10.Kafka是如何封装网络层的(下)
Apache Kafka 是一个分布式的流处理平台,它使用了Java NIO(非阻塞I/O)来实现高效的网络通信。在上一讲中,你们讨论了Kafka如何封装了SocketChannel和Buffer等NIO组件。现在我们将继续探讨Kafka对Selector的封装。
在Java NIO中,Selector是多路复用器,它允许单个线程管理多个通道(channel)。通过注册感兴趣的I/O事件(如读、写),当这些事件发生时,Selector会通知应用程序,这样就可以有效地利用CPU资源,避免为每个连接创建单独的线程。
在Kafka中,org.apache.kafka.common.network.Selector是对标准Java NIO Selector的一个更高层次的封装。这个自定义的Selector类提供了以下功能:
管理多个网络连接:它可以同时监听多个
SocketChannel,并在有数据可读或可写时进行处理。简化编程模型:Kafka的
Selector提供了一种更简洁的方式来处理网络事件,隐藏了底层NIO的一些复杂性。异步处理:支持异步I/O操作,这意味着即使在网络延迟的情况下,服务器也能继续处理其他任务。
定时任务:可以安排定时任务,比如超时检查或者定期发送心跳包。
错误处理:封装了异常处理逻辑,确保在网络出现问题时能够优雅地处理。
负载均衡:根据当前的工作负载动态调整资源分配。
扩展点:提供了插件机制,允许用户自定义网络处理器来处理特定的协议。
在Kafka内部,Selector通常与NetworkClient一起工作,后者负责管理与集群中其他节点的连接,并且通过Selector来执行实际的数据传输。Selector还负责处理来自客户端的请求以及向客户端发送响应。
当你查看Kafka源码中的org.apache.kafka.common.network.Selector类时,你会看到它是如何围绕Java NIO的Selector构建起来的,并添加了额外的功能以满足Kafka的需求。这包括但不限于:
创建并管理
SelectionKey。处理不同类型的I/O事件。
与
TransportLayer交互来处理数据的序列化和反序列化。提供钩子函数来允许外部代码参与到事件循环中。
总之,Kafka的Selector是一个强大的工具,它帮助Kafka实现了高性能的消息传递系统。如果你想要深入了解具体的实现细节,建议直接查阅Kafka的源代码和官方文档。
在上一讲我们讲解了Kafka对JavaNIO组件SocketChannel、Buffer的封装,这一讲我们继续讲解Kafka对JavaNIO组件Selector的封装,封装后的组件是org.apache.kafka.common.network.Selector。
注意: Selector 类的包名是 org.apache.kafka.common.network,不是 Java NIO 下的那个 Selector 类,不要混淆。为了方便,下文我会用 KSelector 来表示org.apache.kafka.common.network.Selector。
不过,在正式开讲之前,我想先和你分享一个我之前的经历。记得有一次,我和我的团队遇到了这样一个问题,业务高峰的时候消息的收发量变得很大,这个时候会出现生产或消费消息延迟的情况,后来我们检查了JVM、带宽、内存、CPU等都没发现问题,只好紧急扩容才勉强解决了这个问题。但是问题依然没找到根源,后来我们对Kafka源码中网络连接的代码进行了研究,发现TCP中SO_SNDBUF、SO_RCVBUF对应的Kafka的参数socket.send.buffer.bytes和socket.receive.buffer.bytes的设置还是默认的100K,我将其调成1M后,延迟问题得到了很大的改善。所以,对Kafka源码的研究真的会非常有利于我们日常的开发工作。
好了,言归正传,我们这就开始今天对KSelector 的讲解。
字段
KSelector这个类包含的字段比较多,这里我结合相关代码把其中比较重要的字段给你解释下。
public class Selector implements Selectable, AutoCloseable
{
//java nio中用来监听网络I/O事件
private final java.nio.channels.Selector nioSelector;
// key:node,value:KafkaChannel。kafka保存和管理这个key-value键值对
private final Map<String, KafkaChannel> channels;
private final Set<KafkaChannel> explicitlyMutedChannels;
private boolean outOfMemory;
//发送完成的Send集合
private final List<Send> completedSends;
//已经完全接收的请求集合
private final LinkedHashMap<String,NetworkReceive>completedReceives;
//立即就连接上的选择键集合
private final Set<SelectionKey> immediatelyConnectedKeys;
private final Map<String, KafkaChannel> closingChannels;
private Set<SelectionKey> keysWithBufferedRead;
//断开连接集合
private final Map<String, ChannelState> disconnected;
//成功连接集合
private final List<String> connected;
//发送失败的请求
private final List<String> failedSends;
//构建KafkaChannel的工具类
private final ChannelBuilder channelBuilder;
//最大接收数据的字节数
private final int maxReceiveSize;
// 分配ByteBuffer的管理器
private final MemoryPool memoryPool;
可以看到,比较重要的字段有以下几个。
nioSelector:JavaNIO的Selector类的对象,负责监听网络IO事件。
channels:集合类型是Map<String,KafkaChannel>,key为NodeId,value是KafkaChannel,表示客户端到各个node的网络连接。
completedSends:请求对象的集合,集合类型是List。集合内的请求对象(Send)都是已经完成网络发送的。上一讲中我们已经讲过Send了,这里就不赘述了。
completedReceives:接收对象的集合,集合类型是LinkedHashMap<String,NetworkReceive>,key是KafkaChannelid,value是NetworkReceive类对象。集合内的value都是已经完成网络接收的NetworkReceive类对象。NetworkReceive上一讲中我们也讲过了,这里就不赘述了。
immediatelyConnectedKeys:立即就连接上的选择键集合。
disconnected:断开连接的集合。集合类型是Map<String,ChannelState>,key是KafkaChannelid,value是ChannelState,即KafkaChannel的状态。保存KafkaChannel状态是因为使用的时候要根据ChannelState判读处理逻辑。
connected:成功连接的集合。集合类型是List,元素是KafkaChannel的id。
failedSends:发送失败的请求集合。集合类型是List,元素是失败请求的channel id。
channelBuilder:用来构建KafkaChannel。
memoryPool:用来分配和回收ByteBuffer的内存池。
主要方法
接下来我们继续讲解 KSelector 这个类包含的方法,这个还是比较多的,主要包括 7 种:connect()、send()、write()、attemptWrite()、attemptRead()、poll() 和 pollSelectionKeys()。
学习这些方法既可以复习JavaNIO底层组件,还可以学到Kafka封装这些底层组件的方法和思想。Kafka对于有些底层Java类并不是直接使用的,而是根据需要自己进行封装和改进,这些我们在后面课程都会讲解。
connect()
connect() 是用于发起网络连接的方法,代码如下所示:
public void connect(String id, InetSocketAddress address,
int sendBufferSize, int receiveBufferSize) throws IOException {
//1.验证
ensureNotRegistered(id);
//2.创建SocketChannel
SocketChannel socketChannel = SocketChannel.open(); SelectionKey key = null;
try {
//3.配置socketChannel configureSocketChannel(socketChannel, sendBufferSize, receiveBufferSize);
// 4.发起一个连接,由于是非阻塞连接,方法会直接返回,但是不一定建立了正式的连接,
// 后面会通过KSelector.finishConnect()方法连接并确认是否连接成功
boolean connected = doConnect(socketChannel, address);
//5.将这个socketChannel注册到nioSelector上,并关注OP_CONNECT事件
key = registerChannel(id, socketChannel, SelectionKey.OP_CONNECT);
if (connected) {
//6.如果立即连接成功了,就取消对OP_CONNECT的监听
log.debug("Immediately connected to node {}", id);
immediatelyConnectedKeys.add(key);
key.interestOps(0);
}
} catch (IOException | RuntimeException e) {
if (key != null)
immediatelyConnectedKeys.remove(key);
channels.remove(id);
socketChannel.close();
throw e;
}
}
connect() 这个发起网络连接的过程大致可描述为如下 6 步。
验证这个连接是否已经在连接成功集合或正在关闭连接的集合里。如果在,就说明连接已经存在或关闭了,不应该再次连接。
创建一个SocketChannel,开始创建一个连接。
配置SocketChannel,包括配置非阻塞模式、设置长连接、设置SO_SNDBUF和SO_RCVBUF的大小。SO_SNDBUF、SO_RCVBUF表示内核发送和接收数据缓存的大小。
发起一个连接,由于是非阻塞连接,方法会直接返回,但是此时连接不一定已经建立了。当然,也有可能立即就连接上了,如果立即连接上返回值为true。
将这个socketChannel注册到nioSelector上,并关注OP_CONNECT事件。上一步没立即连接上,返回false,但是并不代表过一段时间就可以连接上了,所以要监听OP_CONNECT事件,连接上了再做处理。
如果立即连接成功了,就取消对OP_CONNECT的监听,因为已经完成了连接,没有必要再对OP_CONNECT监听了。
这段代码展示了如何使用 Java NIO 创建一个非阻塞的 SocketChannel 并尝试连接到指定地址。以下是代码逻辑的详细解析:
验证:
ensureNotRegistered(id);确保给定的 ID 尚未注册,以避免重复连接。
创建
SocketChannel:SocketChannel socketChannel = SocketChannel.open();打开一个新的SocketChannel用于网络通信。
配置
SocketChannel:configureSocketChannel(socketChannel, sendBufferSize, receiveBufferSize);配置SocketChannel的发送和接收缓冲区大小。
发起连接:
boolean connected = doConnect(socketChannel, address);使用doConnect方法来发起非阻塞连接。如果连接立即成功,则返回true;否则,方法会立即返回false,并且实际的连接过程将在后续处理中完成。
注册
SocketChannel到Selector:key = registerChannel(id, socketChannel, SelectionKey.OP_CONNECT);将SocketChannel注册到Selector上,并设置感兴趣的 I/O 操作为OP_CONNECT,这样当连接准备好时,Selector可以通知我们。如果连接立即成功(即
connected为true),则将该SelectionKey添加到immediatelyConnectedKeys中,并且移除对OP_CONNECT事件的兴趣,因为不再需要等待连接完成的通知。
异常处理:
在
try块中的任何IOException或RuntimeException都会被捕获。如果发生异常,会取消之前的操作,如从集合中移除相关的SelectionKey和SocketChannel,并关闭SocketChannel。最后,抛出异常,以便调用者可以知道发生了错误。
这个 connect 方法是一个典型的异步连接过程。它允许程序在等待连接完成的同时继续执行其他任务。一旦 Selector 发现连接已经准备好(即 OP_CONNECT 事件触发),程序可以通过 KSelector.finishConnect() 来确认连接是否成功,并进行后续的数据交换。
这种设计模式非常适合高并发场景下的网络编程,因为它可以有效地复用线程资源,提高系统的吞吐量和响应速度。
send()
send()方法用于消息发送的时候把消息暂存在KafkaChannel的send字段里,然后等着Selector.poll()执行真正的发送,对应代码如下所示:
/** * 将创建的RequestSend对象缓存到KafkaChannel的send字段中,并开始关注
OP_WRITE事件,但并没有发送网络I/O,接下来的poll操作才是真正的发送网络I/0
* */
public void send(Send send) {
//1.获取channelId作为connectionId
String connectionId = send.destination();
//2.获取连接
KafkaChannel channel = openOrClosingChannelOrFail(connectionId);
//3.如果连接是关闭的,就把connectionId放到closingChannels集合里
if (closingChannels.containsKey(connectionId)) {
this.failedSends.add(connectionId);
} else {
try {
//4.把send放入KafkaChannel里,并监听写事件
channel.setSend(send);
} catch (Exception e) {
//5.更新KafkaChannel的状态为发送失败
channel.state(ChannelState.FAILED_SEND);
//6.把connectionId放入failedSends集合里
this.failedSends.add(connectionId);
//7.关闭连接
close(channel, CloseMode.DISCARD_NO_NOTIFY);
if (!(e instanceof CancelledKeyException)) {
log.error("Unexpected exception during send, closing connection {} and rethrowing exception {}",
connectionId, e);
throw e;
}
}
}
}
这个方法的步骤是这样的:
获取服务端的channelId作为connectionId;
获取连接,从channels或closingChannels找到对应的KafkaChannel;
如果closingChannels有这个KafkaChannel,说明连接还没有建立,则把send放到发送失败的集合里;
如果连接已经建立成功,就把发送数据保存在send字段里暂时缓存起来,等着Selector.poll()去使用;
如果出现异常,就把KafkaChannel的状态改为FAILED_SEND;
把connectionId放到发送失败的集合里;
KafkaChannel连接关闭。
write()
write()是selector.poll()调用的真正往网络I/O写数据的方法,数据是上面的方法send()填充的send字段,代码如下所示:
// 调用KafkaChannel执行写操作
void write(KafkaChannel channel) throws IOException {
//1.获取channel对应的节点id
String nodeId = channel.id();
//2.channel.write()将KafkaChannel.send字段发送出去,返回发出的字节数,一次写不一定能都写完
long bytesSent = channel.write();
//3.如果未完成发送返回null,并继续关注这个channel的写事件。如果发送完成,则返回send,并因为写完了取消对写事件的关注
Send send = channel.maybeCompleteSend();
if (bytesSent > 0 || send != null) {
long currentTimeMs = time.milliseconds();
if (bytesSent > 0)
this.sensors.recordBytesSent(nodeId, bytesSent,
currentTimeMs);
if (send != null) {
// 4.如果发送完成,send添加到completedSends
this.completedSends.add(send);
this.sensors.recordCompletedSend(nodeId, send.size(),
currentTimeMs);
}
}
}
这个方法的步骤可总结为如下的 4 步。
获取channel对应的节点id。
channel.write()将KafkaChannel.send字段发送出去,返回发出的字节数,一次发送不一定能发送完。
判断KafkaChannel.send字段的数据是否发送完毕:如果未完成发送,就返回null,并继续关注这个channel的写事件;如果发送完成,则返回send,并取消对写事件的关注。
发送完成后,把send添加到完成发送集合completedSends。
结合上述内容,我给你描述下发送数据的流程,如下图所示:
网络写数据的流程图
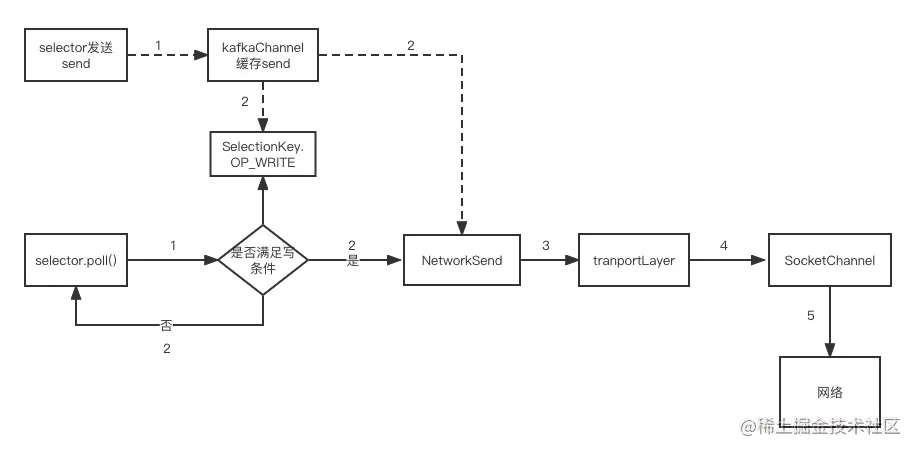
发送数据的准备工作:首先调用seletor的发送方法,然后把要发送的数据放到KafkaChannel类的send字段中,send字段实际上是NetworkSend的类对象。至此,发送结束,接下来等待真正的网络发送。
真正的网络发送:在seletor的poll()方法里,先判断是否满足网络发送的条件,如果不满足则等待下次再调用;如果满足就取得NetworkSend类对象的数据,然后通过transportLayer调用SocketChannel的相关方法实现真正的网络发送。
在 Apache Kafka 中,send() 方法通常用于将消息放入发送队列中,等待实际的网络 I/O 操作来完成消息的传输。这个过程涉及到 KafkaChannel 和 Selector 的协作。下面是对 send() 方法及其相关机制的解释:
send() 方法
send() 方法的主要职责是准备要发送的消息,并将其放置在一个合适的数据结构中(例如 KafkaChannel 的 send 字段),这样当 Selector 轮询时可以发现并执行实际的发送操作。
public void send(String id, RequestOrResponse request) throws IOException {
// 获取与指定ID关联的KafkaChannel
KafkaChannel channel = getChannel(id);
if (channel == null) {
throw new IOException("No channel found for " + id);
}
// 将请求添加到channel的发送队列
channel.add(request);
// 如果channel还没有注册写事件,则注册它
if ((channel.interestOps() & SelectionKey.OP_WRITE) == 0) {
channel.interestOps(channel.interestOps() | SelectionKey.OP_WRITE);
}
}KafkaChannel 结构
KafkaChannel 是一个抽象类,它封装了 SocketChannel 和相关的缓冲区,以及发送和接收队列。KafkaChannel 可能有以下关键属性:
send:一个队列或列表,用来暂存待发送的消息。receive:一个队列或列表,用来存放接收到的消息。state:表示通道的状态(如连接状态)。selectionKey:与Selector关联的SelectionKey。
Selector.poll()
Selector.poll() 是 Java NIO 中 Selector 类的一个方法,用于轮询一组通道上的就绪操作。在 Kafka 中,Selector.poll() 会检查哪些通道已经准备好进行读取、写入或其他 I/O 操作。对于发送操作,如果 KafkaChannel 注册了 OP_WRITE 事件,并且通道可写,那么就会触发发送逻辑。
public int poll(long timeout) throws IOException {
int readyChannels = selector.select(timeout);
if (readyChannels > 0) {
Set<SelectionKey> selectedKeys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = selectedKeys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (!key.isValid()) {
continue;
}
if (key.isWritable()) {
handleWrite(key);
} else if (key.isReadable()) {
handleRead(key);
} else if (key.isConnectable()) {
handleConnect(key);
}
keyIterator.remove(); // 防止重复处理
}
}
return readyChannels;
}
private void handleWrite(SelectionKey key) {
KafkaChannel channel = (KafkaChannel) key.attachment();
while (channel.hasPendingSends()) {
ByteBuffer buffer = channel.nextSendBuffer();
try {
channel.write(buffer);
} catch (IOException e) {
// 处理异常
}
}
if (!channel.hasPendingSends()) {
// 如果没有更多的数据要发送,取消对写事件的兴趣
channel.interestOps(channel.interestOps() & ~SelectionKey.OP_WRITE);
}
}在这个例子中,handleWrite 方法从 KafkaChannel 中获取下一个待发送的消息缓冲区,并尝试通过 write 方法发送数据。如果所有数据都已发送完毕,则取消对该通道的 OP_WRITE 事件的兴趣。
总之,send() 方法负责将消息加入到发送队列中,而 Selector.poll() 负责检测哪些通道已经准备好发送数据,并调用相应的方法来完成实际的 I/O 操作。这种设计允许 Kafka 在单个线程中高效地管理多个并发连接。
attemptWrite()
attemptWrite() 用于调用write()的上层方法,判断是否写数据,代码如下所示:
private void attemptWrite(SelectionKey key, KafkaChannel channel, long nowNanos) throws IOException { if (channel.hasSend() && channel.ready() && key.isWritable() && !channel.maybeBeginClientReauthentication(() -> nowNanos)) { write(channel); } }
可以看到,attemptWrite() 要想执行写操作,必须同时满足以下 4 个条件才可以调用write() 方法。
send不为空,也就是说有数据可以发;
channel连接正常;
网络写事件是可写状态;
客户端验证没有开启。
ttemptRead()
attemptRead() 用于调用read()的上层方法,代码如下所示:
private void attemptRead(KafkaChannel channel) throws
IOException {
String nodeId = channel.id();
//1.channel.read()方法从transportLayer中读取数据到NetworkReceive对象中
long bytesReceived = channel.read();
if (bytesReceived != 0) {
long currentTimeMs = time.milliseconds();
sensors.recordBytesReceived(nodeId, bytesReceived,
currentTimeMs);
madeReadProgressLastPoll = true;
//2.判断读出来的数据是否填满这个NetworkReceive类对象,如果没有读完一个完整的NetworkReceive,则下次触发读事件继续填充这个NetworkReceive对象;
//如果读取了一个完整的NetworkReceive对象,则将NetworkReceive置空,下次触发读操作时,
//创建新的NetworkReceive 对象
NetworkReceive receive = channel.maybeCompleteReceive();
//3.如果一个 NetworkReceive 读完了,就把这个NetworkReceive添加到completedReceives 队列里
if (receive != null) {
addToCompletedReceives(channel, receive, currentTimeMs);
}
}
if (channel.isMuted()) {
outOfMemory = true;
} else {
madeReadProgressLastPoll = true;
}
}
这里的执行步骤可总结为如下的 3 步。
channel.read()方法从transportLayer中读取数据到NetworkReceive对象中。
判断读出来的数据是否填满这个NetworkReceive类对象:如果并没有读完一个完整的NetworkReceive,则下次触发读事件继续填充;如果读取了一个完整的NetworkReceive对象,则将其置空,下次触发读操作时创建新的NetworkReceive 对象。
如果一个 NetworkReceive 读完了,就把这个NetworkReceive添加到completedReceives 队列里。
poll()
poll()方法是核心方法,获取已经准备好的网络IO事件,并做响应的操作,包括完成连接、读数据、写数据,代码如下所示:
public void poll(long timeout) throws IOException {
