(responses)方法,用来调用每个消息自定义的回调。
至此,poll()方法就讲解完了,这个方法比较长,也很重要,是网络通信的核心主干方法,涵盖了元数据获取、网络IO,然后对应各种情况去填充响应集合responses,希望你能把这个流程梳理清楚。
总结
这一讲我们主要介绍了NetworkClient类的重要字段和方法。NetworkClient 类是客户端连接所有外部节点的管理类,实现了对KafkaChannel的管理,同时利用底层通信类实现网络连接、网络读写的功能。
首先,我们讲解了NetworkClient 类几个重要的字段:
inFlightRequests是用来保存已经发送但是还没响应的请求;connectionStates用来保存客户端和所有服务端的连接状态。
然后,我们还分析了NetworkClient 类几个重要的方法:
ready()方法用来判断哪些channel连接是正常的;doSend()方法实例化NetworkSend类对象,并把其赋给KafkaChannel的send字段,然后实例化InFlightRequest类对象并把它加到inFlightRequests集合里;poll()方法可实现网络连接、读写,同时会收集读写到的数据,最后包装成响应集合responses,并且调用上层定义的回调方法完成对响应的处理。
9. Kafka是如何封装网络层的(上)
Kafka 使用 Java NIO(非阻塞 I/O)来封装其网络层,以提供高效且可扩展的网络通信。Java NIO 的主要优点是它支持多路复用 I/O 操作,允许单个线程管理多个通道上的 I/O 事件,从而减少了线程切换开销并提高了系统的吞吐量。下面是 Kafka 如何封装网络层的关键组件和方法:
关键组件
Selector:
Selector是 Java NIO 中的核心组件之一,用于监控多个通道(如 Socket 通道)上的 I/O 事件。Selector允许单个线程处理多个通道的读写操作,从而实现高效的 I/O 多路复用。
SocketChannel:
SocketChannel是一个可选择的通道,表示到 TCP 网络套接字的连接。SocketChannel可以配置为非阻塞模式,这样在读写操作时不会阻塞线程。
ByteBuffer:
ByteBuffer是 Java NIO 中用于数据缓冲的主要类。ByteBuffer提供了灵活的数据读写接口,并且可以被直接传递给操作系统进行高效的 I/O 操作。
KafkaChannel:
KafkaChannel是 Kafka 对SocketChannel的封装,提供了更高级别的抽象和功能。它包含了一个
SocketChannel和相关的缓冲区(ByteBuffer),以及一些状态信息(如连接状态、超时时间等)。
NetworkClient:
NetworkClient是 Kafka 中用于处理网络 I/O 的核心类。它使用
Selector来管理多个KafkaChannel,并负责请求的发送和响应的接收。
主要方法和流程
1. 连接建立
initiateConnect():创建一个新的
KafkaChannel实例。将
KafkaChannel注册到Selector上,并设置连接超时时间。Selector会监控连接过程中的 I/O 事件。
public void initiateConnect(String host, int port, int connectionTimeoutMs) {
InetSocketAddress address = new InetSocketAddress(host, port);
if (connections.containsKey(address)) {
return;
}
KafkaChannel channel = new KafkaChannel(selector, address, maxReceiveSize, receiveBufferSize, sendBufferSize);
connections.put(address, channel);
selector.registerChannel(channel, connectionTimeoutMs);
}2. 请求发送
send(ClientRequest request, long now):检查是否已经存在到目标地址的连接。
如果没有现成的连接,则发起新的连接。
如果有现成的连接,则将请求转换为
NetworkSend对象,并添加到KafkaChannel的发送队列中。
public void send(ClientRequest request, long now) {
InetSocketAddress destination = request.destination();
KafkaChannel channel = getExistingConnection(destination);
if (channel == null) {
initiateConnect(destination.getHostString(), destination.getPort(), config.connectionTimeoutMs());
} else {
doSend(request, channel, now);
}
}
private void doSend(ClientRequest request, KafkaChannel channel, long now) {
NetworkSend send = request.toSend(now);
channel.addSend(send);
inFlightRequests.add(request);
}3. I/O 事件处理
poll(long timeout, long now):调用
Selector.select(timeout)方法,等待并处理 I/O 事件。处理已完成的发送操作。
处理已完成的接收操作,并将响应传递给相应的回调函数。
处理连接和断开连接的操作。
处理超时的连接和请求。
public List<NetworkClient.TransportResponse> poll(long timeout, long now) {
List<NetworkClient.TransportResponse> responses = new ArrayList<>();
while (true) {
// 处理选择器中的I/O事件
handleCompletedSends();
handleCompletedReceives(responses, now);
handleConnections();
handleDisconnections();
handleTimedOutConnections();
// 检查是否有更多的I/O事件需要处理
if (!hasReadyNodes() || !selector.hasReadyKeys()) {
break;
}
}
// 处理超时的请求
handleTimedOutRequests(now);
return responses;
}总结
Kafka 通过以下方式封装其网络层:
使用 Java NIO 的
Selector和SocketChannel:这使得 Kafka 能够在一个线程中高效地管理多个网络连接。自定义的
KafkaChannel类:对SocketChannel进行封装,提供了更高级别的抽象和功能。NetworkClient类:作为网络 I/O 的核心类,负责连接管理、请求发送、响应接收、超时管理和重试机制。
这种设计使得 Kafka 能够在高并发环境下保持高性能和可靠性,同时减少了线程切换开销。如果你有任何具体的问题或需要进一步的解释,请告诉我!
