16.消费者是如何从服务端获取消息的?
前面一节课我们介绍了订阅状态、提交和获取分区已提交offset的代码。这节课我们讨论消费者从broker拉取消息的代码和设计,主要涉及的类是Fetcher类。
我们先从入口方法开始讲解相关的流程和代码。
消费者从服务端获取消息的入口方法
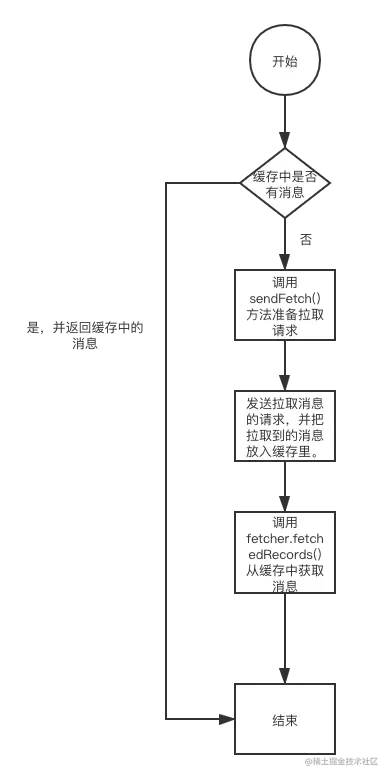
入口方法是KafkaConsumer类的 pollForFetches()方法。具体的代码如下:
private Map<TopicPartition, List<ConsumerRecord<K, V>>> pollForFetches(Timer timer) {
long pollTimeout = coordinator == null ? timer.remainingMs() :
Math.min(coordinator.timeToNextPoll(timer.currentTimeMs()), timer.remainingMs());
// 1.从缓存中获取数据
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = fetcher.fetchedRecords();
if (!records.isEmpty()) {
return records;
}
// 2.调用sendFetches()方法准备拉取请求。
fetcher.sendFetches();
if (!cachedSubscriptionHashAllFetchPositions && pollTimeout > retryBackoffMs) {
pollTimeout = retryBackoffMs;
}
log.trace("Polling for fetches with timeout {}", pollTimeout);
Timer pollTimer = time.timer(pollTimeout);
//3.发送拉取消息的请求
client.poll(pollTimer, () -> {
//因为获取消息可能被后台线程完成了,为了提升业务线程的效率,就不应该阻塞没有必要的poll()。
return !fetcher.hasAvailableFetches();
});
timer.update(pollTimer.currentTimeMs());
//4.再次尝试从缓存中获取消息
return fetcher.fetchedRecords();
}
pollForFetches()方法在KafkaConsumer类中的一个while(true)循环里不断调用,从而不断地消费消息。
下面我简单描述下这个方法的步骤。
第一步,从缓存中获取分区的消息的集合。也就是说,消费者消费消息的时候,并不是直接从broker拉取,而是从消费者的缓存中拉取的。如果缓存中有消息则返回消息集合,如果没有就走下一步。
第二步,调用fetcher.sendFetches()方法准备拉取请求。
第三步,发送拉取消息的请求。同时判断如果缓存里有消息就调用不阻塞的poll()方法,否则调用有阻塞时间的poll()方法。如果有响应,消息会保存在消费者的缓存中。
第四步,再次尝试从缓存中拉取数据。因为此时消费者的缓存可能已经有消息了。
下图简单描述了拉取消息的过程:
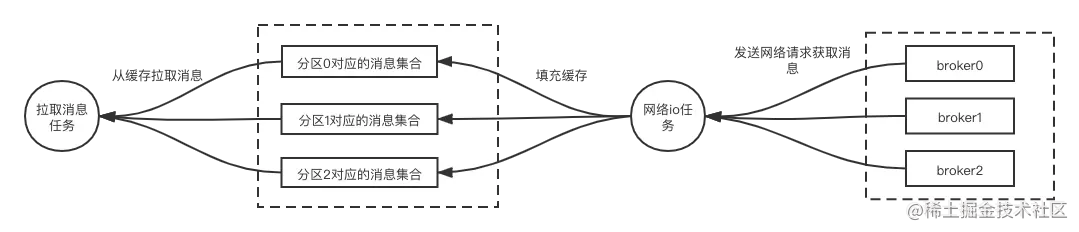
为什么消费者不是直接从broker拉取消息,而是先把消息拉取过来放入缓存再等着获取呢?
先看下下面的逻辑图
从缓存中获取数据
拉取消息任务是通过调用方法fetcher.fetchedRecords()从缓存读消息的,我们来看下相关源码:
public Map<TopicPartition, List<ConsumerRecord<K, V>>> fetchedRecords() {
//1.构建map,map存储用来拉取的分区对应的消息数据。
Map<TopicPartition, List<ConsumerRecord<K, V>>> fetched = new HashMap<>();
Queue<CompletedFetch> pausedCompletedFetches = new ArrayDeque<>();
//2.获取的最多的拉取消息,默认500个
int recordsRemaining = maxPollRecords;
try {
//3.轮询
while (recordsRemaining > 0) {
//4.如果当前获取消息的 nextInLineFetch 为空,或者已经拉取完毕
//则需要从completedFetches重新获取
if (nextInLineFetch == null || nextInLineFetch.isConsumed) {
//5.如果上一个分区缓存中的缓存已经拉取完了,直接中断本次拉取,返回空的消息直到有缓存数据为止
CompletedFetch records = completedFetches.peek();
if (records == null) break;
if (records.notInitialized()) {
try {
nextInLineFetch = initializeCompletedFetch(records);
} catch (Exception e) {
FetchResponse.PartitionData<Records> partition = records.partitionData;
if (fetched.isEmpty() && (partition.records() == null || partition.records().sizeInBytes() == 0)) {
completedFetches.poll();
}
throw e;
}
} else {
nextInLineFetch = records;
}
completedFetches.poll();
} else if (subscriptions.isPaused(nextInLineFetch.partition)) {
pausedCompletedFetches.add(nextInLineFetch);
nextInLineFetch = null;
} else {
//6.从分区缓存中获取指定数量的消息
List<ConsumerRecord<K, V>> records = fetchRecords(nextInLineFetch, recordsRemaining);
//7.把获取的消息进行封装
if (!records.isEmpty()) {
TopicPartition partition = nextInLineFetch.partition;
List<ConsumerRecord<K, V>> currentRecords = fetched.get(partition);
if (currentRecords == null) {
fetched.put(partition, records);
} else {
List<ConsumerRecord<K, V>> newRecords = new ArrayList<>(records.size() + currentRecords.size());
newRecords.addAll(currentRecords);
newRecords.addAll(records);
fetched.put(partition, newRecords);
}
recordsRemaining -= records.size();
}
}
}
} catch (KafkaException e) {
if (fetched.isEmpty())
throw e;
} finally {
completedFetches.addAll(pausedCompletedFetches);
}
return fetched;
}
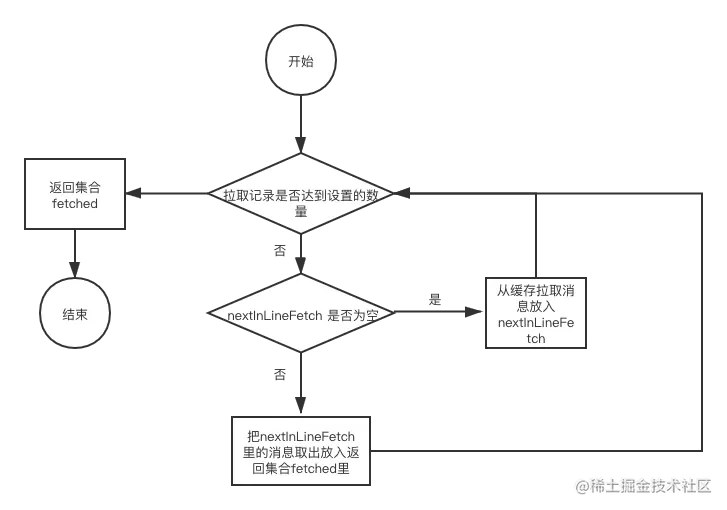
我们来学习一下从缓存中获取消息的步骤。
第一步,构建map类型的变量fetched,map里保存了分区和分区对应的消费到的消息列表,方法的返回值就是fetched。
第二步,定义变量recordsRemaining,表示一次获取多少个消息,也就是fetched变量里的消息数量。这个参数可以通过配置文件进行修改,对应配置文件的参数是max.poll.records,默认值是500。
第三步,通过while不断从缓存中获取消息,直到获取的消息为recordsRemaining设定的消息量。
第四步,判断nextInLineFetch是否为空,如果为空则需要从completedFetches集合获取消息。nextInLineFetch是一个CompletedFetch类型,是一个分区的消息集合。
第五步,completedFetches集合是否为空,如果为空说明缓存里没有消息,这样方法就会直接返回空的集合。如果completedFetches集合不为空就把集合中一个类型为CompletedFetch的元素给nextInLineFetch。
第六步,如果nextInLineFetch不为空,就从nextInLineFetch取出消息。
第七步,把获取的消息进行封装。
第八步,返回fetched集合。
下图是步骤的流程图,可以帮助你更好地理解:
好,我们再看下真正拉取消息的准备工作都做了些什么,相关代码主要在Fetcher类里的方法sendFetches()里。
FetchRequest请求的准备工作
sendFetches() 方法相关源码如下:
public synchronized int sendFetches() {
sensors.maybeUpdateAssignment(subscriptions);
//1.封装node对应的fetch请求的map。
Map<Node, FetchSessionHandler.FetchRequestData> fetchRequestMap = prepareFetchRequests();
for (Map.Entry<Node, FetchSessionHandler.FetchRequestData> entry : fetchRequestMap.entrySet()) {
//3.按node分别做发送请求的准备工作。
final Node fetchTarget = entry.getKey();
final FetchSessionHandler.FetchRequestData data = entry.getValue();
//4 构建请求
final FetchRequest.Builder request = FetchRequest.Builder
.forConsumer(this.maxWaitMs, this.minBytes, data.toSend())
.isolationLevel(isolationLevel)
.setMaxBytes(this.maxBytes)
.metadata(data.metadata())
.toForget(data.toForget())
.rackId(clientRackId);
if (log.isDebugEnabled()) {
log.debug("Sending {} {} to broker {}", isolationLevel, data.toString(), fetchTarget);
}
//5 把请求放入ConsumerNetworkClient的缓存中
RequestFuture<ClientResponse> future = client.send(fetchTarget, request);
this.nodesWithPendingFetchRequests.add(entry.getKey().id());
//6.配置响应的监听器。
future.addListener(new RequestFutureListener<ClientResponse>() {
@Override
public void onSuccess(ClientResponse resp) {
忽略......
}
@Override
public void onFailure(RuntimeException e) {
忽略......
});
}
return fetchRequestMap.size();
}
第一步,封装所有node对应的FetchRequest请求的map集合。
第二步,遍历这个集合,在循环中向每一个node发送fetch请求。
第三步,按node分别做发送请求的准备工作。
第四步,构建FetchRequest请求。
第五步,把请求放入ConsumerNetworkClient的缓存集合unsent中。
第六步,给请求配置监听器,用来处理响应,具体的操作其实就是把响应处理后放入缓存completedFetches集合里,等待消费者从completedFetches集合拉取。
发送拉取消息的请求
真正发送拉取消息的请求还是ConsumerNetworkClient类里的方法 poll() 完成的。
client.poll(pollTimer, () -> {
//因为获取消息可能被后台线程完成了,为了提升业务线程的效率,就不应该阻塞没有必要的poll()。
return !fetcher.hasAvailableFetches();
});
可以看到这里有个匿名方法:() -> { return !fetcher.hasAvailableFetches(); }。
这个方法的含义是:当缓存中的消息对应的分区都是不可获取时,Selector.poll()方法就不会阻塞,因为既然消费者不能获取所有分区的消息那么拉取也就没意义了。分区是否能拉取是由SubscriptionState类里的属性控制的。
总结
这节课我们学习了消费者是如何获取消息的。
获取消息的设计思想是:消费者不断地把消息放入消费者的缓存集合中,然后消费者再从缓存集合中获取消息,这两个步骤是异步的,这样拉取消息和网络拉取消息这两个步骤就解耦了,就大大提升了消费者的性能。
具体的步骤分三个:
从缓存拉取消息;
准备发送拉取消息的请求;
真正发起拉取消息的请求。
pollForFetches()在消息消费中的作用非常关键,主要体现在以下几个方面:
缓存优先:
方法首先尝试从消费者的本地缓存中获取消息,这减少了对网络的依赖,降低了延迟。如果缓存中有消息,消费者可以立即处理,而无需等待从broker拉取数据。
高效的网络请求:
只有在缓存为空时,消费者才会向broker发送拉取请求。这种设计优化了网络使用,避免了不必要的请求,从而提升了整体性能。
非阻塞与阻塞的灵活处理:
根据缓存的状态,
pollForFetches()会选择不同的poll()方法。如果缓存有消息,调用非阻塞的poll(),这样消费者可以继续处理消息;如果没有消息,则使用带阻塞的poll(),确保在一定时间内等待消息的到来。这种灵活性使得消费者在处理消息时既能保持高效,又不会陷入无效的等待。
消息的批量处理:
拉取请求通常会以批量的形式从broker获取消息,这样可以减少网络往返的次数,提升处理效率。
pollForFetches()确保了这些消息能够及时存入缓存中,供后续处理使用。
提高吞吐量:
通过优化网络请求和本地缓存的使用,
pollForFetches()有助于提高消费者的吞吐量,使得系统能够处理更多的消息。
总结来说,pollForFetches()通过有效地利用缓存和优化网络请求,确保消费者能够高效、灵活地消费消息,是Kafka消费者架构中的一个重要组成部分。如果你想了解某个特定的实现细节或性能优化措施,请告诉我!
消费者不是直接从broker拉取消息,而是先将消息拉取到缓存中,主要是为了提高性能和效率,原因如下:
减少网络延迟:
直接从broker拉取消息可能导致频繁的网络请求,而将消息拉取到本地缓存中可以显著降低延迟,消费者可以更快地获取和处理消息。
提高吞吐量:
批量拉取消息到缓存可以减少网络往返次数,增加每次请求中获取的消息数量,从而提升整体吞吐量。
负载均衡:
通过缓存机制,消费者可以在处理消息时更灵活地分配资源,避免在高负载情况下频繁与broker通信,降低了broker的压力。
容错性:
如果网络出现问题,消费者依然可以从缓存中获取之前拉取的消息,确保消息的连续处理和系统的稳定性。
更好的控制:
消费者可以通过调整缓存的策略(如缓存大小、过期策略等)来优化性能,以适应不同的工作负载和应用场景。
总之,使用缓存机制使得Kafka消费者在处理消息时更加高效、灵活和稳定。你是否有兴趣探讨具体的缓存策略或实现细节?
是的,fetcher.fetchedRecords()方法用于从消费者的本地缓存中读取已拉取的消息。这个过程在消息消费中起着重要作用,主要体现在以下几个方面:
高效访问:
通过从缓存中读取消息,消费者可以快速访问数据,避免了额外的网络延迟。这在高频率消费场景中尤为重要,可以显著提升处理速度。
优化性能:
本地缓存通常比直接访问broker要快得多,尤其是在高负载情况下。这样可以有效提高消息的处理速率,增加系统的吞吐量。
简化控制逻辑:
当消费者尝试从缓存中读取消息时,它可以集中处理来自不同分区的消息,这简化了处理逻辑并提高了代码的可读性。
降低资源消耗:
如果消费者频繁地请求broker而不使用缓存,可能会增加网络流量和资源消耗。使用缓存可以减少对broker的请求,降低整体负载。
实现消息的顺序消费:
在Kafka中,消息的顺序性很重要。通过将消息缓存到本地,消费者可以确保按照正确的顺序处理这些消息。
通过这种方式,fetcher.fetchedRecords()不仅提高了消息处理的效率,还提升了系统的整体稳定性和性能。如果你对具体的实现细节或性能优化有进一步的兴趣,请告诉我!
没错,真正发送拉取消息请求的是ConsumerNetworkClient类中的poll()方法。这个方法在Kafka消费者中扮演着关键角色,其主要功能包括:
管理网络请求:
poll()负责发送请求到broker,并接收响应。这使得消费者能够从多个分区拉取消息,保持与broker的连接。
处理异步响应:
在发送拉取请求后,
poll()能够异步接收响应消息,并将这些消息存入消费者的缓存中,以供后续处理。
支持非阻塞和阻塞模式:
根据消费者的需求,
poll()可以配置为非阻塞或阻塞模式,从而灵活应对不同的场景,比如等待新消息的到来。
维护心跳和会话:
poll()还负责发送心跳信号,以维护消费者与Kafka集群的会话,确保消费者不会因超时而被踢出。
错误处理:
方法中包含错误处理逻辑,可以对网络故障或broker不可用等情况进行应对,增强系统的健壮性。
总之,ConsumerNetworkClient的poll()方法是Kafka消费者与broker交互的核心,确保了消息的有效拉取和处理。如果你想了解更多关于这个方法的实现细节或相关机制,随时告诉我!
以下是对上述 Kafka 获取消息设计思想及步骤的详细分析: 一、设计思想 Kafka 让消费者不断地将消息放入消费者的缓存集合,再从缓存集合获取消息,且这两个步骤异步进行,具有以下显著优势: 1. 解耦操作 - 拉取消息和网络拉取消息两个关键步骤解耦,使得系统各部分功能更加独立,降低了模块之间的耦合度。这样在进行功能优化、故障排查或扩展时,可以更加有针对性地对特定部分进行处理,而不会对整个系统造成广泛影响。 - 例如,当网络拉取消息部分出现问题时,不会直接影响到消费者从缓存集合获取消息的操作,从而提高了系统的稳定性和可靠性。 2. 提升性能 - 异步操作允许消费者在等待网络拉取消息的同时,可以继续从缓存集合中获取已有的消息进行处理。这种并行处理方式充分利用了系统资源,避免了因等待网络响应而导致的处理停滞,大大提升了消费者的性能。 - 例如,在高并发的场景下,消费者可以快速地从缓存中获取消息进行处理,而不必等待每次网络拉取的延迟,从而提高了消息处理的吞吐量和响应速度。 二、具体步骤 1. 从缓存拉取消息 - 这一步骤是消费者获取消息的直接操作。消费者首先从本地缓存集合中查找可用的消息。如果缓存中有消息,消费者可以立即获取并进行处理,无需等待网络拉取。 - 缓存的存在可以减少对网络的频繁访问,降低网络延迟对消息处理的影响。同时,缓存还可以存储一些已经拉取但尚未处理完的消息,以便在需要时快速恢复处理状态。 - 例如,当消费者处理消息的速度较快,而网络拉取消息的速度相对较慢时,缓存可以提供一个缓冲区域,确保消费者始终有消息可处理。 2. 准备发送拉取消息的请求 - 在这一步骤中,消费者开始为从 Kafka 服务器拉取新的消息做准备。它会构建拉取消息的请求,包括指定要拉取的主题、分区、偏移量等信息。 - 准备请求的过程需要考虑多种因素,如消费者的订阅状态、当前处理的进度以及 Kafka 集群的配置等。通过精心准备请求,可以确保拉取到的消息是消费者真正需要的,并且能够高效地进行处理。 - 例如,消费者可以根据自己的处理能力和需求,合理地设置每次拉取的消息数量,以平衡性能和资源消耗。 3. 真正发起拉取消息的请求 - 当请求准备好后,消费者会通过网络向 Kafka 服务器发起拉取消息的请求。这个请求会被发送到 Kafka 集群中的相应节点,由节点根据请求的参数从存储中获取消息并返回给消费者。 - 网络拉取消息的过程可能会受到网络延迟、服务器负载等因素的影响。因此,消费者需要对拉取请求的响应进行合理的处理,包括处理错误情况、重试机制等。 - 例如,如果网络出现故障或者服务器响应超时,消费者可以根据预设的重试策略进行多次尝试,以确保能够成功拉取到消息。 综上所述,Kafka 的这种获取消息的设计思想和具体步骤,通过异步操作和缓存机制,有效地提升了消费者的性能和系统的稳定性,为大规模分布式消息处理提供了可靠的解决方案。
如何保证 Kafka 消费者在处理消息时的幂等性?