if (timeout < 0)
throw new IllegalArgumentException("timeout should be >= 0");
boolean madeReadProgressLastCall = madeReadProgressLastPoll;
//1.将上一次Poll()方法的结果全部清除掉
clear();
......忽略
//2. select线程阻塞等待IO事件
int numReadyKeys = select(timeout);
long endSelect = time.nanoseconds();
this.sensors.selectTime.record(endSelect - startSelect, time.milliseconds());
//3. 监控到事件 或 立即连接的集合不为空,或有读的数据在缓存里
if (numReadyKeys > 0 || !immediatelyConnectedKeys.isEmpty() ||
dataInBuffers) {
//4.取得准备就绪事件集合
Set<SelectionKey> readyKeys = this.nioSelector.selectedKeys();
......忽略
// 5.处理监听到准备好的IO事件
pollSelectionKeys(readyKeys, false, endSelect);
readyKeys.clear();
// 6.处理立即连接的事件 pollSelectionKeys(immediatelyConnectedKeys, true, endSelect);
immediatelyConnectedKeys.clear();
} else {
madeReadProgressLastPoll = true;
}
long endIo = time.nanoseconds();
this.sensors.ioTime.record(endIo - endSelect, time.milliseconds());
completeDelayedChannelClose(endIo);
maybeCloseOldestConnection(endSelect);
}
poll() 方法的执行步骤可总结为如下 6 步。
将上一次poll()方法产生的集合数据全部清除掉,包括completedSends、completedReceives、connected和disconnected。
select线程阻塞等待IO事件,这里的select指JavaNIO的类Selector的select(),具体就是线程阻塞直到某个或某几个网络IO事件准备好了。
判断是否处理网络事件,三个条件有一个满足就可以处理网络事件:①监听到事件发生;②立即连接成功的集合不为空;③缓存里有数据。其中“缓存里有数据”这一条件只有在SSL连接里面才可能是true,明文传输不用考虑。
获取监听到的已经准备好的事件集合。
处理准备好的事件,包括连接事件、网络读事件和网络写事件。
调用pollSelectionKeys()方法处理立即连接的选择键集合。这个集合的元素是一开始做连接动作的时候,就立即连接上了,然后把选择键放到这个集合里,等待poll()的处理。
pollSelectionKeys()
pollSelectionKeys()方法是具体处理监听到的事件的,包括连接事件、读事件和写事件,还有立即完成的连接,如下代码所示:
void pollSelectionKeys(Set<SelectionKey> selectionKeys,
boolean isImmediatelyConnected, long currentTimeNanos) {
//1.循环调用
for (SelectionKey key : determineHandlingOrder(selectionKeys)) {
KafkaChannel channel = channel(key);
long channelStartTimeNanos = recordTimePerConnection ? time.nanoseconds() : 0;
boolean sendFailed = false;
String nodeId = channel.id(); sensors.maybeRegisterConnectionMetrics(nodeId);
if (idleExpiryManager != null)
idleExpiryManager.update(nodeId, currentTimeNanos);
try {
//2.判断连接是否准备好了
if (isImmediatelyConnected || key.isConnectable()) {
//3.调用SocketChannel判断连接是否建立成功,建立后开始关注OP_READ事件并取消OP_CONNECT事件
if (channel.finishConnect()) {
this.connected.add(nodeId);
this.sensors.connectionCreated.record();
SocketChannel socketChannel = (SocketChannel) key.channel();
log.debug("Created socket with SO_RCVBUF = {}, SO_SNDBUF = {}, SO_TIMEOUT = {} to node {}",
socketChannel.socket().getReceiveBufferSize(), socketChannel.socket().getSendBufferSize(), socketChannel.socket().getSoTimeout(), nodeId);
} else {
continue;
//连接没有完成,下一轮再尝试
}
}
...... 忽略
//4.网络IO读是否准备好了
if (channel.ready() && (key.isReadable() ||
channel.hasBytesBuffered()) && !hasCompletedReceive(channel)
&& !explicitlyMutedChannels.contains(channel)) {
//5.处理读事件
attemptRead(channel);
}
......忽略
try {
// 6.处理写事件
attemptWrite(key, channel, nowNanos);
} catch (Exception e) {
sendFailed = true;
throw e;
}
if (!key.isValid())
close(channel, CloseMode.GRACEFUL);
} catch (Exception e) {
......忽略
} finally {
maybeRecordTimePerConnection(channel, channelStartTimeNanos);
}
}
}
可以看到,pollSelectionKeys() 方法的执行可总结为如下 6 个步骤。
轮询取出事件集合的事件。
判断是否处理连接事件。这里有两个判断条件:isImmediatelyConnected立即连接上了,或者key.isConnectable()连接事件准备好了。满足其中一个就认为要处理连接事件了。
调用SocketChannel的finishConnect()方法去看连接是否成功,如果连接成功了,就关注OP_READ事件并取消OP_CONNECT事件。因为连接成功后没必要再监听这个channel上的连接事件,并要做好接收数据的准备。
判断读操作是否准备好了。要同时满足3个条件才算读操作准备好了:①socketChannel准备好了,这里的“准备好了”是为SSL连接用的,对于明文连接都是True,所以我们不用关心;②读事件准备好了或channel里有缓存数据,channel里有缓存数据也是SSL连接特有的,明文连接都是False,也不用考虑;③NetworkReceive对象没有被读完,还要继续读。
如果读操作准备好了,就处理读事件。
处理写事件,attemptWrite()方法内部会判断写操作是否准备好了。
总结
这一讲我们学习了Kafka对最后一个NIO组件Selector的封装。KSelector把上一讲我们学到的知识全都串起来了。
我们先介绍了Selector如何进行网络连接、网络读、网络写的操作。其中,网络写是分两个步骤的:一个是预发送,即把要发送的数据放入对应KafkaChannel的send字段中;另一个是网络发送,即把KafkaChannel的send字段中的数据真正发送出去。真正使用的时候是两个线程分别执行的,这样做的好处是让业务线程发送数据和IO线程真正发送数据这两个动作实现解耦。然后,我们还详细讲解了通过调用 poll() 方法发起监听网络事件的操作,并进一步调用方法pollSelectionKeys()实现处理网络事件的流程。
总之,KSelector通过对底层JavaNIO的封装,达到了上层业务不用关心底层NIO组件的目的。
11. 消费者是如何同服务端通信的?
和学习生产者方法一样,我们先学习底层组件,然后再学习上层逻辑,自底向上的学习方法。这节课我们学习消费者负责通信的组件 ConsumerNetworkClient。下面是这节课的知识导图:
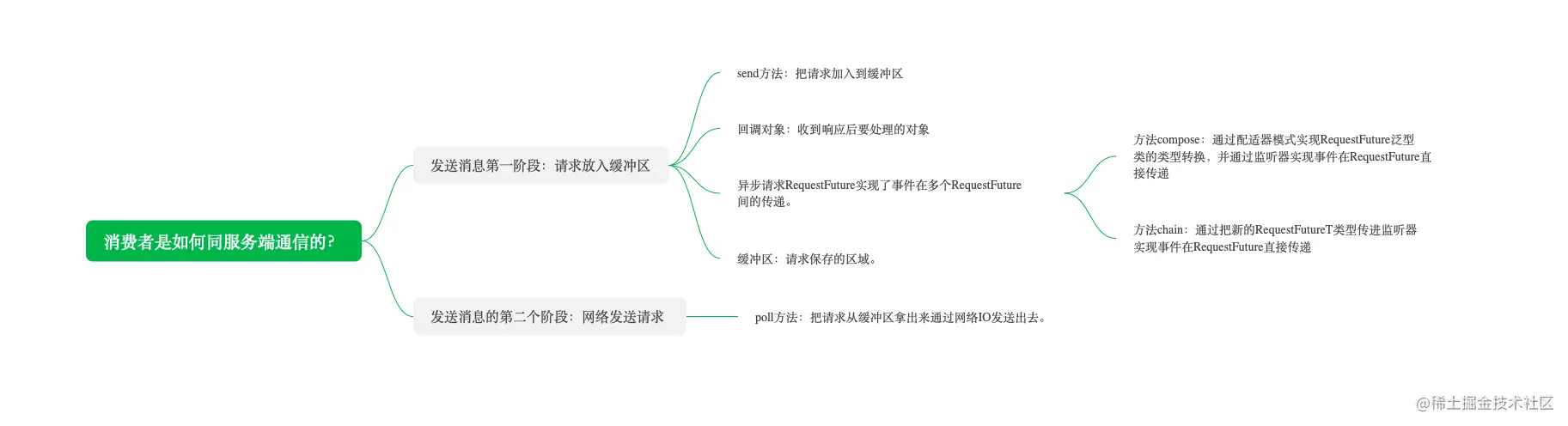
我们在学习生产者源码的时候了解到生产者的通信组件是NetworkClient,而消费者的通信层是在NetworkClient类之上又封装了一层。ConsumerNetworkClient类为上层业务提供了网络服务,包括拉取消息、维持心跳、与Consumer Coordinator交互的一系列请求都使用ConsumerNetworkClient完成网络交互。
ConsumerNetworkClient类是一个线程安全的类,通过锁的机制保障了线程安全。跟生产者发送消息一样,发送请求和真正的请求网络IO是解耦的,也是先发送到一个缓冲区,然后从缓冲区取出请求进行真正的网络发送。
确实,ConsumerNetworkClient 是 Kafka 消费者客户端中用于处理网络通信的核心组件。它建立在 NetworkClient 之上,并为消费者提供了更高级别的抽象和功能。下面是关于 ConsumerNetworkClient 的一些关键点:
ConsumerNetworkClient 的主要职责
消息拉取:从 Kafka 集群中拉取消息。
心跳维护:定期向 Kafka 集群发送心跳以维持会话活跃状态。
与 Coordinator 交互:处理与消费者协调器(Consumer Coordinator)的交互,包括组成员管理和偏移量提交等。
线程安全性
ConsumerNetworkClient 是线程安全的,因为它使用了锁机制来保证多线程环境下的正确性。这意味着多个线程可以同时调用 ConsumerNetworkClient 的方法而不会导致数据不一致或竞态条件。
请求缓冲区
类似于生产者的 NetworkClient,ConsumerNetworkClient 也将请求放入一个缓冲区中,而不是立即执行实际的网络 I/O。这样做的好处是:
解耦:将请求的创建与实际的网络 I/O 分离,使得系统更加灵活。
批量处理:允许累积多个请求后一次性发送,减少网络开销。
异步处理:可以在后台线程中处理网络 I/O,而不阻塞主线程。
工作流程
请求生成:消费者应用程序通过调用
ConsumerAPI 来生成请求,例如poll()或commitSync()。请求入队:这些请求被添加到
ConsumerNetworkClient的内部缓冲区中。轮询选择器:
ConsumerNetworkClient定期调用Selector.poll()方法来检查哪些通道已经准备好进行 I/O 操作。执行 I/O 操作:对于可写的通道,
ConsumerNetworkClient从缓冲区中取出请求并通过网络发送。处理响应:一旦收到响应,
ConsumerNetworkClient将其返回给消费者应用程序。
示例代码
下面是一个简化的 ConsumerNetworkClient 发送请求的示例:
public class ConsumerNetworkClient {
private final NetworkClient networkClient;
private final BlockingQueue<ClientRequest> requestQueue = new LinkedBlockingQueue<>();
private final ReentrantLock lock = new ReentrantLock();
private final Condition notEmpty = lock.newCondition();
public ConsumerNetworkClient(NetworkClient networkClient) {
this.networkClient = networkClient;
}
public void send(ClientRequest clientRequest, long now) {
// 将请求加入队列
lock.lock();
try {
requestQueue.put(clientRequest);
notEmpty.signalAll(); // 通知等待的线程
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException(e);
} finally {
lock.unlock();
}
}
public ClientResponse poll(long timeout, long now) {
lock.lock();
try {
while (requestQueue.isEmpty()) {
if (timeout < 0 || !notEmpty.await(timeout, TimeUnit.MILLISECONDS)) {
return null; // 超时或中断
}
}
// 从队列中获取下一个请求
ClientRequest request = requestQueue.poll();
if (request != null) {
// 通过NetworkClient发送请求
return networkClient.send(request, now);
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException(e);
} finally {