Kafka 是一个分布式系统,生产者和服务端在不同的机器上,这就会涉及网络通信,Java 系统的网络通信一般会用 Java 多路复用的实现库 NIO,同时 Kafka 内部对 Java NIO 封装了统一的框架,实现了多路复用的网络 IO 操作。之所以 Kafka 要自己实现 Java NIO 的封装,而不采用类似 Netty 那样 NIO 封装好的类库,就是因为自己实现的更加适合 Kafka 的一些特性。
为便于你更好地理解,这里我用一个思维导图大体描述下这一讲我们要讲的知识点:
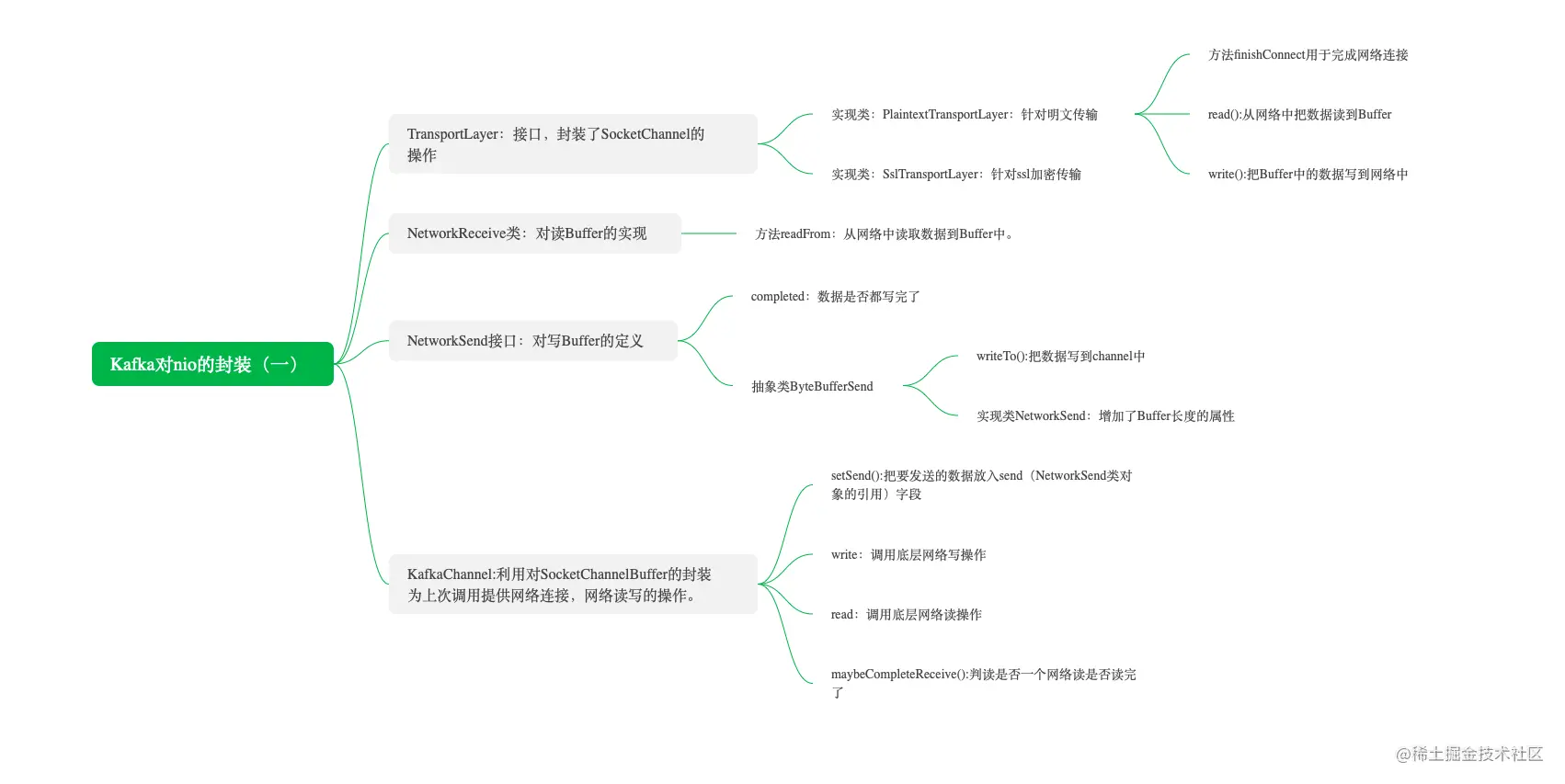
Java NIO 简单介绍
这里我们介绍几个 Java NIO 的组件。
Buffer:缓冲区。这是一个接口,Kafka 用它的 ByteBuffer 实现类,配合 SocketChannel 实现读写操作。读的时候,调用 channel.read(buffer) 把 SocketChannel 的数据读到 ByteBuffer 内;写的时候,调用 channel.write(buffer) 把 Buffer 中的数据写到 SocketChannel 内。SocketChannel:网络连接通道。字节数据的读写都发生在这个通道上,包括从通道中读出数据、将数据写入通道。SelectionKey:选择键。每个 Channel 向 Selector 注册标识时,都将会创建一个 SelectionKey。SelectionKey 里可以定义 Selector 监听 SocketChannel 的事件,包括连接、读、写事件。Selector:选择器。SelectionKey 先把 SocketChannel 注册到 Selector 上,然后就能监听网络连接、读、写事件。
Kafka 对 Java NIO 的封装
下面我列出了 Kafka 对 Java NIO 封装后的组件,以及和 NIO 组件的对应关系。
Kafka 自己的 Selector 类:对 NIO 中 Selector 的封装。TransportLayer:对 NIO 中 SocketChannel 和 SelectionKey 的封装。TransportLayer 是一个接口,实现类有 PlaintextTransportLayer 和 SslTransportLayer,其中,PlaintextTransportLayer 是明文网络传输,SslTransportLayer 是 SSL 加密网络传输,这一讲我们只涉及明文网络传输的讲解。NetworkReceive:对 NIO 中读 Buffer 的封装。NetworkSend:对 NIO 中写 Buffer 的封装。KafkaChannel:把 TransportLayer、NetworkReceive 和 NetworkSend 又做了一次封装,这样用起来比较方便,就不用关心底层的组件了。
Kafka 对 NIO 中的 SelectionKey 并没有封装,而是直接使用。
它们之间的关系如下图所示:
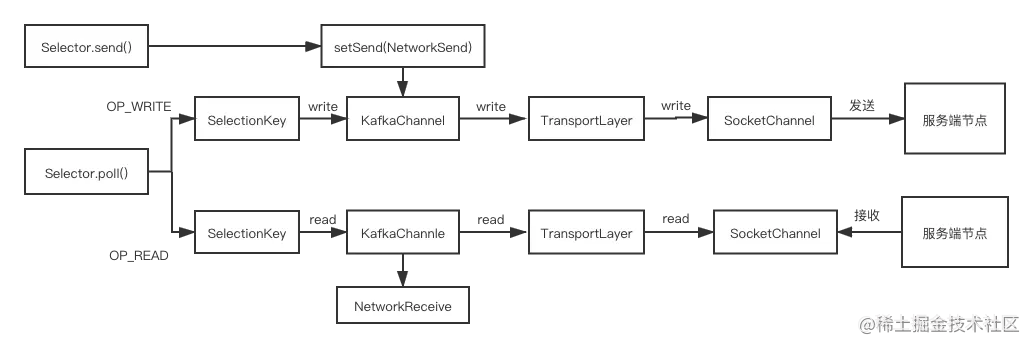
我简单给你介绍一下 Kafka 封装 Java NIO 后处理读写的流程:Selector 监听到客户端的读写事件后,会获取绑定在选择键上的 KafkaChannel;KafkaChannel 会把读写操作交给 TransportLayer,TransportLayer 进一步会把读写操作交给 SocketChannel 完成数据的发送。数据的接收步骤也是类似的,你可以结合操作图对比了解一下。
接下来我主要为你介绍 TransportLayer、NetworkReceive、NetworkSend、KafkaChannel 这几个组件,另外一个 Selector 的封装会在下一讲重点讲解。
好的,你提到的这些组件是 Kafka 网络层的核心部分。下面我将详细介绍 TransportLayer、NetworkReceive、NetworkSend 和 KafkaChannel 这几个组件,并结合读写流程进行说明。
1. TransportLayer
TransportLayer 是 Kafka 中用于处理底层 I/O 操作的抽象层。它封装了 SocketChannel 的读写操作,提供了更高级别的接口。TransportLayer 负责实际的数据传输,并处理与网络相关的细节。
主要职责
数据发送:将数据通过
SocketChannel发送到远程主机。数据接收:从