幂等性的概念
幂等性是指对同一操作的多次重复执行所产生的影响均与一次执行的影响相同。在 Kafka 消费者处理消息的场景中,幂等性意味着无论消息被消费多少次,其对系统状态的最终影响都是一样的。例如,在一个记录用户点赞数的系统中,一条 “用户点赞” 的消息被多次消费,但最终用户的点赞数只会增加一次,这就是幂等性的体现。
保证幂等性的方法
利用数据库的唯一约束
原理:在将消息处理的结果持久化到数据库时,可以利用数据库的主键或者唯一约束来保证幂等性。例如,在一个订单处理系统中,消费者接收到订单消息后,会将订单信息插入到订单表中。如果将订单编号设置为主键,当相同的订单消息被多次处理时,由于数据库主键的唯一性约束,第二次及以后的插入操作会失败,从而保证了只有一次订单信息被插入,实现了幂等性。
示例:假设使用关系型数据库(如 MySQL)来处理订单消息。当消费者接收到订单消息后,执行以下 SQL 插入语句:
INSERT INTO orders (order_id, customer_id, product_id) VALUES ('12345', '67890', '77777')。如果order_id是主键,当相同的订单消息再次被处理时,数据库会抛出主键冲突的错误,避免了重复插入订单信息。
使用消息的唯一标识和状态记录
原理:为每条消息分配一个唯一标识(如消息 ID),在消费者端维护一个已处理消息的状态记录。当消费者接收到消息时,首先检查该消息的唯一标识是否已经在已处理状态记录中。如果是,则说明该消息已经被处理过,直接跳过;如果否,则处理该消息,并将其唯一标识添加到已处理状态记录中。这种状态记录可以存储在数据库、缓存(如 Redis)或者本地文件中。
示例:假设消费者使用 Redis 来记录已处理消息的状态。当收到一条消息时,先从消息中获取消息 ID,然后在 Redis 中检查是否存在名为
processed_messages的集合,并且该消息 ID 是否在这个集合中。如果不存在,可以使用SADD processed_messages <message_id>命令将消息 ID 添加到集合中,并处理该消息;如果已经存在,则跳过该消息的处理。
通过事务机制实现幂等性
原理:如果消费者在处理消息时涉及多个操作(例如,先更新库存,再记录销售记录),可以将这些操作放在一个事务中。当事务成功提交时,表示消息处理完成;如果事务因为任何原因失败,回滚所有操作,这样保证了消息处理的原子性和幂等性。在分布式系统中,可以使用分布式事务协议(如 Seata)来实现跨多个数据源的事务处理。
示例:在一个电商系统中,消费者处理销售消息时,需要同时更新库存表和插入销售记录表。可以使用数据库的事务机制,如在 MySQL 中使用
START TRANSACTION; UPDATE inventory SET quantity = quantity - 1 WHERE product_id = '123'; INSERT INTO sales (product_id, customer_id) VALUES ('123', '456'); COMMIT;这样的语句来保证这两个操作要么同时成功,要么同时失败。如果因为网络原因或者其他异常导致事务提交失败,整个操作会回滚,再次处理相同的销售消息时,会重新执行这一系列操作,保证了幂等性。
17.消费者的整体流程是怎样的?
消费者代码案例
当我们想写一个消费者程序的时候,可以大致看一下消费程序的代码:
public class Consumer extends ShutdownableThread {
private final KafkaConsumer<Integer, String> consumer;
private final String topic;
private final String groupId;
private final int numMessageToConsume;
private int messageRemaining;
private final CountDownLatch latch;
public Consumer(final String topic,
final String groupId,
final Optional<String> instanceId,
final boolean readCommitted,
final int numMessageToConsume,
final CountDownLatch latch) {
super("KafkaConsumerExample", false);
this.groupId = groupId;
//1.初始化配置对象和设置配置对象的属性
Properties props = new Properties();
//指定kafka集群地址
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, KafkaProperties.KAFKA_SERVER_URL + ":" + KafkaProperties.KAFKA_SERVER_PORT);
//消费者组id
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
instanceId.ifPresent(id -> props.put(ConsumerConfig.GROUP_INSTANCE_ID_CONFIG, id));
//自动提交偏移量
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
//自动提交偏移量的时间间隔。
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
//consumer group多久收不到 consumer 的心跳就认为consumer不在consumer group里了
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "30000");
//key的反序列化类
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.IntegerDeserializer");
//value的反序列化类
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
if (readCommitted) {
props.put(ConsumerConfig.ISOLATION_LEVEL_CONFIG, "read_committed");
}
//设置重启后从哪里开始消费
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
//2.实例化新的KafkaConsumer类对象。
consumer = new KafkaConsumer<>(props);
//3.设置用于消费的属性。
//设置主题
this.topic = topic;
//设置消费消息的数量
this.numMessageToConsume = numMessageToConsume;
//剩余消费消息的数量
this.messageRemaining = numMessageToConsume;
//设置latch,从上层调用者控制消费者
this.latch = latch;
}
KafkaConsumer<Integer, String> get() {
return consumer;
}
@Override
public void doWork() {
//1.设置订阅的消费主题。
consumer.subscribe(Collections.singletonList(this.topic));
//2.开始消费主题。
ConsumerRecords<Integer, String> records = consumer.poll(Duration.ofSeconds(1));
//3.消费到的消息打印出来。
for (ConsumerRecord<Integer, String> record : records) {
System.out.println(groupId + " received message : from partition " + record.partition() + ", (" + record.key() + ", " + record.value() + ") at offset " + record.offset());
}
messageRemaining -= records.count();
//4.消费完成,上层调用的主线程阻塞解除。
if (messageRemaining <= 0) {
System.out.println(groupId + " finished reading " + numMessageToConsume + " messages");
latch.countDown();
}
}
@Override
public String name() {
return null;
}
@Override
public boolean isInterruptible() {
return false;
}
}
Kafka Consumer示例代码主要分为两个部分:第一个部分是KafkaConsumer类的初始化,第二部分是KafkaConsumer类开始从服务端拉取消息。下面我分别讲解一下。
KafkaConsumer 的初始化部分
第一步,初始化配置对象和设置配置对象的属性。包括实例化Properties,然后配置相关属性。包括:
指定Kafka集群地址,因为消费者要拉取毕竟要从服务端拉取的,所以要配置服务端的地址,包括ip和端口。服务端的地址是可能是多个。格式如下:node01:9092, node02:9092, node03:9092。
消费组id。因为kafka是按照消费组来分配消费分区的,所以要指定消费者所在的消费组id。
是否自动提交偏移量。消费者成功消费完消息后要提交消息在分区的偏移量,这样再次消费时能从已提交偏移量之后继续进行消费。提交偏移量分为两种,自动提交和手动提交,这里设置为true就是自动提交,否则就是手动提交。
自动提交偏移量的时间间隔。如果用户选择了自动提交偏移量那么就可以在这里设置向服务端consumer group自动提交偏移量的事件间隔。如果设置的间隔时间过长会造成consumer group数据滞后造成重复消费。如果设置的间隔时间过短,会造成consumer group压力过大,可以根据实际情况进行设置。
设置key的反序列化类和value的反序列化类。这里的反序列化类要对应生产者发送消息的序列化类否则反序列化会失败。
设置重启后从哪里开始消费。包括earliest,latest,earliest指从分区第一个的offset消费。latest指从分区最后一个offset消费。
第二步,根据配置的Properties属性实例化 KafkaConsumer,同时KafkaConsumer会初始化一下核心组件。初始化了哪些组件,组件是如何初始化的,本文后面会给大家介绍。
第三步,设置用于消费的一些属性。包括:
配置要消费的主题。
这次要消费的记录数。因为仅仅是个消费实例不需要消费太多的记录。
配置Latch。用于上层调用方线程和消费线程的同步。
好,初始化大体就介绍完了,我们接着看示例代码中关于消费者拉取消息的部分
KafkaConsumer 的拉取消息部分
拉取消息的代码在 dowork() 方法里。我把步骤给你说明一下。
第一步,设置订阅的主题。
第二步,开始消费主题的一批消息。消费者消费一次是一批消费的,这样的好处是减少了网络io的负载。
第三步,把消费到的消息打印出来。
第四步,当拉取的消息的数量达到了设置的消息数,就执行latch.countDown()解除上层的业务主线程的阻塞。
好,接下来我们将分别介绍KafkaConsumer对核心组件的初始化和消费者拉取消息的过程。
KafkaConsumer 对核心组件的初始化过程
首先,还是看下源码:
public KafkaConsumer(Map<String, Object> configs,
Deserializer<K> keyDeserializer,
Deserializer<V> valueDeserializer) {
ConsumerConfig config = new ConsumerConfig(ConsumerConfig.appendDeserializerToConfig(configs, keyDeserializer, valueDeserializer));
try {
GroupRebalanceConfig groupRebalanceConfig = new GroupRebalanceConfig(config,
GroupRebalanceConfig.ProtocolType.CONSUMER);
//获取消费组id
this.groupId = Optional.ofNullable(groupRebalanceConfig.groupId);
//获取消费者id
this.clientId = config.getString(CommonClientConfigs.CLIENT_ID_CONFIG);
忽略......
//设置key和value的反序列化类。
if (keyDeserializer == null) {
this.keyDeserializer = config.getConfiguredInstance(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, Deserializer.class);
this.keyDeserializer.configure(config.originals(Collections.singletonMap(ConsumerConfig.CLIENT_ID_CONFIG, clientId)), true);
} else {
config.ignore(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG);
this.keyDeserializer = keyDeserializer;
}
忽略......
//设置重启后消费策略。
OffsetResetStrategy offsetResetStrategy = OffsetResetStrategy.valueOf(config.getString(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG).toUpperCase(Locale.ROOT));
//初始化订阅状态。
this.subscriptions = new SubscriptionState(logContext, offsetResetStrategy);
ClusterResourceListeners clusterResourceListeners = configureClusterResourceListeners(keyDeserializer,
valueDeserializer, metrics.reporters(), interceptorList);
//初始化消费者元数据
this.metadata = new ConsumerMetadata(retryBackoffMs,
config.getLong(ConsumerConfig.METADATA_MAX_AGE_CONFIG),
!config.getBoolean(ConsumerConfig.EXCLUDE_INTERNAL_TOPICS_CONFIG),
config.getBoolean(ConsumerConfig.ALLOW_AUTO_CREATE_TOPICS_CONFIG),
subscriptions, logContext, clusterResourceListeners);
//忽略......
ApiVersions apiVersions = new ApiVersions();
//初始化底层通信模块
NetworkClient netClient = new NetworkClient(
new Selector(config.getLong(ConsumerConfig.CONNECTIONS_MAX_IDLE_MS_CONFIG), metrics, time, metricGrpPrefix, channelBuilder, logContext),
this.metadata,
clientId,
100, config.getLong(ConsumerConfig.RECONNECT_BACKOFF_MS_CONFIG),
config.getLong(ConsumerConfig.RECONNECT_BACKOFF_MAX_MS_CONFIG),
config.getInt(ConsumerConfig.SEND_BUFFER_CONFIG),
config.getInt(ConsumerConfig.RECEIVE_BUFFER_CONFIG),
config.getInt(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG),
config.getLong(ConsumerConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MS_CONFIG),
config.getLong(ConsumerConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MAX_MS_CONFIG),
ClientDnsLookup.forConfig(config.getString(ConsumerConfig.CLIENT_DNS_LOOKUP_CONFIG)),
time,
true,
apiVersions,
throttleTimeSensor,
logContext);
//初始化消费者通信模块
this.client = new ConsumerNetworkClient(
logContext,
netClient,
metadata,
time,
retryBackoffMs,
config.getInt(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG),
heartbeatIntervalMs); //Will avoid blocking an extended period of time to prevent heartbeat thread starvation
this.assignors = getAssignorInstances(config.getList(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG), config.originals());
// 初始化协调者模块
// no coordinator will be constructed for the default (null) group id
this.coordinator = !groupId.isPresent() ? null :
new ConsumerCoordinator(groupRebalanceConfig,
logContext,
this.client,
assignors,
this.metadata,
this.subscriptions,
metrics,
metricGrpPrefix,
this.time,
enableAutoCommit,
config.getInt(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG),
this.interceptors,
config.getBoolean(ConsumerConfig.THROW_ON_FETCH_STABLE_OFFSET_UNSUPPORTED));
//初始化获取消息的模块
this.fetcher = new Fetcher<>(
logContext,
this.client,
config.getInt(ConsumerConfig.FETCH_MIN_BYTES_CONFIG),
config.getInt(ConsumerConfig.FETCH_MAX_BYTES_CONFIG),
config.getInt(ConsumerConfig.FETCH_MAX_WAIT_MS_CONFIG),
config.getInt(ConsumerConfig.MAX_PARTITION_FETCH_BYTES_CONFIG),
config.getInt(ConsumerConfig.MAX_POLL_RECORDS_CONFIG),
config.getBoolean(ConsumerConfig.CHECK_CRCS_CONFIG),
config.getString(ConsumerConfig.CLIENT_RACK_CONFIG),
this.keyDeserializer,
this.valueDeserializer,
this.metadata,
this.subscriptions,
metrics,
metricsRegistry,
this.time,
this.retryBackoffMs,
this.requestTimeoutMs,
isolationLevel,
apiVersions);
//忽略......
}
我给你分析一下KafkaConsumer初始化核心组件的源码。
第一步,上一步的初始化过程中我们配置了一些参数数值。这一步根据这些参数真正配置到KafkaConsumer类中。包括获取消费组id、获取消费者id、key和value的反序列化类,以及设置重启后消费策略。
第二步,根据重启消费策略初始化SubscriptionState订阅状态类。订阅状态类用于保存订阅的主题和分区,以及分区消费的偏移量。
第三步,初始化消费者元数据组件。
第四步,初始化NetworkClient底层通信模块。因为消费者需要从服务端拉取消息,这样就消费者需要构建这样的组件与服务端进行大量的网络通信。NetworkClient初始化底层是封装Selector组件的,也就是说用的nio的nio网络模型。
第五步,初始化ConsumerNetworkClient。ConsumerNetworkClient是基于NetworkClient的有一次封装,消费者直接调用ConsumerNetworkClient就可以完成与服务端的通信。
第六步,初始化ConsumerCoordinator对象,服务消费者和服务端的GroupCoordinator通信。
第七步,初始化Fetcher对象,对ConsumerNetworkClient进行封装并负责从服务端获取消息。
KafkaConsumer在初始化过程中就会帮我们把上述的组件都初始化好了。这个初始化的过程涉及的组件比较多,我用下面的一副图来较为形象地展示一下:
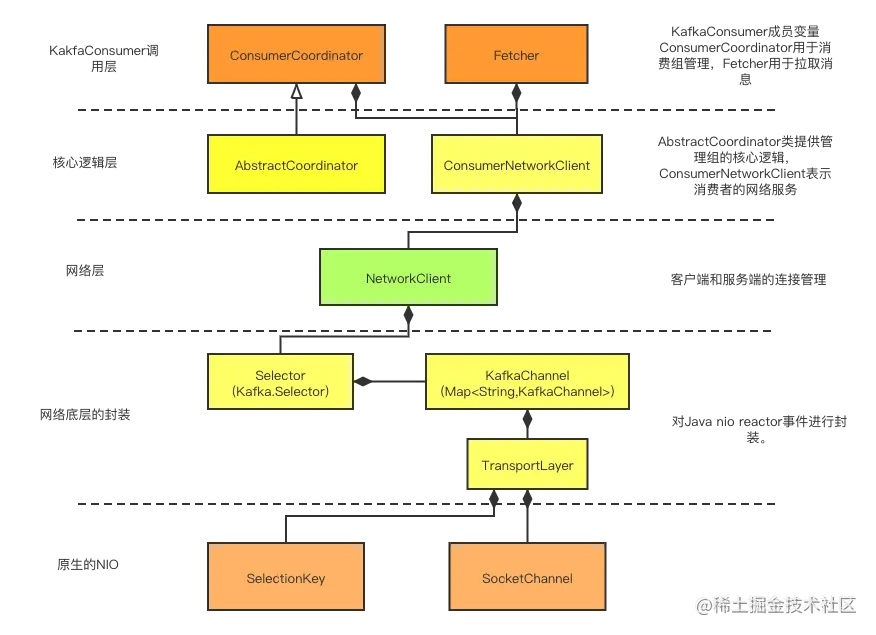
我根据这个图给你简单描述下消费者依赖的相关组件。
首先,KafkaConsumer直接调用的组件有两个ConsumerCoordinator和Fetcher。ConsumerCoordinator用于消费组的管理。Fetcher用于从服务端拉取消息。
下一层是核心逻辑层,AbstractCoordinator提供管理消费组的核心逻辑,ConsumerNetworkClient是为消费组提供网络服务的组件,封装了底层NetworkClient类。
再往下一层是网络层,NetworkClient提供客户端和服务端直接的网络通信。
然后再往下是Reator封装,包括前面介绍的组件Selector、KafkaChannel、TransportLayer。最底层是原生的java nio。
初始化结束后,KafkaConsumer需要把消息拉取过来进行处理。
以下是对 KafkaConsumer 拉取消息过程的详细介绍:
一、核心组件初始化
在使用 KafkaConsumer 进行消息消费之前,通常需要对其核心组件进行初始化。这包括设置消费者的配置参数,如 bootstrap.servers(Kafka 集群地址)、group.id(消费者组 ID)等。通过合理配置这些参数,可以确保消费者能够正确地连接到 Kafka 集群,并以期望的方式进行消息消费。
二、消费者拉取消息过程
设置订阅的主题:
这是消费消息的第一步,明确消费者要从哪些主题中获取消息。通过调用
subscribe()方法,可以指定一个或多个主题,让消费者关注这些主题上的消息发布。例如,consumer.subscribe(Arrays.asList("topic1", "topic2"))表示消费者订阅了名为 “topic1” 和 “topic2” 的两个主题。这样的设置使得消费者能够有针对性地获取所需的消息,避免处理无关的主题数据,提高消息处理的效率。
开始消费主题的一批消息:
Kafka 消费者通常以批量的方式消费消息,这有几个显著的好处。首先,减少网络 I/O 负载是其中一个重要优势。通过一次性拉取一批消息,而不是逐个拉取消息,可以减少网络请求的次数,降低网络开销。
其次,批量处理消息可以提高消费者的处理效率。消费者可以在一次处理中对多个消息进行相同的操作,避免了频繁地启动和停止处理逻辑,从而提高了系统的整体性能。
例如,在一个日志处理系统中,消费者可以一次性拉取一批日志消息,然后对这些消息进行统一的分析和存储,而不是逐个处理每条日志,大大提高了处理速度。
把消费到的消息打印出来:
这一步通常是为了方便调试和观察消费者的工作状态。打印消费到的消息可以让开发人员了解消息的内容和格式,以及消费者是否正确地获取了消息。
在实际应用中,可以根据具体需求将消费到的消息进行更复杂的处理,如存储到数据库、进行数据分析等。打印消息只是一个简单的示例,用于展示消费者的基本功能。
当拉取的消息数量达到设置的消息数,执行 latch.countDown () 解除上层业务主线程的阻塞:
这一步骤在消费者与上层业务逻辑进行交互时非常重要。通过设置一个计数器(latch),当消费者拉取的消息数量达到预设值时,调用
latch.countDown()可以通知上层业务主线程,解除其阻塞状态。这样的机制使得上层业务可以等待消费者完成一定数量的消息处理后再进行下一步操作。例如,在一个数据处理系统中,上层业务可能需要等待消费者处理一定数量的消息后,再进行数据分析或报告生成。
通过这种方式,实现了消费者与上层业务的同步和协调,确保系统的整体运行符合预期。
综上所述,KafkaConsumer 的拉取消息过程通过合理的步骤设置和机制设计,实现了高效、可靠的消息消费,为分布式系统中的数据处理提供了强大的支持。
KafkaConsumer拉取消息的过程
拉取消息的过程是调用了KafkaConsumer的 poll() 方法,poll()方法源码如下:
private ConsumerRecords<K, V> poll(final Timer timer, final boolean includeMetadataInTimeout) {
//1.KafkaConsumer是线程不安全的,同时只能一个线程运行,
//如果有多个线程同时调用poll()会抛出异常
acquireAndEnsureOpen();
try {
this.kafkaConsumerMetrics.recordPollStart(timer.currentTimeMs());
//2.消费者的订阅的主题不能为空,如果没有指定任何主题就抛异常。
if (this.subscriptions.hasNoSubscriptionOrUserAssignment()) {
throw new IllegalStateException("Consumer is not subscribed to any topics or assigned any partitions");
}
//3.循环拉取消息,直到拉取到了消息或超时。
do {
//4.可以中断consumer。
client.maybeTriggerWakeup();
//5.判断includeMetadataInTimeout是true还是false.
if (includeMetadataInTimeout) {
//6.1更新消费分区的任务元数据,协调器,心跳,消费位置。
updateAssignmentMetadataIfNeeded(timer, false);
} else {
//6.2更新消费分区的任务元数据,协调器,心跳,消费位置。
while (!updateAssignmentMetadataIfNeeded(time.timer(Long.MAX_VALUE), true)) {
log.warn("Still waiting for metadata");
}
}
/*
7.开始拉取消息,不是真正从broker拉取消息,而是从缓存拉取消息。
这里是这样设计的:是一个优化提升,如果从缓存拉取成功了,consumer就提前发送下一次的拉取请求,
这样当你的应用在处理刚刚拉取的新纪录的时候,consumer也同时在后台为你拉取好下一次要用的数据并放在缓存里。等待业务线程拉取。
*/
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = pollForFetches(timer);
if (!records.isEmpty()) {
// before returning the fetched records, we can send off the next round of fetches
// and avoid block waiting for their responses to enable pipelining while the user
// is handling the fetched records.