lock.unlock();
}
return null;
}
}在这个简化版本中,send() 方法将请求放入队列,并通过 notEmpty 信号来通知其他可能正在等待的线程。poll() 方法则负责从队列中取出请求并通过 NetworkClient 发送,如果队列为空,则会等待直到有新的请求到达或超时。
ConsumerNetworkClient 通过这种方式有效地管理了消费者的网络通信,确保了高效率和线程安全性。如果你想要深入理解其实现细节,建议查看 Kafka 的源码和相关文档。
ConsumerNetworkClient 是 Kafka 消费者客户端中的一个关键组件,它负责与 Kafka 集群进行网络通信。这个客户端是 Kafka 消费者 API 的一部分,用于从 Kafka 代理(Broker)接收消息。以下是 ConsumerNetworkClient 的一些关键功能和特性:
主要功能
发送请求:
ConsumerNetworkClient负责向 Kafka 代理发送各种请求,例如 Fetch 请求用于获取消息,OffsetCommit 请求用于提交偏移量等。
接收响应:
它处理从 Kafka 代理返回的响应,并将这些响应传递给消费者 API 的其他部分进行处理。
连接管理:
ConsumerNetworkClient管理与 Kafka 代理的连接,包括连接的建立、维护和关闭。
重试机制:
在网络通信失败时,
ConsumerNetworkClient提供了重试机制,以确保请求最终能够成功发送和处理。
线程安全:
ConsumerNetworkClient是线程安全的,可以在多线程环境中使用。
关键方法
send(RequestHeader header, ByteBuffer buffer): 发送一个请求到 Kafka 代理。poll(long timeoutMs): 轮询 Kafka 代理以获取响应。wakeup(): 唤醒正在阻塞的poll调用,通常用于优雅地关闭消费者。close(): 关闭ConsumerNetworkClient,释放所有资源。
使用场景
ConsumerNetworkClient 通常在 Kafka 消费者应用程序中使用,特别是在实现自定义的消费者逻辑时。例如,如果你需要更精细地控制消息获取和处理的过程,可能会直接使用 ConsumerNetworkClient。
示例代码
以下是一个简单的示例,展示了如何使用 ConsumerNetworkClient 发送 Fetch 请求并处理响应:
import org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient;
import org.apache.kafka.common.protocol.RequestHeader;
import org.apache.kafka.common.protocol.requests.FetchRequest;
import org.apache.kafka.common.protocol.responses.FetchResponse;
import java.nio.ByteBuffer;
import java.util.Collections;
import java.util.Properties;
public class CustomConsumer {
public static void main(String[] args) {
Properties props = new Properties();
// 配置 Kafka 消费者属性
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test-group");
ConsumerNetworkClient client = new ConsumerNetworkClient(props);
try {
// 创建 Fetch 请求
FetchRequest fetchRequest = new FetchRequest.Builder()
.addFetch("topic", 0, 0, 1024)
.build();
RequestHeader header = new RequestHeader(FetchRequest.FETCH_KEY, FetchRequest.VERSION_3);
ByteBuffer buffer = ByteBuffer.allocate(fetchRequest.sizeInBytes());
fetchRequest.writeTo(buffer);
// 发送请求
client.send(header, buffer);
// 轮询响应
while (true) {
FetchResponse response = (FetchResponse) client.poll(1000);
if (response != null) {
// 处理响应
System.out.println("Received messages: " + response.records());
break;
}
}
} finally {
client.close();
}
}
}这个示例展示了如何创建一个 ConsumerNetworkClient 实例,发送 Fetch 请求,并处理从 Kafka 代理返回的响应。
总结
ConsumerNetworkClient 是 Kafka 消费者客户端中的一个核心组件,负责与 Kafka 集群进行网络通信。通过使用 ConsumerNetworkClient,开发者可以实现自定义的消息获取和处理逻辑,以满足特定的业务需求。
类ConsumerNetworkClient的字段
我们先学习ConsumerNetworkClient类的字段。
//NetworkClient对象
private final KafkaClient client;
//缓冲队列,key是Node节点,value是发往此Node的ClientRequest集合。
private final UnsentRequests unsent = new UnsentRequests();
//消费者端Kafka集群元数据
private final Metadata metadata;
//重试退避时间
private final long retryBackoffMs;
//超时时间,默认5000ms
private final int maxPollTimeoutMs;
//请求超时时间,默认30000ms
private final int requestTimeoutMs;
private final AtomicBoolean wakeupDisabled = new AtomicBoolean();
private final ReentrantLock lock = new ReentrantLock(true);
private final ConcurrentLinkedQueue<RequestFutureCompletionHandler> pendingCompletion = new ConcurrentLinkedQueue<>();
private final ConcurrentLinkedQueue<Node> pendingDisconnects = new ConcurrentLinkedQueue<>();
private final AtomicBoolean wakeup = new AtomicBoolean(false);
client:KafkaClient类对象。负责网络连接。unsent:UnsentRequests类对象。UnsentRequests类提供了请求的缓冲区,类似于生产者的RecordAccumulator,但是没RecordAccumulator复杂。metadata:MetaData类的子类对象,这里是ConsumerMetadata类的对象。作用是缓存了消费者元数据。retryBackoffMs:失败重试退避时间。maxPollTimeoutMs:定义底层Selector.poll()方法的阻塞超时时间。requestTimeoutMs:请求超时时间。默认30000ms。请求是放到缓冲区的,但是长期在缓冲区中没有发送的请求应该处理掉。wakeupDisabled:bool类型。方法标记是否能唤醒Selector.poll()方法的阻塞。因为有的方法已经执行的情况下就没有必要再唤醒Selector.poll()方法的阻塞了,比如close()方法,因为网络IO已经要关闭了就没必要再唤醒。wakeup:bool类型。当有唤醒selector.poll()阻塞的操作时,就把这个值设为True。lock:ReentrantLock类的对象,用来保证类的线程安全。pendingCompletion:用来存储请求的回调对象的队列集合。响应回来后并不是直接调用回调对象里的回调方法,而是放到队列中等响应处理完了统一调用回调方法。
发送消息第一阶段:请求放入缓冲区
缓冲区存储的是要发送但还没有真正执行的网络请求。我们先看一下相关的方法源码。
ConsumerNetworkClient.send()方法如下:
public RequestFuture<ClientResponse> send(Node node,
AbstractRequest.Builder<?> requestBuilder,
int requestTimeoutMs) {
long now = time.milliseconds();
//1.初始化回调对象
RequestFutureCompletionHandler completionHandler = new RequestFutureCompletionHandler();
//2.构造请求对象
ClientRequest clientRequest = client.newClientRequest(node.idString(), requestBuilder, now, true,
requestTimeoutMs, completionHandler);
//3.把请求对象放入 unsent 集合里
unsent.put(node, clientRequest);
//4.唤醒处在阻塞过程中的selector.poll()方法,这样能对发送的请求发起网络请求。
client.wakeup();
return completionHandler.future;
}
第一步,初始化回调对象。
第二步,构造请求对象,参数包括要发送的节点、请求构造器、发送时间、是否期望有响应、请求超时时间、回调对象。
第三步,把要发送的node和请求对象放入unsent缓冲区里,等待发送。
第四步,唤醒处在阻塞过程中的selector.poll()方法,这样能及时发送缓冲区的请求。
回调对象
这里需要注意,RequestFutureCompletionHandler是回调对象,类图如下:
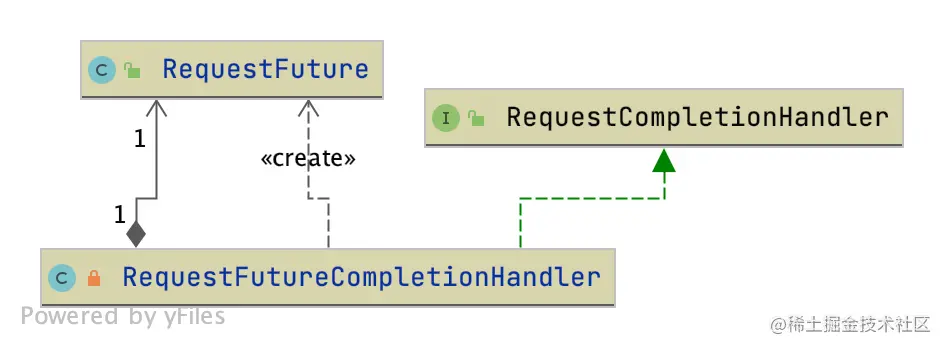
RequestFutureCompletionHandler继承了RequestCompletionHandler,这个接口也被生产者的请求回调继承了。RequestFuture给我们提供了异步请求。
我们看一下回调对象中对响应的处理代码:
public void onFailure(RuntimeException e) {
//获取异常并把回调对象放到pendingCompletion集合里
this.e = e;
pendingCompletion.add(this);
}
//成功时的处理
@Override
public void onComplete(ClientResponse response) {
//获取response并把回调对象放到pendingCompletion集合里
this.response = response;
pendingCompletion.add(this);
}
onFailure()是当响应异常时调用的方法,保存异常并把回调对象放入pendingCompletion集合里。
onComplete()是当响应成功时调用的方法,保存响应并把回调对象放入pendingCompletion集合里。
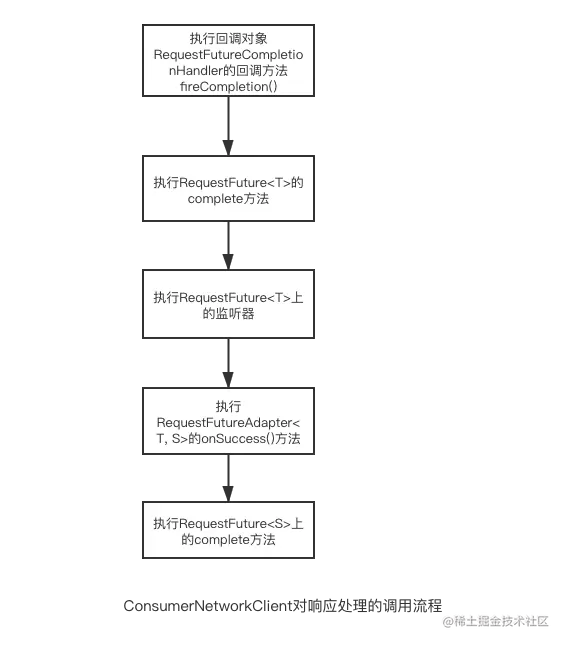
但是这两个方法都没有涉及到调用回调对象的动作,这个动作是fireCompletion()方法做的,源码如下:
public void fireCompletion() {
if (e != null) {
future.raise(e);
} else if (response.authenticationException() != null) {
future.raise(response.authenticationException());
} else if (response.wasDisconnected()) {
log.debug("Cancelled request with header {} due to node {} being disconnected",
response.requestHeader(), response.destination());
future.raise(DisconnectException.INSTANCE);
} else if (response.versionMismatch() != null) {
future.raise(response.versionMismatch());
} else {
future.complete(response);
}
}
如果有异常会调用RequestFuture<ClientResponse>的对象future的raise(e)方法处理,如果没有异常就调用complete(response)处理,我们这里只分析正常响应的处理,异常响应的处理是类似的。complete()方法主要调用了fireSuccess()方法去处理成功的响应。
好,我们接下来看看RequestFuture<T>的代码是如何处理异步请求的。
异步请求
先了解下RequestFuture<T>类的fireSuccess()方法。
private void fireSuccess() {
T value = value();
while (true) {
RequestFutureListener<T> listener = listeners.poll();
if (listener == null)
break;
listener.onSuccess(value);
}
}