SocketChannel读取数据并传递给上层处理。错误处理:处理网络 I/O 操作中可能出现的各种错误。
2. NetworkReceive
NetworkReceive 是一个数据结构,用于表示从网络接收到的数据。它通常包含以下信息:
缓冲区:存储接收到的数据。
源地址:数据的来源地址。
状态信息:例如是否已经完全读取等。
主要职责
数据存储:存储从
SocketChannel读取到的数据。状态管理:跟踪数据的读取状态,确保数据完整性和一致性。
3. NetworkSend
NetworkSend 是一个数据结构,用于表示要发送到网络的数据。它通常包含以下信息:
缓冲区:存储要发送的数据。
目标地址:数据的目标地址。
状态信息:例如是否已经完全发送等。
主要职责
数据存储:存储要通过
SocketChannel发送的数据。状态管理:跟踪数据的发送状态,确保数据完整性和一致性。
4. KafkaChannel
KafkaChannel 是 Kafka 对 SocketChannel 的封装,提供了更高级别的抽象和功能。它负责管理连接的状态、读写缓冲区以及与 Selector 的交互。
主要职责
连接管理:维护与远程主机的连接状态。
读写操作:将读写操作委托给
TransportLayer,并通过SocketChannel完成实际的数据传输。事件处理:处理
Selector监听到的 I/O 事件(如可读、可写)。超时管理:处理连接超时和请求超时。
读写流程
读操作流程
Selector监听事件:Selector监听到KafkaChannel上的可读事件。
获取
KafkaChannel:Selector获取绑定在选择键上的KafkaChannel。
调用
KafkaChannel的读方法:KafkaChannel将读操作委托给TransportLayer。
TransportLayer读取数据:TransportLayer使用SocketChannel从网络读取数据。读取的数据被存储在
NetworkReceive中。
处理读取的数据:
KafkaChannel将NetworkReceive传递给上层处理逻辑(如解析响应、更新元数据等)。
写操作流程
准备
NetworkSend:上层逻辑(如
Sender线程)准备好要发送的数据,并将其封装为NetworkSend。
调用
KafkaChannel的写方法:KafkaChannel将NetworkSend添加到发送队列中。
Selector监听事件:Selector监听到KafkaChannel上的可写事件。
获取
KafkaChannel:Selector获取绑定在选择键上的KafkaChannel。
调用
KafkaChannel的写方法:KafkaChannel将写操作委托给TransportLayer。
TransportLayer发送数据:TransportLayer使用SocketChannel将数据发送到网络。发送的数据来自
NetworkSend。
更新状态:
KafkaChannel更新NetworkSend的状态,标记为已发送或仍在等待发送。
示例代码
以下是一些简化的示例代码,帮助理解这些组件的相互作用:
KafkaChannel 类
public class KafkaChannel {
private final Selector selector;
private final SocketChannel socketChannel;
private final TransportLayer transportLayer;
public KafkaChannel(Selector selector, InetSocketAddress address, int maxReceiveSize) throws IOException {
this.selector = selector;
this.socketChannel = SocketChannel.open();
this.socketChannel.configureBlocking(false);
this.socketChannel.connect(address);
this.transportLayer = new TransportLayer(socketChannel, maxReceiveSize);
this.selector.registerChannel(this, 0);
}
public void read() {