//
// NOTE: since the consumed position has already been updated, we must not allow
// wakeups or any other errors to be triggered prior to returning the fetched records.
if (fetcher.sendFetches() > 0 || client.hasPendingRequests()) {
client.transmitSends();
}
//8.返回拦截器处理后的消息集合
return this.interceptors.onConsume(new ConsumerRecords<>(records));
}
} while (timer.notExpired());
return ConsumerRecords.empty();
} finally {
release();
this.kafkaConsumerMetrics.recordPollEnd(timer.currentTimeMs());
}
}
同样,我给你讲解一下这个poll()方法的大体步骤。
首先,调用acquireAndEnsureOpen()来判断是否有多个线程调用了KafkaConsumer类的方法。KafkaConsumer是一个非线程安全的类,但是有些poll()方法不能同时被多个线程访问,因为有些变量是能够在线程间共享的必须保证线程安全。于是KafkaConsumer设计了一个轻量级的锁来保证同时只有一个线程进入KafkaConsumer类的方法。具体源码如下:
private void acquireAndEnsureOpen() {
acquire();
if (this.closed) {
release();
throw new IllegalStateException("This consumer has already been closed.");
}
}
private void acquire() {
long threadId = Thread.currentThread().getId();
if (threadId != currentThread.get() && !currentThread.compareAndSet(NO_CURRENT_THREAD, threadId))
throw new ConcurrentModificationException("KafkaConsumer is not safe for multi-threaded access");
refcount.incrementAndGet();
}
private void release() {
if (refcount.decrementAndGet() == 0)
currentThread.set(NO_CURRENT_THREAD);
}
首先,acquireAndEnsureOpen()方法调用acquire()方法尝试获得轻量级锁。acquire()方法通过一个if语句判断是否抛出多线程访问的异常。同时满足下列两个条件才会抛出异常:
判断线程id是否是当前线程id,如果是那么refcount加一,表示当前线程又一次访问poll()方法了。refcount表示当前线程重入轻量级锁的次数。
尝试用CAS的方法把当前线程id赋值给currentThread,如果赋值不成功就抛出异常。CAS的方法的初始值是NO_CURRENT_THREAD即默认值-1L,也就是说如果currentThread已经是线程id了是不能赋值成功的。
那么currentThread什么时候会变成默认值-1L呢?
这个是由release()方法控制的,当KafkaConsumer内的方法结尾的时候都会调用release(),这个方法首先把refcount减一,然后判断refcount是否为零,为零说明现在的线程调用KafkaConsumer内的方法都已经结束了,就把currentThread设置为NO_CURRENT_THREAD,这样其他线程才能获得KafkaConsumer的轻量级锁。
好,我们再回到poll()方法的讲解。
第二步,当线程获得轻量级锁之后,方法会判断消费者是否订阅了主题或分配了分区,如果没有就抛出响应的异常。
第三步,循环拉取消息,直到拉取到了消息或超时。
第四步,判断是否被中断了,有的方法是可以中断方法的访问的,如close(),如果消费者都关闭了,那么调用poll()方法去拉取消息也就没什么意义了,中断后会抛出异常。
第五步,判断includeMetadataInTimeout是true还是false。这里一般会设为true,如果设置了false,就会走else分支,获取元数据时会阻塞一段时间直到元数据返回位置,而如果是true获取元数据时不会阻塞。
第六步,更新消费分区的任务元数据,协调器,心跳任务已经对应分区提交的偏移量。
第七步,从内存中拉取消息。
第八步,返回拦截器处理后的消息集合。
总结
又到了总结的时间,这节课我从一个消费者示例给你展示了消费者使用的方法,同时重点介绍了KafkaConsumer类的初始化和KafkaConsumer类的poll()方法。
KafkaConsumer类的初始化了消费者必须依赖的组件,包括用于上层调用的ConsumerCoordinator,Fetcher;用于核心逻辑的AbstractCoordinator,ConsumerNetworkClient;还有网络层NetworkClient;网络底层的封装以及更底层的Java nio。
poll()方法主要步骤是一开始多各种判断和获取各种拉取消息前的任务,包括判断是否是当前的线程,拉取消息前的任务包括获取协调者,分配的分区,开始心跳,获取消费分区的offset。
好,消费者的源码到此就都学习完了,从下一节课开始,我们学习服务端的源码。
18.服务端通信层:SocketServer 类和 Reactor 模式简介
SocketServer 类
功能概述
SocketServer 是 Kafka 服务端用于处理网络通信的核心类。它主要负责监听客户端(如生产者、消费者)的连接请求,并对这些请求进行处理,以实现消息的发送和接收。它就像是一个 “通信枢纽”,协调着 Kafka 服务端与外部客户端之间的信息交互。
内部结构
SocketServer 包含多个组件,其中最关键的是接收请求的线程(Acceptor)和处理请求的线程池(Processor)。Acceptor 线程主要负责监听特定端口,当有客户端连接请求时,它会接受请求并将其交给 Processor 线程池进行后续处理。例如,当一个生产者尝试连接 Kafka 服务端发送消息时,Acceptor 首先捕获这个连接请求,然后将生产者的后续消息发送请求转交给 Processor 线程进行实际的消息处理操作。
重要性
它是 Kafka 服务端能够稳定、高效地与外部客户端进行通信的基础。通过合理的线程分配和请求处理机制,SocketServer 能够处理大量的并发连接请求,确保消息在服务端和客户端之间的顺畅流通。
Reactor 模式简介
基本原理
Reactor 模式是一种事件驱动的设计模式,在 Kafka 的通信层中发挥着关键作用。其核心思想是将对 I/O 事件的处理(如可读、可写事件)从应用程序逻辑中分离出来,由专门的 Reactor(反应器)来处理这些事件。在 Kafka 中,这个 Reactor 就类似于 SocketServer 中的部分功能。
角色和组件
Reactor 模式主要包含以下几个关键部分:
Reactor(反应器):它负责监听 I/O 事件,当事件发生时(如客户端连接、数据可读等),它会将事件分发给对应的处理程序。在 Kafka 的 SocketServer 中,Acceptor 线程部分地扮演了这个角色,它监听连接请求事件。
Handler(处理程序):这些是具体处理 I/O 事件的程序。在 Kafka 中,Processor 线程就相当于 Handler,负责处理从 Acceptor 接收过来的客户端连接后的消息处理等实际操作。
例如,当一个消费者连接到 Kafka 服务端并开始请求拉取消息时,首先由类似 Reactor 的 Acceptor 接受连接请求,然后将拉取消息的请求事件转交给类似 Handler 的 Processor 线程进行处理,包括从存储中查找消息、发送消息给消费者等操作。
优势
高性能:通过将事件监听和处理分离,能够高效地处理大量并发事件。因为 Reactor 可以快速地将事件分发给多个处理程序同时进行处理,避免了单个线程处理所有事件可能导致的性能瓶颈。
可扩展性:这种模式很容易进行扩展。例如,可以方便地增加处理程序(Handler)的数量来应对不断增加的请求量,而不需要对整个架构进行大规模改动。
代码清晰性:将事件处理逻辑从主程序中分离出来,使得代码结构更加清晰,易于维护和理解。不同的处理程序负责不同类型的事件,便于开发人员对代码进行修改和优化。
详细介绍一下 Kafka 服务端的高可用机制
副本机制(Replication)
基本概念
Kafka 通过副本机制来提供数据冗余和高可用性。每个分区(Partition)可以有多个副本,其中一个是领导者(Leader)副本,其余为追随者(Follower)副本。领导者副本负责处理该分区的所有读写请求,而追随者副本则定期从领导者副本同步数据,保持与领导者副本的数据一致性。
工作原理
当生产者发送消息时,消息会被发送到分区的领导者副本。领导者副本会将消息追加到本地日志文件中,然后向生产者返回确认(ACK)。同时,追随者副本会从领导者副本拉取消息并更新自己的日志文件。在这个过程中,通过偏移量(Offset)来保证消息的顺序和一致性。例如,假设一个分区有 3 个副本(1 个领导者和 2 个追随者),生产者发送一条消息到领导者副本,领导者副本将消息追加到日志文件后,会通知追随者副本更新,每个副本中的消息偏移量都是相同的,这样就保证了数据的同步。
故障恢复
如果领导者副本出现故障,Kafka 会从追随者副本中选举出一个新的领导者副本。这个选举过程是基于一定的规则,如根据副本在 ISR(In - Sync Replicas)中的顺序。ISR 是与领导者副本保持同步状态的追随者副本集合。当旧的领导者副本恢复后,它会变为追随者副本,重新从新的领导者副本同步数据。这种机制保证了即使部分节点出现故障,服务也能够持续运行。
分区(Partition)机制
基本概念
分区是 Kafka 对主题(Topic)进行数据划分的单位。一个主题可以包含多个分区,每个分区可以独立地存储和处理消息。这种分区机制使得 Kafka 能够实现并行处理和负载均衡,从而提高系统的整体性能和可用性。
工作原理
生产者可以根据消息的键(Key)或者自定义的策略将消息发送到不同的分区。例如,对于一个订单主题,可以根据订单号的哈希值将订单消息分配到不同的分区。在消费者端,每个消费者可以订阅一个或多个分区,不同的消费者可以并行地处理不同分区的消息,这样就提高了消息处理的效率。同时,分区的存在也使得系统在部分分区出现故障时,其他分区仍然可以正常工作,从而提高了系统的可用性。
负载均衡和扩展性
分区可以在多个代理(Broker)之间进行分配,实现负载均衡。当系统需要扩展时,可以通过增加分区的数量或者增加代理的数量来分担负载。例如,随着消息量的增加,可以增加新的分区,并将部分消息分配到新的分区中,同时可以添加新的代理来存储和处理这些新分区的消息,从而保证系统能够适应不断变化的业务需求。
Zookeeper 的作用
集群管理
Zookeeper 在 Kafka 高可用机制中起到了关键的集群管理作用。它存储了 Kafka 集群的元数据信息,如代理(Broker)的信息、主题(Topic)的配置、分区的分配等。通过 Zookeeper,Kafka 可以方便地进行集群成员的动态加入和退出管理。例如,当一个新的代理加入集群时,它会在 Zookeeper 中注册自己的信息,Kafka 集群可以根据 Zookeeper 中的信息来合理分配分区和负载。
领导者选举
在副本机制中,Zookeeper 协助进行领导者选举。当分区的领导者副本出现故障时,Kafka 依赖 Zookeeper 提供的分布式协调功能来选举新的领导者副本。Zookeeper 通过维护每个分区的选举状态和相关的元数据,确保选举过程的公平性和一致性。例如,它会根据预先定义的选举规则,如 ISR 中的副本顺序,在合适的追随者副本中选择新的领导者副本。
故障检测和恢复
Zookeeper 能够检测代理和分区的故障情况。它通过心跳机制等方式,监控代理和分区的状态。当检测到故障时,它会触发 Kafka 的故障恢复机制,如重新选举领导者副本、重新分配分区等操作,以确保集群的高可用性。例如,如果一个代理长时间没有发送心跳信号,Zookeeper 会判断该代理出现故障,然后通知 Kafka 集群进行相应的故障处理。
介绍一下 Kafka 的高可用机制的优缺点
优点
副本机制相关优点
数据冗余与可靠性
Kafka 的副本机制通过在多个节点上存储相同的数据副本,确保了数据的冗余。当某个节点(存储领导者副本)出现故障时,数据不会丢失,因为追随者副本可以快速接替并提供服务。例如,在金融交易系统中,交易记录消息存储在 Kafka 中,副本机制保证即使部分服务器出现硬件故障或网络问题,交易数据依然安全可靠。
故障恢复能力
高效的故障恢复是副本机制的一大优势。一旦领导者副本出现故障,Kafka 能够在短时间内(通常在几秒内)从追随者副本中选举出新的领导者副本。在选举过程中,服务的中断时间被最小化,并且新的领导者副本可以立即开始处理读写请求。这对于需要持续服务的应用场景,如实时监控系统、在线支付系统等至关重要。
数据一致性保障
副本之间通过偏移量等机制保持数据同步,确保了数据一致性。所有副本在逻辑上应该包含相同的消息序列,这使得消费者无论从领导者副本还是追随者副本(在特殊情况下)获取消息,都能得到相同的内容。这种一致性对于需要精确数据处理的场景,如数据分析系统、事件溯源系统等是非常重要的。
分区机制相关优点
并行处理与负载均衡
分区机制允许 Kafka 将主题的消息划分到多个分区,不同分区可以并行处理。这大大提高了消息处理的效率,尤其在高并发场景下。例如,在一个大型电商促销活动期间,订单消息主题可以通过分区机制分配到多个分区,由多个消费者并行处理,从而有效分担负载,避免单个节点处理过多消息导致的性能瓶颈。
同时,分区可以在不同的代理之间进行合理分配,实现了代理之间的负载均衡。这使得整个 Kafka 集群的资源得到充分利用,并且能够根据系统的负载变化灵活调整分区的分配。
扩展性
分区机制为 Kafka 提供了良好的扩展性。当业务增长导致消息量增加或者需要更高的处理能力时,可以方便地增加分区数量或者代理数量。例如,随着物联网设备的不断接入,产生的传感器数据量不断增加,通过增加分区和代理,可以轻松应对数据洪流,确保系统能够持续高效地运行。
Zookeeper 相关优点
集群管理便捷性
Zookeeper 提供了集中式的集群管理功能,存储了 Kafka 集群的各种元数据信息。这使得集群的管理变得更加便捷,包括代理的动态加入和退出。新的代理可以快速在 Zookeeper 中注册并融入集群,而退出的代理也能被及时发现并进行相应的资源调整。
领导者选举的公平性和一致性
在领导者选举过程中,Zookeeper 发挥了关键作用,确保选举的公平性和一致性。它依据预定义的规则,如基于 ISR(In - Sync Replicas)的顺序,在追随者副本中选择最合适的副本作为新的领导者。这种有规则的选举过程避免了混乱,保证了集群在故障后能够快速稳定地恢复运行。
故障检测与协同恢复
Zookeeper 通过心跳机制等方式有效检测代理和分区的故障情况。一旦发现故障,它可以及时触发 Kafka 的故障恢复机制,如重新选举领导者和重新分配分区。这种协同恢复机制增强了整个集群的鲁棒性,使得 Kafka 能够在复杂多变的环境中保持高可用性。
缺点
副本机制相关缺点
资源消耗
副本机制需要额外的存储资源来保存多个副本的数据。这对于存储成本敏感的应用场景可能是一个问题。例如,在存储海量数据(如视频监控数据)的情况下,每个分区都需要存储多个副本,这会导致存储需求成倍增加。
同时,副本之间的数据同步也需要消耗网络带宽和 CPU 资源。频繁的数据同步可能会对网络和服务器性能产生一定的影响,尤其是在网络带宽有限或者服务器性能较低的情况下。
数据同步延迟可能导致不一致性
尽管 Kafka 通过各种机制尽量保证副本之间的同步,但在某些极端情况下,如网络波动或者服务器负载过高时,数据同步可能会出现延迟。这可能会导致短暂的数据不一致性,即消费者在不同时间从领导者副本和追随者副本获取的消息可能会有微小差异。
分区机制相关缺点
增加系统复杂性
分区机制虽然带来了很多好处,但也增加了系统的复杂性。对于开发人员和运维人员来说,需要理解分区的概念、消息在分区中的分配策略以及分区与代理之间的关系等诸多复杂内容。在出现问题时,如分区不平衡或者分区故障,定位和解决问题的难度也相对较高。
分区过多可能导致性能下降
当分区数量过多时,可能会出现一些性能问题。例如,过多的分区可能会导致元数据管理的负担加重,因为 Kafka 需要维护每个分区的信息。同时,在某些情况下,过多的分区可能会导致消费者的管理变得复杂,例如需要协调更多的消费者来处理众多分区的消息,这可能会增加消息处理的延迟。
Zookeeper 相关缺点
额外的依赖风险
Kafka 对 Zookeeper 的依赖是一个潜在的风险点。如果 Zookeeper 出现故障,可能会影响 Kafka 集群的正常运行。虽然 Zookeeper 本身也是高可用的,但一旦其出现问题,Kafka 的领导者选举、集群管理等功能都会受到影响,进而可能导致整个集群的服务中断或者不稳定。
性能瓶颈可能转移
在高并发场景下,Zookeeper 可能会成为性能瓶颈。因为 Zookeeper 需要处理大量的集群元数据更新、心跳检测等任务。如果 Zookeeper 的性能无法满足需求,可能会导致 Kafka 集群的响应速度变慢,如代理加入或退出集群的操作延迟,或者领导者选举过程变长。
服务端代码是kafka的核心和精华,而且代码量比较大,我根据功能模块划分了几个部分,分别为:网络通信模块,存储模块,副本模块,控制模块,延迟模块,消费组协调器模块。
今天我们开始学习网络通信模块,整个服务端的主类是SocketServer类,跟网络通信层相关的组件主要是SocketServer.scala、KafkaApis.scala和KafkaRequesthandler.scala。今天我们主要研究SocketServer.scala文件的概况和Reactor模式。
SocketServer.scala 文件
SocketServer类是接收客户端socket请求连接、处理服务端和客户端网络IO的核心类。我们先了解一下这个类的基本情况和重要字段。
SocketServer.scala 文件分为8个部分,这里我用一张图展示一下。
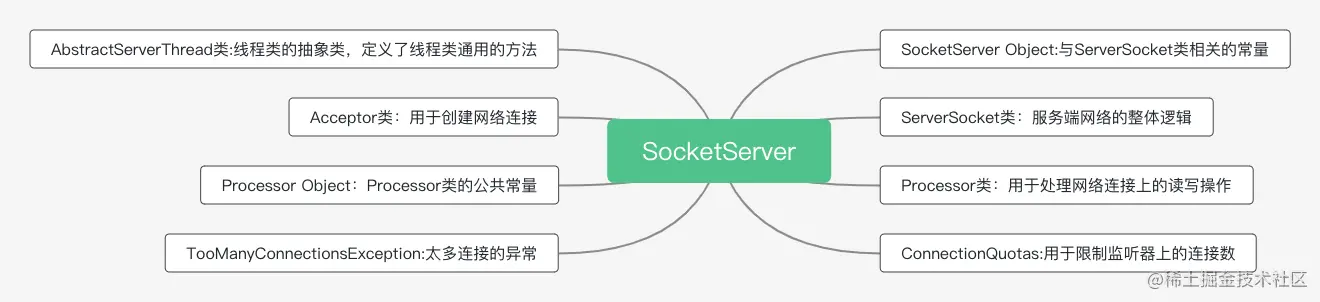
可以看到,共有8个组件,这节课和下节课我会给你介绍几个重点组件。
首先我们讲解类 SocketServer。
类 SocketServer的主要字段如下:
class SocketServer(val config: KafkaConfig,
val metrics: Metrics,
val time: Time,
val credentialProvider: CredentialProvider)
extends Logging with KafkaMetricsGroup with BrokerReconfigurable {
// SocketServer 实现 BrokerReconfigurable trait表明SocketServer的一些参数配置是允许动态修改的
// 即在Broker不停机的情况下修改它们
// SocketServer的请求队列长度,由Broker端参数queued.max.requests值而定,默认值是500
private val maxQueuedRequests = config.queuedMaxRequests
//数据面的Processor线程类集合。
private val dataPlaneProcessors = new ConcurrentHashMap[Int, Processor()
// 处理数据类请求的Acceptor线程集合,每套监听器对应一个Acceptor线程
private[network] val dataPlaneAcceptors = new ConcurrentHashMap[EndPoint, Acceptor]()
// 处理数据类请求专属的RequestChannel对象,多个Processor会共享一个RequestChannel,请求队列长度为500.
val dataPlaneRequestChannel = new RequestChannel(maxQueuedRequests, DataPlaneMetricPrefix, time)
// 用于处理控制类请求的Processor线程
// 注意:目前定义了专属的Processor线程而非线程池处理控制类请求
private var controlPlaneProcessorOpt : Option[Processor] = None
private[network] var controlPlaneAcceptorOpt : Option[Acceptor] = None
// 处理控制类请求专属的RequestChannel对象,请求队列长度为20,远远小于数据类请求,因为控制类不需要这么多
val controlPlaneRequestChannelOpt: Option[RequestChannel] = config.controlPlaneListenerName.map(_ =>
new RequestChannel(20, ControlPlaneMetricPrefix, time))
SocketServer实现了BrokerReconfigurable,说明SocketServer是支持动态配置参数的。哪些参数可以动态配置呢?这些参数都在SocketServer Object保存着,你有兴趣可以了解下。
接下来,我们来讲解其中的重点字段。
maxQueuedRequests:服务端对于新来的请求,Processor会放到请求队列里等待真正的业务线程处理,队列的长度就是由这个参数决定的,默认是500。dataPlaneProcessors:数据面的Processor线程集合,默认3个线程。dataPlaneAcceptors:数据面Acceptor线程的map集合,key是EndPoint,value是Acceptor线程类对象。一个broker可能会有多个EndPoint,一个EndPoint只会有一个Acceptor线程。dataPlaneRequestChannel:数据面的RequestChannel类对象。RequestChannel类定义了请求和响应类,并定义了请求集合等功能。controlPlaneProcessorOpt:控制面的Processor线程类,由于控制面的请求量不高,所以一个Processor线程类就应该够用了。controlPlaneAcceptorOpt:控制面的Acceptor线程类。controlPlaneRequestChannelOpt:控制面的RequestChannel类对象,跟数据面的RequestChannel类对象功能类似。
字段我们了解完了,现在着重学习一下SocketServer类相关的方法。
SocketServer类的启动方法是startup(),所以我们先看一下这个方法都做了什么。
方法 startup()
startup()方法源码如下:
//核心流程:创建各类线程,包括Acceptor,Processor,然后启动
def startup(startProcessingRequests: Boolean = true): Unit = {
this.synchronized {
connectionQuotas = new ConnectionQuotas(config, time, metrics)
//1.创建控制面Acceptor和Processor。包括一个Acceptor线程和一个Processor线程,
createControlPlaneAcceptorAndProcessor(config.controlPlaneListener)
//2.创建数据面Acceptor和Processor。创建一个Acceptor线程,和创建默认3个Processor线程,由配置项num.network.threads决定Processor的线程数,默认3个线程
createDataPlaneAcceptorsAndProcessors(config.numNetworkThreads, config.dataPlaneListeners)
if (startProcessingRequests) {
//3.启动控制面和数据面各自的Acceptor和Processor线程
this.startProcessingRequests()
}
}
…… 省略
}
首先给你介绍下服务端请求的一些分类和概念。kafka服务端给外部请求分为了两个大类:控制面请求和数据面请求。
控制面请求指的是用于控制服务端或协调同步类的请求,比如,关闭broker节点,follower partition所在的节点向leader partition所在的节点拉取消息。
数据面请求是指真正业务数据相关的请求,如生产者生产消息时向broker发送消息的请求,消费者拉取消息时向broker拉取消息的请求等。
好,我们看一下这个方法都做了什么工作。
创建控制面Acceptor和Processor。包括一个Acceptor线程和一个Processor线程。
创建数据面Acceptor和Processor。创建一个Acceptor线程,和创建默认3个Processor线程,由配置项num.network.threads决定Processor的线程数,默认3个线程。
启动控制面和数据面各自的Acceptor和Processor线程。
这里你可能会有一个疑问:为什么要分为控制面请求和数据面请求呢?