这个方法取出所有的监听器并调用onSuccess()方法,也就是说回调对象对响应的处理归根结底还是要轮询调用RequestFuture<T>的监听器的相关方法。
那么我们再看看监听器是如何加到RequestFuture<T>上的,这涉及到RequestFuture<T>的两个方法:compose()和chain()。
首先是compose()方法的源码:
public <S> RequestFuture<S> compose(final RequestFutureAdapter<T, S> adapter) {
final RequestFuture<S> adapted = new RequestFuture<>();
//在当前RequestFuture添加监听器。
addListener(new RequestFutureListener<T>() {
@Override
public void onSuccess(T value) {
adapter.onSuccess(value, adapted);
}
@Override
public void onFailure(RuntimeException e) {
adapter.onFailure(e, adapted);
}
});
return adapted;
}
这个方法是利用适配器RequestFutureAdapter给当前的RequestFuture添加了监听器,并通过adapter实现了RequestFuture的泛型类型转换。
RequestFutureAdapter是适配器的抽象类,主要是定义了onSuccess()和onFailure()方法,这两个方法实现了RequestFuture的类型转换,从RequestFuture<F>到RequestFuture<>的类型转换。
public abstract class RequestFutureAdapter<F, T> {
public abstract void onSuccess(F value, RequestFuture<T> future);
public void onFailure(RuntimeException e, RequestFuture<T> future) {
future.raise(e);
}
}
这里的RequestFutureAdapter有什么用呢?生产者处理响应的时候为什么没有呢?
我在本节课开始讲了,ConsumerNetworkClient.send()方法的返回值是RequestFuture<ClientResponse>,显然这是个原始的响应,仅仅为上次业务提供最原始的异步请求。不管是消费者维持心跳、拉取消息等操作都会调用ConsumerNetworkClient.send()方法去发送请求,而对于响应的处理根据不同的业务也是不一样的,于是对于RequestFuture<T>中的T的类型的要求也是不一样的。在不改变ConsumerNetworkClient.send()方法返回类型前提下,而通过RequestFutureAdapter实现业务调用时得到不同的返回类型。
在 Apache Kafka 中,RequestFuture<T> 和 KafkaRequestFuture<T> 是用于处理异步请求的类。它们允许用户在发送请求后立即返回,而不需要等待响应。当响应到达时,可以通过回调函数(监听器)来处理结果。
RequestFuture 的 fireSuccess() 方法
fireSuccess() 方法的作用是当请求成功完成时,调用所有注册的监听器的 onSuccess 方法。下面是这个方法的简化版本:
private void fireSuccess() {
T value = value(); // 获取请求的结果
while (true) {
RequestFutureListener<T> listener = listeners.poll(); // 从队列中取出一个监听器
if (listener == null)
break; // 如果没有更多的监听器,则退出循环
listener.onSuccess(value); // 调用监听器的 onSuccess 方法,并传递结果
}
}添加监听器到 RequestFuture
为了将监听器添加到 RequestFuture<T>,Kafka 提供了两个主要的方法:compose() 和 chain()。这两个方法都允许你将新的监听器附加到现有的 RequestFuture<T> 上,但它们的行为有所不同。
compose()
compose() 方法允许你在当前 RequestFuture 的基础上构建一个新的 RequestFuture。新 RequestFuture 的结果取决于你提供的 Function 对象的输出。这使得你可以将多个异步操作链接在一起。
public <U> RequestFuture<U> compose(Function<RequestFuture<T>, RequestFuture<U>> mapper) {
final RequestFuture<U> composedFuture = new RequestFuture<>();
addListener(new RequestFutureListener<T>() {
@Override
public void onSuccess(T result) {
try {
RequestFuture<U> mappedFuture = mapper.apply(RequestFuture.this);
if (mappedFuture != null) {
composedFuture.complete(mappedFuture);
} else {
composedFuture.failure(new IllegalStateException("Mapper returned null"));
}
} catch (Throwable t) {
composedFuture.failure(t);
}
}
@Override
public void onFailure(RuntimeException e) {
composedFuture.failure(e);
}
});
return composedFuture;
}在这个例子中,compose() 接受一个 Function,该函数接收当前的 RequestFuture<T> 并返回一个新的 RequestFuture<U>。当当前的 RequestFuture 成功或失败时,它会调用 Function 并将结果设置为新的 RequestFuture 的结果。
chain()
chain() 方法允许你直接向 RequestFuture 添加一个监听器。这个监听器会在 RequestFuture 完成时被调用,无论是成功还是失败。
public RequestFuture<T> chain(RequestFutureListener<T> listener) {
addListener(listener);
return this;
}在这个例子中,chain() 直接将监听器添加到 RequestFuture 的监听器列表中。当 RequestFuture 完成时,无论成功还是失败,都会调用这些监听器。
示例
假设你有一个异步请求 future1,并且你想在它完成后执行一些额外的操作,然后将结果传递给另一个 RequestFuture。
RequestFuture<String> future1 = ...; // 假设这是你的初始未来
// 使用 compose 创建一个新的未来,该未来将在 future1 成功后执行额外操作
RequestFuture<Integer> future2 = future1.compose(result -> {
// 执行额外操作
int length = result.length();
// 返回一个新的未来,该未来包含额外操作的结果
RequestFuture<Integer> newFuture = new RequestFuture<>();
newFuture.success(length);
return newFuture;
});
// 使用 chain 添加一个监听器
future2.chain(new RequestFutureListener<Integer>() {
@Override
public void onSuccess(Integer result) {
System.out.println("Result: " + result);
}
@Override
public void onFailure(RuntimeException e) {
e.printStackTrace();
}
});在这个示例中,future1 是一个初始的 RequestFuture,我们使用 compose() 来创建一个新的 RequestFuture,并在 future1 成功后执行一些额外的操作。然后,我们使用 chain() 添加了一个监听器来处理 future2 的结果。
通过这种方式,Kafka 允许你以链式和组合的方式处理异步请求,从而实现复杂的逻辑流程。
KafkaRequestFuture<T> 是 Kafka 客户端中用于处理异步请求的一个关键类。它允许 Kafka 客户端发送请求并异步地等待响应,而不需要阻塞当前线程。KafkaRequestFuture<T> 的实现依赖于 RequestFuture<T> 类,它是一个泛型类,用于表示一个将来会有结果的请求。
异步请求处理
RequestFuture<T> 类通过以下几个关键组件和方法来处理异步请求:
回调监听器:
RequestFuture<T>维护了一个监听器列表(listeners),这些监听器实现了RequestFutureListener<T>接口。当请求成功完成时,fireSuccess()方法会被调用,它会遍历监听器列表并调用每个监听器的onSuccess(T value)方法。添加监听器:监听器可以通过
compose()和chain()方法添加到RequestFuture<T>上。这些方法允许你将一个RequestFuture<T>的结果传递给另一个函数或操作,并在该操作完成后通知监听器。组合和链接:
compose()方法允许你将一个RequestFuture<T>的结果传递给一个函数,该函数返回一个新的RequestFuture<U>。chain()方法则允许你将一个RequestFuture<T>的结果传递给一个函数,该函数执行一些操作并返回一个新的结果U。
fireSuccess() 方法
fireSuccess() 方法的实现如下:
private void fireSuccess() {
T value = value();
while (true) {
RequestFutureListener<T> listener = listeners.poll();
if (listener == null)
break;
listener.onSuccess(value);
}
}这个方法的作用是:
获取当前
RequestFuture<T>的结果值value。使用一个循环来处理所有的监听器:
从
listeners队列中取出一个监听器。如果没有更多的监听器,退出循环。
调用监听器的
onSuccess(T value)方法,将结果值传递给监听器。
添加监听器
监听器可以通过 compose() 和 chain() 方法添加到 RequestFuture<T> 上:
compose(Function<T, RequestFuture<U>> function):这个方法接受一个函数,该函数将当前RequestFuture<T>的结果转换为一个新的RequestFuture<U>。当当前RequestFuture<T>成功完成时,它会调用这个函数,并将新的RequestFuture<U>添加到监听器列表中。chain(Function<T, U> function):这个方法接受一个函数,该函数将当前RequestFuture<T>的结果转换为一个新的值U。当当前RequestFuture<T>成功完成时,它会调用这个函数,并将新的值U添加到监听器列表中。
示例
以下是一个简单的示例,展示了如何使用 compose() 和 chain() 方法:
RequestFuture<OffsetAndMetadata> future = ...; // 获取一个 RequestFuture<OffsetAndMetadata>
// 使用 compose() 方法将 OffsetAndMetadata 转换为 RequestFuture<String>
RequestFuture<String> futureString = future.compose(offsetAndMetadata -> {
// 这里可以执行一些操作,例如将 OffsetAndMetadata 转换为 String
return RequestFuture.successful(offsetAndMetadata.toString());
});
// 使用 chain() 方法将 OffsetAndMetadata 转换为 String
RequestFuture<String> futureString2 = future.chain(offsetAndMetadata -> {
// 这里可以执行一些操作,例如将 OffsetAndMetadata 转换为 String
return offsetAndMetadata.toString();
});在这个示例中,compose() 方法用于将 OffsetAndMetadata 转换为一个新的 RequestFuture<String>,而 chain() 方法用于将 OffsetAndMetadata 转换为一个新的值 String。
总结
KafkaRequestFuture<T> 和 RequestFuture<T> 类通过监听器列表和 compose()、chain() 方法来处理异步请求。当请求成功完成时,fireSuccess() 方法会被调用,它会遍历监听器列表并调用每个监听器的 onSuccess(T value) 方法。这使得 Kafka 客户端能够异步地处理请求响应,而无需阻塞当前线程。
对于生产者只会给服务端发消息这一种请求,所以不用考虑不同业务返回值不同这个问题。
我们总结一下ConsumerNetworkClient对成功响应处理的调用流程:
我们继续再学习下chain()方法的源码:
public void chain(final RequestFuture<T> future) {
