13.消费组重平衡(上)
我们开始学习消费组的重平衡。由于消费组重平衡内容比较多,所以我会将内容拆分成上、下两节给你讲解。
这节课我们主要讲解消费组重平衡的前两个步骤,课程大纲如下:
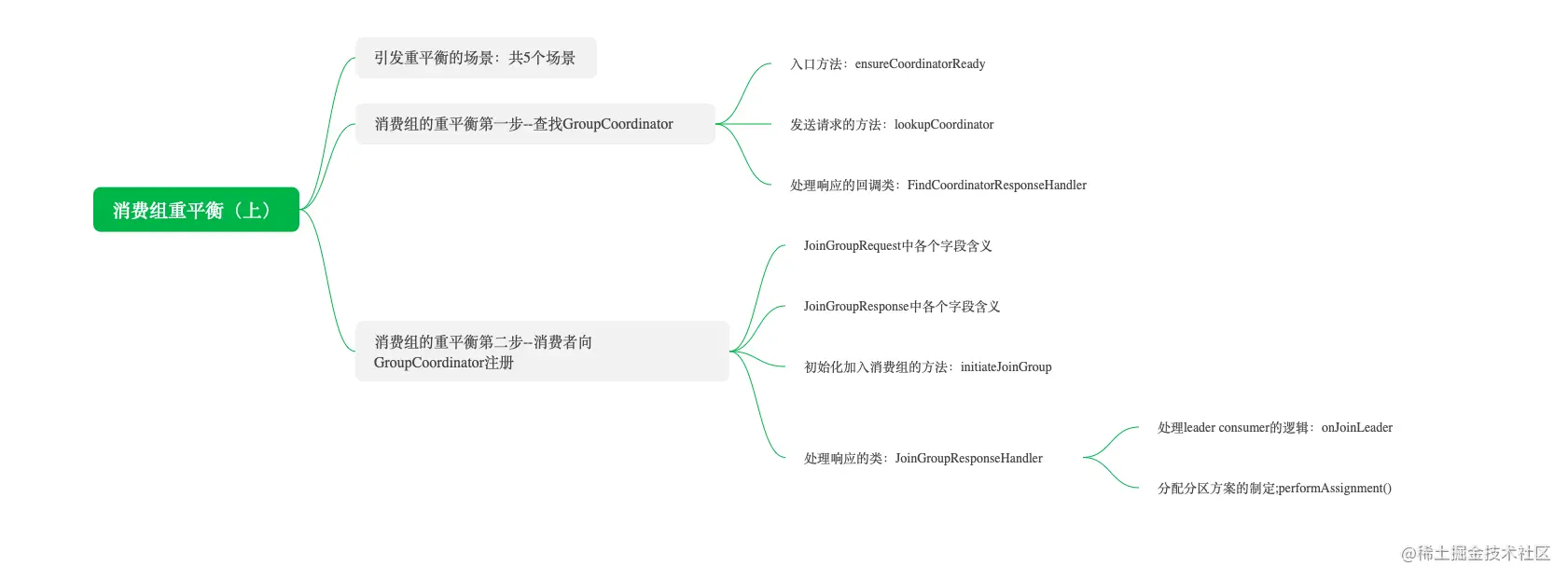
引发重平衡的场景
引发重平衡主要有以下 5 个场景。
有新的消费者加入消费组。
有消费者宕机下线。消费者并不一定需要真正下线,例如遇到长时间的GC、网络迟导致消费者长时间未向 GroupCoordinator 发送心跳等情况时,GroupCoordinator 会认为消费者已经下线。
有消费者主动退出消费组(发送LeaveGroupRequest 请求)。比如,客户端调用子 unsubscrible()方法取消对某些主题的订阅。
消费组所对应的 GroupCoorinator 节点发生了变更。
消费组内所订阅的任一个主题或主题分区数量发生了变化。
消费组的重平衡主要分下面四步。
消费者向集群中任一broker发送获取GroupCoordinator的请求FindCoordinatorRequest,服务端返回GroupCoordinator信息包括GroupCoordinator所在的broker的node_id、host和port信息。
成功找到消费组对应的GroupCoordinator后,消费者进入加入消费组的阶段。消费者会向GroupCoordinator发送JoinGroupRequest请求,GroupCoordinator返回响应告诉消费者是否加入消费组成功了,并选出leader consumer,同时把分区策略和其他消费者的订阅信息发送给leader consumer。
leader consumer根据GroupCoordinator提供的分区策略和所有消费者的订阅信息确定分区消费方案并发送给GroupCoordinator,然后GroupCoordinator根据收到的分区消费方案把每个消费者要消费的分区信息发送给每个消费者。
消费者收到分区消费方案后,向GroupCoordinator所在的broker发送心跳维持从属关系。
消费组重平衡是消息队列中一个非常重要的概念,尤其是在使用像Kafka这样的分布式消息系统时。它涉及到在消费组内的消费者之间重新分配分区的过程,以确保每个消费者负责处理的消息量尽可能均匀,从而提高整个系统的吞咽率和效率。下面我将为你介绍消费组重平衡的基本概念及其工作原理。
什么是消费组?
消费组:一组消费者的逻辑集合,它们共同订阅了相同的一系列主题(topics),并且能够分担这些主题下的数据负载。
每个消费组可以包含一个或多个消费者实例。
同一消费组内不同消费者实例之间不会重复消费同一条消息;但是不同的消费组之间互不影响,可以独立地消费相同的数据流。
为什么需要重平衡?
当以下情况发生时,可能会触发消费组的重平衡:
新增消费者加入到现有消费组。
现有消费者从消费组中离开(比如因为故障)。
订阅的主题列表发生变化。
分区的数量发生变化(虽然这种情况相对少见)。
重平衡过程
发现变化:一旦检测到上述任何一种变化,就会启动重平衡流程。
选举领导者:在所有受影响的消费者中选举出一个协调者来负责此次重平衡的具体实施。通常这一步通过Zookeeper或是Kafka内部机制完成。
分配分区:根据当前活跃的消费者数量以及可用分区数,计算出最优的分区分配方案。目的是让每个消费者都能得到大致相等的工作量。
同步状态:将新的分区分配信息通知给所有的消费者,并等待他们确认收到并准备好开始按照新分配执行。
开始消费:一旦所有相关方都完成了准备工作,就可以依据最新的分配结果开始新一轮的消息消费。
影响因素
网络延迟:在整个过程中,网络状况对性能有很大影响。
消费者能力差异:如果消费者之间的处理能力存在较大差距,则可能会影响整体平衡效果。
分区数量与消费者比例:理想情况下,每个消费者应该至少有一个分区要处理,但过多的消费者相对于较少的分区也会导致资源浪费。
了解了基本概念后,在实际应用中如何优化配置、减少不必要的重平衡次数等都是值得进一步探讨的话题。如果你有兴趣了解更多细节或者是具体案例,请告诉我!
Kafka消费组的重平衡(Rebalance)机制是消费组管理的重要组成部分。当消费组中的消费者发生变化时,Kafka会触发重平衡,以确保分区分配到可用的消费者上。重平衡可以提升消费组的弹性和容错性,但频繁的重平衡也会影响消费的稳定性和性能。
重平衡的触发条件
Kafka会在以下几种情况下触发重平衡:
消费者加入或离开消费组:例如,一个新的消费者加入消费组,或某个消费者因为网络问题或宕机而离开。
订阅的主题发生变化:当消费者的订阅列表发生变动时,重平衡会重新分配分区。
分区变化:当主题的分区数量增加或减少时,会导致重平衡,以重新分配新的分区给消费者。
重平衡的过程
Kafka的重平衡过程通常包括以下几个阶段:
协调器(Coordinator)检测变化:协调器是负责管理消费组的专用服务器节点(通常是消费者的Group Coordinator)。当协调器检测到消费组成员或分区发生变化时,就会启动重平衡。
暂停消费:在重平衡过程中,所有消费者会暂停消息消费,以避免消费同一个分区的数据。
重新分配分区:协调器会根据分配策略(如Range、RoundRobin、Sticky等)为消费者重新分配分区。
同步分区分配:协调器将新的分配方案发送给每个消费者,消费者会更新自己的分区分配情况。
恢复消费:重平衡完成后,消费者恢复消息消费。
分区分配策略
Kafka支持多种分区分配策略:
Range:基于主题的分区范围分配,按照主题顺序和消费者顺序将分区分配给消费者。每个消费者分配到的分区范围可能不均匀,尤其是在分区数量和消费者数量不能整除时。
RoundRobin:按照轮询的方式将所有分区分配给所有消费者。这种方法分配更加均匀。
Sticky:旨在最大限度减少分区的重新分配,尽可能保留上一次的分配结果。
重平衡的代价
虽然重平衡有助于维护消费组的高可用性,但它也有一些代价:
消费中断:在重平衡期间,消费会暂停,导致消息延迟增加。
数据重复或丢失风险:在重平衡过程中,如果未能正确处理提交的偏移量,可能会出现数据重复消费或消息丢失。
解决频繁重平衡的方法
为了解决频繁重平衡问题,可以采用以下方法:
增大session.timeout.ms和heartbeat.interval.ms:适当增加消费者会话超时时间和心跳间隔时间,避免短暂网络抖动导致消费者被踢出消费组。
使用Sticky分区分配策略:尽量减少分区的重新分配,避免无谓的重平衡。
增加消费者的处理能力:提升消费者处理消息的速度,避免由于处理速度较慢导致的Rebalance。
使用自定义分区分配器:根据业务需求实现更适合的分区分配策略。
小结
Kafka的消费组重平衡机制是维护消费组健康和分区分配的核心过程。理解其原理和实现方法有助于优化Kafka的使用,提高消息消费的稳定性和效率。在下一部分中,可以进一步探讨具体的代码实现和Coordinator的工作流程。
引发Kafka消费组重平衡的主要场景包括以下5种情况:
有新的消费者加入消费组 当一个新的消费者加入消费组时,Kafka需要重新分配分区,以便将分区分配给新的消费者,从而均衡地分摊负载。这时会触发重平衡。
有消费者宕机或下线 当消费组中的某个消费者出现宕机或下线时,Kafka会认为该消费者不可用,并启动重平衡过程,将原本分配给该消费者的分区重新分配给其他存活的消费者。 注意,消费者并不一定需要真正下线。例如,在遇到长时间的垃圾回收(GC)或网络延迟导致消费者无法及时向
GroupCoordinator发送心跳时,GroupCoordinator也会认为该消费者已经失联,从而触发重平衡。有消费者主动退出消费组(发送
LeaveGroupRequest请求) 当消费者客户端调用unsubscribe()方法取消对某些主题的订阅,或显式地退出消费组时(通过调用close()或leaveGroup()方法),Kafka会认为该消费者不再参与消费,需要重新调整分区的分配,因而会触发重平衡。消费组所对应的
GroupCoordinator节点发生了变更GroupCoordinator是负责管理消费组的专用Kafka节点。若由于节点故障或负载均衡导致GroupCoordinator发生变更时,消费组的管理会切换到新的GroupCoordinator,这时需要重新进行重平衡以恢复正常的分区分配。消费组内所订阅的任意一个主题或主题的分区数量发生了变化 当消费组订阅的主题有分区数变化时(增加或减少分区数量),Kafka会重新分配这些变化后的分区给消费组内的消费者,从而触发重平衡。例如,新增分区可能需要将这些分区分配给现有消费者,以确保数据的均匀消费。
这些场景下的重平衡机制,虽然能够保证数据分区的可用性和消费的一致性,但频繁重平衡也可能带来消费中断、延迟增加等问题,因此在生产环境中需要尽量优化重平衡的触发频率和重平衡的处理流程。
Kafka的重平衡(Rebalance)机制在消费组中起着关键作用,主要有以下几个用途:
1. 保证分区的高可用性和负载均衡
重平衡的主要作用是将主题的分区均匀分配给消费组中的消费者,从而实现负载均衡。每个消费者都可以消费不同的分区数据,避免某个消费者的工作负载过高或过低。当消费组中消费者的数量发生变化时,重平衡可以重新分配分区,使得每个消费者承担合理的负载。
2. 处理消费者的动态变化
Kafka中的消费者是动态加入和离开的。重平衡机制使消费组能够自动适应这种变化:
新增消费者:当有新的消费者加入消费组时,重平衡会将一些分区分配给新消费者,从而减轻现有消费者的压力。
消费者离开:当消费者宕机、主动退出或者发生故障时,重平衡会将该消费者负责的分区重新分配给其他存活的消费者,确保数据仍然能被正常消费。
3. 保证消费的容错性和数据一致性
在分布式环境中,重平衡有助于容错机制的实现。当某个消费者因故障无法继续消费数据时,重平衡将其负责的分区重新分配给其他消费者,保证消费不中断。同时,Kafka会依赖消费者提交的偏移量,避免因重平衡导致的数据重复或丢失,从而维护数据一致性。
4. 支持分区变化和主题动态调整
当主题的分区数量发生变化(增加或减少)时,Kafka通过重平衡来重新分配分区给消费者,确保所有的分区都能被消费。重平衡能让消费组适应分区数量的动态变化,从而支持系统的扩展性和动态配置。
5. 简化消费组管理
重平衡机制使得消费组的分区管理可以自动化完成,开发者无需手动干预分区的分配和管理。Kafka通过GroupCoordinator和ConsumerCoordinator来管理消费组的成员和分区分配,使消费组的管理变得高效而灵活。
小结
Kafka的重平衡机制在负载均衡、容错处理、动态变化适应和自动化管理方面都有重要作用,确保数据能够高效地被消费,消费组能够应对节点故障或工作负载的变化。然而,频繁的重平衡也会带来消费中断的代价,因此需要合理配置参数和优化重平衡策略。
消费组的重平衡第一阶段:查找 GroupCoordinator
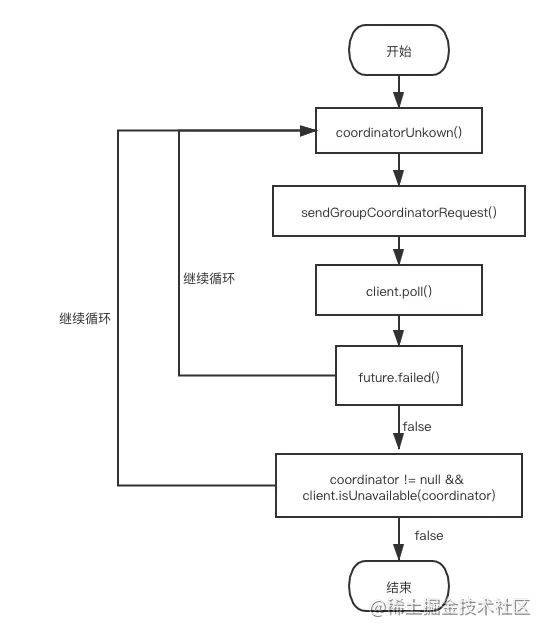
查找GroupCoordinator的入口方法是抽象类AbstractCoordinator的方法,源码如下。
ensureCoordinatorReady()
protected synchronized boolean ensureCoordinatorReady(final Timer timer) {
//1.判断 GroupCoordinator 是否已经存在
if (!coordinatorUnknown())
return true;
do {
if (findCoordinatorException != null && !(findCoordinatorException instanceof RetriableException)) {
final RuntimeException fatalException = findCoordinatorException;
findCoordinatorException = null;
throw fatalException;
}
//2.如果不存在,查找GroupCoordinator的预处理
final RequestFuture<Void> future = lookupCoordinator();
//3.不断请求集群中任一节点直到返回GroupCoordinator的信息
client.poll(future, timer);
//4.判断是否超时
if (!future.isDone()) {
// ran out of time
//说明超时了
break;
}
//4.异常处理
if (future.failed()) {
if (future.isRetriable()) {
log.debug("Coordinator discovery failed, refreshing metadata", future.exception());
client.awaitMetadataUpdate(timer);
} else
throw future.exception();
} else if (coordinator != null && client.isUnavailable(coordinator)) {
markCoordinatorUnknown("coordinator unavailable");
timer.sleep(rebalanceConfig.retryBackoffMs);
}
//5.不断尝试获取GroupCoordinator直到获得GroupCoordinator信息或超时。
} while (coordinatorUnknown() && timer.notExpired());
return !coordinatorUnknown();
}
我分步骤讲解一下。
我分步骤讲解一下。
判断消费者获取的GroupCoordinator是否可用,源码如下:
protected synchronized Node checkAndGetCoordinator() {
//coordinator不为空且消费者与GroupCoordinator连接是否正常。
if (coordinator != null && client.isUnavailable(coordinator)) {
markCoordinatorUnknown(true, "coordinator unavailable");
return null;
}
return this.coordinator;
}
主要是判断字段coordinator是否为空,且消费者与GroupCoordinator连接是否正常。
如果不存在,查找GroupCoordinator的请求预发送方法lookupCoordinator()。这个方法是把请求放入NetworkClient的send缓存字段,等待真正的网络发送
调用ConsumerNetworkClient的poll()方法,同时传入future和定时器,调用的方法如下:
public boolean poll(RequestFuture<?> future, Timer timer) {
do {
poll(timer, future);
} while (!future.isDone() && timer.notExpired());
return future.isDone();
}
ConsumerNetworkClient会不断调用底层组件NetworkClient把FindCoordinatorRequest请求发送出去,直到发送成功或超时。
判断异步请求失败,如果失败就根据失败的原因做以下处理:
有异常,如果是future.isRetriable()异常意味着可以重试。处理方式是等待更新元数据后再次发起请求。否则就抛出异常。
coordinator不为null,说明获得了GroupCoordinator,但是网络连接有问题,那么则等待一段时间后元数据更新了再重试。
判断是否超时,如果超时就跳出循环。
下图更形象地解释了消费者发送获取GroupCoordinator的过程步骤:
这里,我们重点学习一下查找GroupCoordinator的预处理方法lookupCoordinator()。
发送请求 lookupCoordinator()
//寻找GroupCoordinator
protected synchronized RequestFuture<Void> lookupCoordinator() {
if (findCoordinatorFuture == null) {
// find a node to ask about the coordinator
//1.找到负载最小的node
Node node = this.client.leastLoadedNode();
if (node == null) {
log.debug("No broker available to send FindCoordinator request");
return RequestFuture.noBrokersAvailable();
} else {
//2.向node预发送查找GroupCoordinator的请求,
findCoordinatorFuture = sendFindCoordinatorRequest(node);
// remember the exception even after the future is cleared so that
// it can still be thrown by the ensureCoordinatorReady caller
//3.向RequestFuture<Void>添加监听器。
findCoordinatorFuture.addListener(new RequestFutureListener<Void>() {
@Override
public void onSuccess(Void value) {} // do nothing
@Override
public void onFailure(RuntimeException e) {
findCoordinatorException = e;
}
});
}
}
return findCoordinatorFuture;
}
我给你讲解下这个方法的步骤。
找到负载最小的节点。所有的集群节点都保存着集群元数据,我们只要选择一个负载最小的节点获取GroupCoordinator就好。
向找到的node预发送查找GroupCoordinator的请求。
private RequestFuture<Void> sendFindCoordinatorRequest(Node node) {
// initiate the group metadata request
log.debug("Sending FindCoordinator request to broker {}", node);
//1.构建查找Group Coordinator节点的请求
FindCoordinatorRequest.Builder requestBuilder =
new FindCoordinatorRequest.Builder(
new FindCoordinatorRequestData()
.setKeyType(CoordinatorType.GROUP.id())
.setKey(this.rebalanceConfig.groupId));
//2.发送请求,并用FindCoordinatorResponseHandler类对象来处理响应
return client.send(node, requestBuilder)
.compose(new FindCoordinatorResponseHandler());
}
构建获取GroupCoordinator的请求FindCoordinatorRequest,请求结构体格式如下:
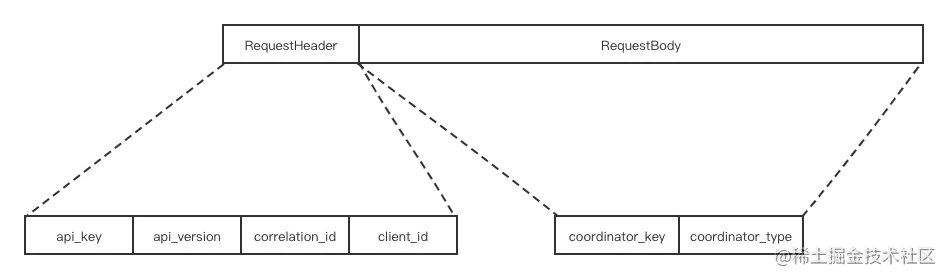
预发送FindCoordinatorRequest请求,把FindCoordinatorRequest放入底层组件NetworkClient的send字段里。而且当消费者收到响应后,通过RequestFuture的compose()方法设置FindCoordinatorResponseHandler的类对象进行处理。
好,我们下面再介绍一下处理响应的类 FindCoordinatorResponseHandler。
处理响应 FindCoordinatorResponseHandler
private class FindCoordinatorResponseHandler extends RequestFutureAdapter<ClientResponse, Void> {
@Override
public void onSuccess(ClientResponse resp, RequestFuture<Void> future) {
log.debug("Received FindCoordinator response {}", resp);
clearFindCoordinatorFuture();
//1.得到找到Group Coordinator 节点的响应
FindCoordinatorResponse findCoordinatorResponse = (FindCoordinatorResponse) resp.responseBody();
Errors error = findCoordinatorResponse.error();
if (error == Errors.NONE) {
synchronized (AbstractCoordinator.this) {
// use MAX_VALUE - node.id as the coordinator id to allow separate connections
// for the coordinator in the underlying network client layer
int coordinatorConnectionId = Integer.MAX_VALUE - findCoordinatorResponse.data().nodeId();
//2. 构建Group Coordinator对象
AbstractCoordinator.this.coordinator = new Node(
coordinatorConnectionId,
findCoordinatorResponse.data().host(),
findCoordinatorResponse.data().port());
log.info("Discovered group coordinator {}", coordinator);
//3.尝试与Group Coordinator所在节点连接
client.tryConnect(coordinator);
heartbeat.resetSessionTimeout();
}
//4.调用RequestFuture<Void>上的监听器
future.complete(null);
} else if (error == Errors.GROUP_AUTHORIZATION_FAILED) {
future.raise(GroupAuthorizationException.forGroupId(rebalanceConfig.groupId));
} else {
log.debug("Group coordinator lookup failed: {}", findCoordinatorResponse.data().errorMessage());
future.raise(error);
}
}
@Override
public void onFailure(RuntimeException e, RequestFuture<Void> future) {
clearFindCoordinatorFuture();
super.onFailure(e, future);
}
}
如果成功获得响应的处理过程如下:
得到找到 Group Coordinator 节点的响应并解析。
如果没有异常就根据响应构建coordinator字段。
尝试与GroupCoordinator的节点连接。
调用
RequestFuture<Void>上的监听器,完成响应事件的传播。
在Kafka消费组的重平衡过程中,第一阶段是查找GroupCoordinator。这个步骤非常重要,因为GroupCoordinator负责管理消费组的成员关系和分区分配。消费者需要先找到GroupCoordinator,然后才能加入消费组、发送心跳以及协调重平衡过程。
什么是GroupCoordinator?