原因是如果不把请求分为控制面和数据面,而数据类请求一般量级很大甚至造成大量请求排队等待处理,比如,生产者生产消息的请求,消费者拉取消息的请求。这时如果出现控制类的请求,就会使控制类亲戚在数据类请求后面排队,这样就会造成控制面请求处理的不及时,而控制类请求又是比较重要的,比如通知某个leader分区变为follower分区等。最终会造成数据的不一致,甚至数据类请求失败。而分成两类就不会大量出现这样的问题,因为毕竟是把两类请求分开处理了。
startup()方法内部创建了控制面和数据面的线程,这两个控制面和数据面的相关线程的创建基本就一样,这里我们讲解一下数据面的相关线程的创建。
以下是对 startup() 方法的详细分析:
一、整体功能概述
startup() 方法是 Kafka 服务端启动过程中的关键方法,主要负责创建各类线程以处理不同类型的请求,包括控制面请求和数据面请求。通过这个方法,Kafka 服务端能够建立起高效的网络通信机制,以接收和处理来自外部的各种请求,确保消息的生产和消费能够顺利进行。
二、方法步骤解析
创建连接配额对象
connectionQuotas = new ConnectionQuotas(config, time, metrics):这一步创建了一个连接配额对象。这个对象用于管理和控制与 Kafka 服务端的连接数量,根据配置参数config、时间信息time和度量指标metrics来限制并发连接数,以防止过多的连接导致服务端过载。
创建控制面 Acceptor 和 Processor
createControlPlaneAcceptorAndProcessor(config.controlPlaneListener):这一步创建了用于处理控制面请求的 Acceptor 和 Processor 线程。控制面请求主要用于控制服务端或协调同步类的操作。例如,关闭 broker 节点的请求,或者 follower partition 所在的节点向 leader partition 所在的节点拉取消息的请求。Acceptor 线程负责监听控制面的连接请求,一旦有请求到来,它会接受连接并将请求传递给 Processor 线程进行处理。Processor 线程则具体执行控制面请求的处理逻辑,确保控制操作能够正确地执行。
创建数据面 Acceptor 和 Processor
createDataPlaneAcceptorsAndProcessors(config.numNetworkThreads, config.dataPlaneListeners):这里创建了用于处理数据面请求的 Acceptor 和 Processor 线程。数据面请求是与真正业务数据相关的请求,比如生产者生产消息时向 broker 发送消息的请求,以及消费者拉取消息时向 broker 拉取消息的请求等。根据配置参数
config.numNetworkThreads确定 Processor 线程的数量,通常默认是 3 个线程。Acceptor 线程负责监听数据面的连接请求,而多个 Processor 线程可以并行处理大量的数据面请求,提高系统的吞吐量和响应速度。
启动线程
this.startProcessingRequests():这一步启动了控制面和数据面各自的 Acceptor 和 Processor 线程。一旦这些线程启动,它们就开始监听和处理相应类型的请求。Acceptor 线程持续监听端口,当有请求到达时,迅速响应并将请求传递给 Processor 线程进行处理。Processor 线程则按照预定的逻辑处理请求,确保请求能够及时、准确地得到处理。
三、控制面和数据面请求的重要性
控制面请求
控制面请求对于 Kafka 服务端的管理和协调至关重要。关闭 broker 节点的请求可以在系统维护或出现故障时进行节点的优雅关闭,避免数据丢失和服务中断。而 follower partition 向 leader partition 拉取消息的请求则保证了副本数据的同步,确保在 leader 出现故障时能够快速选举出新的 leader,维持系统的高可用性。
数据面请求
数据面请求直接关系到 Kafka 作为消息中间件的核心业务功能。生产者发送消息的请求使得数据能够被有效地写入 Kafka 集群,而消费者拉取消息的请求则使得数据能够被及时地读取和处理。这些请求的高效处理对于满足业务系统对实时数据的需求至关重要,确保数据能够在不同的应用组件之间快速、准确地传递。
如何保证控制面线程的高可用性?控制面线程的工作流程是怎样的?数据面线程是如何处理数据请求的?
一、保证控制面线程的高可用性
(一)冗余机制
多节点部署:Kafka 服务通常会部署在多个节点上形成集群。对于控制面线程相关的组件,如处理控制请求的 Acceptor 和 Processor,在多个节点上都有相应的实例。这样,当一个节点上的控制面线程出现故障时,其他节点可以继续处理控制请求,确保系统的管理和协调功能不受影响。例如,在一个包含 5 个节点的 Kafka 集群中,每个节点都有自己的控制面线程,即使其中一个节点发生硬件故障,其余 4 个节点的控制面线程依然能够维持集群的正常运行,如处理分区副本的同步协调等控制请求。
副本策略应用于关键数据:对于控制面线程处理过程中涉及的关键元数据(如集群的配置信息、分区状态等),采用副本策略存储。可以利用类似 Zookeeper 这样的分布式协调服务来存储这些关键元数据的副本。当控制面线程需要读取或更新这些元数据时,即使某个存储副本的节点出现问题,也可以从其他副本获取正确的数据,保证控制面线程操作的准确性和连续性。
(二)健康监测与自动恢复
心跳检测和故障监测:采用心跳机制来监测控制面线程的健康状况。控制面线程会定期向监控模块发送心跳信号,一旦监控模块在一定时间内没有收到某个线程的心跳信号,就会判定该线程出现故障。同时,对于线程处理的请求响应时间等指标也进行监测,如果响应时间过长或者出现大量错误响应,也可能预示着线程出现问题。例如,监控模块可以设定如果控制面线程连续 3 次没有发送心跳信号,或者处理关闭 broker 节点请求的平均响应时间超过 10 秒,就判定该线程出现故障。
自动重启和重新分配任务:当监测到控制面线程出现故障时,系统会自动尝试重启故障线程。如果重启失败,会对该线程负责的任务进行重新分配。例如,若某个负责处理分区副本同步请求的控制面 Processor 线程出现故障,系统会尝试重启该线程;若重启不成功,则将其任务分配给其他正常的 Processor 线程,确保分区副本同步等控制请求能够继续得到处理。
(三)资源隔离与优先级保障
资源隔离:为控制面线程分配独立的资源,如 CPU 核心、内存等,避免其受到数据面线程或其他非关键进程的资源抢占。可以通过操作系统的资源管理工具或者容器化技术来实现资源隔离。例如,在使用容器编排工具(如 Kubernetes)部署 Kafka 时,可以为控制面线程所在的容器设置资源限制,确保其有足够的 CPU 和内存来稳定运行,防止因资源不足导致的可用性问题。
优先级设置:赋予控制面线程较高的优先级,使得在系统资源紧张的情况下,控制面线程能够优先获取资源来处理紧急的控制请求。例如,在处理集群重新平衡或选举新的分区领导者等关键控制请求时,高优先级可以保证这些请求能够及时得到处理,避免影响整个集群的稳定性和可用性。
二、控制面线程的工作流程
监听请求
控制面线程中的 Acceptor 线程首先负责监听特定端口,等待控制面请求的到来。这个端口是在服务配置时指定的用于接收控制请求的端口。例如,当一个节点需要向另一个节点发送分区副本同步请求时,请求会首先到达接收节点的 Acceptor 线程所监听的端口。
接受请求并传递
当有控制请求到达时,Acceptor 线程接受请求并建立连接。然后,它将请求传递给 Processor 线程。在传递过程中,可能会对请求进行一些初步的封装或标记,以便 Processor 线程能够更好地识别和处理。例如,添加请求的来源信息、请求类型标识等。
Processor 线程处理请求
Processor 线程接收到请求后,会根据请求的类型进行相应的处理。
集群管理请求处理:
如果是关闭 broker 节点的请求,Processor 线程会首先进行一系列的检查,如确保该节点上的分区副本已经正确地迁移或关闭,没有正在进行的关键数据操作(如消息生产或消费)。然后,它会通知集群中的其他节点该节点即将关闭,协调分区副本的重新分配等操作,确保集群状态的平稳过渡。
副本同步请求处理:
对于 follower partition 所在的节点向 leader partition 所在的节点拉取消息的请求,Processor 线程会负责协调数据传输。它会检查 follower 节点的状态,如是否已经与 leader 节点建立了正确的连接,是否在同步的允许范围内(如是否在 ISR 中)。然后,它会向 leader 节点发送具体的拉取消息指令,包括拉取的分区、偏移量范围等信息,接收并处理 leader 节点返回的数据,更新 follower 节点的分区副本数据。
反馈处理结果
在 Processor 线程完成请求处理后,会将处理结果通过网络返回给请求的发送方。例如,对于分区副本同步请求,如果成功更新了 follower 节点的副本数据,会返回成功的消息;如果出现错误,如网络故障导致数据传输中断或者 leader 节点数据不一致,会返回相应的错误码和错误信息,以便请求方进行后续处理。
三、数据面线程处理数据请求的方式
数据接收
数据面线程中的 Acceptor 线程同样负责监听特定的数据请求端口。当生产者发送消息的请求或者消费者拉取消息的请求到达时,Acceptor 线程接受请求并建立连接。例如,生产者发送消息时,请求首先被 Acceptor 线程捕获,这个请求包含消息内容、目标分区等信息。
请求分配与排队
接受的请求会被分配给 Processor 线程进行处理。如果有多个 Processor 线程,会根据一定的策略进行分配,如轮询分配或者基于请求类型的优先级分配。在高并发情况下,请求可能会在一个队列中等待 Processor 线程空闲。例如,对于一些高优先级的数据请求(如实时数据的消费者拉取请求)可以设置为优先分配给 Processor 线程。
Processor 线程处理数据请求
生产者消息发送请求处理:
当 Processor 线程处理生产者发送消息的请求时,首先会验证消息的格式是否正确,包括消息头、消息体等部分。然后,根据消息中的目标分区信息,将消息发送到对应的分区。如果目标分区有多个副本,会将消息先发送到领导者副本。在这个过程中,会记录消息的偏移量,用于后续消费者拉取消息时确定消息的位置。同时,会向生产者返回确认(ACK)信息,告知消息是否成功发送。
消费者消息拉取请求处理:
对于消费者拉取消息的请求,Processor 线程会根据请求中包含的分区、偏移量等信息,从对应的分区中读取消息。如果消费者请求拉取一批消息,会按照顺序从分区的存储中读取指定数量的消息。然后,将消息返回给消费者。在这个过程中,会更新消费者的偏移量信息,记录消费者已经拉取到的位置,以便下次拉取时从正确的位置开始。
错误处理与重试(如果需要)
如果在处理数据请求过程中出现错误,如网络故障导致消息发送或接收中断、分区存储故障等,Processor 线程会进行相应的错误处理。对于一些可以重试的情况,如网络暂时抖动导致的消息发送失败,会进行重试操作。例如,如果生产者发送消息时因为网络问题没有收到 ACK 确认,在一定的重试次数范围内,Processor 线程会重新尝试接收并处理该消息发送请求,确保消息能够成功发送到目标分区。同时,对于无法重试或者重试多次后仍然失败的情况,会向请求方(生产者或消费者)返回相应的错误信息,告知请求无法完成
在 Kafka 中,`startup()` 方法是服务端启动过程中的一个关键方法,它负责初始化和启动 Kafka 服务器的核心组件。根据你提供的源码片段,这个方法主要做了以下几个步骤:
1. 创建连接配额(Connection Quotas):这是在 Kafka 配置中用于限制客户端连接数量的机制,以防止资源耗尽。
2. 创建控制面 Acceptor 和 Processor:控制面请求处理涉及到 Kafka 集群的管理操作,如关闭 broker、分区副本之间的同步等。`createControlPlaneAcceptorAndProcessor()` 方法会创建一个 Acceptor 线程和一个 Processor 线程来处理这些请求。
3. 创建数据面 Acceptor 和 Processor:数据面请求处理涉及到实际的业务数据操作,如消息的生产和消费。`createDataPlaneAcceptorsAndProcessors()` 方法会根据配置创建一个 Acceptor 线程和多个 Processor 线程来处理这些请求。Processor 线程的数量可以通过配置项 num.network.threads 来设置,默认是 3 个。
4. 启动请求处理:如果 startProcessingRequests 参数为 true,则会调用 startProcessingRequests() 方法来启动 Acceptor 和 Processor 线程,开始处理请求。
控制面和数据面请求的区分是为了更好地管理和优化 Kafka 集群的性能。控制面请求通常涉及到集群的元数据操作,这些操作对实时性的要求不如数据面请求高,因此可以单独处理。而数据面请求则直接关系到业务数据的流转,通常需要更高的吞吐量和更低的延迟。
在 Kafka 集群中,这种分离的设计允许集群在处理大量数据请求的同时,还能够有效地进行集群管理和同步操作,从而保证了集群的稳定性和数据的一致性。
控制面线程的高可用性保证
控制面线程主要负责处理集群管理任务,如分区Leader选举、副本同步等。为了保证控制面线程的高可用性,Kafka采取了以下措施:
Controller角色:Kafka集群中的某个Broker会被选举为Controller,负责管理集群元数据和分区Leader选举等控制面操作。当当前Controller失败时,会进行新一轮选举以确保控制面操作不会中断。
ZooKeeper协调:在早期版本的Kafka中,Controller通过ZooKeeper来监控集群状态变化并进行Leader选举。虽然新版本中这一机制已被内部的Raft协议取代,但ZooKeeper仍然在协调控制面操作中发挥了重要作用。
高吞吐量的网络模型:Kafka的网络模型支持多个Acceptor线程,实现主从多Reactor模型,这有助于提高控制面请求的处理吞吐量。
控制面线程的工作流程
控制面线程的工作流程大致如下:
监听和接受连接:Acceptor线程负责监听端口,接受新的连接请求。
请求处理:Processor线程(网络线程)负责处理控制面的请求,如Leader选举和副本同步等。Processor线程将解析请求并将其放入全局请求队列(RequestChannel)中。
业务逻辑处理:IO线程(KafkaRequestHandler)从RequestChannel中取出请求,调用KafkaApis中的具体实现来完成逻辑处理。
响应返回:处理完请求后,IO线程将响应结果发送给Processor线程,由Processor线程返回给客户端。
数据面线程处理数据请求
数据面线程主要负责处理业务数据相关的请求,如消息的生产和消费。其工作流程如下:
网络通信:数据面线程同样通过Acceptor线程接受连接,Processor线程处理网络读写事件,将请求解码成Kafka可以处理的请求对象。
请求队列:Processor线程将解析出的请求对象放入全局的请求队列(RequestChannel)中。
业务逻辑处理:KafkaRequestHandler线程(IO线程)从RequestChannel中取出请求,进行具体的业务逻辑处理,如消息存储、检索等。
响应生成:处理完成后,KafkaRequestHandler线程将生成的响应数据放入Processor线程的响应队列中。
数据传输:Processor线程从响应队列中取出响应数据,通过SocketChannel将响应数据发送回客户端。
通过这种分离的设计,Kafka能够确保控制面操作的高效性和数据面请求的高吞吐量处理能力。同时,Kafka的线程模型也支持动态调整,以适应不同的负载和性能需求。
startup()方法内部创建了控制面和数据面的线程,这两个控制面和数据面的相关线程的创建基本就一样,这里我们讲解一下数据面的相关线程的创建。
方法 createDataPlaneAcceptorsAndProcessors()
其源码如下:
private def createDataPlaneAcceptorsAndProcessors(
dataProcessorsPerListener: Int,endpoints: Seq[EndPoint]): Unit = {
// 遍历监听器endpoints集合
// endpoints:一台服务器可以配置多个kafka实例,通过port区分开来。
// node01:9092,node01:9093,node01:9094
endpoints.foreach { endpoint =>
// 将监听器纳入到连接配额管理之下
connectionQuotas.addListener(config, endpoint.listenerName)
// 为监听器创建对应的Acceptor线程
val dataPlaneAcceptor = createAcceptor(endpoint,DataPlaneMetricPrefix)
// 为监听器创建多个Processor线程。具体数目由num.network.threads决定
addDataPlaneProcessors(dataPlaneAcceptor, endpoint, dataProcessorsPerListener)
// 将<监听器,Acceptor线程>对保存起来统一管理
dataPlaneAcceptors.put(endpoint, dataPlaneAcceptor)
info(s"Created data-plane acceptor and processors for endpoint : ${endpoint.listenerName}")
}
}
首先遍历这个broker设置的所有监听器(endpoint),一台服务器可以配置多个kafka实例,通过port区分开来,一个kafka实例就是一个监听器,比如一个机器名为node1的broker,在这个broker上可以配置多个监听器:node01:9092、node01:9093、node01:9094。
我们再看看遍历循环的内部都做了什么。
首先把监听器纳入连接配额管理之下,kafka服务端为了保证网络质量对每个监听器的连接配额是有限制的。
然后创建一个Acceptor线程,Acceptor线程是专门负责与外部建立连接的线程,一个监听器只会分配一个Acceptor线程。
下一步建立多个为监听器创建多个Processor线程,Processor线程是用来处理网络读写操作的,具体线程数由num.network.threads决定,默认是3个线程。
最后把<监听器,Acceptor线程>对保存在map集合dataPlaneAcceptors中统一管理。
接下来我们分别看一下,Acceptor线程和Processor线程是如何创建的。
其源码如下:
private def createAcceptor(endPoint: EndPoint, metricPrefix: String) : Acceptor = {
//配置socket发出和接受数据缓冲区大小,默认128kb。
val sendBufferSize = config.socketSendBufferBytes
val recvBufferSize = config.socketReceiveBufferBytes
//获取broker节点id。
val brokerId = config.brokerId
new Acceptor(endPoint, sendBufferSize, recvBufferSize, brokerId, connectionQuotas, metricPrefix)
}
首先配置socket发出和接受数据缓冲区大小,默认为128kb,但在实际生产环境中,128kb肯定是不够的,可以根据实际请求进行修改。对应的参数分别是 socket.send.buffer.bytes和socket.receive.buffer.bytes,同时获取brokerId作为节点表示,最后创建Acceptor对象。
方法 addDataPlaneProcessors()
接下来我们学习数据面的Processor线程的创建过程:
private def addDataPlaneProcessors(acceptor: Acceptor, endpoint: EndPoint, newProcessorsPerListener: Int): Unit = {
//监听器名称
val listenerName = endpoint.listenerName
//协议
val securityProtocol = endpoint.securityProtocol
//Processor数组。
val listenerProcessors = new ArrayBuffer[Processor]()
//遍历newProcessorsPerListener,默认为3
for (_ <- 0 until newProcessorsPerListener) {
//创建Processor对象
val processor = newProcessor(nextProcessorId, dataPlaneRequestChannel, connectionQuotas, listenerName, securityProtocol, memoryPool)
//把processor添加到数组中。
listenerProcessors += processor
//把processor加入到dataPlaneRequestChannel内的集合中,用来监控processor对象
dataPlaneRequestChannel.addProcessor(processor)
//线程id加一。
nextProcessorId += 1
}
//把processId和processor通过map集合存储起来
listenerProcessors.foreach(p => dataPlaneProcessors.put(p.id, p))
//为acceptor加对应的processor
acceptor.addProcessors(listenerProcessors, DataPlaneThreadPrefix)
}
首先获取监听器的名称、支持的安全协议。安全协议具体有PLAINTEXT、SSL、SASL_PLAINTEXT、SASL_PLAINTEXT、SASL_SSL。
然后根据要创建的processor数量,循环创建processor对象,把新创建的processor对象加到集合listenerProcessors中。还要把processor对象加到 dataPlaneRequestChannel对象的集合内,dataPlaneRequestChannel对象的类是RequestChannel,这个类我会在下节课中给你讲解。