transportLayer.read();
}
public void write(NetworkSend send) {
transportLayer.write(send);
}
}TransportLayer 类
public class TransportLayer {
private final SocketChannel socketChannel;
private final ByteBuffer readBuffer;
private final ByteBuffer writeBuffer;
public TransportLayer(SocketChannel socketChannel, int bufferSize) {
this.socketChannel = socketChannel;
this.readBuffer = ByteBuffer.allocate(bufferSize);
this.writeBuffer = ByteBuffer.allocate(bufferSize);
}
public void read() {
try {
int bytesRead = socketChannel.read(readBuffer);
if (bytesRead > 0) {
// 处理读取的数据
processReadData(readBuffer.array(), 0, bytesRead);
} else if (bytesRead == -1) {
// 连接关闭
closeConnection();
}
} catch (IOException e) {
// 处理读取异常
handleReadException(e);
}
}
public void write(NetworkSend send) {
try {
writeBuffer.clear();
writeBuffer.put(send.data());
writeBuffer.flip();
while (writeBuffer.hasRemaining()) {
socketChannel.write(writeBuffer);
}
// 标记发送完成
send.completed();
} catch (IOException e) {
// 处理写入异常
handleWriteException(e);
}
}
}NetworkSend 类
public class NetworkSend {
private final byte[] data;
private boolean completed;
public NetworkSend(byte[] data) {
this.data = data;
}
public byte[] data() {
return data;
}
public void completed() {
this.completed = true;
}
public boolean isCompleted() {
return completed;
}
}NetworkReceive 类
public class NetworkReceive {
private final byte[] data;
private int offset;
private int length;
public NetworkReceive(byte[] data, int offset, int length) {
this.data = data;
this.offset = offset;
this.length = length;
}
public byte[] data() {
return data;
}
public int offset() {
return offset;
}
public int length() {
return length;
}
}总结
TransportLayer:封装了SocketChannel的读写操作,提供更高级别的接口。NetworkReceive和NetworkSend:分别表示从网络接收到的数据和要发送到网络的数据。KafkaChannel:对SocketChannel进行封装,管理连接状态和读写操作。
通过这种设计,Kafka 实现了高效且可靠的网络通信,能够在一个线程中处理多个网络连接,减少了线程切换开销,提高了系统的吞吐量和性能。如果你有任何具体的问题或需要进一步的解释,请告诉我!