GroupCoordinator是Kafka集群中的一个特定角色,它负责消费组的管理,包括:
追踪消费组的成员状态
维护分区和消费者的对应关系
触发和协调消费组的重平衡
GroupCoordinator通常由一个Kafka broker来担任,且每个消费组都有唯一的GroupCoordinator。
查找GroupCoordinator的过程
发送
FindCoordinatorRequest请求: 消费者首先会向Kafka集群发送一个FindCoordinatorRequest请求,该请求的目的是寻找指定消费组的GroupCoordinator。请求中包含消费组的名称,Kafka使用这个名称来确定哪个broker是该消费组的GroupCoordinator。Kafka集群返回
FindCoordinatorResponse响应: 集群中的任意broker接收到FindCoordinatorRequest请求后,会查找指定消费组的GroupCoordinator,然后返回FindCoordinatorResponse响应,其中包含GroupCoordinator的broker信息(如主机地址和端口)。消费者连接到
GroupCoordinator: 一旦消费者获取到GroupCoordinator的地址信息,就会与该GroupCoordinator节点建立连接。这之后,消费者可以向GroupCoordinator发送JoinGroup请求,正式加入消费组。
GroupCoordinator的选择机制
GroupCoordinator的选择机制是基于哈希算法来确定的:
Kafka使用消费组的名称进行哈希计算,得到哈希值后,通过对集群中broker数量取模来确定
GroupCoordinator所在的broker。这个算法可以保证相同的消费组总是由同一个
GroupCoordinator进行管理。
查找GroupCoordinator失败的处理
如果查找GroupCoordinator失败(例如,目标broker不可用或消费组不存在),消费者会进行重试,直到成功找到GroupCoordinator或达到重试次数的上限。此外,如果GroupCoordinator发生变更,消费者也会重新查找新的GroupCoordinator,以确保消费组的稳定性。
小结
查找GroupCoordinator是消费组重平衡的第一步,只有成功找到GroupCoordinator,消费者才能参与到消费组的成员管理和分区分配中去。这一步为后续的重平衡阶段奠定了基础。
在Kafka中,消费组的重平衡过程分为多个阶段,其中第一阶段是查找GroupCoordinator。GroupCoordinator是负责管理消费组的Kafka节点,重平衡的所有操作都依赖于它的协调。下面是这一阶段的详细流程:
1. 消费者连接到Kafka集群
当消费者启动时,它首先需要连接到Kafka集群。为了找到GroupCoordinator,消费者会向集群中的任意一个Broker发送请求。
2. 获取GroupCoordinator
消费者发送FindCoordinator请求来查找特定消费组的GroupCoordinator。这个请求包含消费组的ID。
请求内容:消费者需要在请求中提供消费组的ID,以便Kafka能够找到相应的协调器。
Broker响应:Kafka的某个Broker会作为协调器响应请求,并返回相应的
GroupCoordinator的地址。
3. 建立与GroupCoordinator的连接
一旦消费者知道了GroupCoordinator的地址,它会建立与该节点的连接。这个连接用于后续的重平衡操作,包括心跳检测、分区分配和提交偏移量等。
4. 处理协调器响应
消费者在获取到GroupCoordinator的地址后,会进行以下操作:
更新本地状态:消费者更新自己的状态,记录当前的
GroupCoordinator信息。发起心跳请求:消费者会定期向
GroupCoordinator发送心跳请求,以保持其在消费组中的活跃状态,防止被认为下线。
5. 异常处理
如果在查找GroupCoordinator的过程中发生异常,例如找不到对应的协调器或连接失败,消费者会采取以下措施:
重试机制:消费者会设置重试机制,定期重试获取
GroupCoordinator。日志记录:在出现异常时,消费者应该记录相关错误日志,以便后续的排查和优化。
小结
查找GroupCoordinator是消费组重平衡的第一阶段,消费者通过发送FindCoordinator请求获取到负责该消费组的协调器。之后,消费者与GroupCoordinator建立连接,进行后续的重平衡操作。这一阶段的成功与否直接影响到重平衡的整体流程和效率,因此合理配置消费者的重试机制和心跳机制对于提高系统的健壮性至关重要。
好了,到这里第一阶段的内容就讲解完了,下面开始第二阶段的讲解。
消费组的重平衡第二阶段:消费者向 GroupCoordinator 注册
在成功找到对应的GroupCoordinator之后,进入了向GroupCoordinator注册阶段。这个阶段,消费者会向GroupCoordinator发送JoinGroupRequest请求,并处理响应。
请求结构体格式如下:
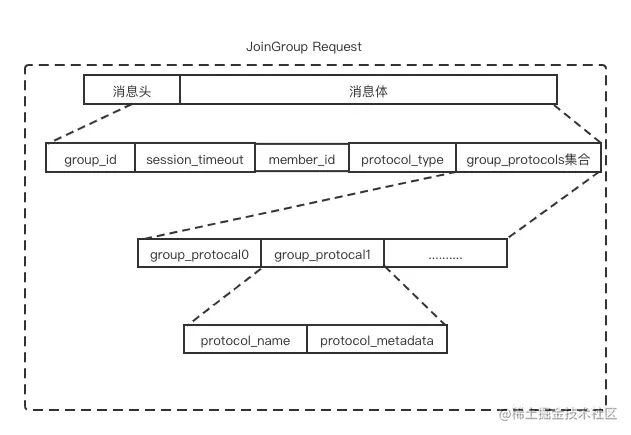
JoinGroupRequest 中各个字段含义如下表所示:
响应结构体格式如下:
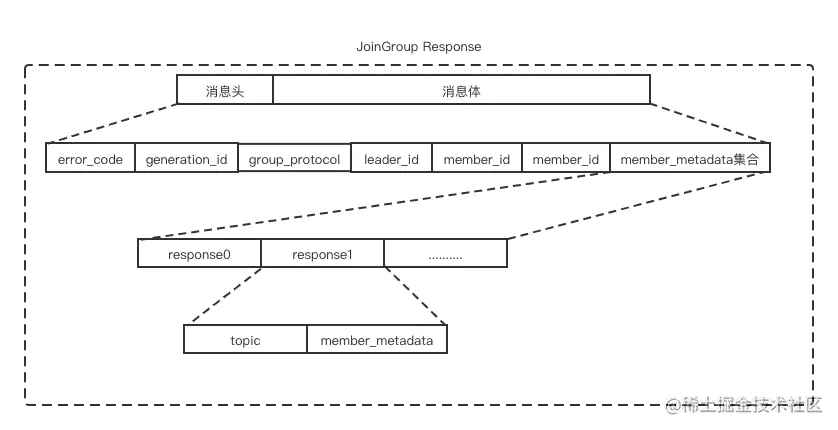
JoinGroupResponse 中各个字段含义如下表所示:
抽象类AbstractCoordinator的joinGroupIfNeeded()方法是入口方法。源码如下:
boolean joinGroupIfNeeded(final Timer timer) {
while (rejoinNeededOrPending()) {
//1.再一次检查是否获得了groupCoordinator
if (!ensureCoordinatorReady(timer)) {
return false;
}
//2.加入组之前的准备工作。
if (needsJoinPrepare) {
needsJoinPrepare = false;
onJoinPrepare(generation.generationId, generation.memberId);
}
//3.发送注册到Group Coordinator里的JoinGroup请求前的工作,
final RequestFuture<ByteBuffer> future = initiateJoinGroup();
//4.网络阻塞发送
client.poll(future, timer);
if (!future.isDone()) {
// we ran out of time
return false;
}
......忽略
简单给你讲讲这个方法的步骤。
再一次检查是否获得了groupCoordinator。目的是担心与groupCoordinator的连接出问题,这样方法能及时再获取一次groupCoordinator。
加入组之前的准备工作。准备工作包括:
如果是自动提交offset,则提交offset。目的是防止已经消费的partition的offset由于换了消费者造成重复消费消息。
调用注册在SubscriptionState中的ConsumerRebalanceListener上的回调方法。
初始化加入消费组。包括构建JoinGroupRequest请求,预发送JoinGroupRequest请求,异步请求上加监听器。
网络阻塞发送。
初始化加入消费组 initiateJoinGroup()
private synchronized RequestFuture<ByteBuffer> initiateJoinGroup() {
if (joinFuture == null) {
//1.设置consumer的状态为预重平衡
state = MemberState.PREPARING_REBALANCE;
if (lastRebalanceStartMs == -1L)
lastRebalanceStartMs = time.milliseconds();
//2.做发送JoinGroupRequest请求的准备工作。
joinFuture = sendJoinGroupRequest();
//3.给异步请求加监听器
joinFuture.addListener(new RequestFutureListener<ByteBuffer>() {
@Override
public void onSuccess(ByteBuffer value) {
}
@Override
public void onFailure(RuntimeException e) {
synchronized (AbstractCoordinator.this) {
sensors.failedRebalanceSensor.record();
}
}
});
}
return joinFuture;
}
第一步,设置消费者的状态为PREPARING_REBALANCE,表示准备重平衡了。
第二步,做发送JoinGroupRequest请求的准备工作。
第三步,给异步请求加监听器,对应失败会做异常处理。对于成功没做任何事,因为发送JoinGroupRequest请求的准备工作的回调对象会完成回调处理。
这里,我们还需要重点说说做发送JoinGroupRequest请求的准备工作 sendJoinGroupRequest() 方法的代码。
RequestFuture<ByteBuffer> sendJoinGroupRequest() {
if (coordinatorUnknown())
return RequestFuture.coordinatorNotAvailable();
log.info("(Re-)joining group");
//1.构建加入Group Coordinator的请求
JoinGroupRequest.Builder requestBuilder = new JoinGroupRequest.Builder(
new JoinGroupRequestData()
.setGroupId(rebalanceConfig.groupId)
.setSessionTimeoutMs(this.rebalanceConfig.sessionTimeoutMs)
.setMemberId(this.generation.memberId)
.setGroupInstanceId(this.rebalanceConfig.groupInstanceId.orElse(null))
.setProtocolType(protocolType())
.setProtocols(metadata())
.setRebalanceTimeoutMs(this.rebalanceConfig.rebalanceTimeoutMs)
);
log.debug("Sending JoinGroup ({}) to coordinator {}", requestBuilder, this.coordinator);
int joinGroupTimeoutMs = Math.max(client.defaultRequestTimeoutMs(),
rebalanceConfig.rebalanceTimeoutMs + JOIN_GROUP_TIMEOUT_LAPSE);
//2.发送请求,并设置处理ClientResponse的对象JoinGroupResponseHandler
return client.send(coordinator, requestBuilder, joinGroupTimeoutMs)
.compose(new JoinGroupResponseHandler(generation));
}
第一步,构造JoinGroupRequest请求。
第二步,预发送请求,并通过给RequestFuture.compose()方法配置回调对象的方式增加监听器。
到这里发送的源码就分析完成了,我们再来看一下用来处理响应的类JoinGroupResponseHandler。
处理响应的类 JoinGroupResponseHandler
我们重点学习 handle()方法:
public void handle(JoinGroupResponse joinResponse, RequestFuture<ByteBuffer> future) {
......忽略
synchronized (AbstractCoordinator.this) {
//1.解析joinResponse
if (state != MemberState.PREPARING_REBALANCE) {
future.raise(new UnjoinedGroupException());
} else {
//2.更新状态为正在执行重平衡
state = MemberState.COMPLETING_REBALANCE;
if (heartbeatThread != null)
heartbeatThread.enable();
AbstractCoordinator.this.generation = new Generation(
joinResponse.data().generationId(),
joinResponse.data().memberId(), joinResponse.data().protocolName());
log.info("Successfully joined group with generation {}", AbstractCoordinator.this.generation);
//3.判断是否为leader
if (joinResponse.isLeader()) {
onJoinLeader(joinResponse).chain(future);
} else {
onJoinFollower().chain(future);
}
}
}
}
} else if (error == Errors.COORDINATOR_LOAD_IN_PROGRESS) {
......忽略
}
第一步,解析joinResponse。
第二步,更新状态为正在执行重平衡。
第三步,根据响应判断这个消费者是否被选为消费组的leader,如果是leader就走onJoinLeader()的逻辑,否则如果是follower就走onJoinFollower()的逻辑。如果是leader consumer会收到消费组所有消费者的订阅信息已经GroupCoordinator选择好的分区策略,而follower consumer不会收到,所以follower consumer不会有太多的逻辑。
我们重点研究onJoinLeader()的逻辑。
onJoinLeader() 相关源码如下:
private RequestFuture<ByteBuffer> onJoinLeader(JoinGroupResponse joinResponse) {
try {
//1.基于响应返回的分区策略和消费组里所有消费者的元数据计算出分区方案。
Map<String, ByteBuffer> groupAssignment = performAssignment(joinResponse.data().leader(), joinResponse.data().protocolName(),
joinResponse.data().members());
List<SyncGroupRequestData.SyncGroupRequestAssignment> groupAssignmentList = new ArrayList<>();
for (Map.Entry<String, ByteBuffer> assignment : groupAssignment.entrySet()) {
groupAssignmentList.add(new SyncGroupRequestData.SyncGroupRequestAssignment()
.setMemberId(assignment.getKey())
.setAssignment(Utils.toArray(assignment.getValue()))
);
}
//2.构建发送分区消费方案的请求
SyncGroupRequest.Builder requestBuilder =
new SyncGroupRequest.Builder(
new SyncGroupRequestData()
.setGroupId(rebalanceConfig.groupId)
.setMemberId(generation.memberId)
.setProtocolType(protocolType())
.setProtocolName(generation.protocolName)
.setGroupInstanceId(this.rebalanceConfig.groupInstanceId.orElse(null))
.setGenerationId(generation.generationId)
.setAssignments(groupAssignmentList)
);
log.debug("Sending leader SyncGroup to coordinator {} at generation {}: {}", this.coordinator, this.generation, requestBuilder);
//3.发送分区消费方案的请求
return sendSyncGroupRequest(requestBuilder);
} catch (RuntimeException e) {
return RequestFuture.failure(e);
}
}
第一步,基于响应返回的分区策略和消费组里所有消费者的元数据计算出分区方案。