循环最后一步是nextProcessorId加一,nextProcessorId表示当前processor线程的id。循环结束后,Processor对象会加到集合dataPlaneProcessors中,dataPlaneProcessors是类SocketServer的字段,表示SocketServer类下所有监听器的Processor集合。
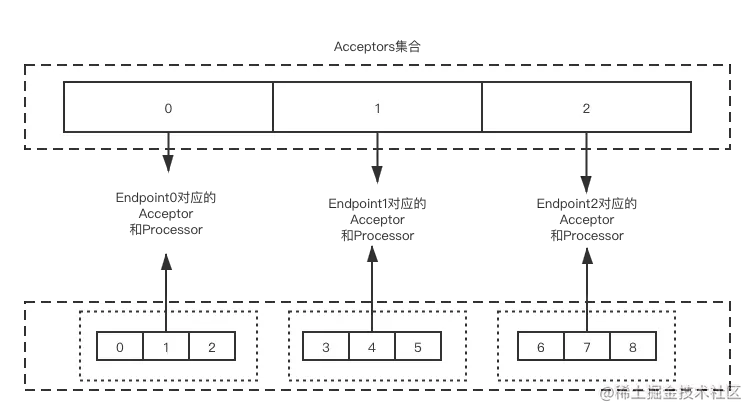
最后,processor对象会加到acceptor对象里的集合里。也就是说,processor线程创建结束后会加到三个集合中,包括dataPlaneRequestChannel对象内的processor集合,dataPlaneProcessors集合,acceptor对象下的集合。
为了更好地让你理解acceptor和processor的对应关系,可参考下面的关系图:
SocketServer类对线程的创建就介绍完了,但是线程还没有启动呢?这就是方法startProcessingRequests()的工作了。这个方法启动了控制面的线程和数据面的线程,最终都调用了startAcceptorAndProcessors()去启动线程。
方法 startAcceptorAndProcessors()
以下是源码并附有注释:
private def startAcceptorAndProcessors(threadPrefix: String,
endpoint: EndPoint,
acceptor: Acceptor,
authorizerFutures: Map[Endpoint, CompletableFuture[Void]] = Map.empty): Unit = {
debug(s"Wait for authorizer to complete start up on listener ${endpoint.listenerName}")
waitForAuthorizerFuture(acceptor, authorizerFutures)
debug(s"Start processors on listener ${endpoint.listenerName}")
//通过后台线程启动acceptor下的Processors线程。
acceptor.startProcessors(threadPrefix)
debug(s"Start acceptor thread on listener ${endpoint.listenerName}")
//通过后台线程启动acceptor线程。
if (!acceptor.isStarted()) {
KafkaThread.nonDaemon(
s"${threadPrefix}-kafka-socket-acceptor-${endpoint.listenerName}-${endpoint.securityProtocol}-${endpoint.port}",
acceptor
).start()
acceptor.awaitStartup()
}
info(s"Started $threadPrefix acceptor and processor(s) for endpoint : ${endpoint.listenerName}")
}
private[network] def startProcessors(processorThreadPrefix: String): Unit = synchronized {
if (!processorsStarted.getAndSet(true)) {
startProcessors(processors, processorThreadPrefix)
}
}
private def startProcessors(processors: Seq[Processor], processorThreadPrefix: String): Unit = synchronized {
// 线程命名规范:processor线程前缀-kafka-network-thread-broker序号-监听器名称-安全协议-Processor序号
// 假设为序号为0的Broker设置PLAINTEXT://localhost:9092作为连接信息,那么3个Processor线程名称分别为:
processors.foreach { processor =>
KafkaThread.nonDaemon(
s"${processorThreadPrefix}-kafka-network-thread-$brokerId-${endPoint.listenerName}-${endPoint.securityProtocol}-${processor.id}",
processor
).start()
}
}
方法步骤如下:
启动acceptor下的Processors线程。创建Processor线程代码讲解提到过,Processor线程创建完成后要放入对应Acceptor线程的对应集合里。一个监听器对应一个Acceptor线程,一个Acceptor对应默认3个Processor线程。具体启动方法是:调用Acceptor类的方法startProcessors(),以后台线程的形式启动所有的Acceptor下所有的Processor线程。
通过后台线程启动acceptor线程。注意是先创建处理网络读写的线程再创建建立连接的线程,这样当Acceptor线程接到请求后能够把读写操作交给Processor线程完成。
好了,SocketServer类基本上学习完了,你可能对SocketServer类的设计有疑问:处理网络请求的时候为什么要分为两类线程,分别是Acceptor和Processor?为什么不能用一类线程然后用多线程处理呢?这里我们就要聊聊Reactor的设计模式了。
Reactor 的设计模式
Reactor是反应的意思,反应指的是「对事件反应」,也就是来了一个事件,Reactor 就有相对应的反应/响应。
Reactor设计模式也叫Dispatcher 模式,用于监听事件的Reactor线程监听到事件后,根据事件的类型分配给相应的处理逻辑。
Reactor设计模式分为3种:
单 Reactor 单业务进程;
单 Reactor 多业务线程;
多 Reactor 多业务线程。
单 Reactor 单业务进程
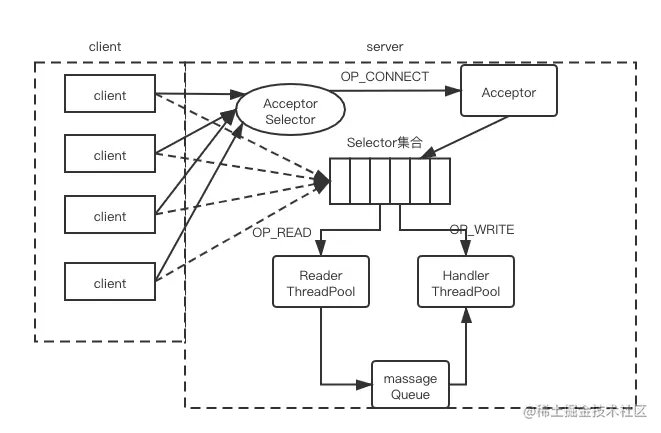
这种模式有三个对象:Selector、Acceptor、Handler(业务处理对象)。Handler 又细分为 Reader Handler(用于处理读)和 Writer Handler(用于处理写)。
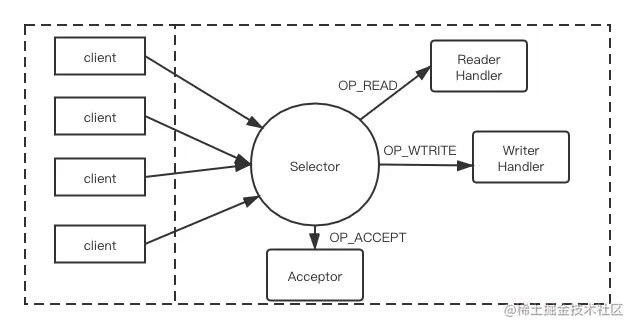
简单介绍其工作原理。
首先创建ServerSocketChannel 对象并在 Selector上注册OP_ACCEPT事件,ServerSocketChannel 负责监听指定端口上的连接请求。
当客户端发起到服务端的网络连接时,服务端的Selector 监听到此 OP_ACCEPT事件,会触发 Acceptor 来处理OP_ACCEPT。
当 Acceptor接收到来自客户端的 Socket连接请求时,会为这个连接创建相应的SocketChannel,将SocketChannel设置为非阻塞模式,并在Selector上注册其关注的I/O事件,例如,OP_READ OPWRITE。此时,客户端与服务端之间的Socket 连接正式建完成。
当客户端通过上面建立的Socket连接向服务端发送请求时,服务端的Selector会监听到OP_READ事件,并触发执行相应的处理逻辑(图中的 Reader Handler 业务线程)。当服务端可以向客户端写数据时,服务端的Selector会监听到 OP_WRITE事件,并触发执行相应的处理逻辑(图中的 Writer Handler 业务线程)。
注意:上述的一系列操作都是在一个线程中完成的。好处是逻辑简单,你可以回顾一下生产者的设计,用的就是一个线程处理所有的任务。这种设计比较适合数据量小的情况,因为生产者作为客户端仅仅是向一个服务端或几个服务端发送数据,而服务端就不一样了,生产环境中几百、上万的客户端连接都有可能的,数据量会很大。如果还用这种设计显然是不合理的。比如,一个线程处理请求处理是,遇到一个很复杂的业务造成了阻塞,这样其他的请求就处理不了了。同时,现在的服务器都是多核的,只运行一个线程是资源的浪费。
这样就出现了单 Reactor 多业务线程的模式。
单 Reactor 多业务线程
下图描述了单 Reactor 多业务线程模式的设计原理:
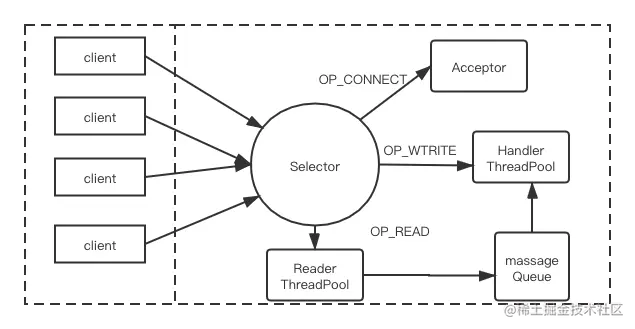
Acceptor 单独运行在一个线程中。Reader ThreadPool 线程池中的所有线程都会在 Selector上注册OP_READ事件,负责服务端读取请求的逻辑,当然也是一个线程对应处理多个Socket连接。Reader ThreadPool中的线程成功读取请求后,将请求放入MessageQueue,等待HandlerThreadPool消费MessageQueue 这个队列。
Hander ThreadPool 线程池中的线程会从MessageQueue中取出请求,然后执行业务逻辑对请求进行处理。这种模式下,即使处理某个请求的线程阻塞了,池中还有其他线程继续从 MessageQueue 中获取请求并进行处理,从而避免了个服务端阻塞。
当请求处理完成后,Handler 线程还负责产生响应并发送给客户端。 Handler ThreadPool 中的线程会在 Selector 中注册 OP_WRITE事件,实现发送响应的功能。
最后需要注意的是,当读取请求与业务处理之间的速度不匹配时,MessageQueue列长度的选择就显得尤为重要,尤其是 MessageQueue 队列是固定的大小的时候。如果的列长度太小,就会出现拒绝请求的情况;如果不限制 MessageQucue 队列的长度,则可能因为堆积过多未处理请求而导致内存溢出。这就需要设计人员根据实际的业务需求进行权衡和设计。
通过将网络处理与业务逻辑进行切分后实现了上述设计,此设计中读取、写入、业务处理都实现了多线程处理,不再存在性能瓶颈。但是,如果同一时间出现大量 I/O 事件单个 Selector 就可能在分发事件时阻塞(或延时)而成为瓶颈。我们可以将上述设计中单独的 Selector 对象扩展成多个,让它们监听不同的 I/O 事件,这样就可以避免单个 Selector带来的瓶颈问题。这就引出了下面的多 Reactor 多业务线程。
多 Reactor 多业务线程
如下图所示:
一般情况下,Acceptor单独占用一个Selector。当Acceptor Selector监听到OP_ ACCEPT时,会创建相应的 SocketChannel,在上图设计中,我们使用一定的策略,例如轮训 Selector 集合或选择注册连接数最少的 Selector,让不同的连接在不同的 Selector上注册 I/O事件。之后就由此Selector 负责监听此 SocketChannel 上的事件。
这样,就可以缓解单个Seletor带来的瓶颈问题。
总结
今天我们学习了SocketServer.scala文件。这个文件有8个部分,我们重点学习了其中的 SocketServer类,SocketServer类是服务端网络通信的基础和入口,同时还负责创建和启动服务端网络层的两个线程类Acceptor和Processor。Acceptor负责建立网络连接,Processor负责网络读写。
然后,我们还介绍了Reactor设计模式,Reactor设计模式总的来说是为了处理服务端高并发的场景,基于事件驱动的模式高效完成网络处理。Reactor设计模式分为三类:单 Reactor 单业务进程、单 Reactor 多业务线程、多 Reactor 多业务线程。
以下是对createDataPlaneAcceptorsAndProcessors()方法的详细分析:
一、整体功能概述
这个方法主要用于创建数据平面的Acceptor线程和Processor线程,以处理数据面的请求。它遍历所有的监听器(代表不同的端口或实例),为每个监听器进行一系列的操作,包括纳入连接配额管理、创建Acceptor线程、创建多个Processor线程,并将监听器与对应的Acceptor线程保存起来进行统一管理。
二、方法步骤解析
遍历监听器集合
endpoints.foreach { endpoint =>... }:这里遍历了所有的监听器(endpoint)。每个监听器代表一个特定的端口或实例,例如在一台服务器上配置的多个 Kafka 实例可以通过不同的端口区分开来,如node01:9092、node01:9093、node01:9094。这种多监听器的配置方式允许服务器同时处理来自不同渠道或不同类型的请求,提高了系统的灵活性和可扩展性。
纳入连接配额管理
connectionQuotas.addListener(config, endpoint.listenerName):这一步将监听器纳入连接配额管理之下。Kafka 服务端为了保证网络质量,对每个监听器的连接数量进行限制。通过连接配额管理,可以防止某个监听器因过多的连接而导致系统性能下降或崩溃。例如,如果不进行连接配额管理,一个监听器可能会被大量的请求淹没,导致其他监听器无法获得足够的资源,影响整个系统的稳定性。
创建
Acceptor线程val dataPlaneAcceptor = createAcceptor(endpoint, DataPlaneMetricPrefix):为每个监听器创建一个Acceptor线程。Acceptor线程专门负责与外部建立连接,是数据面请求进入系统的入口点。一个监听器只会分配一个Acceptor线程,这样可以确保连接的有序建立和管理。例如,当有生产者发送消息或消费者拉取消息的请求到达时,Acceptor线程会首先接收这些请求,并将它们传递给后续的处理线程。
创建多个
Processor线程addDataPlaneProcessors(dataPlaneAcceptor, endpoint, dataProcessorsPerListener):为每个监听器创建多个Processor线程。Processor线程用于处理网络读写操作,具体的线程数量由num.network.threads决定,默认是 3 个线程。多个Processor线程可以并行处理数据面的请求,提高系统的吞吐量和响应速度。例如,在高并发的情况下,多个Processor线程可以同时处理不同的生产者消息发送请求或消费者消息拉取请求,避免请求的积压和延迟。
保存并管理
dataPlaneAcceptors.put(endpoint, dataPlaneAcceptor):将监听器和对应的Acceptor线程保存到dataPlaneAcceptors这个map集合中进行统一管理。这样可以方便地跟踪和管理每个监听器的连接状态和处理线程,以便在需要时进行监控、故障排除或资源调整。例如,如果某个监听器出现问题,可以快速定位到对应的Acceptor线程和Processor线程,进行相应的处理。
三、重要性和作用
灵活性和可扩展性:通过支持多个监听器的配置,系统可以适应不同的网络环境和业务需求。例如,可以为不同的业务部门或应用程序分配不同的监听器,实现资源的隔离和定制化服务。
连接管理和性能优化:连接配额管理可以确保系统的稳定性和性能。通过限制每个监听器的连接数量,可以避免资源的过度消耗和系统的过载。同时,
Acceptor线程和Processor线程的合理配置可以提高系统的并发处理能力,减少请求的响应时间。统一管理和故障排除:将监听器和
Acceptor线程保存起来进行统一管理,方便了系统的监控和故障排除。管理员可以通过查看这个集合,了解每个监听器的状态和处理线程的运行情况,及时发现和解决问题。
在 Kafka 中,createDataPlaneAcceptorsAndProcessors 方法负责为数据面创建 Acceptor 和 Processor 线程。这些线程是 Kafka 网络层的核心,负责处理客户端的连接和数据交换。下面是该方法的详细解释:
Acceptor 线程的创建
连接配额管理:首先,方法会将每个监听器(endpoint)纳入连接配额管理。这是为了确保 Kafka 服务器能够处理的客户端连接数量不会超过配置的限制,从而保证网络资源的合理使用和服务质量。
创建 Acceptor 线程:对于每个监听器,会创建一个对应的 Acceptor 线程。Acceptor 线程的主要职责是监听来自客户端的连接请求。当一个新的连接请求到达时,Acceptor 线程会接受这个连接,并将其注册到一个 Selector 上,以便后续的读写操作。
Acceptor 线程通常与特定的监听器(即特定的端口和协议)关联,确保所有通过该监听器的连接请求都由同一个线程处理。
Processor 线程的创建
创建多个 Processor 线程:除了 Acceptor 线程,方法还会为每个监听器创建多个 Processor 线程。Processor 线程的数量由配置参数
num.network.threads决定,默认是 3 个。这些线程负责处理网络的读写事件,包括从网络中解码请求、将响应编码后写回网络等。处理网络事件:每个 Processor 线程都会处理一个或多个网络连接的读写事件。它们会从 Selector 中获取已经就绪的网络事件(如可读或可写事件),然后进行相应的处理。例如,当有数据可读时,Processor 线程会读取数据,并将其解析成 Kafka 请求;当有响应需要发送时,Processor 线程会将响应数据写入网络。
统一管理
最后,方法会将每个监听器与其对应的 Acceptor 线程存储在一个映射(map)中,以便进行统一管理和后续的资源清理。
总结
createDataPlaneAcceptorsAndProcessors 方法是 Kafka 启动过程中的一个关键步骤,它确保了 Kafka 服务器能够接收和处理来自客户端的连接请求和数据交换。通过为每个监听器配置一个 Acceptor 线程和多个 Processor 线程,Kafka 能够高效地处理大量的并发连接和数据请求,从而提供高吞吐量和低延迟的数据服务。
创建数据平面的`Acceptor`线程和`Processor`线程有什么作用? 如何优化数据平面的性能? 如何确保数据平面的高可靠性
一、创建数据平面的Acceptor线程和Processor线程的作用
(一)Acceptor线程的作用
连接建立:
Acceptor线程是数据面请求进入 Kafka 服务端的 “守门人”。它负责监听指定端口(对应不同的监听器),等待来自外部的连接请求,如生产者发送消息的请求或者消费者拉取消息的请求。例如,当一个生产者应用程序想要向 Kafka 集群发送消息时,它会尝试与 Kafka 服务端建立连接,此时Acceptor线程就会检测到这个连接请求并建立连接。初步处理与请求转发:在接受连接后,
Acceptor线程会对请求进行初步处理。这可能包括验证连接的合法性、提取请求中的基本信息等。然后,它会将请求转发给Processor线程进行后续的深度处理。例如,Acceptor线程可以从请求中获取一些元数据,如请求类型(是消息发送还是消息拉取)、目标主题等,并将这些信息和请求一起传递给Processor线程,确保Processor线程能够更高效地处理请求。
(二)Processor线程的作用
读写操作处理:
Processor线程主要负责实际的网络读写操作处理。对于生产者发送消息的请求,Processor线程会将消息写入对应的分区存储中。它会根据消息的目标分区、偏移量等信息,准确地将消息存储到合适的位置。例如,根据消息的键(Key)计算出应该存储到哪个分区,然后将消息追加到该分区的日志文件中。对于消费者拉取消息的请求,Processor线程会从分区存储中读取消息,并将消息返回给消费者。它会根据消费者请求的偏移量范围等信息,从存储中提取相应的消息,确保消费者能够获取到正确的消息序列。业务逻辑处理:除了基本的读写操作,
Processor线程还可能涉及一些业务逻辑处理。例如,在处理消息发送请求时,它需要验证消息的格式是否符合要求,包括消息头、消息体的格式等。在处理消息拉取请求时,它可能需要更新消费者的偏移量信息,记录消费者已经拉取到的位置,以便下次拉取时从正确的位置开始。同时,Processor线程还可能参与一些数据一致性检查和错误处理的工作,确保数据的准确性和完整性。并发处理提升性能:通过创建多个
Processor线程,可以实现对数据面请求的并发处理。这有助于提高系统的吞吐量和响应速度,特别是在高并发的场景下。例如,在电商促销活动期间,大量的订单消息需要发送到 Kafka,多个Processor线程可以同时处理这些消息发送请求,避免请求的积压和延迟。同样,当有众多消费者同时拉取消息时,多个Processor线程可以并行地从分区存储中读取消息并返回给消费者,提高消费者的体验。
二、优化数据平面性能的方法
(一)线程数量调整
根据负载动态调整
Processor线程数量:根据系统的实际负载情况,动态地调整Processor线程的数量。如果发现数据面请求的处理出现延迟或者系统的吞吐量无法满足需求,可以适当增加Processor线程的数量。例如,通过监控系统观察到在业务高峰期,消息发送和拉取请求的处理时间变长,可以通过配置参数增加num.network.threads的值,从而增加Processor线程数量,以提高并发处理能力。相反,在负载较低的时期,可以适当减少Processor线程数量,以节省系统资源。合理配置
Acceptor线程与Processor线程比例:虽然每个监听器通常只配置一个Acceptor线程,但需要考虑Acceptor线程与Processor线程之间的配合。如果Processor线程数量过多而Acceptor线程成为瓶颈,可能会导致请求在连接建立阶段就出现延迟。因此,需要根据实际的请求类型和处理复杂度,合理确定Acceptor线程和Processor线程的比例。例如,对于简单的消息处理场景,可能可以适当减少Processor线程数量,同时确保Acceptor线程能够快速地将请求转发给Processor线程。
(二)缓存策略
消息缓存:在
Processor线程处理读写操作时,可以采用适当的消息缓存策略。对于生产者发送的消息,可以在内存中设置一个消息缓存区。当消息到达Processor线程时,先将消息放入缓存区,然后再批量地将消息写入分区存储。这样可以减少磁盘 I/O 操作的频率,提高写入性能。例如,每累积 100 条消息后统一写入分区,而不是每条消息都立即写入。对于消费者拉取消息的请求,也可以采用缓存策略。在内存中缓存一部分经常被拉取的消息,当消费者请求这些消息时,可以直接从缓存中获取,减少从磁盘读取的时间。连接缓存:对于
Acceptor线程建立的连接,可以考虑进行连接缓存。当有新的请求来自已经建立过连接的客户端(如同一生产者或消费者)时,可以直接从缓存中获取连接信息,减少连接建立的时间。例如,通过维护一个连接缓存池,记录已经建立的连接的状态和相关信息,当客户端再次请求时,快速从缓存池中查找并复用连接,提高连接的复用率和系统的整体性能。