TransportLayer
TransportLayer 是对 NIO 中 SocketChannel 的封装。它的实现类有 2 个:
PlaintextTransportLayer 类,对接口 TransportLayer 的明文传输的实现;
SslTransportLayer 类,对接口 TransportLayer 的 SSL 加密传输的实现。
其中 PlaintextTransportLayer 是比较有代表性的,我们主要学习这个类。如果你对另一个实现感兴趣,可以自己去源码中找到 SslTransportLayer 类去研究相关代码。
PlaintextTransportLayer 这个类的字段和定义比较简单,代码如下:
public class PlaintextTransportLayer implements TransportLayer {
private final SelectionKey key; //java nio 中的事件
//java nio 中的SocketChannel
private final SocketChannel socketChannel;
//Kafka的安全相关字段
private final Principal principal = KafkaPrincipal.ANONYMOUS;
public PlaintextTransportLayer(SelectionKey key) throws IOException {
this.key = key;
this.socketChannel = (SocketChannel) key.channel();
}
我们先了解下其中的字段。
key:NIO 中 SelectionKey 类的对象引用。
socketChannel:NIO 中 SocketChannel 类的对象引用。
由此可以看出,PlaintextTransportLayer 就是对 NIO 中 SelectionKey 和 SocketChannel 的封装。
在类的定义中,我们可以构造方法参数 SelectionKey 的类对象,构造方法会把 SelectionKey 的类对象赋给 key,然后从 key 中取出对应的 SocketChannel 给 socketChannel,这样就完成了初始化。
类初始化完成以后,下面我们看看相关的重要方法是怎么使用这两个 NIO 组件的。这里我将讲解 finishConnect()、read() 和 write() 这三种方法。
finishConnect() 方法用于完成网络连接,代码如下所示:
//连接是否完成,如果完成就关注OP_READ事件并取消OP_CONNECT事件
@Override
public boolean finishConnect() throws IOException {
//调用nio通道的finishConnect()方法,方法会返回连接是否已经连接好
boolean connected = socketChannel.finishConnect();
//如果建立好就取消对连接事件的监听,同时增加对读事件的监听
if (connected)
key.interestOps(key.interestOps() & ~SelectionKey.OP_CONNECT | SelectionKey.OP_READ);
return connected;
}
这个方法首先调用 NIO 组件 socketChannel 的 finishConnect() 方法看是否连接成功,如果连接成功就取消对连接事件的监听,同时增加对读事件的监听(因为连接好以后就有可能接收到数据了),最后方法返回网络连接是否成功。
read() 方法是把 socketChannel 里的数据读到缓冲区 ByteBuffer 中,具体是调用 NIO 的socketChannel 的 read 方法,代码如下所示:
/**
* 从channel中读一个byte序列到给定的 ByteBuffer中
*/
@Override
public int read(ByteBuffer dst) throws IOException {
//调用nio的通道实现数据的读取
return socketChannel.read(dst);
}
write() 方法是把缓冲区 ByteBuffer 的数据写到 SocketChannel 里,具体是调用 NIO 的 socketChannel 的 Write 方法,代码如下所示:
/**
把ByteBuffer中Byte序列写到socketChannel中
*/
@Override
public int write(ByteBuffer src) throws IOException {
return socketChannel.write(src);
}
对于 Java NIO 来说,一次读写不一定能把数据读写完,这样就需要判断读写是否完成,没有读写完的数据还需要继续执行读写操作,这样的操作涉及的步骤过于烦琐,显然对上层逻辑不是很友好。
于是 Kafka 内部把 ByteBuffer 进行了封装,并按读和写封装成 NetworkReceive 和 NetworkSend,上层调用方不用关心读写是否完成,NetworkReceive 和 NetworkSend 自己会做判断和处理。
NetworkReceive
NIO 中网络数据的读取要通过 Buffer 来实现,NetworkReceive 这个类就是对读取时的 Buffer 的封装。
其中,NetworkReceive 类的字段如下所示:
public class NetworkReceive implements Receive {
private final String source;//channel id
private final ByteBuffer size;//存储数据长度的ByteBuffer
private final int maxSize;//数据的最大长度
private final MemoryPool memoryPool;//ByteBuffer池
private ByteBuffer buffer;//存储数据体的ByteBuffer
source:channnel id,用来确定这个 NetworkReceive 是和哪个 channel 配套使用的。
size:存储数据长度的 ByteBuffer。
maxSize:数据的最大长度,这里的数据长度是指接收数据的最大字节数。
memoryPool:用来分配和管理数据体 ByteBuffer 的组件。
buffer:存储数据体的 ByteBuffer。
NetworkReceive 类的定义如下代码所示:
public NetworkReceive(int maxSize, // 能接收的最大消息
String source, // channel id
MemoryPool memoryPool // 内存池
) {
this.source = source;
this.size = ByteBuffer.allocate(4); // 分配4个字节大小的数据长度
this.buffer = null;
this.maxSize = maxSize;
this.memoryPool = memoryPool;
}
这里我重点说一下 size 字段的初始化,其中存储数据长度的 ByteBuffer 是由 4 个字节的 ByteBuffer 定义的,也就是 32 位,和 Java int 类型占用的字节相同,取值最大约等于 21G,足以满足表示消息长度的数值。
说完这个类的字段和定义,下面我们再来分析下其包含的 readFrom() 方法。
readFrom() 方法表示把 channel 中的数据读到 NetworkReceive 中的字段,包括表示消息长度的字段 size 和表示消息体本身的字段 buffer,代码如下所示:
//把channel里的数据读到ByteBuffer中
public long readFrom(ScatteringByteChannel channel) throws IOException {
//总读取数据大小
int read = 0;
// 1. 判断数据长度的缓存是否读完,没有读完接着读
if (size.hasRemaining()) {
//2.读取数据的长度
int bytesRead = channel.read(size);
if (bytesRead < 0)
throw new EOFException();
//每次读取后,读取长度加到总读取长度里
read += bytesRead;
//3.如果数据长度的缓存读完了
if (!size.hasRemaining()) {
size.rewind();
//4.读取数据长度
int receiveSize = size.getInt();
//5.如果有异常就抛出
if (receiveSize < 0)
throw new InvalidReceiveException("Invalid receive (size = " + receiveSize + ")");
if (maxSize != UNLIMITED && receiveSize > maxSize)
throw new InvalidReceiveException("Invalid receive (size = " + receiveSize + " larger than " + maxSize + ")");
requestedBufferSize = receiveSize;
if (receiveSize == 0) {
buffer = EMPTY_BUFFER;
}
}
}
//6.如果数据体ByteBuffer还没有分配,且requestedBufferSize赋值,就分配requestedBufferSize字节大小的内存空间
if (buffer == null && requestedBufferSize != -1) { //we know the size we want but havent been able to allocate it yet
buffer = memoryPool.tryAllocate(requestedBufferSize);
if (buffer == null)
log.trace("Broker low on memory - could not allocate buffer of size {} for source {}", requestedBufferSize, source);
}
// 7.如果ByteBuffer分配成功就把channel里的数据读到buffer中
if (buffer != null) {
int bytesRead = channel.read(buffer);
if (bytesRead < 0)
throw new EOFException();
read += bytesRead;
}
return read;
}
可以看到,readFrom() 方法主要是把对应 channel 中的数据读到 ByteBuffer 中,具体的步骤如下。
判断 size 是否读完了,如果没读完就接着读。因为接收数据的前 4 个字节表示响应头,而 size 长度也是 4 个字节,所以正好读完响应头,响应头表示的是数据体的长度。
通过调用 Java NIO 底层的方法 channel.read(size),把数据体的大小读到 size 中。
把读取的长度累加到总长度中。
如果表示 size 的数据读完了,就把 size 的 int 数值赋给 receiveSize,receiveSize 表示响应体的长度。
如果有异常就抛出,包括数据体的长度大于最大长度、数据体的长度无效等。
如果数据体 ByteBuffer 还没有分配,且 requestedBufferSize 没有赋值,就分配 requestedBufferSize 字节大小的内存空间。
如果 ByteBuffer 分配成功,就把 channel 里的数据读到表示响应体的 buffer 中。
NetworkSend
读 Buffer 的封装讲完了,我们接着讲讲用来写的 Buffer。下图是写 Buffer 的相关接口和类的关系图:
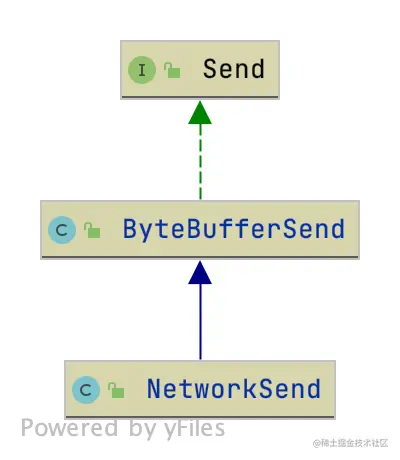
我们先看一下接口 Send 都定义了哪些方法。
接口 Send 定义了发送数据 buffer 的方法,如下所示:
public interface Send {
/**
* channel id
*/
String destination();
/**
* 数据是否发送完成
*/
boolean completed();
/**
* 把数据写到channel中
*/
long writeTo(GatheringByteChannel channel) throws IOException;
/**
* 发送数据的大小
*/
long size();
}
这里我简单介绍下代码中所包含方法的含义。
destination():要把数据写入 channel id。
completed():要发送的数据是否发送完了。
writeTo():把数据往指定的 channel 里写。
size():发送数据的大小。
ByteBufferSend 这个抽象类实现了上面的接口 Send,也实现了数据从 ByteBuffer 数组发送到 channel,对应字段如下所示:
private final String destination; //channel id
private final int size; //一共要写多少字节
protected final ByteBuffer[] buffers;//用于写入channel里的ByteBuffer数组
private int remaining;//一共还剩多少字节没有写完
private boolean pending = false;
public ByteBufferSend(String destination, ByteBuffer... buffers) {
this.destination = destination;
this.buffers = buffers;
for (ByteBuffer buffer : buffers)
remaining += buffer.remaining();
this.size = remaining;//计算需要写入字节的总和
}
其中,重要的字段有以下几个。
buffers:ByteBuffer 数组,承载了要写进 channel 的数据。
remaining:表示 ByteBuffer 数组内所有 ByteBuffer 还剩多少字节没有写。
size:需要往 channel 中写入多少字节。
destination:这里指 channel id,就是数据写到哪里。
下面我重点介绍下 writeTo() 方法,这是负责真正写数据的方法,与 readFrom() 读数据是对应的。其他方法比较简单,你可以自行学习。
writeTo() 方法是把 buffer 数组写入 SocketChannel 中,代码如下所示:
//把buffer数组写入传输层中
@Override
public long writeTo(GatheringByteChannel channel) throws IOException {
//1.调用java nio底层方法把buffers写入传输层,并返回写入的字节数
long written = channel.write(buffers);
if (written < 0)
throw new EOFException("Wrote negative bytes to channel. This shouldn't happen.");
//2.修改还剩多少字节没有写进传输层
remaining -= written;
pending = TransportLayers.hasPendingWrites(channel);
return written;
}
可以看到,writeTo() 方法首先把 buffers 写入 channel 中,我前面说过,写一次不一定能把数据全都写成功,底层 channel.write() 会返回一个“写成功了多少字节”的返回值,我们利用这个返回值就能知道调用一次写操作究竟写入了多少字节。
NetworkSend 这个类继承了 ByteBufferSend,是我们真正用于写 Buffer 的类,字段如下所示:
public class NetworkSend extends ByteBufferSend {
//实例化
public NetworkSend(String destination, ByteBuffer buffer) {
super(destination, sizeBuffer(buffer.remaining()), buffer);
}
//构造4个字节的sizeBuffer
private static ByteBuffer sizeBuffer(int size) {
//声明4个字节的ByteBuffer
ByteBuffer sizeBuffer = ByteBuffer.allocate(4);
sizeBuffer.putInt(size);
//写结束,更新postion的位置
sizeBuffer.rewind();
return sizeBuffer;
}
}
NetworkSend 类实例化的过程是:先分配长度为 4 个字节的 ByteBuffer 的变量 sizeBuffer,再把要发送的数据长度赋值给 sizeBuffer。这样 sizeBuffer 的字节数和 sizeBuffer 的数据就都有了,正好对应了前面 NetworkReceive 类对 ByteBuffer 的处理。
KafkaChannel
到这里,读写缓存区的内容我们就讲完了,接下来我再给你分析一下 KafkaChannel,这个类封装了我们上面讲的 TransportLayer、NetworkReceive、NetworkSend 的使用,代码如下所示:
public class KafkaChannel implements AutoCloseable {
......忽略
private final String id;// channel id
private final TransportLayer transportLayer;//传输层对象
private final Supplier<Authenticator> authenticatorCreator;
private final int maxReceiveSize; //能收到请求的最大字节数
private final MemoryPool memoryPool;//负责分配指定大小的ByteBuffer
//读时的缓存
private NetworkReceive receive;
//写时的缓存
private Send send;
private boolean disconnected;//是否连接关闭
private ChannelState state;//连接状态
private SocketAddress remoteAddress;//要连接的远端地址
public KafkaChannel(String id, TransportLayer transportLayer, Supplier<Authenticator> authenticatorCreator,
int maxReceiveSize, MemoryPool memoryPool, ChannelMetadataRegistry metadataRegistry) {
this.id = id;
this.transportLayer = transportLayer;
this.authenticatorCreator = authenticatorCreator;
this.authenticator = authenticatorCreator.get();