第二步,构建向GroupCoordinator发送分区消费方案的请求SyncGroupRequest。
第三步,向GroupCoordinator发送分区方案。
我们再重点关注下分区方案的制定,方法performAssignment():
protected Map<String, ByteBuffer> performAssignment(String leaderId,
String assignmentStrategy,
List<JoinGroupResponseData.JoinGroupResponseMember> allSubscriptions) {
//1.根据GroupCoordinator选出的分区策略名称查找分区策略。
ConsumerPartitionAssignor assignor = lookupAssignor(assignmentStrategy);
if (assignor == null)
throw new IllegalStateException("Coordinator selected invalid assignment protocol: " + assignmentStrategy);
Set<String> allSubscribedTopics = new HashSet<>();
Map<String, Subscription> subscriptions = new HashMap<>();
Map<String, List<TopicPartition>> ownedPartitions = new HashMap<>();
//2.收集消费组中全部消费组的订阅,订阅的主题,消费者和订阅分区的关系集合。
for (JoinGroupResponseData.JoinGroupResponseMember memberSubscription : allSubscriptions) {
Subscription subscription = ConsumerProtocol.deserializeSubscription(ByteBuffer.wrap(memberSubscription.metadata()));
subscription.setGroupInstanceId(Optional.ofNullable(memberSubscription.groupInstanceId()));
subscriptions.put(memberSubscription.memberId(), subscription);
allSubscribedTopics.addAll(subscription.topics());
ownedPartitions.put(memberSubscription.memberId(), subscription.ownedPartitions());
}
// 3.作为leader要开始关注任何消费组订阅主题的变化,确保能及时获取这些主题相关的元数据
updateGroupSubscription(allSubscribedTopics);
isLeader = true;
log.debug("Performing assignment using strategy {} with subscriptions {}", assignor.name(), subscriptions);
// 4.开始分区分配
Map<String, Assignment> assignments = assignor.assign(metadata.fetch(), new GroupSubscription(subscriptions)).groupAssignment();
if (protocol == RebalanceProtocol.COOPERATIVE) {
validateCooperativeAssignment(ownedPartitions, assignments);
}
......忽略
//5.分区结果序列化并保存在groupAssignment map集合里
Map<String, ByteBuffer> groupAssignment = new HashMap<>();
for (Map.Entry<String, Assignment> assignmentEntry : assignments.entrySet()) {
ByteBuffer buffer =
//序列化 ConsumerProtocol.serializeAssignment(assignmentEntry.getValue());
groupAssignment.put(assignmentEntry.getKey(), buffer);
}
return groupAssignment;
}
leader consumer根据GroupCoordinator选出的分区策略名称查找分区策略。因为GroupCoordinator是在所有消费者都有的分区策略中选出的一个分区策略,所以leader consumer本地也肯定有这个策略。
收集消费组中全部消费组的订阅、订阅的主题、消费者和订阅分区的关系集合,为制定分区消费方案做数据准备。
leader consumer扩充订阅信息并获取消费组中所有要消费的主题相关的元数据。因为leader consumer是要给所有消费者分配分区消费的,主题是基础数据之一。跟获取元数据的步骤一样,会发生请求的阻塞。
调用assignor.assign(),根据基础数据获取每个消费者对应的分区消费方案。
分区结果序列化并保存在groupAssignment map里,为发送给GroupCoordinator做准备。
下图是处理响应JoinGroupResponse的步骤,你可以梳理一下:
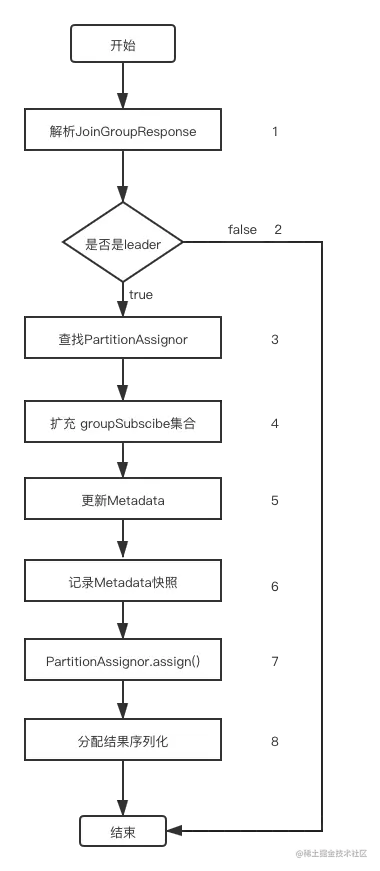
总结
今天这节课我给你讲解了引起消费组重平衡的 5 个场景,并且还重点剖析了消费组重平衡的前两个步骤。
第一个步骤查找 GroupCoordinator。过程简单来说就是消费者往负载最小的node节点发送请求得到GroupCoordinator的地址,然后消费者尝试跟这个节点建立网络连接。核心方法和类包括发送请求的lookupCoordinator()方法和处理响应的FindCoodinatorResponseHandle回调类。
第二个步骤是消费者向注册 GroupCoordinator。消费者把member_id和支持的分区策略发送给GroupCoordinator,GroupCoordinator收到后会选出一个消费者作为consumer leader,同时会选出一个所有消费者都支持的分区策略,然后把选出的分区策略和消费组里的所有消费者的订阅发送给consumer leader,consumer leader收到响应后,先获取消费组订阅的所有主题的元数据,然后根据元数据数据和响应的数据给所有的消费者分配要消费的分区。
你的总结基本涵盖了重平衡的前两个步骤的核心流程。为了更详细地说明每个步骤的作用和涉及的核心类或方法,我将进一步补充和解释。
1. 查找 GroupCoordinator
目的:找到负责管理指定消费组的
GroupCoordinator节点。GroupCoordinator是Kafka集群中某个Broker上的组件,负责消费组的协调和管理工作,包括分区的分配和心跳检测。过程:
消费者启动后会通过
lookupCoordinator()方法向集群中负载最小的节点(Node)发送FindCoordinatorRequest请求,来查找指定消费组的GroupCoordinator。当
FindCoordinatorRequest请求发送后,Kafka会根据消费组的ID(哈希分布)确定哪台Broker应该成为GroupCoordinator。消费者接收到
FindCoordinatorResponse响应后,会通过FindCoordinatorResponseHandler回调方法处理响应,获取到GroupCoordinator的地址。消费者随后会尝试与
GroupCoordinator节点建立网络连接,以便进行后续的交互。
核心类和方法:
ConsumerNetworkClient.lookupCoordinator():用于发送FindCoordinatorRequest请求。FindCoordinatorResponseHandler:用于处理FindCoordinatorResponse响应,获取GroupCoordinator的地址。
2. 消费者向GroupCoordinator注册
目的:注册消费者到消费组,让
GroupCoordinator知道该消费者的存在,并准备进行分区分配。过程:
消费者通过发送
JoinGroupRequest请求向GroupCoordinator注册。请求中包含消费者的member_id(初次为空,由GroupCoordinator分配)和支持的分区分配策略(例如RangeAssignor、RoundRobinAssignor等)。GroupCoordinator收到JoinGroupRequest后,会将该消费者加入消费组的成员列表,并检查所有消费者的支持的分区分配策略,从中选出一个所有消费者都支持的策略。GroupCoordinator会选出一个消费者作为consumer leader,并在响应中通知它成为Leader的角色。Leader消费者的任务是负责执行分区分配算法。GroupCoordinator会将消费组内所有消费者的订阅信息和选出的分区分配策略发送给consumer leader,以便其进行分区分配。consumer leader接收到JoinGroupResponse响应后,会首先获取消费组中所有订阅的主题的元数据(如主题的分区数量),然后根据元数据和从响应中得到的消费者订阅信息进行分区分配。
核心类和方法:
AbstractCoordinator.sendJoinGroupRequest():用于发送JoinGroupRequest请求,向GroupCoordinator注册。JoinGroupResponseHandler:用于处理JoinGroupResponse响应,包括consumer leader的选举和分区分配策略的选择。ConsumerPartitionAssignor.assign():实现分区分配逻辑的策略类。
小结
重平衡的前两个步骤为后续的分区分配奠定了基础。第一步查找GroupCoordinator确保消费者找到负责管理消费组的Broker,而第二步消费者向GroupCoordinator注册则使得所有消费者能被识别并加入消费组。这两个步骤的顺利完成确保消费组可以进行分区的均衡分配和协调管理。
Kafka消费组的重平衡第二阶段是消费者向GroupCoordinator进行注册。这一阶段的目的是让GroupCoordinator知道哪些消费者属于当前消费组,并准备后续的分区分配。以下是这一阶段的详细流程:
1. 发送JoinGroup请求
当消费者成功找到GroupCoordinator后,下一步就是向GroupCoordinator发送JoinGroup请求。这个请求的作用是让消费者向消费组注册,以表明自己是这个消费组的成员。
请求内容:
JoinGroup请求中包含消费组ID、消费者的成员ID(初始为空,由GroupCoordinator分配)、消费者订阅的主题列表等信息。新加入的消费者:如果是新加入的消费者,成员ID会为空。
GroupCoordinator会为该消费者分配一个新的成员ID。
2. GroupCoordinator的响应处理
在收到消费者的JoinGroup请求后,GroupCoordinator会执行以下操作:
更新消费组成员信息:
GroupCoordinator会将该消费者加入到消费组的成员列表中。检查消费组的当前状态:如果消费组处于"空闲"状态,
GroupCoordinator会将状态切换为"正在重平衡"。等待其他消费者的
JoinGroup请求:GroupCoordinator会等待一段时间(由配置参数rebalance.timeout.ms控制),以接收消费组中所有消费者的JoinGroup请求。
3. 选举组的Leader
一旦所有消费者都发送了JoinGroup请求,GroupCoordinator会从消费组成员中选举一个Leader消费者。Leader消费者的任务是负责执行分区分配策略,并将分配方案提交给GroupCoordinator。
Leader消费者:
GroupCoordinator会在JoinGroup的响应中告知哪个消费者是Leader,并返回所有消费者的成员信息和订阅的主题。非Leader消费者:对于其他非Leader的消费者,
JoinGroup的响应只包含其分配到的成员ID。
4. 异常和重试机制
在向GroupCoordinator注册的过程中,可能会出现以下异常情况:
组的重平衡超时:如果
JoinGroup请求在rebalance.timeout.ms内没有完成,消费者会被踢出消费组,需要重新注册。注册失败或被拒绝:如果消费者注册失败或被拒绝,客户端会重试发送
JoinGroup请求,直到成功或达到重试次数上限。
5. 成功注册后的状态更新
当消费者成功完成注册并接收到JoinGroup响应后,消费组进入下一个重平衡阶段(即分区分配阶段)。此时,消费者的状态更新为"已注册",并准备接收分区分配结果。
小结
消费者向GroupCoordinator注册是消费组重平衡的关键步骤,确保所有消费者能够加入消费组并进行分区分配。此阶段还包括Leader的选举,用于后续的分区分配工作。这一阶段的顺利完成为分区的均衡分配和消费组的稳定运行奠定了基础。
触发Kafka消费组重平衡的主要场景。
让我们更详细地了解一下这些情况:
有新的消费者加入消费组:
当一个新的消费者实例加入现有的消费组时,为了保证消息处理的均衡性,需要重新分配分区给所有的消费者(包括新加入的)。这样可以确保每个消费者都能公平地分担工作负荷。
有消费者宕机下线:
如果某个消费者由于故障或其他原因无法继续参与消息消费,则它之前负责的分区将被重新分配给剩余活跃的消费者。这里需要注意的是,并非一定要物理意义上的“宕机”,比如长时间GC、网络问题导致的心跳超时等也会被视为暂时或永久离线。
消费者主动退出消费组:
有时应用程序可能会选择从当前消费组中退出,这可能是出于维护目的或者是调整订阅的主题列表等原因。当发生这种情况时,同样需要进行一次重平衡来重新分配剩下的消费者之间的工作负载。
消费组对应的GroupCoordinator节点发生变化:
Kafka集群中的每个broker都可以担任GroupCoordinator的角色,负责管理特定消费组的状态信息及协调重平衡过程。如果因为某些原因导致原本负责某消费组的GroupCoordinator不再可用,则会选举出新的GroupCoordinator接管该职责,在此过程中也需要执行重平衡以保持一致性。
订阅的主题或主题分区数量变化:
当消费组订阅的新主题被添加进来或者已有主题增加了新的分区时,也需要通过重平衡来让现有消费者能够访问到新增加的数据源;反之亦然,如果有主题被取消订阅或分区减少,则可能需要减少部分消费者的任务量。
综上所述,这些都是比较常见的触发Kafka消费组重平衡的情形。值得注意的是,频繁的重平衡操作会对系统性能造成负面影响,因此在设计和实现时应尽量避免不必要的重平衡发生。例如,可以通过合理设置心跳间隔时间、优化消费者代码逻辑等方式来降低因短暂网络波动等因素引起的不必要重平衡频率。
14.消费组重平衡(下)
在讨论了消费组重平衡的基本概念、触发场景之后,接下来我们深入探讨一下消费组重平衡的具体机制以及如何优化这一过程。
消费组重平衡的机制
1. 协调者(Coordinator)的角色
选举:当一个消费组需要进行重平衡时,Kafka会从集群中选出一个broker作为该消费组的协调者。
心跳监测:协调者负责监控消费者的心跳。如果某个消费者在一定时间内没有发送心跳,则被认为已经下线。
分配策略:根据当前活跃的消费者和可用分区的情况,协调者将使用一种分配算法来决定新的分区分配方案。常用的分配算法包括Range Assignment和RoundRobin Assignment。
2. 分配策略
Range Assignment:按照字典顺序对主题的分区进行排序,然后将这些分区均匀地分配给消费者。这种分配方式简单直接,但在某些情况下可能导致负载不均。
RoundRobin Assignment:采用轮询的方式分配分区给消费者,这样可以确保每个消费者都能获得大致相等数量的分区。这种方法更适用于需要均衡处理能力的情况。
3. 重平衡的过程
准备阶段:所有消费者向协调者发送JoinGroup请求,并等待成为领导者或成员。
选举阶段:协调者选择一个消费者作为领导者,负责计算出新的分区分配方案。
同步阶段:领导者计算出分配方案后,通过SyncGroup请求将其分发给其他消费者。
完成阶段:所有消费者确认接受新的分配方案,并开始按照新方案消费消息。
优化消费组重平衡
为了减少不必要的重平衡次数并提高系统的稳定性与性能,可以采取以下措施:
合理设置session.timeout.ms:这个参数定义了一个消费者被认为是失效的时间间隔。设置得太短可能会导致频繁的假阳性重平衡;太长则可能延迟检测到真正的失败。
适当配置heartbeat.interval.ms:这是消费者向协调者发送心跳的频率。应该小于session.timeout.ms的一半,以确保即使在网络不稳定的情况下也能及时更新状态。
增加max.poll.interval.ms:对于耗时较长的消息处理逻辑,可以通过增加此参数值来避免因处理时间过长而被误判为失效。
实现幂等性消费者:确保你的消费者能够安全地处理重复的消息,这有助于缓解由于重平衡期间可能出现的数据重复问题。
使用静态成员资格:Kafka 2.3+引入了静态成员资格的概念,允许开发者指定特定消费者的ID。这可以帮助保持稳定的消费者集合,从而减少不必要的重平衡事件。
通过以上方法,可以有效地管理和优化消费组的重平衡过程,进而提升整个消息处理系统的稳定性和效率。如果你有更具体的应用场景或者遇到了特定的问题,欢迎进一步探讨!