(三)优化网络配置
调整网络参数:优化网络相关的配置参数,如
socket.send.buffer.bytes和socket.receive.buffer.bytes等。适当增大发送和接收缓冲区的大小,可以减少网络传输过程中的频繁缓冲操作,提高网络传输效率。例如,如果发现网络传输过程中有较多的缓冲溢出错误或者消息传输延迟,可以适当增大这些缓冲区的大小,以适应大数据量的消息传输。使用高效的网络协议和技术:考虑采用更高效的网络协议或技术来优化数据平面的性能。例如,如果网络环境支持,使用零拷贝(Zero - Copy)技术可以减少数据在内存和网络之间的拷贝次数,从而提高数据传输速度。同时,确保 Kafka 服务端和客户端之间的网络连接稳定,避免网络抖动和丢包等问题,可以通过使用高质量的网络设备、优化网络拓扑结构等方式来实现。
三、确保数据平面高可靠性的方法
(一)冗余与备份
多节点和副本机制:在 Kafka 集群层面,通过多节点部署和分区副本机制来确保数据平面的可靠性。将数据存储在多个节点上的分区副本中,当一个节点出现故障时,其他节点上的副本可以继续提供服务。例如,每个分区可以有多个副本,其中一个为领导者(Leader)副本负责处理读写请求,其余为追随者(Follower)副本。如果领导者副本所在的节点出现故障,追随者副本可以快速接替成为新的领导者副本,确保数据的读写服务不中断。
数据备份策略:除了分区副本机制,还可以采用数据备份策略。定期对数据平面存储的数据进行备份,将备份数据存储在独立的存储介质或远程节点上。这样,在出现数据损坏、磁盘故障等极端情况下,可以从备份数据中恢复。例如,每天定时将分区数据备份到云端存储或者独立的磁盘阵列中,当本地磁盘出现故障导致数据丢失时,可以从备份数据中恢复分区数据。
(二)故障检测与恢复
心跳机制和故障监测:采用心跳机制来检测数据平面相关组件(如
Acceptor线程、Processor线程、节点等)的健康状况。例如,Processor线程可以定期向监控模块发送心跳信号,监控模块如果在一定时间内没有收到心跳信号,就判定该线程出现故障。同时,对系统的关键指标进行监测,如消息处理成功率、磁盘 I/O 错误率等,当这些指标超出正常范围时,也可以判断系统出现故障。一旦检测到故障,系统会启动相应的恢复机制。自动恢复流程:对于检测到的故障,要有自动恢复流程。如果是
Processor线程故障,可以尝试重启故障线程;如果是节点故障,需要重新分配分区副本,并选举新的领导者副本。例如,当发现一个节点的Processor线程出现故障时,系统会自动尝试重启该线程。如果重启失败,会将该节点上的分区副本重新分配到其他正常节点上,并在正常节点的Processor线程中继续处理数据请求。错误处理和重试机制:在
Processor线程处理数据请求过程中,建立完善的错误处理和重试机制。对于一些可恢复的错误,如网络暂时抖动导致的消息发送或接收中断,要进行重试操作。例如,当生产者发送消息时,如果因为网络问题没有收到确认(ACK),在一定的重试次数范围内,Processor线程会重新尝试接收并处理该消息发送请求,确保消息能够成功发送到目标分区。同时,对于无法重试或者重试多次后仍然失败的情况,要记录详细的错误信息,以便进行后续的故障排查。
创建数据平面的Acceptor线程和Processor线程的作用
Acceptor 线程的作用
监听端口:Acceptor 线程负责监听 Kafka 服务器配置的端口,等待客户端的连接请求。
接受连接:当客户端发起连接请求时,Acceptor 线程负责接受这些连接,创建新的 SocketChannel,并将其注册到 Processor 线程的 Selector 上,以便进行后续的读写操作。
Processor 线程的作用
网络读写:Processor 线程负责处理网络的读写事件。它们会从 Selector 中获取已经就绪的网络事件,并进行相应的处理,如读取客户端发送的数据,或者将服务器的响应数据写回客户端。
请求处理:Processor 线程将从网络中读取的二进制数据流解码成 Kafka 请求,并将这些请求放入请求队列中,等待后续的处理。
响应返回:对于已经处理完成的请求,Processor 线程还会负责将响应数据写入网络,返回给客户端。
如何优化数据平面的性能
增加 Processor 线程数量:通过配置
num.network.threads,可以增加 Processor 线程的数量,以提高网络读写的并发能力,从而提升整体的数据面性能。优化网络参数:调整网络相关的参数,如增加 socket 缓冲区大小(
socket.request.max.bytes、replica.socket.receive.buffer.bytes),可以减少网络拥塞和数据拷贝的次数,提高数据传输效率。使用高效的编解码:确保 Kafka 请求和响应的数据格式尽可能高效,减少编解码的开销。
合理配置请求队列:通过配置
queued.max.requests,可以限制请求队列中允许的请求数量,避免单个客户端的大量请求对其他客户端造成饥饿。使用零拷贝技术:Kafka 内部使用了 mmap 和 sendfile 等零拷贝技术,减少了数据在用户空间和内核空间之间的拷贝,提高了数据传输效率。
监控和调整:监控 Kafka 的性能指标,如网络线程的空闲率,请求队列的长度等,根据实际情况动态调整配置参数。
如何确保数据平面的高可靠性
副本机制:Kafka 通过多副本机制来提高数据的可靠性。每个分区可以配置多个副本,分布在不同的 Broker 上,即使某个 Broker 宕机,数据仍然可以从其他副本中恢复。
Leader Election:当 Leader 副本所在的 Broker 宕机时,Kafka 会通过 Controller 进行 Leader 选举,从 ISR(In-Sync Replicas)中选择一个新的 Leader 来继续提供服务。
数据同步:Kafka 确保所有 ISR 中的副本都与 Leader 保持同步,这样即使发生故障转移,新的 Leader 也会有完整的数据。
持久化存储:Kafka 将数据持久化存储到磁盘上,即使在 Kafka 进程崩溃的情况下,也能从磁盘恢复数据。
定期备份:定期备份 Kafka 数据到其他存储系统,可以在发生严重故障时恢复数据。
监控和报警:实施实时监控,一旦发现性能瓶颈或故障,立即报警并采取措施。
容错配置:合理配置 Kafka 的容错参数,如
unclean.leader.election.enable,以确保在发生故障时能够正确地进行故障转移。
通过上述措施,Kafka 的数据平面可以在高并发和高吞吐量的情况下,保持高可靠性和数据一致性。
在Kafka中,Acceptor线程和Processor线程之间是如何协作的?2如何调整Kafka的网络配置以应对高流量场景?在Kafka集群中,如何设置副本以确保数据的高可靠性?
一、Acceptor 线程和 Processor 线程之间的协作方式
(一)连接建立与请求传递
监听与接收请求:Acceptor 线程负责监听特定的端口,等待来自外部客户端(如生产者或消费者)的数据面请求。当有请求到达时,Acceptor 线程接受连接请求并建立与客户端的连接。例如,在一个典型的 Kafka 场景中,当生产者想要发送消息或者消费者想要拉取消息时,它们会向 Kafka 服务端的相应端口发起请求,Acceptor 线程会检测到这些请求并完成连接建立的操作。
请求初步处理与转发:在建立连接后,Acceptor 线程会对请求进行初步处理。这可能包括解析请求头以获取一些基本信息,如请求类型(是消息发送还是消息拉取)、目标主题等。然后,Acceptor 线程会将请求放入一个共享队列或者直接将请求传递给 Processor 线程。这个共享队列可以确保在高并发情况下请求的有序排队,避免 Processor 线程被过多的请求同时冲击。
(二)请求处理与反馈
Processor 线程的处理流程:Processor 线程从共享队列或者直接从 Acceptor 线程获取请求后,开始进行深度处理。对于生产者发送消息的请求,Processor 线程会验证消息格式、根据消息的目标分区信息将消息存储到对应的分区中,并记录消息的偏移量。对于消费者拉取消息的请求,Processor 线程会根据消费者请求的偏移量范围从分区中读取消息,并将消息返回给消费者,同时更新消费者的偏移量记录。
反馈处理结果:在 Processor 线程完成请求处理后,会将处理结果(如消息发送成功的确认、消息拉取成功的数据或错误信息)通过网络返回给客户端。同时,它也可能会向 Acceptor 线程或者其他管理模块反馈一些状态信息,如处理请求所花费的时间、是否出现异常等,以便 Acceptor 线程能够更好地管理连接和请求排队,或者用于系统的监控和性能优化。
二、调整 Kafka 的网络配置以应对高流量场景的方法
(一)调整缓冲区大小相关参数
发送缓冲区(socket.send.buffer.bytes):适当增大发送缓冲区的大小。在高流量场景下,生产者会频繁地向 Kafka 发送消息,增大发送缓冲区可以允许更多的消息在内存中等待发送,减少因缓冲区满而导致的消息发送延迟。例如,如果发现生产者发送消息的速度明显高于网络实际传输速度,并且出现消息积压的情况,可以尝试增大这个参数。但要注意,过大的缓冲区可能会占用过多的内存资源。
接收缓冲区(socket.receive.buffer.bytes):同样地,增大接收缓冲区大小有助于在高流量的消费者拉取消息场景下,减少因接收缓冲区溢出而导致的消息丢失或重传。当大量消费者同时拉取消息时,足够大的接收缓冲区可以容纳更多的消息,确保消息能够被及时处理。
(二)调整连接相关参数
最大连接数(max.connections):根据预估的高流量情况下的客户端连接数量,合理调整服务端允许的最大连接数。如果连接数限制过低,可能会导致部分客户端无法连接到 Kafka 服务端。但也要注意,过多的连接数可能会给系统带来过高的资源消耗和管理成本,需要综合考虑服务器的硬件资源和处理能力。
连接超时(connections.max.idle.ms):在高流量场景下,可以适当缩短连接超时时间。这样可以及时清理长时间空闲的连接,释放系统资源,以应对更多新的连接请求。例如,当有大量的生产者和消费者在短时间内与 Kafka 建立连接并完成消息发送或拉取后,部分连接可能会处于空闲状态,通过缩短连接超时时间,可以快速回收这些资源。
(三)优化网络 I/O 相关参数
I/O 线程数量(num.network.threads):增加网络 I/O 线程(即 Processor 线程)的数量。在高流量情况下,更多的 Processor 线程可以并行处理大量的数据面请求,提高系统的吞吐量。可以根据服务器的 CPU 核心数量、内存大小以及预期的流量负载,合理地增加这个参数的值。例如,在一个多核服务器上,且流量负载主要集中在数据面请求处理时,可以适当增加 Processor 线程数量,以充分利用 CPU 资源。
启用零拷贝(Zero - Copy)技术(如果支持):如果操作系统和 Kafka 版本支持零拷贝技术,启用它可以显著提高网络传输效率。零拷贝技术减少了数据在内存和网络之间的拷贝次数,从而加快了消息的发送和接收速度,特别适用于处理高流量的大数据消息。
三、在 Kafka 集群中设置副本以确保数据高可靠性的方法
(一)确定副本数量
根据数据重要性和系统可用性要求:对于非常重要的数据主题,如金融交易记录、关键业务指标数据等,可以设置较多的副本数量。一般来说,副本数量越多,数据的冗余度越高,数据丢失的风险就越低。但副本数量的增加也会带来存储成本和数据同步开销的增加。例如,对于一个要求极高可用性的金融数据主题,可以设置 5 个副本;而对于一些不太重要的日志主题,可能设置 3 个副本就足够了。
考虑集群规模和资源限制:副本数量还需要考虑集群的规模和资源限制。如果集群中的节点数量有限,设置过多的副本可能会导致每个节点的存储和处理负担过重。在一个较小的 Kafka 集群中,要合理平衡副本数量和节点资源,确保每个节点都能够正常存储和同步副本数据。例如,在一个只有 5 个节点的集群中,对于每个分区设置 4 个副本可能会使节点的存储和网络资源紧张,此时可以考虑设置 3 个副本。
(二)副本分布策略
跨节点均匀分布:副本应该尽量均匀地分布在不同的节点上。这样可以避免因某个节点故障而导致大量副本数据丢失的情况。例如,在一个有 10 个节点的集群中,对于一个分区的 3 个副本,应该分别放置在不同的节点上,而不是集中在少数几个节点。可以通过 Kafka 的分区分配策略和副本分配算法来实现副本的跨节点均匀分布。
考虑机架(Rack)因素(如果适用):在大型数据中心环境中,如果服务器分布在不同的机架上,还需要考虑副本在不同机架之间的分布。将副本分布在不同机架的节点上,可以进一步降低因机架级故障(如电源故障、网络交换机故障等)导致的数据丢失风险。例如,对于一个有多个机架的集群,每个分区的副本应该至少分布在两个不同机架的节点上。
(三)副本同步机制
保持副本同步的及时性:确保副本之间能够及时同步数据是保证数据可靠性的关键。Kafka 通过领导者(Leader)副本和追随者(Follower)副本的机制来实现数据同步。领导者副本负责处理读写请求,追随者副本会定期从领导者副本拉取数据进行更新。需要合理设置副本同步的频率和延迟时间,以确保在领导者副本出现故障时,追随者副本的数据是最新的。例如,可以根据业务对数据时效性的要求和网络带宽等因素,调整追随者副本从领导者副本拉取数据的时间间隔。
监控副本同步状态:建立副本同步状态的监控机制。通过监控工具或 Kafka 自带的监控指标,如副本的滞后程度(即追随者副本与领导者副本之间的数据差距)、同步成功率等,及时发现副本同步过程中出现的问题。当发现副本同步出现延迟或者错误时,能够及时采取措施进行修复,如重新同步、更换有问题的节点等。
Acceptor线程和Processor线程的协作
在Kafka中,Acceptor线程和Processor线程之间的协作主要体现在网络通信的处理上。Acceptor线程负责监听新的连接请求,并在有新的连接建立时,将这些连接(SocketChannel)以轮询(round-robin)的方式分配给Processor线程处理。Processor线程负责后续与这些SocketChannel相关的数据读写操作,包括读取客户端发送的数据、解析请求、发送响应等。Processor线程将读取到的数据解析成Kafka可以处理的请求对象,并将其放入全局的请求队列(requestQueue)中。处理完客户端的请求后,Processor线程会将生成的响应数据写入到对应的SocketChannel中,并注册OP_WRITE事件,以便在数据真正写入到Socket时得到通知。这种设计允许Kafka在不同的阶段使用不同数量的线程,以优化资源的使用和系统的性能。
调整Kafka的网络配置以应对高流量场景
为了应对高流量场景,可以采取以下措施调整Kafka的网络配置:
增加网络和IO线程数量:通过配置
num.network.threads和num.io.threads,可以增加处理网络事件和IO操作的线程数量,从而提高Kafka处理高并发请求的能力。优化Socket缓冲区大小:通过调整
socket.send.buffer.bytes和socket.receive.buffer.bytes,可以增加Socket缓冲区的大小,减少网络拥塞和数据拷贝的次数,提高数据传输效率。调整请求和响应的最大字节数:通过配置
socket.request.max.bytes,可以增加单个请求或响应的最大字节数,允许更大的消息通过,减少小消息带来的开销。启用数据压缩:Kafka支持对数据进行压缩以减少网络传输和磁盘存储。通过设置
compression.type为snappy等压缩算法,可以显著减小数据传输的大小,提高性能。调整文件描述符限制:Kafka在高负载情况下可能会涉及大量文件句柄的操作,通过调整操作系统的文件描述符限制,可以确保Kafka能够处理大量的并发连接。例如,使用
ulimit -n 65536调整文件描述符的限制。优化操作系统的TCP参数:通过更改操作系统的TCP参数,如
net.core.somaxconn和net.ipv4.tcp_max_syn_backlog,可以调整TCP连接的最大等待队列,以确保更好的网络性能。
在Kafka集群中设置副本以确保数据的高可靠性
在Kafka集群中,可以通过以下方式设置副本以确保数据的高可靠性:
合理设置分区和副本数:创建主题时,通过设置合理的分区数和副本数,可以满足业务需求并保障负载均衡。例如,使用
kafka-topics.sh --create --topic my_topic --partitions 6 --replication-factor 3 --bootstrap-server localhost:9092创建一个具有6个分区和3个副本的主题。确保数据的持久化存储:Kafka将数据持久化存储到磁盘上,即使在Kafka进程崩溃的情况下,也能从磁盘恢复数据。
监控和调整ISR集合:Kafka通过In-Sync Replicas(ISR)集合来确保数据的高可靠性。监控ISR集合的大小和分区分布,确保副本同步状态良好。
合理配置副本相关参数:通过配置如
replica.lag.time.max.ms、num.replica.fetchers、replica.fetch.min.bytes、replica.fetch.max.bytes和replica.fetch.wait.max.ms等参数,可以优化主从同步过程,确保数据的一致性和可靠性。
通过上述措施,Kafka能够在面对节点故障、网络波动等不利条件时依然能够稳定、高效地运行,确保数据的高可靠性。
19.服务端通信层:Acceptor 线程类和 Processor 线程类
Acceptor类是负责接收外部请求并与外部建立网络连接,随后Acceptor线程类会把建立好的连接交给集合内的Processor线程类,Processor线程类负责在连接上读取或写入数据。
Acceptor线程类
Acceptor线程类会构建单独一个Selector和一个serverChannel处理外部请求,并构建一个线程监控Accept事件。我们首先讲解类的参数和重要的字段。
参数和重要的字段
Acceptor类的参数和重要字段参见下面的代码:
private[kafka] class Acceptor(val endPoint: EndPoint,//终端
val sendBufferSize: Int,//出栈网络io底层缓冲区大小,默认100k
val recvBufferSize: Int,//入栈网络io底层缓冲区大小,默认100k
brokerId: Int,//broker id
connectionQuotas: ConnectionQuotas,//连接配额
metricPrefix: String) extends AbstractServerThread(connectionQuotas) with KafkaMetricsGroup {
// 创建底层的NIO Selector对象
// Selector对象负责执行底层实际I/O操作,如监听连接创建请求、读写请求等,注意不是KSelector
private val nioSelector = NSelector.open()
// Broker端创建对应的ServerSocketChannel实例
val serverChannel = openServerSocket(endPoint.host, endPoint.port)
// 创建此Acceptor对应的Processor线程池,实际上是Processor线程数组
private val processors = new ArrayBuffer[Processor]()
Acceptor线程类继承了抽象类AbstractServerThread,AbstractServerThread封装了一些为线程服务的公共的方法和参数,比如,线程启动和停止要做的一些额外的工作等。
其类参数如下。
endPoint:终端。包括ip、port等数据。sendBufferSize:出栈网络io底层缓冲区大小,默认100k。recvBufferSize:入栈网络io底层缓冲区大小,默认100k。brokerId:所在的broker的编号id。connectionQuotas:连接配额,为了保证已成功连接正常工作,要通过连接配额控制连接的数量。
字段可总结为如下。
nioSelector:Acceptor线程类的java nio selector对象,一个Acceptor线程类拥有一个selector对象。serverChannel:java nio 的ServerSocketChannel类对象。processors:processor线程类集合,一个Acceptor类对象都有一个processor线程类集合,当Acceptor类建立好一个网络连接后,会从集合里取出一个processor线程类处理这个网络连接上的网络操作。
介绍完了类的参数和类的字段,我们来学习一下方法,首先给大家讲解建立连接的方法accept(key)。
accept()
这个方法接收请求并建立连接,然后返回对应的SocketChannel,也就是我们所说的连接。具体方法代码如下:
private def accept(key: SelectionKey): Option[SocketChannel] = {
val serverSocketChannel = key.channel().asInstanceOf[ServerSocketChannel]
//1.客户端和服务端建立起了连接。
val socketChannel = serverSocketChannel.accept()
try {
//2.连接统计
connectionQuotas.inc(endPoint.listenerName, socketChannel.socket.getInetAddress, blockedPercentMeter)
//3.配置相关属性,如非阻塞,keepAlive,sendBufferSize的大小等。
socketChannel.configureBlocking(false)
socketChannel.socket().setTcpNoDelay(true)
socketChannel.socket().setKeepAlive(true)
if (sendBufferSize != Selectable.USE_DEFAULT_BUFFER_SIZE)
socketChannel.socket().setSendBufferSize(sendBufferSize)
Some(socketChannel)
} catch {
case e: TooManyConnectionsException =>
info(s"Rejected connection from ${e.ip}, address already has the configured maximum of ${e.count} connections.")