addListener(new RequestFutureListener<T>() {
@Override
public void onSuccess(T value) {
future.complete(value);
}
@Override
public void onFailure(RuntimeException e) {
future.raise(e);
}
});
}
方法chain()和方法compose类似,都是通过给RequestFuture加监听器来实现事件在不同RequestFuture之间的传递。不同的是,chain不用实现RequestFuture<T>中泛型T类型的转换。
接下来,我们学习一下缓冲区的源码
消费者请求缓冲区
UnsentRequests是ConsumerNetworkClient的一个内部静态类,作用是提供一个请求缓冲区以及对缓冲区的相关操作。
我们学习一下相关的代码,类UnsentRequests的字段:
private final static class UnsentRequests {
private final ConcurrentMap<Node, ConcurrentLinkedQueue<ClientRequest>> unsent;
unsent是一个ConcurrentHashMap的类对象,key是节点,value是ConcurrentLinkedQueue<ClientRequest>类对象,按照节点和发送节点的请求队列保存的Map。
我们接着看一下向 unsent 缓存请求的方法。
缓存请求
public void put(Node node, ClientRequest request) {
synchronized (unsent) {
ConcurrentLinkedQueue<ClientRequest> requests = unsent.get(node);
if (requests == null) {
requests = new ConcurrentLinkedQueue<>();
unsent.put(node, requests);
}
requests.add(request);
}
}
我简单介绍下这个方法的流程:首先synchronized加锁,锁对象是unsent;然后根据node取出要发送请求的队列,如果队列不为空就取出队列,如果队列是空的就创建一个队列并放入unsent中;最后把请求放入队列中。
这里注意一点:unsent是ConcurrentHashMap类型,为什么还要加锁呢?
因为put方法里有放入请求队列再往队列添加请求的两个连续的动作,如果中间发生了删除节点对应请求列表的动作,那么往列表添加请求后unsent集合并不存在这个请求,而put()又没有告知调用者这个请求添加失败了,这样就造成数据的不一致。
删除过期请求
如果请求在缓冲区很久没发送出去就应该删除。源码如下:
private Collection<ClientRequest> removeExpiredRequests(long now) {
List<ClientRequest> expiredRequests = new ArrayList<>();
//1.遍历请求
for (ConcurrentLinkedQueue<ClientRequest> requests : unsent.values()) {
Iterator<ClientRequest> requestIterator = requests.iterator();
while (requestIterator.hasNext()) {
ClientRequest request = requestIterator.next();
//2.计算耗费的时间
long elapsedMs = Math.max(0, now - request.createdTimeMs());
//3.如果大于超时时间就把请求加入过期集合,并从unsent集合中删除。
if (elapsedMs > request.requestTimeoutMs()) {
expiredRequests.add(request);
requestIterator.remove();
} else
break;
}
}
return expiredRequests;
}
第一步,遍历unsent里所有的请求。
第二步,用当前时间减去请求创建的时间得到请求在缓冲区存在的时间。
第三步,如果请求在缓冲区存在的时间大于请求超时时间,把请求加入过期请求集合并从缓冲区删除。
到这里,请求缓冲区讲完了,我们接着来看看真正的请求网络发送是如何实现的?
发送消息的第二个阶段:网络发送请求
这里主要是通过方法poll()实现的网络发送。
方法poll()
public void poll(Timer timer, PollCondition pollCondition, boolean disableWakeup) {
firePendingCompletedRequests();
lock.lock();
try {
handlePendingDisconnects();
//1.请求从 unsent 里拿出并预发送,返回poll延迟时间
long pollDelayMs = trySend(timer.currentTimeMs());
// 2.调用poll()方法,首先会更新元数据,然后发送send字段的数据,
if (pendingCompletion.isEmpty() && (pollCondition == null || pollCondition.shouldBlock())) {
long pollTimeout = Math.min(timer.remainingMs(), pollDelayMs);
if (client.inFlightRequestCount() == 0)
pollTimeout = Math.min(pollTimeout, retryBackoffMs);
client.poll(pollTimeout, timer.currentTimeMs());
} else {
client.poll(0, timer.currentTimeMs());
}
timer.update();
// 3.处理断开连接的node的消息
checkDisconnects(timer.currentTimeMs());
if (!disableWakeup) {
// 4.如果有selector.poll()阻塞中断请求而且有方法标记不能中断,则抛出异常
maybeTriggerWakeup();
}
maybeThrowInterruptException();
//5.因为上面调用了poll()方法,send就有可能发送成功了,也可能增加了网络连接,所以再次从unsent集合中取请求做预发送
trySend(timer.currentTimeMs());
//6.处理unsent中超时的请求
failExpiredRequests(timer.currentTimeMs());
unsent.clean();
} finally {
lock.unlock();
}
firePendingCompletedRequests();
metadata.maybeThrowAnyException();
}
第一步,调用trySend()方法循环处理unsent中缓存的请求,遍历对应每个节点的请求列表,并用判断NetworkClient.ready(node,now)判断要发送的节点是否满足发送条件,如果满足就调用NetworkClient.send()做好预发送并将请求放入InFlightRequest集合中等待响应,最后删除unsent集合对应的请求。
代码在下面:
// 请求预发送
long trySend(long now) {
long pollDelayMs = maxPollTimeoutMs;
// send any requests that can be sent now
// 1.按节点从unsent里取出缓存队列
for (Node node : unsent.nodes()) {
//2.取到node对应的发送队列
Iterator<ClientRequest> iterator = unsent.requestIterator(node);
if (iterator.hasNext())
//3.返回poll()操作的延迟时间
pollDelayMs = Math.min(pollDelayMs, client.pollDelayMs(node, now));
//4.轮询队列里的请求,预发送请求。
while (iterator.hasNext()) {
ClientRequest request = iterator.next();
//4.调用NetworkClient.ready()检测是否可以发送请求。
if (client.ready(node, now)) {
//5调用NetworkClient.send()方法,完成请求的预发送,等待正式的网络发送。
client.send(request, now);
//6.删除队列中对应额请求
iterator.remove();
} else {
// try next node when current node is not ready
break;
}
}
}
//7.返回poll延迟时间
return pollDelayMs;
}
第二步,计算超时时间。会用这个超时时间作为Selector最长阻塞的时间。
第三步,调用poll()方法发送,首先如果有必要会更新元数据,然后发送send字段的请求数据。
第四步,处理断开连接的node的消息。如果有连接断开的节点,就把unsent对应的请求都删除。
第五步,如果有selector.poll()唤醒阻塞请求而且有方法标记不能唤醒就抛出异常。这种情况主要是在调用close()方法的过程中,如果再唤醒显然不合理,因为通信要关闭了,唤醒就没有必要了。
第六步,再次调用trySend()方法。因为这时用于调用了NetworkClient.poll()方法,KafkaChannel.send字段可能已经发送出去了,就又能做预发送的工作了,也有可能unsent集合这时出现了向新的node发送的请求,所以再尝试一次trySend()方法。
第七步,调用failExpiredRequests()方法处理unsent中过期的请求。
第八步,调用firePendingCompletedRequests()方法。收到响应时,会把回调对象放入到这个集合里。这个方法是调用回调对象里的回调方法的,完成响应的处理。
总结
今天我们主要讲解了消费者的通信组件ConsumerNetworkClient。发送的流程和生产者类似,也是先发送到缓冲区,然后通过消费缓冲区的请求去发送真正的网络请求。
同时,我们还讲解了ConsumerNetworkClient对响应的处理,通过监听器在多个RequestFuture之间传递事件,实现基础通信组件ConsumerNetworkClient和上层业务的解耦。除此之外,还介绍了消费者缓冲区的一些字段和方法。
确实,ConsumerNetworkClient 是 Kafka 消费者客户端中的一个关键组件,它负责处理与 Kafka 服务器之间的网络通信。下面是关于 ConsumerNetworkClient 的发送流程、响应处理以及缓冲区的一些字段和方法的详细讲解。
发送流程
请求生成:消费者应用程序通过调用
KafkaConsumer的 API(如poll()或commitSync())来生成请求。请求入队:这些请求被放入
ConsumerNetworkClient的内部缓冲区中。这个缓冲区通常是基于BlockingQueue实现的,以确保线程安全。轮询选择器:
ConsumerNetworkClient定期调用Selector.poll()方法来检查哪些通道已经准备好进行 I/O 操作。执行 I/O 操作:对于可写的通道,
ConsumerNetworkClient从缓冲区中取出请求并通过网络发送。处理响应:一旦收到响应,
ConsumerNetworkClient将其返回给消费者应用程序或触发相应的监听器。
响应处理
ConsumerNetworkClient 使用 RequestFuture 和监听器机制来处理异步响应。以下是主要步骤:
创建
RequestFuture:每个请求都会关联一个RequestFuture对象,该对象用于存储请求的结果和管理监听器。添加监听器:可以通过
compose()和chain()方法向RequestFuture添加监听器。监听器在请求成功或失败时会被调用。触发回调:当请求完成时,
fireSuccess()或fireFailure()方法会被调用,进而触发所有注册的监听器。
缓冲区字段和方法
ConsumerNetworkClient 内部通常会维护一些关键字段和方法来管理请求和响应。以下是一些常见的字段和方法:
字段
requestQueue:一个阻塞队列,用于存储待发送的请求。inFlightRequests:一个映射,用于跟踪当前正在处理的请求。pendingCompletionReceives:一个映射,用于跟踪等待完成的接收操作。lastHeartbeatSend:记录上次心跳发送的时间戳。lastHeartbeatReceive:记录上次心跳接收的时间戳。
方法
send(ClientRequest request, long now):将请求加入到
requestQueue中,并设置为待发送状态。更新相关的时间戳和其他状态信息。
poll(long timeout, long now):调用
Selector.poll()来检查就绪的 I/O 事件。处理可读和可写的通道,包括从缓冲区中取出请求并发送,以及处理接收到的响应。
completeResponses(int maxWaitMs, long now):完成所有已完成的响应,并触发相应的监听器。
清理已完成的请求和响应。
maybeTriggerWakeup():如果需要唤醒
KafkaConsumer,则触发唤醒操作。这通常发生在有新的数据到达或者某些错误发生时。
heartbeatCheck(long now):检查是否需要发送心跳以维持会话活跃状态。
如果需要,则发送心跳请求。
pollNoWakeup():类似于
poll(),但不会触发唤醒操作。这通常在后台线程中使用,以避免干扰主消费线程。
示例代码
以下是一个简化的 ConsumerNetworkClient 类的示例,展示了上述字段和方法的基本实现:
public class ConsumerNetworkClient {