在Kafka消费组重平衡的后续阶段中,主要包括分区分配、同步和稳定的三个步骤。这些步骤完成后,消费组就可以开始正常的消息消费。下面是详细的流程说明。
3. 分区分配
在JoinGroup阶段,GroupCoordinator会选举一个消费者作为consumer leader,并将消费组内所有成员的订阅信息和选定的分区分配策略发送给consumer leader。接下来,consumer leader将负责执行分区分配的具体操作:
获取主题元数据:
consumer leader需要获取消费组订阅的所有主题的元数据,主要包括每个主题的分区数量等信息。执行分区分配算法:
根据分配策略(例如
RangeAssignor、RoundRobinAssignor等),将所有主题的分区分配给消费组的消费者。分区分配策略会根据消费者的订阅情况和分区的数量来均衡地分配负载。分配结果会记录每个消费者对应的分区列表。
发送分配结果给
GroupCoordinator:consumer leader将分区分配的结果通过SyncGroupRequest发送给GroupCoordinator。
4. 分区同步
在分区分配结果提交给GroupCoordinator之后,GroupCoordinator会将分区分配方案同步到所有消费者:
发送
SyncGroupResponse:GroupCoordinator将分配结果发送给所有消费者,每个消费者都会收到其具体分配到的分区信息。消费者处理
SyncGroupResponse:每个消费者会在接收到
SyncGroupResponse后,根据其中包含的分区信息更新本地的分区分配状态。如果消费者在
SyncGroupResponse中发现自己没有分配到任何分区,它将进入空闲状态,等待下次重平衡。
异常处理:在分区同步过程中,如果某个消费者无法及时接收到
SyncGroupResponse,可能会被踢出消费组,从而触发新一轮的重平衡。
5. 稳定阶段
当所有消费者都成功接收到SyncGroupResponse并完成分区分配的更新后,消费组进入稳定状态:
开始消息消费:每个消费者可以开始消费自己分配到的分区中的消息。消费者会从上次提交的偏移量继续消费,或者从最新的偏移量开始(取决于配置)。
定期发送心跳:为了维持消费组的活跃状态,消费者会定期向
GroupCoordinator发送心跳请求。如果心跳超时或失败,消费者会被认为已离开消费组,从而触发新一轮的重平衡。偏移量提交:在正常的消息消费过程中,消费者会定期提交偏移量,以便在发生故障时从上次提交的偏移量继续消费。
重平衡的异常和优化
重平衡过程中可能会出现一些异常情况,如消费者网络故障、心跳超时等,都会导致重平衡的重新触发。为了优化重平衡的影响,可以采用以下策略:
提高重平衡的稳定性:通过合理配置心跳间隔、会话超时时间和分区分配策略,减少重平衡的频率。
使用
StickyAssignor策略:StickyAssignor分区分配策略会尽量保持上次分配的分区不变,以减少重平衡带来的影响。动态增加分区:通过动态增加分区的方式来适应消费组规模的变化,减少因分区数量不均匀导致的频繁重平衡。
小结
消费组重平衡的后续步骤包括分区分配、分区同步和稳定阶段。完成这些步骤后,消费组就可以开始正常的消息消费,并通过心跳机制保持组的活跃性。合理配置重平衡相关参数和采用合适的分区分配策略可以有效降低重平衡的频率和对系统的影响。
上节课我们讨论了消费组重平衡的前两个阶段:查找GroupCoordinator和注册到GroupCoordinator。这节课我们继续讨论第三个阶段“同步消费组状态”和第四个阶段“消费者向GroupCoordinator发送心跳”。
在消费组重平衡的过程中,第三个阶段是“同步消费组状态”。这个阶段发生在消费者成功注册到GroupCoordinator之后,并且所有消费者都已经准备好参与新的分配方案。这一阶段的主要目的是确保所有的消费者都了解最新的分区分配情况,并且准备开始根据新的分配方案来消费消息。下面是该阶段的详细过程:
同步消费组状态
选举领导者:
在所有注册到GroupCoordinator的消费者中,会有一个被选为领导者(Leader)。这个选择通常基于某种策略,比如第一个加入组的消费者或者随机选择。
领导者负责决定如何将主题的分区分配给各个消费者。
计算分配方案:
领导者根据当前活跃的消费者列表和可用的主题分区来计算一个新的分区分配方案。
分配方案可以采用不同的算法,如Range Assignment或RoundRobin Assignment等。
发送SyncGroup请求:
领导者通过向GroupCoordinator发送SyncGroup请求来提交分配方案。
SyncGroup请求包含了每个消费者的ID以及它们各自被分配到的分区列表。
广播分配方案:
GroupCoordinator接收到SyncGroup请求后,会将新的分配方案广播给消费组中的所有成员。
每个消费者都会收到一个包含其应处理的分区列表的消息。
确认分配:
收到新分配方案的消费者需要向GroupCoordinator确认他们已经接收到了这些信息,并准备好按照新的分配方案进行工作。
一旦所有消费者都确认了新的分配方案,整个消费组就进入了稳定状态,可以开始正常消费消息。
处理未完成的任务:
如果之前的分配中有尚未完成的消息处理任务,消费者可能需要在开始新的分配之前妥善处理这些遗留任务,例如保存偏移量、提交事务等。
注意事项
故障恢复:如果在同步过程中某个消费者出现故障,则需要重新启动重平衡流程。
网络延迟:网络状况会影响同步的速度,因此要确保网络连接的质量。
性能考虑:频繁的重平衡会对系统性能产生负面影响,因此优化消费者的行为以减少不必要的重平衡是非常重要的。
第四个阶段:消费者向GroupCoordinator发送心跳
在同步完消费组状态并确定了新的分配方案之后,消费者进入了一个相对稳定的状态,在这段时间内,它们会定期向GroupCoordinator发送心跳消息,以表明自己仍然活跃并且能够继续处理消息。
心跳机制:
消费者会周期性地向GroupCoordinator发送心跳包。
心跳包中通常包含消费者的ID以及其他必要的元数据。
心跳间隔:
心跳间隔由
heartbeat.interval.ms配置参数控制。为了防止因短暂的网络问题导致消费者被视为下线,心跳间隔应当小于
session.timeout.ms的一半。
心跳超时:
如果GroupCoordinator在
session.timeout.ms的时间内没有收到消费者的心跳,则认为该消费者已经失效。一旦检测到消费者失效,就会触发新一轮的重平衡过程。
通过这两个阶段的操作,消费组能够动态调整其内部结构以适应不断变化的环境,同时保证系统的高可用性和负载均衡。
消费组重平衡的第三个阶段是“同步消费组状态”,在这个阶段中,分区的分配结果会在所有消费者之间进行同步,使每个消费者都知道自己需要消费哪些分区。这个步骤是完成分区分配的最后一步,确保消费组成员能够开始正常消费消息。
1. 同步消费组状态的流程
在之前的分区分配阶段,consumer leader已经将分区分配方案提交给了GroupCoordinator。接下来,GroupCoordinator需要将分配结果发送给所有消费者,以完成同步。
步骤详解:
GroupCoordinator发送SyncGroupResponse:GroupCoordinator会把分区分配的方案通过SyncGroupResponse发送给消费组内的每一个成员。每个消费者在接收到
SyncGroupResponse时,都会获得自己具体被分配到的分区列表。如果某个消费者没有分配到任何分区,它将进入空闲状态,等待下一次重平衡。
消费者处理
SyncGroupResponse:当消费者收到
SyncGroupResponse时,会根据其中的信息更新本地的分区分配状态。这个状态的更新包括记录分配到的分区和准备开始消费消息。如果某个消费者在
SyncGroupResponse中没有分到任何分区,它可能会释放本地资源或暂时进入等待状态。
分区分配策略的影响:
不同的分区分配策略(如
RangeAssignor、RoundRobinAssignor、StickyAssignor等)会影响SyncGroupResponse中的分配方案。一般来说,StickyAssignor会尽量保持消费者之前分配的分区不变,以减少分区重新分配带来的开销。
异常情况的处理:
如果某个消费者在处理
SyncGroupResponse时出现网络异常或处理超时,可能会被视为失联,从而导致新一轮的重平衡。这也是Kafka设计心跳机制的原因,心跳可以及时发现消费者是否健康,避免长时间等待导致的重平衡延迟。
2. 核心类和方法
AbstractCoordinator.sendSyncGroupRequest():该方法用于发送SyncGroupRequest请求给GroupCoordinator,以完成分区同步。SyncGroupResponseHandler:该回调类用于处理SyncGroupResponse响应,更新消费者的分区分配状态。ConsumerRebalanceListener:Kafka提供了该接口用于监控和管理消费者的重平衡过程。当发生重平衡时,可以通过该接口触发相应的操作,如提交偏移量或清理资源。
同步消费组状态的重要性
同步阶段的核心目标是确保每个消费者能够顺利获得自己需要消费的分区列表,并能从适当的偏移量开始消费。这个步骤对于保证消费组的负载均衡和数据消费的连续性至关重要。
完成“同步消费组状态”后,消费组重平衡的核心过程已经完成,接下来就进入第四个阶段,即消费者向GroupCoordinator发送心跳,以维持消费组的稳定状态。
在接下来的内容中,我们将继续讨论消费组重平衡的第四个阶段:“消费者向GroupCoordinator发送心跳”。
消费组重平衡第三个阶段:同步消费组状态
我们在上节课讲到 leader consumer 制定了消费组内所有消费者的分配方案,下一步leader consumer就要把分配方案发送给GroupCoordinator。这时就进入了同步消费组的状态。leader consumer向GroupCoordinator发送SyncGroupRequest请求并处理GroupCoordinator发送回来的SyncGroupResponse响应。
也就是说,leader consumer并不是直接和其余的普通消费者同步分配方案,而是通过GroupCoordinator这个中介转发同步分配方案的。包括leader consumer和普通的consumer在内都会向GroupCoordinator发送SyncGroupRequest请求,但是只有leader consumer发送的SyncGroupRequest请求里有所有消费者的分配方案。
如下图所示:
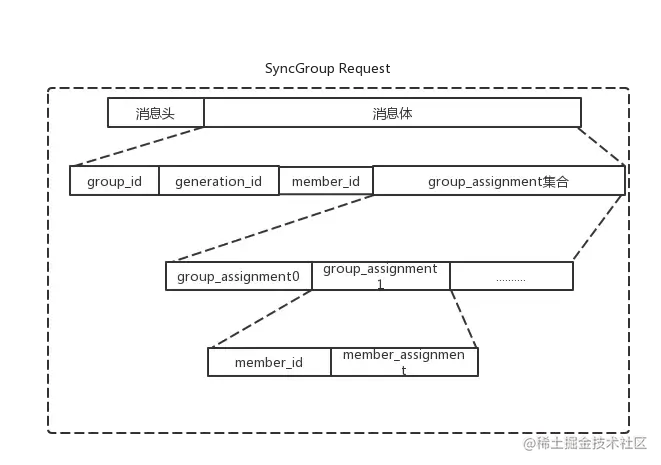
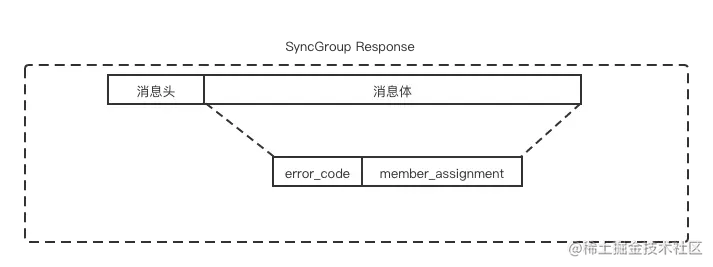
SyncGroupRequest 中各个字段的含义如下表:
SyncGroupResponse 中各个字段的含义如下表:
上节课我们已经分析了onJoinLeader()方法,方法主要是构建SyncGroupRequest请求和发送SyncGroupRequest,这节课就不再赘述了,我们主要看下处理响应SyncGroupResponse的类。
类 SyncGroupResponseHandler
private class SyncGroupResponseHandler extends CoordinatorResponseHandler<SyncGroupResponse, ByteBuffer> {
private SyncGroupResponseHandler(final Generation generation) {
super(generation);
}
@Override
public void handle(SyncGroupResponse syncResponse,
RequestFuture<ByteBuffer> future) {
Errors error = syncResponse.error();
//1.如果响应没有异常。
if (error == Errors.NONE) {
//1.1 协议类型是否是消费者
if (isProtocolTypeInconsistent(syncResponse.data.protocolType())) {
log.error("SyncGroup failed due to inconsistent Protocol Type, received {} but expected {}",
syncResponse.data.protocolType(), protocolType());
//抛出协议类型不符的错误。
future.raise(Errors.INCONSISTENT_GROUP_PROTOCOL);
} else {
//2.收到成功的响应。
log.debug("Received successful SyncGroup response: {}", syncResponse);
sensors.syncSensor.record(response.requestLatencyMs());
synchronized (AbstractCoordinator.this) {
//如果年代不为空且消费者状态是正在重平衡
if (!generation.equals(Generation.NO_GENERATION) && state == MemberState.COMPLETING_REBALANCE) {
final String protocolName = syncResponse.data.protocolName();
final boolean protocolNameInconsistent = protocolName != null &&
!protocolName.equals(generation.protocolName);
//协议名称不一致
if (protocolNameInconsistent) {
log.error("SyncGroup failed due to inconsistent Protocol Name, received {} but expected {}",
protocolName, generation.protocolName);
future.raise(Errors.INCONSISTENT_GROUP_PROTOCOL);
} else {
log.info("Successfully synced group in generation {}", generation);
//3.修改状态
state = MemberState.STABLE;
rejoinNeeded = false;
lastRebalanceEndMs = time.milliseconds();
sensors.successfulRebalanceSensor.record(lastRebalanceEndMs - lastRebalanceStartMs);
lastRebalanceStartMs = -1L;
//4.异步请求完成。
future.complete(ByteBuffer.wrap(syncResponse.data.assignment()));
}
} else {
log.info("Generation data was cleared by heartbeat thread to {} and state is now {} before " +
"receiving SyncGroup response, marking this rebalance as failed and retry",
generation, state);
future.raise(Errors.ILLEGAL_GENERATION);
}
}
}
} else {
//做好再次加入group的标记
requestRejoin();
//验证失败
if (error == Errors.GROUP_AUTHORIZATION_FAILED) {
future.raise(GroupAuthorizationException.forGroupId(rebalanceConfig.groupId));
//正在重平衡,需要再次加入group
} else if (error == Errors.REBALANCE_IN_PROGRESS) {
log.info("SyncGroup failed: The group began another rebalance. Need to re-join the group. " +
"Sent generation was {}", sentGeneration);
future.raise(error);
//消费者 member_id 相同
} else if (error == Errors.FENCED_INSTANCE_ID) {
log.error("SyncGroup failed: The group instance id {} has been fenced by another instance. " +
"Sent generation was {}", rebalanceConfig.groupInstanceId, sentGeneration);
future.raise(error);
//识别不出来的消费者member_id或非法的GENERATION
} else if (error == Errors.UNKNOWN_MEMBER_ID
|| error == Errors.ILLEGAL_GENERATION) {
log.info("SyncGroup failed: {} Need to re-join the group. Sent generation was {}",
error.message(), sentGeneration);
if (generationUnchanged())
resetGenerationOnResponseError(ApiKeys.SYNC_GROUP, error);
future.raise(error);
//GroupCoordinator不可用或不是正确的GroupCoordinator
} else if (error == Errors.COORDINATOR_NOT_AVAILABLE
|| error == Errors.NOT_COORDINATOR) {
log.info("SyncGroup failed: {} Marking coordinator unknown. Sent generation was {}",
error.message(), sentGeneration);
markCoordinatorUnknown(error);
future.raise(error);
//其他错误
} else {
future.raise(new KafkaException("Unexpected error from SyncGroup: " + error.message()));
}
}
}
}
我给你讲解一下处理响应的方法 handle()。
第一步,解析SyncGroupResponse,判断是否有error,如果没有error就进入正常响应的处理逻辑。
第二步,判断协议类型是否是consumer。如果不是,说明不是发给消费者的响应,接着打出错误的异常。如果协议类型是consumer,就进入正常响应处理流程。
第三步,判断消费者状态是否正确。判断条件是消费者处于COMPLETING_REBALANCE的状态且消费者获取的groupCoordinator的年代不为空。如果满足就修改消费者的状态为Stable,否则就抛出相应的错误。
第四步,异步请求完成。
但是,这里只是消费者收到分区消费方案,并不是真正处理和加载分区消费方案的地方。那真正处理和加载分区消费方案的地方在哪里呢?我们需要回到第二阶段消费者注册GroupCoordinator的joinGroupIfNeeded()方法。
在消费组重平衡的第三阶段“同步消费组状态”中,handle() 方法的主要任务是处理 SyncGroupResponse 响应,并对消费者的分区分配进行确认和更新。你所描述的步骤详细地讲解了 handle() 方法的处理逻辑。接下来,让我们进一步分析这些步骤的细节。
handle() 方法详解
第一步:解析 SyncGroupResponse
方法的第一步是解析
SyncGroupResponse,判断响应中是否存在错误。如果没有错误,就可以继续进行正常的处理流程。
如果有错误(例如
REBALANCE_IN_PROGRESS或ILLEGAL_GENERATION),则会触发相应的错误处理逻辑,可能导致新一轮的重平衡。
第二步:检查协议类型
解析完
SyncGroupResponse之后,需要检查协议类型(protocol type)。如果协议类型不是
consumer,则说明该响应不是针对消费者的,将会打印错误日志并停止处理。如果协议类型是
consumer,说明响应是针对消费者的分区分配,同步过程可以继续。
第三步:检查消费者状态
检查消费者的状态,确保当前的状态是
COMPLETING_REBALANCE,并且获取到的GroupCoordinator的generation(年代)信息不为空。如果这些条件满足,表示消费者已经完成了重平衡并且分区分配已准备好,消费者的状态会被更新为
Stable,表示可以开始正常的消息消费。如果不满足这些条件,会抛出相应的错误,说明消费者的状态不正确,重平衡可能会失败。
第四步:异步请求完成
最后一步是将请求标记为完成,并触发后续的回调。