close(endPoint.listenerName, socketChannel)
None
}
}
好,接下来我们重点分析线程类Acceptor的run()方法。
第一步,从SelectionKey类对象参数key中取得serverSocketChannel,然后从serverSocketChannel中获取连接socketChannel。
第二步,更新连接统计,连接数加一。
第三步,配置相关属性,如非阻塞、keepAlive、sendBufferSize的大小等。
第四步,返回socketChannel。
好,我们接下来学习线程类的核心方法run()方法。
run() 方法
源码如下:
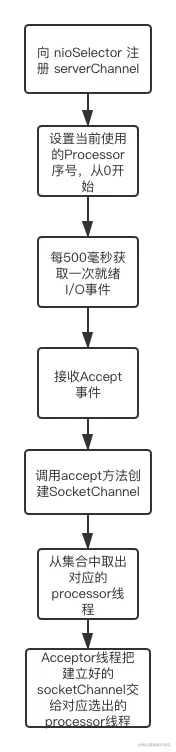
def run(): Unit = {
//1.向 nioSelector 注册 serverChannel 并监控serverChannel上的OP_ACCEPT 事件,等待客户端的请求
serverChannel.register(nioSelector, SelectionKey.OP_ACCEPT)
//2.标识Acceptor 线程启动完成,并唤醒阻塞的线程。
startupComplete()
try {
// 3.当前使用的Processor序号,从0开始,最大值是num.network.threads - 1
var currentProcessorIndex = 0
while (isRunning) {
try {
// 4.每500毫秒获取一次就绪I/O事件
val ready = nioSelector.select(500)
if (ready > 0) {
//5.获取所有监听到的注册的key
val keys = nioSelector.selectedKeys()
val iter = keys.iterator()
while (iter.hasNext && isRunning) {
try {
val key = iter.next
iter.remove()
// 6.只监控Accept事件。
if (key.isAcceptable) {
//调用accept方法创建Socket连接
//轮询处理socketChannel
accept(key).foreach { socketChannel =>
var retriesLeft = synchronized(processors.length)
var processor: Processor = null
do {
retriesLeft -= 1
// 7.轮询选择哪个 Processor线程进行处理,目的是负载均衡
processor = synchronized {
currentProcessorIndex = currentProcessorIndex % processors.length
//取出对应的processor
processors(currentProcessorIndex)
}
// 8.更新Processor线程序号,这样下次就能用下一个Processor了。
currentProcessorIndex += 1
//9.Acceptor线程把建立好的socketChannel交给对应选出的processor
} while (!assignNewConnection(socketChannel, processor, retriesLeft == 0))
}
//因为只注册了OP_ACCEPT事件,如果是别的事件就应该抛出异常。
} else
throw new IllegalStateException("Unrecognized key state for acceptor thread.")
} catch {
case e: Throwable => error("Error while accepting connection", e)
}
}
}
}
catch {
case e: ControlThrowable => throw e
case e: Throwable => error("Error occurred", e)
}
}
} finally {
// 执行各种资源关闭逻辑
debug("Closing server socket and selector.")
//关闭连接
CoreUtils.swallow(serverChannel.close(), this, Level.ERROR)
//关闭连接对应的Selector
CoreUtils.swallow(nioSelector.close(), this, Level.ERROR)
//标识关闭完成,并唤醒对应的执行关闭的被阻塞的线程
shutdownComplete()
}
}
给你介绍下这个执行步骤。
第一步,serverChannel向nioSelector注册,并监控serverChannel上的OP_ACCEPT 事件,等待客户端的请求。
第二步,标识Acceptor 线程启动完成,并唤醒阻塞的线程。因为线程的启动是在别的类里,当启动后并不知道是否启动成功所以会阻塞,而是否能启动成功的判断在这一步,这样到这步就应该给解除线程的阻塞了。
第三步,进入while(true)轮询代码,标识当前轮询到的Processor线程的序号。
第四步,调用Selector的select()方法,监听是否有网络连接事件。每500毫秒轮询一次。收到监听事件后把key拿出来,然后判断是否是Accept事件,只有Accept事件才会处理。
第五步,获取所有监听到的注册的key。
第六步,判断是否是Accept事件,因为Acceptor线程类只处理Accept事件。如果是Accept事件就调用accept()方法,建立连接并开始轮询处理socketChannel。
第七步,从Acceptor类字段processors集合轮询选择出一个Processor线程。这样能够把任务平均分配到processors集合内Processor线程里。这样能确保某个Processor线程的负担不至于很重。
第八步,当前Processor索引加一。这样下次分配的Processor线程就是processors集合的下一个Processor线程。
第九步,把新创建的socketChannel分配给选到的Processor线程。
这个过程有点复杂,我下面画了个流程图帮助你理解:
好,Acceptor线程类基本就介绍完了,接下来我们介绍Processor线程类。
Processor线程类
Acceptor线程类负责创建连接并把代表连接的socketChannel交给Processor线程类处理。Processor线程类得到socketChannel后,会处理这个socketChannel上的网络读写请求。
重要字段
接下来我们先学习一下重要的字段。源码如下:
private[kafka] class Processor(val id: Int,
time: Time,
maxRequestSize: Int,
requestChannel: RequestChannel,
connectionQuotas: ConnectionQuotas,
connectionsMaxIdleMs: Long,
failedAuthenticationDelayMs: Int,
listenerName: ListenerName,
securityProtocol: SecurityProtocol,
config: KafkaConfig,
metrics: Metrics,
credentialProvider: CredentialProvider,
memoryPool: MemoryPool,
logContext: LogContext,
connectionQueueSize: Int = ConnectionQueueSize) extends AbstractServerThread(connectionQuotas) with KafkaMetricsGroup {
//每个Processor线程都有自己的SocketChannel队列,用来保存连接的信息
//当Acceptor线程接收新的连接请求时,会把连接放入Processor线程对应的SocketChannel队列中。
private val newConnections = new ArrayBlockingQueue[SocketChannel](connectionQueueSize)
//inflightResponses里的集合元数是:返回给客户端途中的响应。
private val inflightResponses = mutable.Map[String, RequestChannel.Response]()
//Response队列
private val responseQueue = new LinkedBlockingDeque[RequestChannel.Response]()
//注意这里创建的是KSelector
private val selector = createSelector(
ChannelBuilders.serverChannelBuilder(listenerName,
listenerName == config.interBrokerListenerName,
securityProtocol,
config,
credentialProvider.credentialCache,
credentialProvider.tokenCache,
time,
logContext))
newConnections:类型为ArrayBlockingQueue[SocketChannel]的队列,保存的元素是SocketChannel,Acceptor创建SocketChannel后把SocketChannel放到这个集合里。inflightResponses:类型为mutable.Map[String, RequestChannel.Response]的map集合,这是个临时 Response 集合。里面保存是每个连接对应的返回给客户端途中的响应。有些 Response 回调逻辑要在 Response 被发送回发送方之后,才能执行,比如:response成功发送后要执行的回调逻辑,因此需要暂存在一个临时队列里面。这就是 inflightResponses 存在的意义。responseQueue:Response队列,Response队列里面保存着要返回给客户端的响应。selector:用作监听网络事件的KSelector类对象,KSelector类是kafka基于nio 的Selector封装的类,讲解生产者的时候就已经讲解过了,这里就不再展开讨论。
讲完重要的字段后,接下来我们继续讲解这个类里重要的方法。Processor线程类的方法比较多,因为这个类是真正处理网络读写的类,我会给你一个个讲解。
accept()方法
这个方法是由Acceptor类调用的,用于把新建的socketChannel分配给Processor线程类。方法的源码如下:
/** * 把 socketChannel 加入 newConnections 集合里,等待Processor线程的处理 */
def accept(socketChannel: SocketChannel,mayBlock: Boolean,
acceptorIdlePercentMeter: com.yammer.metrics.core.Meter): Boolean = {
val accepted = {
if (newConnections.offer(socketChannel))
true
else if (mayBlock) {
val startNs = time.nanoseconds
newConnections.put(socketChannel)
acceptorIdlePercentMeter.mark(time.nanoseconds() - startNs)
true
} else
false
}
if (accepted)
wakeup()
accepted
}
这个方法其实很简单,就是把socketChannel放入Processor类字段newConnections集合里。也就是说Processor线程类并没有直接处理socketChannel,而是Acceptor类把socketChannel先存放在newConnections集合里,等待Processor线程类处理。
好,接下来我们看看Processor线程类是如何处理newConnections集合里的socketChannel的。
方法 configureNewConnections()
源码在下面,我给你一步步讲解下:
/**
* 注册在队列里的新连接。每次迭代处理连接的数量是被限制的,目的是保证已存在的连接通信顺畅。
*/
private def configureNewConnections(): Unit = {
var connectionsProcessed = 0// 当前已配置的连接数计数器
//一次迭代要处理的连接要小于connectionQueueSize=20个,并且连接集合不能为空
while (connectionsProcessed < connectionQueueSize && !newConnections.isEmpty) {
val channel = newConnections.poll()// 从连接队列中取出SocketChannel
try {
debug(s"Processor $id listening to new connection from ${channel.socket.getRemoteSocketAddress}")
// 用给定Channel注册到指定的Selector,并监听OP_READ事件
// 底层就是调用Java NIO的SocketChannel.register(selector, SelectionKey.OP_READ)
selector.register(connectionId(channel.socket), channel)
connectionsProcessed += 1// 更新计数器
} catch {
case e: Throwable =>
val remoteAddress = channel.socket.getRemoteSocketAddress
close(listenerName, channel)
processException(s"Processor $id closed connection from $remoteAddress", e)
}
}
}
第一步,首先代码会进入一个while循环,必须同时满足下面两个条件才能进入while循环。
connectionsProcessed < connectionQueueSize:connectionsProcessed是while循环内处理的连接数,connectionQueueSize是处理连接队列的长度,默认值是20。也就是说,方法configureNewConnections调用一次,只能处理20个连接。每次迭代处理连接的数量是被限制的,目的是保证已存在的连接通信通畅。
!newConnections.isEmpty: 连接队列集合newConnections不为空,没有新的连接就不会进入while循环。
第二步,进入while循环后,从连接队列newConnections中取出一个SocketChannel。
第三步,把这个SocketChannel注册到Processor线程类的selector,并监听网络读事件。
第四步,connectionsProcessed += 1:更新计数器加一。
好,下面我们来看看给客户端的响应是如何发送的。相关方法有两个processNewResponses()和sendResponse()。
方法 processNewResponses()
首先我们看看processNewResponses()做了什么。下面是源码,并附加注释,我会分步骤给你讲解。
private def processNewResponses(): Unit = {
//声明一个response变量。
var currentResponse: RequestChannel.Response = null
//从响应队列中取出response
while ({currentResponse = dequeueResponse(); currentResponse != null}) {
// 获取 channel_id
val channelId = currentResponse.request.context.connectionId
try {
currentResponse match {
//不需要给客户端响应的Response类型,无需做太多的操作。
//acks=0
case response: NoOpResponse =>
updateRequestMetrics(response)
trace(s"Socket server received empty response to send, registering for read: $response")
handleChannelMuteEvent(channelId, ChannelMuteEvent.RESPONSE_SENT)
// 没有响应需要发送给客户端,需要读取更多的请求,于是,channel 再次绑定OP_READ事件。
tryUnmuteChannel(channelId)
// 真正的发送Response,并将Response放入inflightResponses用于发送响应成功或响应失败后执行回调逻辑。
case response: SendResponse =>
sendResponse(response, response.responseSend)
case response: CloseConnectionResponse =>
updateRequestMetrics(response)
trace("Closing socket connection actively according to the response code.")
close(channelId)
case _: StartThrottlingResponse =>
handleChannelMuteEvent(channelId, ChannelMuteEvent.THROTTLE_STARTED)
case _: EndThrottlingResponse =>
handleChannelMuteEvent(channelId, ChannelMuteEvent.THROTTLE_ENDED)
tryUnmuteChannel(channelId)
case _ =>
throw new IllegalArgumentException(s"Unknown response type: ${currentResponse.getClass}")
}
} catch {
case e: Throwable =>
processChannelException(channelId, s"Exception while processing response for $channelId", e)
}
}
}
第一步,声明一个response变量,这个变量用来保存要发送的response对象。从响应队列中取出。然后从响应队列里取出一个response,响应队列是阻塞的队列里没有响应对象就一直会阻塞在这里。
第二步,从队列中取出response后,判断response的类型,我们这里分析最重要也是出现最多的两种情况。
NoOpResponse:表示不需要给客户端响应的Response类型。这种情况的原因一般是生产端设置了acks=0,acks=0表示无需服务端的响应。由于不需要把响应发给客户端,同时对应的SocketChannel要继续处理读事件。调用方法tryUnmuteChannel(channelId),channel会再次绑定OP_READ事件。
SendResponse:表示客户端需要服务端的响应。这时会调用方法sendResponse()向客户端发送响应。
方法 sendResponse()
接下来我们看看方法sendResponse()做了哪些事情。
这个方法主要是完成了发送响应的准备工作,并把response对象放入inFlightResponses集合中临时存放response对象。代码在下面,我会分步骤给你讲解。
protected[network] def sendResponse(response: RequestChannel.Response, responseSend: Send): Unit = {
//获取得到对应的channelId。
val connectionId = response.request.context.connectionId
trace(s"Socket server received response to send to $connectionId, registering for write and sending data: $response")
//查找对应的kafkaChannel,判断是否为空
if (channel(connectionId).isEmpty) {
warn(s"Attempting to send response via channel for which there is no open connection, connection id $connectionId")
response.request.updateRequestMetrics(0L, response)
}
// 连接是否可以用
if (openOrClosingChannel(connectionId).isDefined) {
//向客户端返回响应,本质是缓存在了对应的KafkaChannel里,将响应通过Selector先标记为Send,
// 下次轮询时把响应发送给客户端。
//并且selector会在SocketChannel上注册OP_WRITE事件等待写事件发生。
selector.send(responseSend)
//把响应放入inflightResponses map集合里。
inflightResponses += (connectionId -> response)
}
}
第一步,获取response对应连接的id,并查找对应的kafkaChannel,并判断是否为空。
第二步,判断连接是否可以,如果可用就调用selector.send(responseSend)方法去做发送响应的准备工作。
第三步,把channelid和返回的response放入map集合inflightResponses里。inflightResponses里的响应是指是要发送但还没确定发送成功过的响应。目的是,inflightResponses里的response有回调方法,根据响应发送的结果会调用回调方法。
好,发送响应的准备工作做完了,我们来看看响应是怎么发送客户端的.