private final NetworkClient networkClient;
private final BlockingQueue<ClientRequest> requestQueue = new LinkedBlockingQueue<>();
private final Map<String, RequestFuture<?>> inFlightRequests = new HashMap<>();
private final Map<String, Deque<RequestFuture<?>>> pendingCompletionReceives = new HashMap<>();
private final ReentrantLock lock = new ReentrantLock();
private final Condition notEmpty = lock.newCondition();
private long lastHeartbeatSend;
private long lastHeartbeatReceive;
public ConsumerNetworkClient(NetworkClient networkClient) {
this.networkClient = networkClient;
}
public void send(ClientRequest clientRequest, long now) {
lock.lock();
try {
requestQueue.put(clientRequest);
inFlightRequests.put(clientRequest.correlationId(), clientRequest.future());
notEmpty.signalAll();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException(e);
} finally {
lock.unlock();
}
}
public void poll(long timeout, long now) {
int readyOps = networkClient.poll(timeout, now);
// 处理可写通道
for (Map.Entry<String, NetworkClient.ClientResponse> entry : networkClient.completedSends()) {
RequestFuture<?> future = inFlightRequests.remove(entry.getKey());
if (future != null) {
future.success(entry.getValue());
}
}
// 处理可读通道
for (Map.Entry<String, NetworkClient.ClientResponse> entry : networkClient.completedReceives()) {
String correlationId = entry.getKey();
ClientResponse response = entry.getValue();
Deque<RequestFuture<?>> futures = pendingCompletionReceives.get(correlationId);
if (futures == null) {
// 请求还未发送,先缓存响应
futures = new ArrayDeque<>();
pendingCompletionReceives.put(correlationId, futures);
}
futures.add(new RequestFuture<>());
// 触发回调
while (!futures.isEmpty() && response.isCompletedReceive()) {
RequestFuture<?> future = futures.poll();
if (future != null) {
if (response.wasSuccessful()) {
future.success(response.responseBody());
} else {
future.failure(response.exception());
}
}
}
}
}
public void completeResponses(int maxWaitMs, long now) {
// 完成所有已完成的响应
for (Map.Entry<String, Deque<RequestFuture<?>>> entry : pendingCompletionReceives.entrySet()) {
Deque<RequestFuture<?>> futures = entry.getValue();
while (!futures.isEmpty()) {
RequestFuture<?> future = futures.peek();
if (future.isDone()) {
futures.poll().complete(null); // 触发回调
} else {
break;
}
}
}
}
public void heartbeatCheck(long now) {
if (now - lastHeartbeatSend > HEARTBEAT_INTERVAL_MS) {
// 发送心跳
lastHeartbeatSend = now;
send(heartbeatRequest(), now);
}
}
private void maybeTriggerWakeup() {
// 检查是否需要唤醒 KafkaConsumer
// ...
}
}在这个示例中,ConsumerNetworkClient 管理了一个请求队列 requestQueue,并将请求发送到 networkClient。poll() 方法处理了就绪的 I/O 事件,并触发了相应的回调。completeResponses() 方法完成了所有已完成的响应。heartbeatCheck() 方法定期发送心跳以维持会话活跃状态。
通过这种方式,ConsumerNetworkClient 提供了一种高效且解耦的方式来处理消费者的网络通信。
在 Kafka 中,生产者和消费者的网络通信都是通过 SocketServer 和 NetworkClient 实现的。生产者通过 ProducerNetworkClient 发送消息到 Kafka 集群,而消费者通过 ConsumerNetworkClient 从 Kafka 集群接收消息。下面我们将详细讲解消费者的通信组件 ConsumerNetworkClient 的发送流程和对响应的处理。
发送流程
构建请求:
消费者首先构建一个网络请求,例如
FetchRequest,用于从 Kafka 集群获取消息。
序列化请求:
将请求对象序列化为字节缓冲区(
ByteBuffer)。
发送到缓冲区:
将序列化后的请求添加到
NetworkClient的发送缓冲区(sendBuffer)。
发送网络请求:
NetworkClient从发送缓冲区中取出请求,并通过Selector发送到 Kafka 集群。
处理响应:
Kafka 集群处理请求后,将响应发送回消费者。
NetworkClient通过Selector接收响应,并将其添加到响应缓冲区(responseBuffer)。
处理响应缓冲区:
ConsumerNetworkClient从响应缓冲区中取出响应,并进行反序列化处理。
对响应的处理
ConsumerNetworkClient 通过监听器(RequestFutureListener)在多个 RequestFuture 之间传递事件,实现基础通信组件和上层业务的解耦。具体步骤如下:
添加监听器:
在发送请求时,消费者可以为每个请求添加一个或多个监听器(
RequestFutureListener)。
处理响应事件:
当
NetworkClient接收到响应并将其添加到响应缓冲区时,ConsumerNetworkClient会触发相应的事件。ConsumerNetworkClient调用fireSuccess()或fireFailure()方法,通知所有监听器请求的成功或失败。
监听器处理事件:
监听器实现
RequestFutureListener接口,定义onSuccess(T value)和onFailure(Throwable exception)方法。当请求成功时,监听器的
onSuccess(T value)方法被调用,传递响应结果。当请求失败时,监听器的
onFailure(Throwable exception)方法被调用,传递异常信息。
消费者缓冲区字段和方法
ConsumerNetworkClient 维护了一些字段和方法,用于管理发送和接收缓冲区:
sendBuffer:发送缓冲区,用于存储待发送的请求。
responseBuffer:响应缓冲区,用于存储接收到的响应。
poll(long timeoutMs):轮询方法,用于从响应缓冲区中取出响应,并处理发送缓冲区中的请求。
send(RequestHeader header, ByteBuffer buffer):发送请求的方法,将请求添加到发送缓冲区。
fireSuccess():通知监听器请求成功的方法。
fireFailure(Throwable exception):通知监听器请求失败的方法。
示例代码
以下是一个简单的示例,展示了如何使用 ConsumerNetworkClient 发送请求并处理响应:
import org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient;
import org.apache.kafka.common.protocol.RequestHeader;
import org.apache.kafka.common.protocol.requests.FetchRequest;
import org.apache.kafka.common.protocol.responses.FetchResponse;
import java.nio.ByteBuffer;
import java.util.Collections;
import java.util.Properties;
public class CustomConsumer {
public static void main(String[] args) {
Properties props = new Properties();
// 配置 Kafka 消费者属性
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test-group");
ConsumerNetworkClient client = new ConsumerNetworkClient(props);
try {
// 创建 Fetch 请求
FetchRequest fetchRequest = new FetchRequest.Builder()
.addFetch("topic", 0, 0, 1024)
.build();
RequestHeader header = new RequestHeader(FetchRequest.FETCH_KEY, FetchRequest.VERSION_3);
ByteBuffer buffer = ByteBuffer.allocate(fetchRequest.sizeInBytes());
fetchRequest.writeTo(buffer);
// 发送请求
client.send(header, buffer);
// 轮询响应
while (true) {
FetchResponse response = (FetchResponse) client.poll(1000);
if (response != null) {
// 处理响应
System.out.println("Received messages: " + response.records());
break;
}
}
} finally {
client.close();
}
}
}在这个示例中,我们创建了一个 ConsumerNetworkClient 实例,发送了一个 Fetch 请求,并处理了从 Kafka 集群返回的响应。
总结
ConsumerNetworkClient 是 Kafka 消费者客户端中的一个核心组件,负责与 Kafka 集群进行网络通信。通过使用 ConsumerNetworkClient,开发者可以实现自定义的消息获取和处理逻辑,以满足特定的业务需求。同时,ConsumerNetworkClient 通过监听器在多个 RequestFuture 之间传递事件,实现基础通信组件和上层业务的解耦。
12 消费者协调器
ConsumerCoordinator 的工作原理
客户端ConsumerCoordinators是和服务端GroupCoordinator配合使用的,目的是管理消费者,包括通过管理消费者上下线,给消费者分发要消费的主题分区。不过,我在介绍消费者协调器之前,先解释几个概念。
offset 管理
每一个consumer客户端内存都会保存它消费的每个主题分区的消费offset,消费offset表示这个consumer group消费到这个主题分区的哪个offset了。
为什么要有消费offset呢?当某个消费者上下线时会造成主题分区的消费换到别的消费者,而新的消费者不知道主题分区消费到哪里了,这时就需要服务端保存消费offset,这样新的消费者才能得到消费的offset接着消费,不会造成重复消费和漏掉消费的情况。
也就是说消费者会定期向服务端提交offset,老版本是写入ZooKeeper,显然消费者提交offset是个高频操作。而ZooKeeper是做分布式协调的,轻量级元数据存储,ZooKeeper不适合高并发的请求。
后来的版本放弃 ZooKeeper 做消费offset的保存而改用内部主题__consumer_offsets,主题的key是group.id+topic+分区号,value就是当前消费的offset值。每隔一段时间__consumer_offsets会把key重复的历史的数据删除,也就是说只保留最新的一条key值。内部主题__consumer_offsets的分区数是50,这样就能很好地抵挡高并发的请求。
GroupCoordinator
什么是 GroupCoordinator ?