这一阶段完成后,消费者并未真正处理和加载分区的消费方案,只是确认了分区分配的稳定性。
真正处理和加载分区消费方案的位置
在 handle() 方法中,消费者虽然收到了分区消费方案,但实际的分区处理和加载并不是在这个方法里完成的。真正处理和加载分区的地方在第二阶段的 joinGroupIfNeeded() 方法中。
joinGroupIfNeeded() 方法的作用
joinGroupIfNeeded()是消费者在向GroupCoordinator注册时调用的方法之一,用于检测当前消费者是否需要重新加入消费组。在这个方法中,会触发
SyncGroup的逻辑,等待SyncGroupResponse的到来。当
SyncGroupResponse被成功处理后,消费者会正式完成分区的加载和本地状态的更新,准备开始消息消费。
加载分区的过程
获取分区分配方案:在
joinGroupIfNeeded()方法中,消费者会根据SyncGroupResponse中的分区分配方案来更新自己的本地状态。加载分区消费信息:消费者会加载需要消费的分区,并设置初始的偏移量。
触发消费者的
onPartitionsAssigned回调:如果使用了ConsumerRebalanceListener,会调用onPartitionsAssigned()方法,以便执行一些初始化操作(如提交偏移量)。
小结
handle()方法的主要功能是处理SyncGroupResponse,并确认消费者的分区分配状态是否稳定。真正处理和加载分区的地方在
joinGroupIfNeeded()方法中,它在消费者加入消费组后触发分区同步和分区加载逻辑。重平衡完成后,消费者进入
Stable状态,可以开始正常的消息消费。
SyncGroupResponseHandler 是 Kafka 客户端内部用于处理 SyncGroupResponse 的回调类。该类负责解析 SyncGroupResponse 的响应内容,确保消费者可以正常接收并更新自己的分区分配状态。通过这个类,每个消费者都能知道自己被分配到的分区,开始消费流程。
1. SyncGroupResponseHandler 的功能
接收并解析响应:从
GroupCoordinator处接收同步分配结果,并根据结果更新本地的分区信息。异常处理:在同步过程中检测异常情况(如网络故障或响应超时),如果失败则触发新一轮的重平衡。
通知监听器:同步完成后,触发
ConsumerRebalanceListener中的回调方法,便于用户执行清理或提交偏移等操作。
2. 关键逻辑分析
class SyncGroupResponseHandler implements RequestCompletionHandler {
@Override
public void onComplete(ClientResponse response) {
if (response.wasDisconnected()) {
log.warn("SyncGroupRequest failed: disconnected from GroupCoordinator");
coordinator.handleDisconnect();
return;
}
SyncGroupResponse syncResponse = (SyncGroupResponse) response.responseBody();
Errors error = syncResponse.error();
if (error != Errors.NONE) {
log.warn("SyncGroupRequest failed with error: {}", error.message());
coordinator.handleSyncGroupError(error);
return;
}
try {
// 更新消费者的分区分配信息
Map<String, List<TopicPartition>> assignment = syncResponse.groupAssignment();
coordinator.onJoinComplete(syncResponse.generationId(),
syncResponse.memberId(),
assignment);
} catch (Exception e) {
log.error("Failed to update partition assignment", e);
coordinator.handleSyncGroupError(Errors.UNKNOWN_SERVER_ERROR);
}
}
}3. 关键步骤详解
(1) 处理断开连接情况
if (response.wasDisconnected()) {
log.warn("SyncGroupRequest failed: disconnected from GroupCoordinator");
coordinator.handleDisconnect();
return;
}如果在同步过程中客户端与
GroupCoordinator的连接断开,则调用coordinator.handleDisconnect()方法进行处理。一旦检测到断开,当前消费者会被移除出消费组,并可能触发新一轮重平衡。
(2) 检查同步响应中的错误
Errors error = syncResponse.error();
if (error != Errors.NONE) {
log.warn("SyncGroupRequest failed with error: {}", error.message());
coordinator.handleSyncGroupError(error);
return;
}如果
SyncGroupResponse返回了错误码(如超时或非法请求),调用handleSyncGroupError()进行错误处理。常见错误:
REBALANCE_IN_PROGRESS:当前正处于重平衡状态,需要重试。ILLEGAL_GENERATION:消费组状态已过期,需重新加入。
(3) 更新分区分配状态
Map<String, List<TopicPartition>> assignment = syncResponse.groupAssignment();
coordinator.onJoinComplete(syncResponse.generationId(),
syncResponse.memberId(),
assignment);解析
SyncGroupResponse中的 分区分配信息,并通过coordinator.onJoinComplete()更新本地的分配状态。此处会使用 generationId(消费组的版本)和 memberId(消费者的唯一标识)记录状态,确保分配的一致性。
(4) 异常处理
catch (Exception e) {
log.error("Failed to update partition assignment", e);
coordinator.handleSyncGroupError(Errors.UNKNOWN_SERVER_ERROR);
}如果在更新分区分配时出现任何异常,则将错误处理为
UNKNOWN_SERVER_ERROR并触发重平衡。
4. 类的作用总结
SyncGroupResponseHandler 是 Kafka 消费者客户端中的核心类,它确保消费组重平衡的最后一步顺利完成:
成功时:分区分配状态被更新,消费者准备开始消费消息。
失败时:错误会触发重平衡,保证消费组的一致性和可用性。
5. 使用场景和应用
维护消费组的一致性:确保每个消费者获取到正确的分区,并从指定的偏移量开始消费。
管理异常情况:处理断开连接或同步失败,避免消费者进入不一致状态。
支持自定义监听器:配合
ConsumerRebalanceListener进行偏移量提交或资源清理操作。
SyncGroupResponseHandler 的执行标志着消费组重平衡的关键步骤已完成,接下来消费者将进入正常的消费阶段,并通过心跳机制维持消费组的活跃状态。
joinGroupIfNeeded() 方法源码如下:
boolean joinGroupIfNeeded(final Timer timer) {
while (rejoinNeededOrPending()) {
......忽略
//1.发送注册到Group Coordinator里的JoinGroup请求前的工作,
final RequestFuture<ByteBuffer> future = initiateJoinGroup();
//2.网络阻塞发送
client.poll(future, timer);
if (!future.isDone()) {
return false;
}
//3.如果异步请求成功了
if (future.succeeded()) {
Generation generationSnapshot;
MemberState stateSnapshot;
generationSnapshot = this.generation;
stateSnapshot = this.state;
}
//4.Group年代不为空,且消费者的状态为STABLE,也就是说已经收到了分区分配方案。
if (!generationSnapshot.equals(Generation.NO_GENERATION)
//获取分区分配策略
ByteBuffer memberAssignment = future.value().duplicate();
//5.处理分区分配
onJoinComplete(generationSnapshot.generationId, generationSnapshot.memberId, generationSnapshot.protocolName, memberAssignment);
resetJoinGroupFuture();
needsJoinPrepare = true;
} else {
log.info("Generation data was cleared by heartbeat thread to {} and state is now {} before " +
"the rebalance callback is triggered, marking this rebalance as failed and retry",
generationSnapshot, stateSnapshot);
resetStateAndRejoin();
resetJoinGroupFuture();
}
} else {
final RuntimeException exception = future.exception();
if (!(exception instanceof MemberIdRequiredException)) {
log.info("Rebalance failed.", exception);
}
resetJoinGroupFuture();
if (exception instanceof UnknownMemberIdException ||
exception instanceof RebalanceInProgressException ||
exception instanceof IllegalGenerationException ||
exception instanceof MemberIdRequiredException)
continue;
else if (!future.isRetriable())
throw exception;
resetStateAndRejoin();
timer.sleep(rebalanceConfig.retryBackoffMs);
}
}
return true;
}
我用流程图解释一下这整个流程。
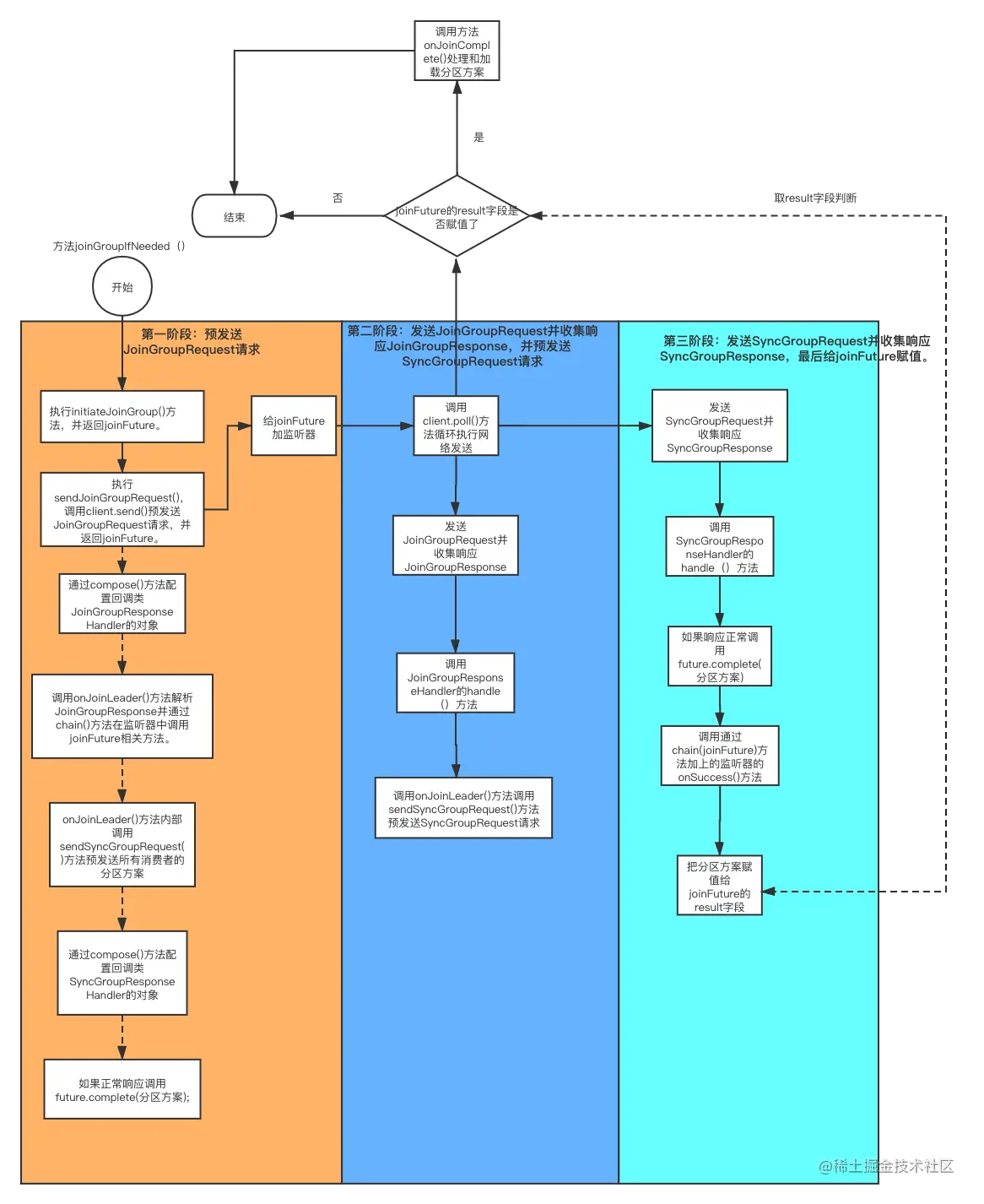
结合该流程图,简述一下“消费者注册消费组到处理分区方案的整体流程”步骤,可分三个大阶段。
第一阶段,预发送JoinGroupRequest请求。调用方法initiateJoinGroup()对JoinGroupRequest请求预处理并返回joinFuture,joinFuture包含给这个消费者分配的分区方案。同时这个方法及调用的方法大量使用RequestFuture<T>内部的compose()和chain()方法实现事件的传递。包括配置对JoinGroupResponse响应处理的回调对象和SyncGroupResponse响应处理的回调对象。当响应收到后产生事件传播,按照我们的配置层层调用。
第二阶段,网络发送JoinGroupRequest请求,并收集JoinGroupResponse响应,JoinGroupResponseHandler类对象处理JoinGroupResponse响应并预发送SyncGroupRequest请求。
第三阶段,网络发送SyncGroupRequest请求并收集SyncGroupResponse响应。SyncGroupResponseHandler类对象解析SyncGroupResponse响应,完成当前future并把分区方案给当前的future,调用相应的监听器完成对joinFuture的赋值。
这个时候joinFuture就有值了,接下来调用方法onJoinComplete()解析和处理分区方案。
消费者注册消费组并处理分区方案的整体流程可以分为三个主要阶段,每个阶段都有其特定的任务和目标。以下是结合你提供的信息对这三个阶段的简述:
第一阶段:预发送JoinGroupRequest请求
初始化:在这一阶段,消费者首先会调用
initiateJoinGroup()方法来准备一个JoinGroupRequest。这个请求是用于向Kafka集群表明自己想要加入某个消费组。事件链构建:此方法内部使用了
RequestFuture<T>对象,并通过compose()和chain()方法来构建一系列异步操作的链条。这样做的目的是确保当从服务器接收到响应时(无论是JoinGroupResponse还是之后的SyncGroupResponse),能够按照预定顺序执行相应的回调函数。设置回调:在这一步中,还会设置好处理
JoinGroupResponse以及后续可能收到的SyncGroupResponse的回调逻辑。
第二阶段:网络发送JoinGroupRequest请求及响应处理
发送请求:一旦准备工作完成,就将之前构造好的
JoinGroupRequest通过网络发送给Kafka集群中的协调者节点。接收响应:消费者等待来自协调者的
JoinGroupResponse。该响应包含了关于哪些成员被选为领导者、当前组的状态等信息。处理响应与发起新请求:收到响应后,由
JoinGroupResponseHandler类负责解析,并根据需要准备下一个步骤所需的SyncGroupRequest。
第三阶段:发送SyncGroupRequest请求及最终确认
同步请求:基于上一步获得的信息,生成并向协调者发送
SyncGroupRequest,这是为了告知其他组成员自己的状态更新。处理最终响应:协调者返回
SyncGroupResponse,其中包含分配给各个消费者的主题分区列表。这些信息会被SyncGroupResponseHandler解码。完成future并通知监听器:最后,利用解析得到的数据填充最初创建的
joinFuture,并通过调用相关监听器的方法触发进一步的动作或通知,比如调用onJoinComplete()来开始实际的消息拉取工作。
整个过程中,RequestFuture机制保证了所有操作都是非阻塞式的,并且能够有效地管理多个并发请求之间的依赖关系。此外,合理地设计回调函数使得系统能够在不同阶段之间平滑过渡,确保数据的一致性和完整性。
结合你提供的流程图,我们可以将“消费者注册消费组到处理分区方案的整体流程”简化为以下三个大阶段:
第一阶段:预发送 JoinGroupRequest 请求
初始化请求:消费者调用
initiateJoinGroup()方法,进行JoinGroupRequest请求的预处理。创建
joinFuture:该方法返回一个joinFuture,该对象将用于存储消费者分配的分区方案。配置事件传播:在请求预处理过程中,
initiateJoinGroup()方法及其调用的方法会大量使用RequestFuture<T>内部的compose()和chain()方法。这些方法用于实现事件的传递,配置对JoinGroupResponse和SyncGroupResponse响应的处理回调对象。事件传递:当响应收到后,将触发事件传播,按照预配置的回调层层调用,最终将响应结果传递到消费者。
第二阶段:发送 JoinGroupRequest 请求
网络请求:消费者通过网络发送
JoinGroupRequest请求给GroupCoordinator。响应处理:在收到
JoinGroupResponse响应后,JoinGroupResponseHandler类对象处理该响应。预发送
SyncGroupRequest:在处理完JoinGroupResponse后,该处理器会立即发送SyncGroupRequest请求,以便继续进行分区的同步。
第三阶段:发送 SyncGroupRequest 请求
网络请求:消费者通过网络发送
SyncGroupRequest请求给GroupCoordinator。响应解析:
SyncGroupResponseHandler类对象解析SyncGroupResponse响应。完成
joinFuture:解析过程中,将当前的SyncGroupResponse中的分区方案填充到之前创建的joinFuture中,完成对该future的赋值。调用分区方案处理:一旦
joinFuture被赋值,接下来消费者将调用onJoinComplete()方法,解析并处理分区方案,完成消费者的注册过程。
小结
通过这三个阶段,消费者能够成功注册到消费组并获得分区方案,确保在分布式环境中有效地进行消息消费。整个流程涉及请求的预处理、网络发送、响应处理和分区方案的最终解析,保证了消费者的稳定性和可靠性。
这个时候joinFuture就有值了,接下来调用方法onJoinComplete()解析和处理分区方案。
好,我们继续学习一下onJoinComplete()方法,具体如下:
protected void onJoinComplete(int generation,
String memberId,
String assignmentStrategy,
ByteBuffer assignmentBuffer) {
log.debug("Executing onJoinComplete with generation {} and memberId {}", generation, memberId);
//1.只有leader consumer才关系元数据的变化。
if (!isLeader)
assignmentSnapshot = null;
//2.查找使用的分区策略
ConsumerPartitionAssignor assignor = lookupAssignor(assignmentStrategy);
if (assignor == null)
throw new IllegalStateException("Coordinator selected invalid assignment protocol: " + assignmentStrategy);
......忽略
//3.反序列化,更新assignment。
Assignment assignment = ConsumerProtocol.deserializeAssignment(assignmentBuffer);
//4.获取分配的分区
Set<TopicPartition> assignedPartitions = new HashSet<>(assignment.partitions());
//5.获取分配的分区是否符合消费者的订阅。
if (!subscriptions.checkAssignmentMatchedSubscription(assignedPartitions)) {
//重新加入消费组
requestRejoin();
return;
}
final AtomicReference<Exception> firstException = new AtomicReference<>(null);
Set<TopicPartition> addedPartitions = new HashSet<>(assignedPartitions);
addedPartitions.removeAll(ownedPartitions);
if (protocol == RebalanceProtocol.COOPERATIVE) {
Set<TopicPartition> revokedPartitions = new HashSet<>(ownedPartitions);
revokedPartitions.removeAll(assignedPartitions);
);
if (!revokedPartitions.isEmpty()) {
firstException.compareAndSet(null, invokePartitionsRevoked(revokedPartitions));
log.info("Need to revoke partitions {} and re-join the group", revokedPartitions);
requestRejoin();
}
}
maybeUpdateJoinedSubscription(assignedPartitions);
// 6.调用消费者收到分区方案后的回调方法并设置异常。