this.networkThreadTimeNanos = 0L;
this.maxReceiveSize = maxReceiveSize;//可接收的最大字节数
this.memoryPool = memoryPool;
this.metadataRegistry = metadataRegistry;
this.disconnected = false;
this.muteState = ChannelMuteState.NOT_MUTED;
this.state = ChannelState.NOT_CONNECTED;
}
其中包含的字段如下。
id:channel id。
transportLayer:传输层对象,用于调用 SocketChannel 的方法。
maxReceiveSize:能收到请求的最大字节数。
memoryPool:负责分配指定大小的 ByteBuffer,对 ByteBuffer 进行管理。
receive:NetworkReceive 类的实例。读时的缓存,上面介绍过,就不重复说明了。
send:NetworkSend 类的实例。写时的缓存,上面介绍过,就不重复说明了。
disconnected:channel 连接是否关闭。
state:ChannelState 类的实例,表示 KafkaChannel 的状态。
remoteAddress:要连接的远端地址。
KafkaChannel 的状态有以下 6 种。
NOT_CONNECTED:表示远端服务器不可用。
AUTHENTICATE:处于 SSL 验证状态。这是 SSL 等加密连接时的状态,用于 SSL 握手时的状态描述,明文连接不会有这个状态。
READY:表示连接成功。
EXPIRED:表示连接超时而关闭。
FAILED_SEND:表示连接因为发送失败而关闭。
LOCAL_CLOSE:表示主动把连接关闭。
接下来我们继续讲解 KafkaChannel 这个类包含的方法,主要有四种:setSend()、write()、read() 和 maybeCompleteReceive()。
我们先来看一下 setSend() 这个方法:
//正式发送请求前,先把请求放入send字段
public void setSend(Send send) {
if (this.send != null)
throw new IllegalStateException("Attempt to begin a send operation with prior send operation still in progress, connection id is " + id);
//设置要发送消息的字段
this.send = send;
//调用传输层关注写事件
this.transportLayer.addInterestOps(SelectionKey.OP_WRITE);
}
这个方法的主要用处就是在真正发送网络请求前,把要发送的数据保存在 send 字段里,然后调用传输层增加对这个 channel 上写事件的关注。当真正执行发送的时候,会读取 send 里的数据。
write() 方法是把保存在 send 字段上的数据真正发送出去,如下所示:
//调用写操作
public long write() throws IOException {
if (send == null)
return 0;
midWrite = true;
//调用传输层把数据真正发送出去
return send.writeTo(transportLayer);
}
首先判断要发送的 send 字段是否为零,为零说明缓存在 KafkaChannel 的 Buffer 都发送出去了,就不用再发送了;如果不为零就调用上面我们讲的 NetworkSend 类中的 writeTo() 方法把数据通过网络 IO 发送出去。
read() 方法是把从网络 IO 中读出的数据保存到字段 NetworkReceive 中,我们通过代码了解下这个方法:
//接收数据
public long read() throws IOException {
if (receive == null) {
receive = new NetworkReceive(maxReceiveSize, id, memoryPool);
}
long bytesReceived = receive(this.receive);
......忽略
return bytesReceived;
}
首先实例化一个 NetworkReceive 对象,再调用 receive() 方法把 channel 的数据读到 NetworkReceive 对象中,最后返回读到的字节数。如果没有读完下次还是读这个NetworkReceive 对象,如果读完了就新创建一个 NetworkReceive 对象。
maybeCompleteReceive() 这个方法用来判断读 Buffer 是否读完,我们同样结合代码了解其方法逻辑:
public NetworkReceive maybeCompleteReceive() {
if (receive != null && receive.complete()) {
receive.payload().rewind();
NetworkReceive result = receive;
receive = null;
return result;
}
return null;
}
判断是否读完的条件是 NetworkReceive 里的 buffer 是否用完,包括上面说过的表示 buffer 长度的 ByteBuffer 和请求本身的 ByteBuffer。这两个都读完才算真正读完了。
总结
这一讲我们介绍了 Kafka 对 Java NIO 的封装,包括 SocketChannel 和 ByteBuffer。
SocketChannel 封装类 TransportLayer 实现了最基础的网络连接、网络读、网络写操作。其中,负责明文传输的是 PlaintextTransportLayer 类。
对 ByteBuffer 的封装主要是分为两块:写 Buffer 的封装 NetworkSend 和读 Buffer 的封装 NetworkReceive。通过与 PlaintextTransportLayer 类的配合,实现从 Channel 把数据读到 NetworkReceive 缓存类,以及把数据从 NetworkSend 缓存类写到 Channel。
最后,KafkaChannel 针对上述封装为上层提供了更加友好的网络连接、读写。从这里我们能看到 Kafka 对底层封装的效果,KafkaChannel 的代码更加适合 Kafka 的实际业务,同时代码有层次、扩展性也非常好。