整体功能理解
sendResponse()方法在 Kafka 服务端的网络通信层起到了关键作用。它主要负责处理将响应发送给客户端的前期准备工作,包括对连接状态的检查、发送操作的初步设置以及对未发送成功的响应进行暂存管理,确保响应能够在合适的时机准确地发送给客户端。
步骤详细分析
第一步:获取连接 ID 并查找对应的 KafkaChannel,检查是否为空
功能:首先通过
response.request.context.connectionId获取响应对应的连接 ID。这个连接 ID 是用于唯一标识客户端与服务端之间的连接。然后,利用这个连接 ID 查找对应的kafkaChannel。检查kafkaChannel是否为空是很重要的一步,因为如果kafkaChannel为空,意味着可能没有建立有效的连接,这可能是由于连接已经关闭或者出现异常导致的。意义:这一步骤的检查可以帮助提前发现潜在的问题,避免在不存在有效连接的情况下尝试发送响应,从而引发错误。例如,在网络波动导致连接意外中断的情况下,能够及时捕获这种情况,避免后续无意义的发送操作。
第二步:判断连接是否可用并进行发送响应的准备工作
功能:通过
openOrClosingChannel(connectionId).isDefined判断连接是否可用。如果连接可用,就调用selector.send(responseSend)方法进行发送响应的准备工作。在这里,selector是 Kafka 网络通信中用于处理 I/O 事件的关键组件。selector.send(responseSend)的操作本质上是将响应缓存在对应的KafkaChannel里,并且通过Selector先将响应标记为Send。这样,在下一次轮询时,Selector就会检测到这个Send标记,进而把响应发送给客户端。同时,Selector会在SocketChannel上注册OP_WRITE事件,等待写事件发生,以便在合适的时机将响应数据写入网络通道发送给客户端。意义:这一步骤是实现响应发送的核心环节。通过
Selector的机制,可以高效地管理网络 I/O 事件,将响应的发送与网络的实际状态(如是否可写)相结合,确保响应能够在网络通道允许的情况下及时发送。这种异步的、基于事件驱动的发送方式有助于提高系统的整体性能和吞吐量。
第三步:将连接 ID 和响应放入
inflightResponses集合功能:将连接 ID 和返回的响应放入
map集合inflightResponses中。这个集合用于临时存放尚未确定发送成功的响应。这里的响应之所以被放入这个集合,是因为它们有回调方法。当响应发送的结果确定后(例如,发送成功或者发送失败),会根据这个结果调用相应的回调方法。这种回调机制可以用于后续的处理,如更新请求的状态、记录发送的结果等操作。意义:
inflightResponses集合的存在提供了一种跟踪和管理未完成发送的响应的方式。通过回调方法,可以在发送过程出现各种情况时进行灵活的处理,例如在发送失败时进行重试或者记录错误信息,从而增强了系统的可靠性和容错性。
与客户端通信的衔接
在完成这些准备工作后,响应的发送实际上是通过
Selector的轮询机制来实现的。Selector会在合适的时机(如网络通道可写时)检测到之前标记为Send的响应,并将其发送给客户端。在这个过程中,inflightResponses集合中的响应会随着发送状态的变化而被相应地处理,通过回调方法实现对发送结果的反馈和后续操作。这种设计使得 Kafka 服务端能够高效、可靠地与客户端进行通信,确保响应能够准确地传递到客户端。
方法 poll()
poll()方法是真正做了发送response到客户端的工作。我们看下这个方法的代码:
private def poll(): Unit = {
val pollTimeout = if (newConnections.isEmpty) 300 else 0
try selector.poll(pollTimeout)
catch {
case e @ (_: IllegalStateException | _: IOException) =>
error(s"Processor $id poll failed", e)
}
}
这个方法很简单就是调用selector.poll()方法,这个方法获取对应SocketChannel上准备就绪的I/O操作并执行对应操作的方法。对应已经发送消息成功的响应会把发送的响应放入集合completedSends里。
好,接下来我们看一下处理成功响应的方法processCompletedSends()。
方法 processCompletedSends()
这个方法的源码以及注释在下面:
private def processCompletedSends(): Unit = {
//遍历SocketChannel已经发送的Response。
selector.completedSends.forEach { send =>
try {
//因为Response已经发送出去了,这时需要把表示正在处理的响应集合inflightResponses对应的响应删除
val response = inflightResponses.remove(send.destination).getOrElse {
throw new IllegalStateException(s"Send for ${send.destination} completed, but not in `inflightResponses`")
}
//更新统计指标
updateRequestMetrics(response)
// 调用发送完成的回调方法,服务端完成发送后也是要调用对应的回调方法的。
response.onComplete.foreach(onComplete => onComplete(send))
handleChannelMuteEvent(send.destination, ChannelMuteEvent.RESPONSE_SENT)
//重新注册OP_READ,这样又可以监听客户端请求了。也就是说一个channel处理完了才会继续监听,不存在一个channel同时处理两个请求的情况。
tryUnmuteChannel(send.destination)
} catch {
case e: Throwable => processChannelException(send.destination,
s"Exception while processing completed send to ${send.destination}", e)
}
}
selector.clearCompletedSends()
}
第一步,遍历SocketChannel已经发送成功的Response。已经发送成功的Response在KSelector的集合completedSends内。只要遍历这个集合就能够获得已经发送成功的Response。
第二步,删除并获取inflightResponses已经发送成功的response对象。已经发送成功的响应就不应该在临时响应集合里。
第三步,调用临时集合中的response对象的回调方法。(注意这里不是发送成功的response对象。)
第四步,重新注册这个channel的OP_READ事件。这样又可以监听客户端请求了。也就是说一个channel处理完了才会继续监听,不存在一个channel同时处理两个请求的情况。
以下是对processCompletedSends()方法的详细分析:
一、整体功能概述
这个方法主要用于处理已经完成发送的响应。它确保在响应成功发送后,进行一系列的清理和后续处理操作,以保持系统的状态正确并为接收新的请求做好准备。
二、方法步骤解析
第一步:遍历已发送的响应
selector.completedSends.forEach { send =>... }:这里遍历了SocketChannel已经发送成功的响应。completedSends集合存储了所有已经成功发送的响应对应的发送操作信息。通过遍历这个集合,可以逐一处理每个已发送的响应,确保后续的清理和状态更新操作能够正确执行。例如,在高并发的场景下,可能有多个响应同时发送成功,通过遍历可以对每个响应进行独立的处理。
第二步:删除并获取已发送的响应对象
val response = inflightResponses.remove(send.destination).getOrElse {...}:从临时存储未完成发送响应的inflightResponses集合中删除已经发送成功的响应对象。这一步非常重要,因为已经发送成功的响应不应该再留在临时集合中。如果在临时集合中找不到对应的响应,会抛出异常,表明系统出现了不一致的状态。例如,确保不会出现响应被重复处理或者遗漏处理的情况。
第三步:调用响应对象的回调方法
response.onComplete.foreach(onComplete => onComplete(send)):调用临时集合中已发送成功响应对象的回调方法。这个回调方法可以用于执行一些后续的处理逻辑,比如更新请求的状态、记录发送的结果等。虽然这里注释提到 “注意这里不是发送成功的 response 对象”,但实际上通过回调方法可以间接操作发送成功的响应对象,以实现特定的业务逻辑。例如,在一个分布式事务的场景中,响应发送成功后可以触发其他相关操作的回调,确保事务的一致性。
第四步:重新注册 OP_READ 事件并准备接收新请求
tryUnmuteChannel(send.destination):重新注册这个通道的OP_READ事件,这样又可以监听客户端的请求了。这意味着一个通道在处理完一个请求并发送响应后,才会继续监听新的请求,不存在一个通道同时处理两个请求的情况。这种设计确保了请求的有序处理,避免了混乱和并发问题。例如,保证每个请求都能得到完整的处理,不会出现多个请求相互干扰的情况。
三、重要性和作用
状态管理和一致性:通过及时清理已发送的响应对象,维护了系统的状态一致性。确保临时集合中只存储未完成发送的响应,避免了资源的浪费和错误的处理。
回调机制和业务逻辑扩展:回调方法的使用为系统提供了灵活性,可以在响应发送成功后执行特定的业务逻辑。这对于实现复杂的业务流程和系统集成非常重要。
高效的请求处理:通过有序地处理请求和响应,确保了系统的高效性和稳定性。一个通道在处理完一个请求后才接收新请求,避免了并发处理可能带来的混乱和错误,提高了系统的可靠性和性能。
好,如何处理发送成功的响应讲解完了,接下来我们来学习一下已经接收完成的请求是如何处理的,对应的方法是processCompletedReceives()。
方法 processCompletedReceives()
以下是该方法的源码和注释:
private def processCompletedReceives(): Unit = {
// 1.遍历所有已接收的Request
selector.completedReceives.forEach { receive =>
try {
// 2.保证对应连接通道已经建立,同时获取KafkaChannel的id。
openOrClosingChannel(receive.source) match {
case Some(channel) =>
//获取header
val header = parseRequestHeader(receive.payload)
if (header.apiKey == ApiKeys.SASL_HANDSHAKE && channel.maybeBeginServerReauthentication(receive,
() => time.nanoseconds()))
trace(s"Begin re-authentication: $channel")
else {
val nowNanos = time.nanoseconds()
// 如果认证会话已过期,则关闭连接
if (channel.serverAuthenticationSessionExpired(nowNanos)) {
debug(s"Disconnecting expired channel: $channel : $header")
close(channel.id)
expiredConnectionsKilledCount.record(null, 1, 0)
} else {
//获取连接id
val connectionId = receive.source
val context = new RequestContext(header, connectionId, channel.socketAddress,
channel.principal, listenerName, securityProtocol,
channel.channelMetadataRegistry.clientInformation)
//3.构建 request 对象:包括按协议解析请求,解析成一个request对象,包括processorId,
//header,body等字段,供Handler使用
val req = new RequestChannel.Request(processor = id, context = context,
startTimeNanos = nowNanos, memoryPool, receive.payload, requestChannel.metrics)
if (header.apiKey == ApiKeys.API_VERSIONS) {
val apiVersionsRequest = req.body[ApiVersionsRequest]
if (apiVersionsRequest.isValid) {
channel.channelMetadataRegistry.registerClientInformation(new ClientInformation(
apiVersionsRequest.data.clientSoftwareName,
apiVersionsRequest.data.clientSoftwareVersion))
}
}
// 4.核心代码:将Request添加到requestQueue队列中,等待处理
requestChannel.sendRequest(req)
//把op_read事件移除掉:已经把这个channel上的 read事件处理了并缓存了request,就要把read事件抹除。
//下一轮再去注册这个事件,目的是什么呢?
/*
为什么 Processor.run()方法内会有多处注册/取消OP_READ事件和OP_Write事件?
因为当Processor把请求放入RequestChannel.requestQueue队列后会有多个的Hander线程去消费,
为了保证顺序性用多处注册/取消OP_READ事件和OP_Write事件保证这一个时间只有一个请求被处理,知道这个请求处理了
才会处理下一个。保证了请求的顺序性。
*/
selector.mute(connectionId)
handleChannelMuteEvent(connectionId, ChannelMuteEvent.REQUEST_RECEIVED)
}
}
case None =>
throw new IllegalStateException(s"Channel ${receive.source} removed from selector before processing completed receive")
}
} catch {
case e: Throwable =>
processChannelException(receive.source, s"Exception while processing request from ${receive.source}", e)
}
}
selector.clearCompletedReceives()
}
第一步,遍历SocketChannel已经接收成功的Request对象。已经接收成功的Request在KSelector的集合completedReceives内。只要遍历这个集合就能够获得已经发送成功的Request对象。
第二步,判断对应连接通道是否已经建立,同时获取KafkaChannel的id。
第三步,构建 request 对象,包括按协议解析请求,解析成一个request对象,包括processorId、header、body等字段,供Handler使用。
第四步,将Request添加到requestQueue队列中,等待处理。Processor接收到Request对象后,并没有进一步处理而是通过调用requestChannel.sendRequest(req)方法把Request对象放入requestChannel对象里的requestQueue队列里等待业务线程处理。(RequestChannel和业务线程相关学习会在下节给你介绍。)
第五步,调用selector.mute(connectionId)把连接上的op_read事件移除掉。这时已经把这个channel上的 read事件处理了并缓存了request,同时再把连接上的op_read事件移除掉就不会有新的请求读进来,这样业务线程池可以先处理这里连接的请求,而不用担心有两个请求同时处理造成顺序不一致。
我再进一步给你解释一下为什么要这么设计。因为当Processor把请求放入RequestChannel.requestQueue队列后会有多个的Hander线程去消费,为了保证顺序性,就用多处注册/取消OP_READ事件和OP_Write事件保证这一个时间只有一个请求被处理,知道这个请求处理了才会处理下一个。
好,Processor类的主要方法介绍完了,现在我们看看作为线程类,run()方法都做了些什么事情。
以下是对processCompletedReceives()方法的分析:
一、整体功能概述
这个方法主要用于处理已经完成接收的请求。它负责从接收缓冲区中提取请求数据,进行解析和进一步的处理操作,以确保客户端的请求能够被正确地处理并作出相应的响应。
二、方法步骤解析
遍历已完成接收的通道
类似于
processCompletedSends()方法中的遍历已发送响应的操作,这里会遍历所有已经完成接收数据的通道。可以通过特定的集合或数据结构来获取这些已完成接收的通道信息。例如,可能会使用类似于selector.completedReceives这样的集合来存储已完成接收的通道对应的接收操作信息。
提取请求数据并解析
对于每个已完成接收的通道,从接收缓冲区中提取请求数据。这可能涉及到从网络缓冲区中读取数据,并根据特定的协议格式进行解析。例如,Kafka 可能使用自定义的二进制协议或者基于文本的协议,需要根据协议规范将接收到的数据解析成可理解的请求对象。
处理请求
根据解析后的请求对象进行具体的处理操作。这可能包括确定请求的类型(如生产者发送消息请求、消费者拉取消息请求等),然后调用相应的处理逻辑。例如,如果是生产者发送消息请求,可能会将消息存储到对应的分区中;如果是消费者拉取消息请求,可能会从分区中读取消息并返回给消费者。
生成响应
根据请求的处理结果生成相应的响应对象。这个响应对象包含了对请求的处理结果信息,例如请求是否成功、返回的数据等。例如,如果请求处理成功,响应对象中可能包含确认信息或者请求的数据;如果请求处理失败,响应对象中可能包含错误码和错误信息。
发送响应
最后,将生成的响应对象发送回客户端。这可能涉及到调用类似
sendResponse()方法来进行响应的发送准备工作,并通过网络通道将响应发送给客户端。确保响应能够准确地传达给客户端,完成整个请求 - 响应的处理流程。
三、重要性和作用
高效的请求处理:确保客户端的请求能够被及时、准确地处理,提高系统的响应速度和吞吐量。通过有序地处理接收的请求,避免了请求的积压和延迟。
协议解析和兼容性:正确地解析客户端发送的请求数据,确保系统能够与不同版本的客户端进行兼容通信。根据协议规范进行解析,保证了数据的准确性和完整性。
业务逻辑实现:通过处理请求并生成相应的响应,实现了系统的核心业务逻辑。根据不同类型的请求进行特定的处理操作,满足了各种业务场景的需求。
系统稳定性和可靠性:及时处理接收的请求并发送响应,有助于提高系统的稳定性和可靠性。避免了客户端因长时间等待响应而出现超时或错误,增强了用户体验。
方法run()
run()方法是一个while(true)的循环,里面执行的内容基本是我上面讲解的方法。源码和注释在下面,我给你一步步讲解一下这个代码过程。
override def run(): Unit = {
// 标识Processor线程启动完成
startupComplete()
try {
while (isRunning) {
try {
// 1.遍历SocketChannel集合
configureNewConnections()
//2.注册写事件,用于发送响应给客户端,同时把要发送的response放入inflightResponses这个临时队列里。
processNewResponses()
poll()// 真正的发送response到客户端。执行NIO poll()方法,获取对应SocketChannel上准备就绪的I/O操作
processCompletedReceives()// 处理KSelector.completedReceives队列,处理成功接收到的请求。将Request放入RequestQueue队列
processCompletedSends()// 处理KSelector.completedSends队列,处理成功发送的响应。对每个Response执行回调逻辑
processDisconnected()// 处理KSelector.disconnected队列,处理发送失败而导致断开的连接。
closeExcessConnections()// 关闭超过配额限制部分的连接
} catch {
case e: Throwable => processException("Processor got uncaught exception.", e)
}
}
} finally {// 关闭底层资源
debug(s"Closing selector - processor $id")
CoreUtils.swallow(closeAll(), this, Level.ERROR)
shutdownComplete()
}
}
第一步,标识Processor线程启动。
第二步,调用方法configureNewConnections()。遍历SocketChannel集合,SocketChannel注册到selector上,然后Selector监听SocketChannel上的OP_READ事件。
第三步,调用方法processNewResponses()。从响应队列里拿出一个response。根据response的类型,做响应的处理。如果response需要发送给客户端,做好发送Response前的准备,并将Response放入到inflightResponses临时队列。
第四步,调用方法poll():这是真正接收请求和发送响应的方法。执行NIO poll()方法,获取对应SocketChannel上准备就绪的I/O操作并执行对应的处理方法。
第五步,调用方法processCompletedReceives():处理收到的请求。具体是轮询KSelector.completedReceives队列,处理成功接收到的请求。将Request放入RequestQueue队列。
第六步,调用processCompletedSends()方法:处理KSelector.completedSends队列。目的是处理成功发送的响应。对每个Response执行回调逻辑。
第七步,调用processDisconnected()方法:从KSelector.disconnected队列获取发送失败而导致断开的连接,然后处理这些连接。
第八步,调用closeExcessConnections()方法。关闭超过配额限制部分的连接。
下面我画了张流程图,简单描述一下run()方法执行流程。
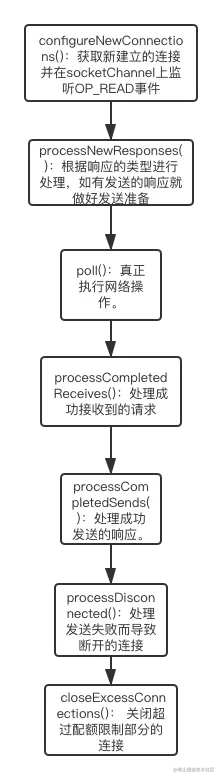
好了,Accept类和Processor类都介绍完了,两者之间的关系我用下面的一张图来简单展示一下,你也可以对照着图回顾下今天的课程。
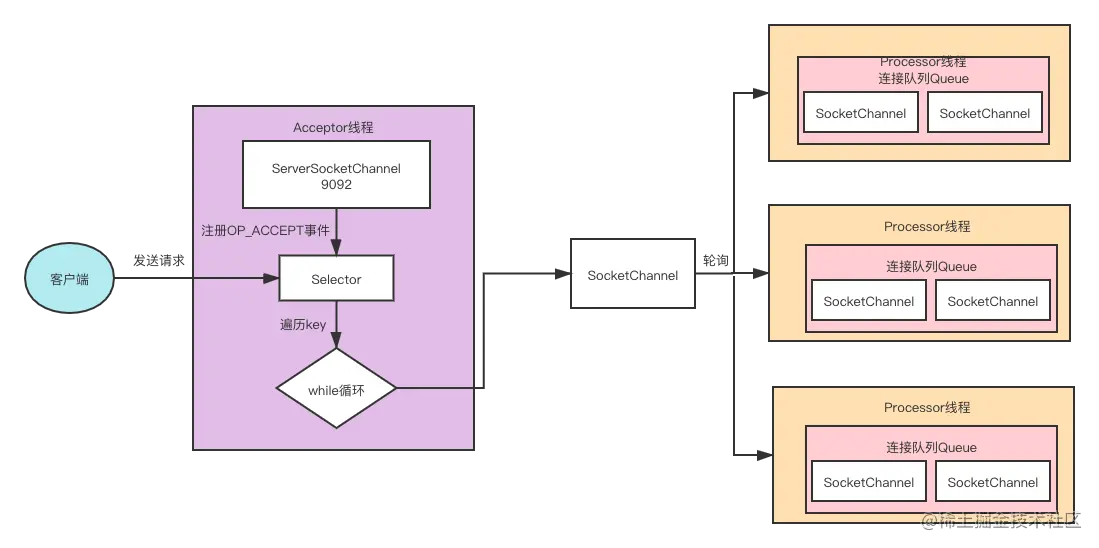
总结
这节我们主要讨论了Acceptor类和Processor类。
首先这两个类都是线程类,都是通过run()方法启动的。
Acceptor类主要负责接收外部的连接请求并建立连接,把建立好的连接交给processor类处理。Processor类主要负责连接中发生的读写事件。run()方法是这两个类的启动方法,Acceptor类的run()方法负责创建连接并把连接给Processor类,注意并不是直接把连接给Processor类处理,而是把连接放入Processor类的一个连接集合里。Processor类的run()方法从连接集合里获取连接,并处理连接发送的读写操作。
Processor类只负责网络读写,那么具体的业务执行是谁做了呢?下一节我将给你详细分析和讲解。
业务执行具体是如何进行的?
请求解析与任务分发
请求解析:当 Processor 类获取到连接并接收到读写请求后,首先会对请求进行解析。Kafka 有自己的请求协议格式,例如,对于生产者发送消息的请求,会解析出消息所属的主题、分区信息(如果有指定)、消息内容等;对于消费者拉取消息的请求,会解析出要拉取的主题、分区、偏移量范围等关键信息。这一过程类似于根据一套 “通信语言” 来理解客户端的意图。
任务分发:解析完请求后,会根据请求类型将任务分发给对应的业务处理模块。例如,将生产者发送消息的任务发送给消息存储模块,将消费者拉取消息的任务发送给消息检索模块。这种分发机制使得不同类型的业务请求能够在合适的模块中得到处理,提高了系统的可维护性和扩展性。
消息存储模块(针对生产者消息发送)
确定目标分区:如果生产者发送消息时没有指定分区,消息存储模块会根据消息的键(Key)通过哈希算法等方式确定消息应该存储到哪个分区。例如,对于一个订单主题的消息,如果消息的键是订单号,系统可以通过对订单号进行哈希计算,将消息分配到特定的分区,确保相同键的消息存储在同一分区,方便后续按顺序处理。
写入消息到分区:确定分区后,消息会被追加到该分区对应的日志文件中。在这个过程中,会记录消息的偏移量,偏移量是用于标记消息在分区中的位置,方便消费者后续拉取消息。同时,系统会维护一些索引结构,以提高消息检索的效率。例如,通过维护时间戳索引,能够快速定位某个时间段内的消息。
副本同步(如果有副本):在消息存储到领导者(Leader)副本分区后,还需要进行副本同步操作。追随者(Follower)副本会定期从领导者副本拉取消息更新自己的存储内容。这个过程通过网络通信进行,并且有相应的机制来确保副本之间的一致性,如检查消息的偏移量是否一致,若出现不一致的情况会进行调整。
消息检索模块(针对消费者消息拉取)
定位消息位置:根据消费者请求中包含的主题、分区和偏移量信息,消息检索模块首先要在存储中定位消息的位置。如果消费者是首次拉取消息,可能从分区的起始偏移量开始;如果是继续拉取,就从上次拉取结束的偏移量开始。利用之前存储的索引结构,可以快速定位到消息所在的物理位置。
读取并返回消息:定位消息后,消息检索模块会从存储中读取指定数量的消息(根据消费者请求的数量),并将这些消息返回给消费者。同时,会更新消费者的偏移量记录,记录消费者已经拉取到的位置,以便下次拉取时从正确的位置开始。在这个过程中,也需要考虑一些异常情况,如消息存储损坏、偏移量错误等,并进行相应的处理,如返回错误信息给消费者。
其他业务相关操作
权限验证:在业务执行过程中,可能还涉及到权限验证的环节。例如,检查生产者是否有向特定主题发送消息的权限,消费者是否有从特定主题拉取消息的权限。这可以通过与权限管理模块进行交互来实现,权限管理模块可以存储主题 - 权限的对应关系,根据连接的客户端信息(如用户名、密码、证书等)来验证权限。
数据转换与过滤(如果有):根据业务需求,可能还需要对消息进行数据转换或过滤。例如,对于某些需要对消息内容进行格式统一的场景,可以在业务执行过程中对消息进行数据转换操作;对于只需要部分消息的消费者,也可以在拉取消息时进行过滤,只返回符合条件的消息。这些操作可以在消息存储模块或消息检索模块中根据具体的业务规则来实现。