firstException.compareAndSet(null, invokeOnAssignment(assignor, assignment));
if (autoCommitEnabled)
this.nextAutoCommitTimer.updateAndReset(autoCommitIntervalMs);
//7.填充assignment集合
subscriptions.assignFromSubscribed(assignedPartitions);
firstException.compareAndSet(null, invokePartitionsAssigned(addedPartitions));
if (firstException.get() != null) {
if (firstException.get() instanceof KafkaException) {
throw (KafkaException) firstException.get();
} else {
throw new KafkaException("User rebalance callback throws an error", firstException.get());
}
}
}
第一步,只有leader consumer才关系元数据的变化,如果是follower consumer就要取消对元数据的监控。
第二步,查找使用的分区。
第三步,反序列化,更新assignment。
第四步,获取分配的分区。
第五步,判断获取分配的主题分区是否符合消费者订阅的主题,如果不符合就调用requestRejoin(),下次找机会再次加入消费组。
第六步,调用消费者收到分区方案后的回调方法并设置异常。收到分区方案后要调用注册在这个事件上的监听器。
第七步,填充assignment集合到订阅类中,这样消费者就知道要消费哪些分区了。
消费组重平衡第四个阶段:消费者向GroupCoordinator发送心跳
当消费者处于正常工作状态后,消费者通过向GroupCoordinator发送心跳来维持它与GroupCoordinator的从属关系。消费者和GroupCoordinator之间的心跳是抽象类AbstractCoordinator中的内部类HeartbeatThread线程维持的。
在 Kafka 中,当消费者处于正常工作状态时,它们需要通过定期发送心跳来维持与 GroupCoordinator 的从属关系。这一机制确保了消费者在消费组中的活跃状态,以避免因长时间未发送心跳而被认为已经下线。下面是对心跳机制的详细解释:
心跳机制的工作原理
心跳的目的:
维持活跃状态:通过发送心跳,消费者向
GroupCoordinator表示自己仍然活跃,并防止被剔除出消费组。检测故障:如果
GroupCoordinator在设定的超时时间内未收到某个消费者的心跳,它会认为该消费者已经宕机,并会触发重平衡。
心跳的发送:
心跳机制由抽象类
AbstractCoordinator中的内部类HeartbeatThread负责管理。HeartbeatThread是一个独立的线程,负责定期向GroupCoordinator发送心跳请求。
心跳的实现:
在
HeartbeatThread中,消费者会定期调用sendHeartbeat()方法,以向GroupCoordinator发送心跳请求。sendHeartbeat()方法会创建并发送一个心跳请求,其中包含消费者的member_id和当前的generation。
心跳的频率:
心跳的发送频率可以通过配置项
heartbeat.interval.ms来控制,通常设置为几秒钟,以确保及时反馈消费者的活跃状态。
心跳失败处理:
如果
HeartbeatThread发送心跳失败(例如网络问题或GroupCoordinator不可用),消费者会尝试重新发送心跳请求。在多次失败后,消费者可能会被认为已经下线,这将导致重平衡,并可能影响消费组的稳定性。
小结
心跳机制是 Kafka 消费者维持与 GroupCoordinator 关系的关键,它通过定期发送心跳请求,确保消费者的活跃状态,并在发生故障时进行检测。AbstractCoordinator 中的 HeartbeatThread 线程自动管理这一过程,保证消费者在消费组中的稳定性与高可用性。
当消费者成功加入消费组并开始正常工作后,它需要定期向GroupCoordinator发送心跳来维持其会话和成员身份。这是通过AbstractCoordinator抽象类中的内部类HeartbeatThread线程实现的。下面是对这一过程的简述:
消费者与GroupCoordinator之间的心跳机制
心跳线程初始化:一旦消费者成功加入消费组(即完成上述三个阶段),它会在内部创建一个
HeartbeatThread实例。这个线程专门负责周期性地向GroupCoordinator发送心跳消息。心跳间隔设定:心跳发送的时间间隔通常由Kafka集群配置决定,比如可以通过
session.timeout.ms参数来指定。如果在该时间间隔内GroupCoordinator没有收到任何心跳,则认为消费者已经失效,并可能触发再平衡操作来重新分配分区给其他活跃的消费者。心跳消息构造与发送:每当到达预设的心跳间隔时,
HeartbeatThread会构建一个心跳请求(通常是HeartbeatRequest),并通过网络将其发送到GroupCoordinator。心跳请求中包含了消费者的元数据信息,如消费组ID、成员ID等。处理心跳响应:GroupCoordinator接收到心跳请求后,会检查消费者的当前状态是否仍然有效。然后返回一个心跳响应(
HeartbeatResponse)给消费者。如果一切正常,响应将指示消费者继续按计划发送心跳;如果有问题,例如发生再平衡事件,则响应可能会包含错误码或其他指示信息,促使消费者采取相应行动。异常情况下的重试机制:若因网络原因或其它因素导致心跳请求失败,
HeartbeatThread一般会有一定的重试策略来尝试重新发送心跳,以确保消费者与GroupCoordinator之间的连接不被中断。线程监控与维护:除了发送心跳外,
HeartbeatThread还负责监听来自外部的关闭信号或其他命令,以便适时停止运行或者调整自身的行为模式。
通过这种方式,Kafka保证了每个消费者都能够持续地保持与GroupCoordinator的有效联系,从而支持了大规模分布式环境下的高效可靠的消息消费。同时,这也为Kafka提供了灵活性,在检测到某个消费者不再活跃时能够快速做出反应,确保整个消费组的工作效率不受影响。
run()
HeartbeatThread是一个线程类,它的主要的逻辑在 run() 方法里,我们看一下这个方法的源码:
public void run() {
try {
log.debug("Heartbeat thread started");
//死循环
while (true) {
synchronized (AbstractCoordinator.this) {
if (closed)
return;
//1.判断是否能开启心跳线程。
if (!enabled) {
AbstractCoordinator.this.wait();
continue;
}
// 2.没加入GroupCoordinator就不会发心跳。
if (state.hasNotJoinedGroup() || hasFailed()) {
disable();
continue;
}
client.pollNoWakeup();
long now = time.milliseconds();
//3.是否找到了 GroupCoordinator,如果没找到则什么都不做,再次进入循环判断是否找到了GroupCoordinator。
if (coordinatorUnknown()) {
if (findCoordinatorFuture != null || lookupCoordinator().failed())
//3.1如何获取GroupCoordinator失败,有可能没broker可用,则阻塞一段时间然后再次进入循环,确保有broker可用。
AbstractCoordinator.this.wait(rebalanceConfig.retryBackoffMs);
//4.心跳超时,再次进入循环。
} else if (heartbeat.sessionTimeoutExpired(now)) {
markCoordinatorUnknown("session timed out without receiving a "
+ "heartbeat response");
//5.网络发送超时
} else if (heartbeat.pollTimeoutExpired(now)) {
String leaveReason = "consumer poll timeout has expired. This means the time between subsequent calls to poll() " +
"was longer than the configured max.poll.interval.ms, which typically implies that " +
"the poll loop is spending too much time processing messages. " +
"You can address this either by increasing max.poll.interval.ms or by reducing " +
"the maximum size of batches returned in poll() with max.poll.records.";
//5.1 离开group coordinator。
maybeLeaveGroup(leaveReason);
//6.是否应该发送
} else if (!heartbeat.shouldHeartbeat(now)) {
//6.1不应该发心跳就阻塞等待。
AbstractCoordinator.this.wait(rebalanceConfig.retryBackoffMs);
} else {
//7.可以发送心跳了,并设置最后一次发送心跳的时间
heartbeat.sentHeartbeat(now);
//8.发送心跳请求的准备工作
final RequestFuture<Void> heartbeatFuture = sendHeartbeatRequest();
//9.加监听器。
heartbeatFuture.addListener(new RequestFutureListener<Void>() {
@Override
public void onSuccess(Void value) {
synchronized (AbstractCoordinator.this) {
heartbeat.receiveHeartbeat();
}
}
@Override
public void onFailure(RuntimeException e) {
synchronized (AbstractCoordinator.this) {
if (e instanceof RebalanceInProgressException) {
heartbeat.receiveHeartbeat();
} else if (e instanceof FencedInstanceIdException) {
log.error("Caught fenced group.instance.id {} error in heartbeat thread", rebalanceConfig.groupInstanceId);
heartbeatThread.failed.set(e);
} else {
heartbeat.failHeartbeat();
AbstractCoordinator.this.notify();
}
}
}
});
}
}
}
}
......忽略
}
}这个方法是一个 while(true) 的死循环,会一直执行心跳,描述一下while循环内部的执行步骤。
第一步,判断是否能开启心跳线程。消费者到Completing_Rebalance状态后会设置开启心跳线程了。
第二步,判断消费者是否加入了GroupCoordinator,如果没加入就拒绝发心跳。
第三步,调用coordinatorUnknown()判断消费者是否找到了group coordinator,如果没找到就阻塞心跳线程,等待消费者找到group coordinator。
第四步,通过调用heartbeat.sessionTimeoutExpired(now)判断心跳返回是否超时了,一般认为是GroupCoordinator挂了。
第五步,判断心跳请求网络发送是否超时。一般是消费者的性能或网络不好造成的,这时消费者要退出消费组。
第六步,判断是否应该发送心跳。判断逻辑是心跳的间隔时间是否到了,如果没到就阻塞。默认阻塞时间是100ms,配置参数是retry.backoff.ms,你可以根据具体情况配置。
第七步,更新发送心跳的属性了,设置最后一次发送心跳的时间,并把heartbeatInFlight的参数设置为true,表明有没有处理完的心跳请求在发送。
第八步,发送心跳请求的准备工作。
第九步,给异步请求加监听器。其中监听器处理成功是调用方法heartbeat.receiveHeartbeat(),把heatbeatInFlight设置为false,这样表明这次的心跳请求就不是在发送过程中了,而是已经发送完成,下次心跳可以正常发送了。
HeartbeatThread 的 run() 方法通过一个无限循环来持续发送心跳消息给GroupCoordinator,以维持消费者与消费组之间的连接。下面是根据你提供的信息对这个方法内部逻辑的详细描述:
run() 方法执行步骤
判断是否开启心跳线程:
在开始每次循环之前,首先检查是否满足启动心跳线程的条件。通常情况下,当消费者进入
Completing_Rebalance状态后,表示它已经准备好并且可以加入到心跳机制中了。
检查是否已加入GroupCoordinator:
如果消费者还没有成功加入任何GroupCoordinator,则不会发送心跳。这是因为在没有加入任何一个消费组的情况下,发送心跳是没有意义的。
确认找到GroupCoordinator:
调用
coordinatorUnknown()方法来验证当前是否已经知道了负责管理该消费组的GroupCoordinator。如果没有找到,那么心跳线程将被阻塞,直到找到正确的GroupCoordinator。
检查会话超时:
使用
heartbeat.sessionTimeoutExpired(now)来检查最后一次成功的心跳是否已经超过配置的会话超时时间(通常是session.timeout.ms)。如果超过了这个时间,说明可能GroupCoordinator出现了问题或网络中断,这时需要采取相应的措施,如触发再平衡等。
检查请求超时:
检查上次心跳请求是否因为网络或其他原因而超时。这种情况可能是由于消费者的性能瓶颈或网络状况不佳造成的。如果确实发生了超时,消费者可能会决定退出当前消费组并重新加入。
判断是否应发送心跳:
通过比较当前时间和上一次发送心跳的时间来确定是否到了应该发送下一次心跳的时间点。如果还未到达发送间隔,则线程会被短暂地阻塞一段时间(默认为100毫秒),具体时间可以通过配置参数
retry.backoff.ms调整。
更新心跳发送属性:
更新记录最后一次发送心跳的时间,并设置标志位
heartbeatInFlight为true,表明有一个新的心跳请求正在处理过程中。
准备发送心跳请求:
进行发送心跳请求前的一些准备工作,例如构建
HeartbeatRequest对象等。
添加监听器并发送心跳:
为即将发送的心跳请求添加异步回调监听器。成功的回调函数是
heartbeat.receiveHeartbeat(),用于在接收到心跳响应后将heartbeatInFlight设置为false,表示本次心跳请求已完成。发送心跳请求给GroupCoordinator。
这样的设计确保了即使在网络不稳定或者GroupCoordinator暂时不可达的情况下,消费者也能够保持其状态,并且一旦条件允许,能够迅速恢复心跳通信。同时,通过定期发送心跳,Kafka集群能够有效地监控每个消费者的健康状况,并及时进行必要的故障转移和负载均衡操作。
在 Kafka 的消费者心跳机制中,HeartbeatThread 类的 run() 方法实现了心跳的持续发送。下面是对该方法内部 while(true) 死循环的详细步骤描述:
run() 方法内部执行步骤
检查心跳线程状态:
首先判断消费者是否处于
Completing_Rebalance状态。只有在这个状态下,消费者才能开始发送心跳请求。如果没有处于该状态,则跳过后续步骤。
验证加入状态:
检查消费者是否已经成功加入到
GroupCoordinator。如果尚未加入,则拒绝发送心跳,并等待消费者完成加入过程。
查找
GroupCoordinator:调用
coordinatorUnknown()方法,判断消费者是否找到了GroupCoordinator。如果尚未找到,心跳线程将阻塞,直到消费者找到GroupCoordinator。
检查心跳超时:
使用
heartbeat.sessionTimeoutExpired(now)方法判断上一次发送心跳的时间是否超时。如果超时,通常表示GroupCoordinator已挂掉,此时需要进行相应的处理。
检查请求超时:
判断心跳请求的网络发送是否超时。如果超时,可能是由于消费者性能不足或网络问题,此时消费者可能会选择退出消费组。
判断是否发送心跳:
检查心跳的间隔时间是否已到。如果没有达到预设的间隔时间,心跳线程将阻塞。默认的阻塞时间为 100 毫秒,且可以通过配置参数
retry.backoff.ms来调整。
更新心跳属性:
设置最后一次发送心跳的时间,并将
heartbeatInFlight属性设置为true,表明当前有一个心跳请求正在发送中。
准备发送心跳请求:
进行发送心跳请求的准备工作,包括创建心跳请求的对象等。
添加异步请求监听器:
为发送的心跳请求添加监听器。监听器在成功接收到心跳响应时,会调用
heartbeat.receiveHeartbeat()方法,将heartbeatInFlight设置为false,表示本次心跳请求已经成功处理,可以准备发送下一次心跳。
小结
HeartbeatThread 的 run() 方法通过上述步骤持续监控和发送心跳请求,确保消费者与 GroupCoordinator 之间的连接稳定。这一机制不仅能及时检测消费者的状态,还能有效处理可能的故障情况,从而维护 Kafka 消费组的正常运行。
好的,下面用一个具体的例子来说明 HeartbeatThread 的 run() 方法中的心跳机制如何在 Kafka 消费者中工作。
场景示例:Kafka 消费者的心跳机制
假设我们有一个 Kafka 消费者,它正在消费一个名为 orders 的主题,并且它的状态已经转变为 Completing_Rebalance。这个消费者现在需要通过心跳来保持与 GroupCoordinator 的联系。
步骤详解
开启心跳线程:
消费者处于
Completing_Rebalance状态,因此心跳线程开始运行。
验证加入状态:
HeartbeatThread检查消费者是否已经成功加入消费组。如果消费者尚未加入,它会等待加入完成。假设消费者已经成功加入,继续执行后续步骤。
查找
GroupCoordinator:coordinatorUnknown()方法被调用。如果消费者没有找到GroupCoordinator,心跳线程会阻塞,直到找到为止。假设消费者成功找到了
GroupCoordinator,继续执行。
检查心跳超时:
调用
heartbeat.sessionTimeoutExpired(now),检查上次心跳是否超时。假设上次心跳是在 3 秒前发送的,而GroupCoordinator的心跳超时时间设定为 5 秒,检查通过,继续。
检查请求超时:
HeartbeatThread评估当前的网络状况,判断心跳请求的发送是否超时。如果在网络中出现问题,消费者可能会选择退出消费组。假设一切正常,没有超时。
判断是否发送心跳:
检查心跳间隔时间,假设上次心跳是在 1 秒前发送的,而心跳间隔设定为 2 秒。由于时间尚未到,心跳线程阻塞 100 毫秒后再进行检查。
经过 100 毫秒,时间到了,继续发送心跳。
更新心跳属性:
更新最后一次发送心跳的时间为当前时间,并将
heartbeatInFlight设置为true,表示正在发送心跳。
准备发送心跳请求:
构造心跳请求对象,比如
HeartbeatRequest,准备发送给GroupCoordinator。
添加异步请求监听器:
为这个心跳请求添加监听器,监听器负责处理响应。当收到心跳成功的响应时,调用
heartbeat.receiveHeartbeat()方法,将heartbeatInFlight设置为false,表示心跳请求已成功完成。
结果
通过这样的机制,消费者可以保持与 GroupCoordinator 的活跃联系,确保自己在消费组中的状态被正确识别。若出现网络问题或消费者长时间未发送心跳,GroupCoordinator 将会认为该消费者已经宕机,进而触发重平衡机制,确保消费组的稳定性和可靠性。
总结
通过这个例子,可以清楚地看到 HeartbeatThread 是如何在 Kafka 中保持消费者与 GroupCoordinator 的活跃联系,以及如何通过各种判断确保心跳的稳定发送。这样一来,Kafka 的消费者就能够有效地管理自己的状态,及时响应网络或节点的变化。
这里我们在看一下第八步的详情:发送心跳请求的准备工作都做了什么?
sendHeartbeatRequest()
具体源码如下:
synchronized RequestFuture<Void> sendHeartbeatRequest() {
log.debug("Sending Heartbeat request with generation {} and member id {} to coordinator {}",
generation.generationId, generation.memberId, coordinator);
//封装心跳请求
HeartbeatRequest.Builder requestBuilder =
new HeartbeatRequest.Builder(new HeartbeatRequestData()
.setGroupId(rebalanceConfig.groupId)
.setMemberId(this.generation.memberId)
.setGroupInstanceId(this.rebalanceConfig.groupInstanceId.orElse(null))
.setGenerationId(this.generation.generationId));
return client.send(coordinator, requestBuilder)
.compose(new HeartbeatResponseHandler(generation));
}
可以看到:主要工作是封装心跳请求HeartbeatRequest,并把请求预发送出去,同时配置回调对象,对应的回调类为HeartbeatResponseHandler。
我们这就看一下回调类中处理响应的核心方法 handle()。
handle()
具体源码如下:
public void handle(HeartbeatResponse heartbeatResponse, RequestFuture<Void> future) {
sensors.heartbeatSensor.record(response.requestLatencyMs());
Errors error = heartbeatResponse.error();
//1.正常响应,把成功响应的事件传播下去。
if (error == Errors.NONE) {
log.debug("Received successful Heartbeat response");
future.complete(null);
//2.找不到GroupCoordinator
} else if (error == Errors.COORDINATOR_NOT_AVAILABLE
|| error == Errors.NOT_COORDINATOR) {
log.info("Attempt to heartbeat failed since coordinator {} is either not started or not valid",
coordinator());
markCoordinatorUnknown(error);
future.raise(error);
//3.正在重平衡的过程中
} else if (error == Errors.REBALANCE_IN_PROGRESS) {
//3.1 如果是STABLE状态
if (state == MemberState.STABLE) {
log.info("Attempt to heartbeat failed since group is rebalancing");
//重新发送JoinGroupRequest,尝试加入GroupCoordinator。
requestRejoin();
future.raise(error);
//3.2 不是STABLE状态,就不用尝试加入GroupCoordinator,因为正在尝试加入。
} else {
log.debug("Ignoring heartbeat response with error {} during {} state", error, state);
future.complete(null);
}
//4.其他错误
//1).generationid过期。2).GroupCoordinator不能识别消费者的member_id。
//3).consumer 的instance_id重复。
} else if (error == Errors.ILLEGAL_GENERATION ||
error == Errors.UNKNOWN_MEMBER_ID ||
error == Errors.FENCED_INSTANCE_ID) {
if (generationUnchanged()) {
log.info("Attempt to heartbeat with {} and group instance id {} failed due to {}, resetting generation",
sentGeneration, rebalanceConfig.groupInstanceId, error);
resetGenerationOnResponseError(ApiKeys.HEARTBEAT, error);
future.raise(error);
} else {
log.info("Attempt to heartbeat with stale {} and group instance id {} failed due to {}, ignoring the error",
sentGeneration, rebalanceConfig.groupInstanceId, error);
future.complete(null);
}
} else if (error == Errors.GROUP_AUTHORIZATION_FAILED) {
future.raise(GroupAuthorizationException.forGroupId(rebalanceConfig.groupId));
} else {
future.raise(new KafkaException("Unexpected error in heartbeat response: " + error.message()));
}
}
}
其大体步骤可总结为如下。
第一步,如果是正常响应,就调用future.complete()把事件传播出去,这样就会调用future上定义的方法onSuccess()。
第二步,如果响应报出找不到GroupCoordinator的错误,就报出相应的日志。
第三步,如果响应报出消费组正在重平衡的错误,会做进一步的分析:
如果消费者显示是Stable状态,也就是正常工作的状态,就说明消费者的状态过时了需要调用重新加入消费组的方法requestRejoin()。
如果消费者不是Stable状态,就不用处理响应直接调用future.complete()把事件传播出去。因为消费者的状态也是重平衡中,和服务端响应的状态一致,可以忽略心跳的响应。
第四步,如果响应报出其他三类错误会做响应处理的,下面是这三类的错误。
generationid过期;
GroupCoordinator不能识别消费者的member_id;
consumer 的instance_id重复。
总结
今天这节课我给你讲解了消费组重平衡第三个阶段:同步消费组状态,就是leader consumer把制定好的所有消费者的分区方案发送给GroupCoordinator,然后GroupCoordinator再转发给各个消费者,同时还分析了从注册消费者到同步消费组状态这两个阶段的总体流程。
接下来又给你介绍了消费者和服务端GroupCoordinator之间的心跳,心跳主要作用是维持消费者对于GroupCoordinator的从属关系。
15.消费者订阅状态和 offset 操作
在 Kafka 中,消费者的订阅状态和 offset 操作是管理消息消费的关键部分。以下是对这两者的详细解释。
消费者订阅状态
订阅主题:
当消费者启动时,它需要订阅一个或多个主题,以便从这些主题中获取消息。订阅可以通过调用
subscribe()方法实现。例如,
consumer.subscribe(Arrays.asList("topic1", "topic2"));订阅了topic1和topic2。
消费者组:
消费者属于一个消费组,消费组是由一个或多个消费者组成的,负责消费一个或多个主题中的消息。
每个消息在一个主题的每个分区中只会被同一消费组中的一个消费者消费,这样可以实现负载均衡。
状态管理:
消费者的状态在消费过程中可能会发生变化,包括:
加入消费组:当消费者启动并注册到
GroupCoordinator时,状态变为已加入。重平衡:当消费组内的消费者变化(如新消费者加入或已有消费者退出)时,会触发重平衡,消费者的分区分配可能会重新调整。
离开消费组:当消费者主动调用
unsubscribe()或者因故障下线时,状态变为已退出。
Offset 操作
Offset 概念:
Offset 是 Kafka 中每条消息的唯一标识,表示消息在分区中的位置。消费者通过 offset 来跟踪已消费的消息。
每个分区的 offset 是独立的,且 offset 是顺序递增的。
提交 Offset:
消费者在处理消息后需要提交 offset,以便下次消费时可以从上次消费的位置继续。提交 offset 可以是自动的或手动的:
自动提交:消费者可以配置
enable.auto.commit=true,Kafka 会自动提交 offset。自动提交的频率由auto.commit.interval.ms控制。手动提交:消费者在处理完消息后显式地调用
commitSync()或commitAsync()方法提交 offset。这种方式可以提供更大的灵活性和控制。
// 手动提交示例 try { // 处理消息 consumer.commitSync(); } catch (CommitFailedException e) { // 处理提交失败的情况 }管理 Offset:
Offset 的管理对于确保消息消费的准确性和效率至关重要。常见的管理策略包括:
提交当前处理的消息的 offset:确保消费者在处理完消息后再提交,避免重复消费或漏消费。
使用自定义 offset 管理:通过外部存储(如数据库)管理 offset,以实现更复杂的消费场景。
Offset 重置:
当消费者第一次启动或 offset 不存在时,Kafka 会根据配置决定如何处理。常用的配置有:
auto.offset.reset:earliest:从最早的消息开始消费。latest:从最新的消息开始消费。none:如果没有找到 offset,抛出异常。
小结
消费者的订阅状态和 offset 操作是 Kafka 消费者机制的核心组成部分。通过有效地管理订阅状态和 offset,消费者能够确保稳定、高效地消费消息,处理复杂的消费逻辑和异常情况。正确的 offset 提交策略和状态管理是实现数据一致性和高可用性的关键。
前面两节课我们讨论了消费者加入GroupCoordinator并获取到分区方案的源码。那么我们既然知道了消费者的分区是不是就能直接消费了呢?不是的,因为我们还不知道消费者的订阅状态信息,比如,消费者订阅的主题是否有变化,消费到分区的哪个offset了……这些订阅信息我们需要管理。
同时,根据我们前几节课讲到的消费组重平衡的原理,在消费者开始消费的过程中和Rebalance操作之前都要提交一次offset。在消费者刚开始消费某个partition的时候也需要获取分区的offset。这就涉及到了offset的提交和获取操作。
因此,这节课我们讨论消费者订阅状态和消费者如何提交和获取offset的。
在 Kafka 中,消费者的订阅状态和 offset 提交与获取操作是确保消息正确消费的关键部分。以下是对这些概念的详细讨论。
一、消费者订阅状态管理
订阅主题信息:
消费者在启动时会订阅一个或多个主题。每个主题的消息分布在多个分区中,消费者需要根据其订阅的信息进行消费。
订阅状态信息包括当前订阅的主题、分区及其对应的 offset。
状态变更监控:
在消费者运行期间,订阅的主题或分区可能会发生变化,例如添加或删除主题。消费者需要监控这些变化,以便进行相应的调整。
如果订阅状态发生变化,消费者可能需要重新分配分区并更新其内部的状态信息。
二、Offset 提交与获取操作
Offset 提交:
Offset 提交是指消费者在处理完消息后,向 Kafka 提交当前分区的 offset,以便在下一次消费时能够从上次处理的位置继续。
提交的方式可以是自动或手动:
自动提交:通过设置
enable.auto.commit=true,Kafka 会自动在指定的间隔内提交当前的 offset。这种方式简单,但可能会导致重复消费或漏消费。手动提交:消费者在处理完消息后显式调用
commitSync()或commitAsync()提交 offset,提供了更大的灵活性。
// 示例:手动提交当前处理的 offset try { // 处理消息 consumer.commitSync(); } catch (CommitFailedException e) { // 处理提交失败的情况 }Offset 获取:
在消费者开始消费某个分区时,需要获取该分区的最新 offset。这通常在消费者首次启动时发生。
如果没有找到对应的 offset(例如,新消费者或 offset 被删除),Kafka 会根据
auto.offset.reset配置决定从哪个位置开始消费:earliest:从分区最早的消息开始消费。latest:从分区最新的消息开始消费。
// 示例:配置自动 offset 重置 Properties props = new Properties(); props.put("auto.offset.reset", "earliest");Offset 管理策略:
有效的 offset 管理策略能够避免消息重复消费或漏消费。消费者可以根据自己的需求实现不同的 offset 提交策略。
常见策略包括:
在每次处理消息后提交 offset:确保处理完每条消息后再提交,降低重复消费的风险。
批量处理消息后提交:在处理一批消息后统一提交 offset,提升性能,但需要谨慎处理批次中的错误。
三、总结
消费者的订阅状态和 offset 提交与获取操作是确保 Kafka 消息消费可靠性的基础。通过有效管理订阅状态和 offset,消费者能够准确跟踪已消费的消息位置,并在消费组重平衡或其他异常情况下维持消息的一致性与完整性。这对于实现高效、可靠的消息处理机制至关重要。
消费者订阅状态:SubscriptionState 类
Kafka消费者使用SubscriptionState类来保存消费者订阅的主题,并追踪TopicPartition与offset的对应关系。这里,我们需要学习一下 SubscriptionState 类的字段和方法。
字段
public class SubscriptionState {
private static final String SUBSCRIPTION_EXCEPTION_MESSAGE =
"Subscription to topics, partitions and pattern are mutually exclusive";
private final Logger log;
//表示订阅Topic的模式,分四类:
private enum SubscriptionType {
NONE, //初始值。
AUTO_TOPICS, //按指定的Topic进行订阅,自动分配分区。
AUTO_PATTERN, //按正则表达式匹配的topic进行订阅,自动分配分区。
USER_ASSIGNED //用户自己定制消费者要消费的topic和分区。
}
private SubscriptionType subscriptionType;
//用来过滤topic的正则表达式
private Pattern subscribedPattern;
//用户手动写的要订阅的topic
private Set<String> subscription;
//消费组订阅的所有topic
private Set<String> groupSubscription;
//记录消费者里主题分区的状态集合。
private final PartitionStates<TopicPartitionState> assignment;
private final OffsetResetStrategy defaultResetStrategy;
private ConsumerRebalanceListener rebalanceListener;
private int assignmentId = 0;
SubscriptionType:枚举类。表示订阅Topic的模式,有以下四类。
NONE:初始值。
AUTO_TOPICS:按指定的Topic进行订阅,自动分配分区。
AUTO_PATTERN:按正则表达式匹配的topic进行订阅,自动分配分区。
USER_ASSIGNED:用户自己指定消费者要消费的topic和分区。
subscribedPattern:用来过滤主题的正则表达式。符合这个正则表达式的主题都会成为订阅主题。subscription:Set集合。用户手动指定的订阅主题。groupSubscription:消费组订阅的所有topic。当这个消费者被服务端groupCoordinator选为leader consumer的时候,这个字段是消费组所有消费者订阅的主题,用于监控消费组主题相关的元数据的变化,以满足消费组重平衡时为消费组制定分区方案的需要。而如果是follower consumer,由于不涉及为消费组全体消费者指定分区方案,这个字段只会保存本消费者订阅的主题。assignment:记录消费者里主题分区的状态集合。集合元素是TopicPartitionState,记录着每一个主题分区的消费情况,包括消费到分区的哪个位置了。defaultResetStrategy:默认重置策略。所谓重置策略就是当消费者重启的时候会使用什么策略进行消费,消费策略有两种:LATEST,从分区最后位置消费;EARLIEST,从分区最一开始的位置消费。rebalanceListener:ConsumerRebalanceListener类的对象。用于监听重平衡后消费者要消费的分区的变化。
方法
类的方法都比较简单,这里我就挑选其中一个方法给你讲解一下。
subscribe(),这个方法功能是用户指定要订阅的主题。
public synchronized boolean subscribe(Set<String> topics, ConsumerRebalanceListener listener) {
registerRebalanceListener(listener);
setSubscriptionType(SubscriptionType.AUTO_TOPICS);
return changeSubscription(topics);
}
首先,配置监控重平衡事件的监听器;然后设置订阅分区类型为AUTO_TOPICS,也就是自动配置分区;最后,配置要订阅的主题。
好,订阅状态基本讲完了,下面讲解 offset 的提交和获取。
消费者提交和获取 offset
前面几节课我们学习消费组的重平衡的时候,我们提到在重平衡消费组之前,消费者要向从属的Group Coordinator提交offset记录当前消费的位置。其实不仅仅是重平衡这个场景要提交offset,消费组在正常消费的过程中也是要向服务端提交offset的,因为如果消费者挂掉了,别的消费者会根据分区现在的offset继续消费。
消费者提交 offset
我们先了解一下 OffsetCommitRequest 和 OffsetCommitResponse 的消息体格式。
OffsetCommitRequest 消息体格式示意图如下:
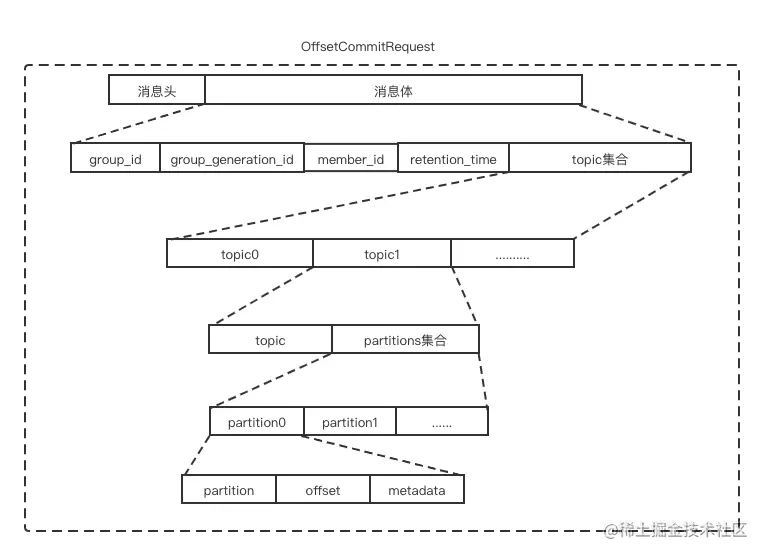
其各字段含义如下表:
OffsetCommitResponse 消息体格式如下示意图:
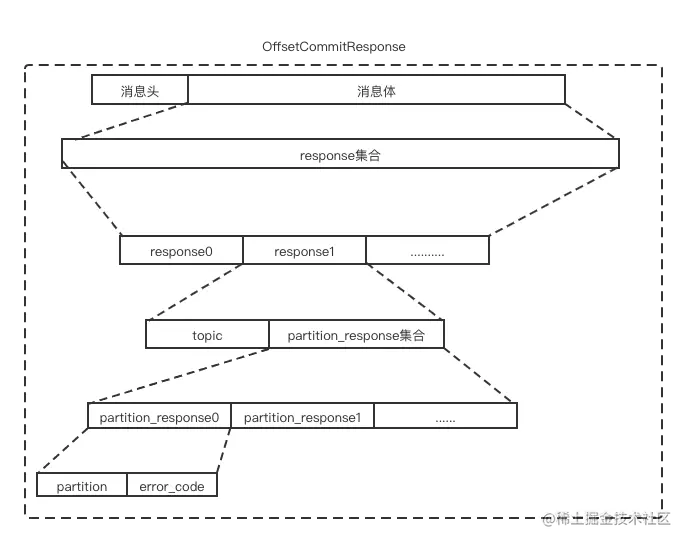
其各字段含义如下表:
接下来,我们重点说说提交offset涉及的相关方法。提交offset有两个。
一个是异步提交。异步提交是指业务线程提交offset的时候不用等待服务端发来的响应,业务线程可以继续做接下来的工作,而响应结果由回调对象处理。好处是:由于线程没有阻塞,提升线程的并发度有所提升。但是如果线程后面的逻辑对于消费者是否成功消费敏感就不适用了。
另一个是同步提交。与异步提交相反,业务线程必须等待offset提交完才能往下执行。这种场景会造成线程的阻塞,影响线程的并发性,但是适用于线程后面的逻辑对消费者是否成功消费敏感。
这节课我们只讨论异步提交的方法,同步提交的逻辑差不多,你可以自己学习。
我们首先看一下上次逻辑调用自动提交offset的入口方法maybeAutoCommitOffsetsAsync():
public void maybeAutoCommitOffsetsAsync(long now) {
//是否开启了偏移量。
if (autoCommitEnabled) {
//记录当前提交偏移量的时间,目的是为了计时。
nextAutoCommitTimer.update(now);
//超时判断,超时时间是autoCommitIntervalMs。
if (nextAutoCommitTimer.isExpired()) {
//重置下次过期时间
nextAutoCommitTimer.reset(autoCommitIntervalMs);
doAutoCommitOffsetsAsync();
}
}
}
首先根据参数autoCommitEnabled判断是否是自动提交,autoCommitEnabled对应配置文件的参数是auto.commit.interval.ms,默认是5000ms。如果是自动提交就更新提交偏移量的时间,然后判断当定时器过时的时候重置下次提交offset的时间,最后调用方法doCommitOffsetsAsync()。
我们继续看一下对应的方法 doCommitOffsetsAsync() 的源码:
private void doCommitOffsetsAsync(final Map<TopicPartition, OffsetAndMetadata> offsets, final OffsetCommitCallback callback) {
//1.创建并缓存OffsetCommiteRequest请求
RequestFuture<Void> future = sendOffsetCommitRequest(offsets);
//2.得到回调对象
final OffsetCommitCallback cb = callback == null ? defaultOffsetCommitCallback : callback;
//3.给异步请求加监听器。
future.addListener(new RequestFutureListener<Void>() {
@Override
public void onSuccess(Void value) {
if (interceptors != null)
interceptors.onCommit(offsets);
//把完成的offset提交加到完成队列中
completedOffsetCommits.add(new OffsetCommitCompletion(cb, offsets, null));
}
@Override
public void onFailure(RuntimeException e) {
Exception commitException = e;
if (e instanceof RetriableException) {
commitException = new RetriableCommitFailedException(e);
}
completedOffsetCommits.add(new OffsetCommitCompletion(cb, offsets, commitException));
if (commitException instanceof FencedInstanceIdException) {
asyncCommitFenced.set(true);
}
}
});
}
还是简单说说这个方法的步骤。
第一步,调用方法sendOffsetCommitRequest()创建OffsetCommiteRequest请求,并把请求缓存到ConsumerNetworkClient的unsent集合里。
第二步,获取完成提交offset的回调对象。
第三步,给异步请求加监听器,值得注意的是,跟前面一些异步请求的监听器不同。这里的监听器对应成功的响应的处理是把回调方法放到一个队列里让上层逻辑调用。
好,我们再分析一下创建并缓存OffsetCommiteRequest请求的方法 sendOffsetCommitRequest()。
RequestFuture<Void> sendOffsetCommitRequest(final Map<TopicPartition, OffsetAndMetadata> offsets) {
if (offsets.isEmpty())
return RequestFuture.voidSuccess();
//1.获取 Group Coordinator。
Node coordinator = checkAndGetCoordinator();
if (coordinator == null)
return RequestFuture.coordinatorNotAvailable();
//开始创建offset提交的请求。
//2.创建要发送的key为主题,value为这个主题下的分区要提交offset信息 的map集合,
Map<String, OffsetCommitRequestData.OffsetCommitRequestTopic> requestTopicDataMap = new HashMap<>();
for (Map.Entry<TopicPartition, OffsetAndMetadata> entry : offsets.entrySet()) {
......忽略
//3.填充集合
requestTopicDataMap.put(topicPartition.topic(), topic);
}
final Generation generation;
//4.如果是自动分配分区方案
if (subscriptions.hasAutoAssignedPartitions()) {
generation = generationIfStable();
// 如果generation为空,就认为这个消费者没有加入一个激活的消费组。
// 要做的事情是提交offset失败,然后让消费者重新加入组。
if (generation == null) {
log.info("Failing OffsetCommit request since the consumer is not part of an active group");
if (rebalanceInProgress()) {
//如果消费者在重平衡的过程中,那么就返回正在重平衡的异常
return RequestFuture.failure(new RebalanceInProgressException("Offset commit cannot be completed since the " +
"consumer is undergoing a rebalance for auto partition assignment. You can try completing the rebalance " +
"by calling poll() and then retry the operation."));
} else {
//如果消费者不在重平衡的过程中,那么就返回消费者不在激活的消费组异常。
return RequestFuture.failure(new CommitFailedException("Offset commit cannot be completed since the " +
"consumer is not part of an active group for auto partition assignment; it is likely that the consumer " +
"was kicked out of the group."));
}
}
//如果是指定消费分区就不考虑
} else {
generation = Generation.NO_GENERATION;
}
//5.构造提交offset的请求。
OffsetCommitRequest.Builder builder = new OffsetCommitRequest.Builder(
new OffsetCommitRequestData()
.setGroupId(this.rebalanceConfig.groupId)
.setGenerationId(generation.generationId)
.setMemberId(generation.memberId)
.setGroupInstanceId(rebalanceConfig.groupInstanceId.orElse(null))
.setTopics(new ArrayList<>(requestTopicDataMap.values()))
);
log.trace("Sending OffsetCommit request with {} to coordinator {}", offsets, coordinator);
//6.把请求保存在client的缓存中,同时配置回调对象。
return client.send(coordinator, builder)
.compose(new OffsetCommitResponseHandler(offsets, generation));
}
我再给你简单介绍一下这个方法的步骤。
第一步,获取 Group Coordinator。当Group Coordinator为null时,我们认为消费者连从属的Group Coordinator都找不到,那么提交offset就无从谈起了,于是返回Group Coordinator不可用的结果。
第二步,创建map集合requestTopicDataMap,里面的entry的key为主题,value为主题下分区的提交offset的信息。
第三步,填充集合requestTopicDataMap。
第四步,判断消费者的分区方案是自动的还是手动的。如果是自动的,要判断generation是否为空,如果为空我们认为消费者没有加入到活跃的group coordinator中,如果一个消费者没有加入到活跃的group coordinator中那么我们认为它的分区分配方案是有问题的。那么提交offset请求也应该拦截,对于提交offset请求的拦截有两个场景:
加入的消费组在重平衡过程中,这是我们可以把这种情况合并为消费组正在重平衡的异常,并抛出消费组正在重平衡的异常。
加入的消费组不在重平衡过程中,我们抛出提交offset的异常。
第五步,构建提交offset的请求。
第六步,把请求保存在client的缓存中,同时配置offset提交请求回调对象。
我们来看下,回调对象的类方法OffsetCommitResponseHandler.handle():
public void handle(OffsetCommitResponse commitResponse, RequestFuture<Void> future) {
sensors.commitSensor.record(response.requestLatencyMs());
Set<String> unauthorizedTopics = new HashSet<>();
//1.遍历已提交的所有offset的信息。
for (OffsetCommitResponseData.OffsetCommitResponseTopic topic : commitResponse.data().topics()) {
for (OffsetCommitResponseData.OffsetCommitResponsePartition partition : topic.partitions()) {
TopicPartition tp = new TopicPartition(topic.name(), partition.partitionIndex());
OffsetAndMetadata offsetAndMetadata = this.offsets.get(tp);
long offset = offsetAndMetadata.offset();
Errors error = Errors.forCode(partition.errorCode());
if (error == Errors.NONE) {
log.debug("Committed offset {} for partition {}", offset, tp);
} else {
......各种错误的处理
}
//
if (!unauthorizedTopics.isEmpty()) {
log.error("Not authorized to commit to topics {}", unauthorizedTopics);
future.raise(new TopicAuthorizationException(unauthorizedTopics));
} else {
//2.把成功提交的事件传播出去。
future.complete(null);
}
}
这个方法很简单,就是遍历提交offset请求的响应,如果有错误就根据错误类型分别处理,如何没有错误就把提交offset成功的事件传播出去。
消费者获取 offset
消费者获取offset的目的是获取新分配的分区的消费offset。比如,消费者刚刚启动后Group Coordinator给它分配了要消费的分区,但是消费者不知道从哪个offset消费。这就需要消费者向Group Coordinator发送请求获取分区对应的offset。
我们还是要先看下消费者获取offset的请求体和响应体。
请求体 OffsetFetch Request 如下图:
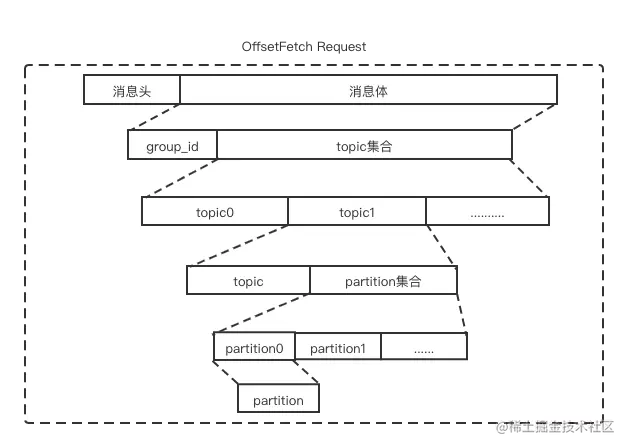
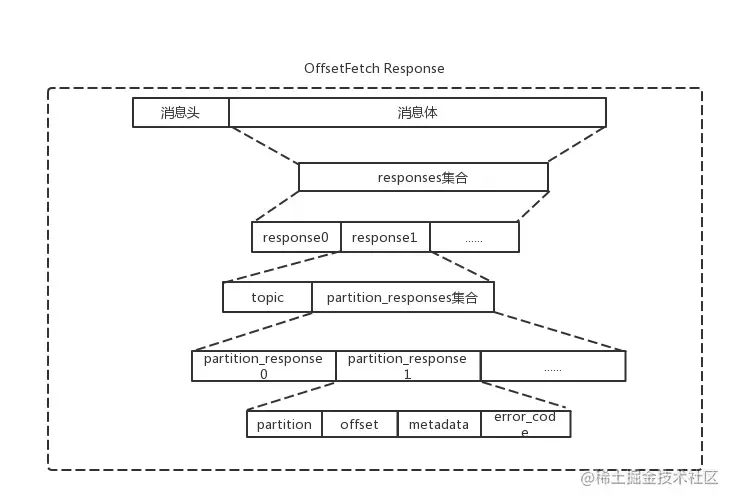
响应体 OffsetFetch Response 如下图:
然后我们学习获取offset的相关方法的源码。获取offset的方法还是在ConsumerCoordinator中,入口方法是refreshCommittedOffsetsIfNeeded():
public boolean refreshCommittedOffsetsIfNeeded(Timer timer) {
//1.获取处于初始化阶段的分区。
final Set<TopicPartition> initializingPartitions = subscriptions.initializingPartitions();
//2.向group coordinator阻塞发送获取offset的请求
final Map<TopicPartition, OffsetAndMetadata> offsets = fetchCommittedOffsets(initializingPartitions, timer);
if (offsets == null) return false;
//3.循环获取分区对应的offset
for (final Map.Entry<TopicPartition, OffsetAndMetadata> entry : offsets.entrySet()) {
final TopicPartition tp = entry.getKey();
final OffsetAndMetadata offsetAndMetadata = entry.getValue();
if (offsetAndMetadata != null) {
entry.getValue().leaderEpoch().ifPresent(epoch -> this.metadata.updateLastSeenEpochIfNewer(entry.getKey(), epoch));
//4.判断这个分区是否给这个消费者分配了。
if (this.subscriptions.isAssigned(tp)) {
final ConsumerMetadata.LeaderAndEpoch leaderAndEpoch = metadata.currentLeader(tp);
final SubscriptionState.FetchPosition position = new SubscriptionState.FetchPosition(
offsetAndMetadata.offset(), offsetAndMetadata.leaderEpoch(),
leaderAndEpoch);
//更新subscriptions对应的分区offset
this.subscriptions.seekUnvalidated(tp, position);
log.info("Setting offset for partition {} to the committed offset {}", tp, position);
} else {
log.info("Ignoring the returned {} since its partition {} is no longer assigned",
offsetAndMetadata, tp);
}
}
}
return true;
}
我们简单描述下该方法的步骤。
第一步,获得获取offset状态是初始化状态的分区集合,因为只有初始化状态的分区获取已提交offset才有意义。
第二步,调用方法fetchCommittedOffsets()向group coordinator发送获取offset的请求,并返回分区对应的已提交offset的map集合。
第三步,循环获取每个分区对应的offset元数据信息,更新subscriptions里分区已经提交的offset。
第四步,判断这个分区是否是消费者要消费的分区。因为如果重平衡后这个消费者不在消费这个分区,那就没有意义再更新分区的已提交offset了。
第五步,如果这个分区是消费者要消费的分区,就在subscriptions里更新分区已提交offset。
这里第二步中用于发送获取已提交offset请求的 fetchCommittedOffsets() 我需要再给你讲解一下,源码如下:
public Map<TopicPartition, OffsetAndMetadata> fetchCommittedOffsets(final Set<TopicPartition> partitions,
final Timer timer) {
if (partitions.isEmpty()) return Collections.emptyMap();
final Generation generationForOffsetRequest = generationIfStable();
//1.判断是否已经发送过了同样的请求。
if (pendingCommittedOffsetRequest != null &&
!pendingCommittedOffsetRequest.sameRequest(partitions, generationForOffsetRequest)) {
pendingCommittedOffsetRequest = null;
}
do {
//2.判断Coordinator是否可用。
if (!ensureCoordinatorReady(timer)) return null;
final RequestFuture<Map<TopicPartition, OffsetAndMetadata>> future;
if (pendingCommittedOffsetRequest != null) {
future = pendingCommittedOffsetRequest.response;
} else {
//3.缓存获取offset的请求,并配置回调对象。
future = sendOffsetFetchRequest(partitions);
pendingCommittedOffsetRequest = new PendingCommittedOffsetRequest(partitions, generationForOffsetRequest, future);
}
//4.网络发送获取offset的请求。
client.poll(future, timer);
//5.阻塞等待响应处理完成。
if (future.isDone()) {
//把pendingCommittedOffsetRequest置为空,这样下个获取已提交offset的请求就能执行了
pendingCommittedOffsetRequest = null;
if (future.succeeded()) {
return future.value();
} else if (!future.isRetriable()) {
throw future.exception();
} else {
timer.sleep(rebalanceConfig.retryBackoffMs);
}
} else {
return null;
}
} while (timer.notExpired());
return null;
}
简单描述下发送请求的过程。
第一步,判断是否已经发送过了同样的请求。因为有可能已经发送了获取已提交offset的请求但还没有返回。如果为ture,我们就把pendingCommittedOffsetRequest赋值为null。判断为ture的条件是下面两个条件必须同时满足:
pendingCommittedOffsetRequest != null :pendingCommittedOffsetRequest不为空。pendingCommittedOffsetRequest是正在获取但还没返回的已提交offset的请求。
!pendingCommittedOffsetRequest.sameRequest(partitions, generationForOffsetRequest):判断现在的请求是否和上次的一样。
第二步,确保Group Coordinator是否可用,如果可用直接返回,如果不可用就要查找Group Coordinator并创建连接。
第三步,根据pendingCommittedOffsetRequest的值是否为空采用不同的处理逻辑。如果不为空,说明跟上次的请求是一个请求,就不用再发送网络请求了,直接把上个请求future赋给现在的请求future。如果为空,我们再缓存获取offset的请求,并配置回调。
第四步,网络发送获取已提交offset的请求。
第五步,阻塞等待已提交offset的请求的响应。如果future完成了,则pendingCommittedOffsetRequest置为null。这样下个相同获取已提交offset的请求就不用在缓存获取offset的请求了。
好,讲完了发送消息,我们再来看一下处理响应的回调方法的代码,回调方法是OffsetFetchResponseHandler类的handle()方法。具体步骤是处理错误响应。构建分区和已提交offset的map集合offsets。最后如果响应正常的话就调用future.complete(offsets)完成异步请求。
总结
这节课我给你详细讲解了消费者的订阅状态。消费者的订阅状态保存的是订阅的主题,同时维护着订阅主题下所有分区以及分区对应的已提交offset的集合。我们还介绍了消费者提交和获取已提交offset,消费者提交和获取已提交offset都是要和服务端Group Coordinator发送通信。我们分析了消费者提交offset请求和获取已提交offset请求的请求体和响应体,还有发送请求的方法和处理响应的回调方法。
下节课我们继续讲解消费者如何从 broker 获取消息的内容。
明白了,您这节课主要讲解了消费者的订阅状态以及offset的提交和获取机制,并且提到了这些操作是如何与Group Coordinator进行交互的。下面我来总结一下关键点,并进一步解析消费者提交offset请求、获取已提交offset请求的请求体(Request)和响应体(Response),以及相关的方法和回调。
消费者的订阅状态
订阅的主题:指定了消费者想要消费哪些主题的消息。
分区信息:对于每个订阅的主题,Kafka会将该主题下的分区分配给消费者。
已提交的Offset集合:记录了每个分区最后提交的偏移量,这样在重新启动或发生重平衡后,可以继续从上次中断的地方开始消费。
Offset的提交与获取
提交Offset (Commit Offset)
自动提交:通过设置
enable.auto.commit=true来启用,Kafka定期为消费者自动提交偏移量。手动提交:
commitSync():同步方式提交,直到偏移量被成功提交才会返回。commitAsync():异步方式提交,立即返回,但可以通过提供一个回调函数来处理提交结果。
获取Offset (Fetch Committed Offset)
在消费者开始拉取消息之前,它需要知道上一次提交的偏移量是从哪里开始消费。如果启用了自动提交并且有可用的偏移量,则使用这些值;否则根据
auto.offset.reset策略决定。
请求体和响应体
当消费者与Group Coordinator通信时,涉及到具体的协议消息格式:
OffsetCommitRequest:
请求体包含:group_id, topic-partition列表及对应的offsets。
响应体包括:每个topic-partition对的错误码,指示提交是否成功。
OffsetFetchRequest:
请求体包含:group_id, topic-partition列表。
响应体包括:每个topic-partition对及其对应的最新提交的offset。
方法与回调
发送请求的方法:例如
send(OffsetCommitRequest)用于发送偏移量提交请求。处理响应的回调方法:如
onCompletion(OffsetCommitResponse, Exception)用来处理提交结果,检查是否有错误发生。
通过这些机制,Kafka能够有效地管理和跟踪消费者的进度,确保即使在消费者重启或网络问题等情况下也能正确地恢复消费过程。这种设计保证了系统的可靠性和数据的一致性。如果您希望深入探讨某个特定方面或者有更多具体的问题,请告诉我!