每个消费者组都会选择一个broker作为自己的 GroupCoordinator,GroupCoordinator 负责监控消费者组里各个消费者的心跳,判断是否宕机,然后开启 rebalance 把分区分配给各个消费者。
消费组中的消费者刚启动的时候,就会跟对应GroupCoordinator的broker建立通信,GroupCoordinator会分配主题分区给这个消费者消费。GroupCoordinator会尽量均匀地分配分区给各个消费者进行消费。
那如何找到 GroupCoordinator 呢?
每个消费者都有一个消费者组id,消费者首先对消费者组id进行hash,hash后的值对__consumer_offsets的分区数取模得到要发送的分区。消费者向集群中一个节点发送请求,节点根据消费者提供消费组id和节点缓存的元数据得到这个分区的leader所在的broker,这个broker上运行的 GroupCoordinator 负责接收和管理对应消费者组提交的消费offset。
Rebalance 消费者重平衡
ConsumerCoordinators和GroupCoordinator之间最重要的职责就是负责执行消费者重平衡的操作。消费者重平衡是指在分区或消费者有变动的时候,需要重新给消费者内的消费者分配要消费的分区。
好,接着我来给你介绍下 ConsumerCoordinator 和 GroupCoordinator 的工作流程。
协调者工作流程
如下图所示,Kafka 集群有 3 个节点,同一个消费者组 1 下有 3 个消费者去消费 topic。
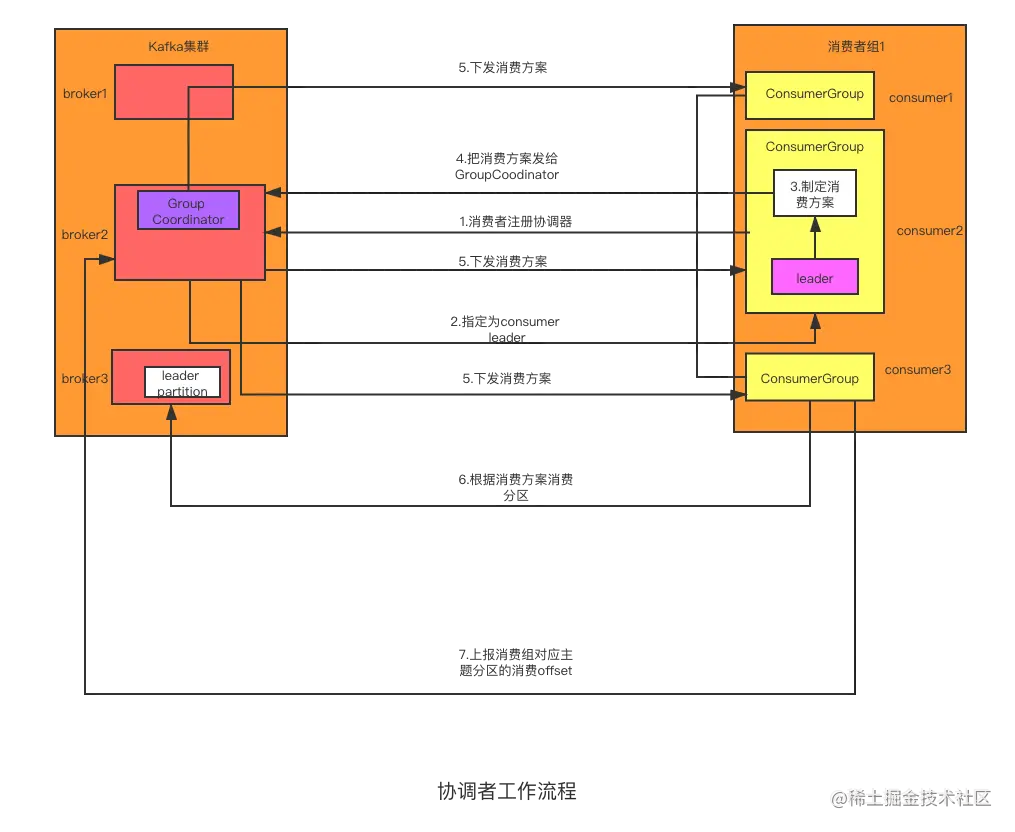
结合该示意图,我介绍下这个工作流程。
第一步,消费者启动的时候,根据元数据和消费者组id得到对应的Group Coordinator对应的broker后,向这个broker发送JoinGroupRequest请求。
第二步,Group Coordinator会选出一个consumer作为消费者组的leader,然后响应这些消费者是否注册成功,消费者会收到 JoinGroupResponse响应。在响应中,对于consumer leader还会把它是leader的信息发给它。到这里完成注册。
第三步,consumer leader根据服务端的响应信息指定消费的分配方案。
第四步,consumer leader把分配方案发送给Group Coordinator。
第五步,Group Coordinator把分配方案发送给消费者组下的所有消费者。
第六步,消费者开始根据收到的消费方案找到对应的leader partition所在的broker消费。
第七步,消费者处理完消息后会把消费的offset发给Group Coordinator,Group Coordinator会保存在__consumer_offsets里。
接着继续介绍消费者的ConsumerCoordinator类。
ConsumerCoordinator 类
ConsumerCoordinator类组件实现了与服务端的GroupCoordinator的交互,ConsumerCoordinator类继承了抽象类AbstractCoordinator,我们先学习抽象类AbstractCoordinator的源码。(我们这节只涉及AbstractCoordinator和ConsumerCoordinator核心字段的讲解,方法会放在后面章节讲解。)
AbstractCoordinator 核心字段
源码如下:
public abstract class AbstractCoordinator implements Closeable {
//消费者成员状态
protected enum MemberState {
UNJOINED,
PREPARING_REBALANCE,
COMPLETING_REBALANCE,
STABLE;
public boolean hasNotJoinedGroup() {
return equals(UNJOINED) || equals(PREPARING_REBALANCE);
}
}
//心跳对象
private final Heartbeat heartbeat;
//负责网络通信
protected final ConsumerNetworkClient client;
//Node类型,保存着服务端GroupCoordinator的节点。
private Node coordinator = null;
//标记重新发送JoinGroupRequest请求。
private boolean rejoinNeeded = true;
//是否重新发送JoinGroupRequest请求。
private boolean needsJoinPrepare = true;
private HeartbeatThread heartbeatThread = null;
private RequestFuture<ByteBuffer> joinFuture = null;
private RequestFuture<Void> findCoordinatorFuture = null;
volatile private RuntimeException findCoordinatorException = null;
//服务端GroupCoordinator的年代信息
private Generation generation = Generation.NO_GENERATION;
//最后一次rebalance的开始时间
private long lastRebalanceStartMs = -1L;
//最后一次rebalance的结束时间
private long lastRebalanceEndMs = -1L;
MemberState是一个枚举,列举了消费者和服务端Group Coordinator交互的4个状态。UNJOINED,表示消费者还没加入到服务端Group Coordinator中;PREPARING_REBALANCE,表示消费者发出了加入Group Coordinator的请求,但是还没收到响应;COMPLETING_REBALANCE,表示消费者收到了加入Group Coordinator的响应;STABLE,表示消费者发出了加入Group Coordinator中,并正在向Group Coordinator发送心跳。heartbeat:Heartbeat的类对象。用来保存与GroupCoordinator维持心跳的一些配置数据,如最近发送心跳的时间,下次要发送心跳的时间等。client:ConsumerNetworkClient的类对象。提供底层通讯服务。coordinator:Node的类对象。保存着GroupCoordinator的节点信息。rejoinNeeded:bool类型。是否重新发送加入GroupCoordinator的请求。heartbeatThread:维持心跳的线程。加入到GroupCoordinator后就会发起定时的心跳线程。joinFuture:加入GroupCoordinator的异步请求类对象。findCoordinatorFuture:客户端查找GroupCoordinator的异步请求类对象。generation:GroupCoordinator发过来的Rebalance年代。为了区分上次Rebalance延迟造成新的Rebalance被覆盖,造成数据不一致。
好,抽象类AbstractCoordinator核心字段介绍完了,下面开始介绍ConsumerCoordinator类的核心字段。
ConsumerCoordinator 类的核心字段
相关核心字段看下面的源码:
public final class ConsumerCoordinator extends AbstractCoordinator {
//订阅分区任务列表
private final List<ConsumerPartitionAssignor> assignors;
//消费者元数据
private final ConsumerMetadata metadata;
//订阅状态,保存了主题分区和offset的对应关系。
private final SubscriptionState subscriptions;
//是否自动提交offset
private final boolean autoCommitEnabled;
//提交offset的时间间隔
private final int autoCommitIntervalMs;
//提交offset后的处理列表
private final ConcurrentLinkedQueue<OffsetCommitCompletion> completedOffsetCommits;
//是否是leader
private boolean isLeader = false;
//保存分区信息,用来监控分区信息是否变了。
private MetadataSnapshot metadataSnapshot;
//消费组元数据
private ConsumerGroupMetadata groupMetadata;
我给你讲解一下:
assignors:订阅分区任务列表,列表的元素是ConsumerPartitionAssignor。ConsumerPartitionAssignor里是发送JoinGroupRequest请求中消费者支持的分区算法等信息。GroupCoordinator会从所有消费者都支持的算法中选择一个,并通知leader consumer使用这个分区算法进行分配。一个消费可以包含多个分区算法,可以在partition.assignment.strategy参数中配置。metadata:ConsumerMetadata类对象。保存着消费者消费的元数据,如分区和offset的对应关系,要消费的主题等。subscriptions:SubscriptionState的类对象。 保存着消费者消费的分区和offset的对应关系。autoCommitEnabled:bool类型。是否自动提交offset。completedOffsetCommits:ConcurrentLinkedQueue<OffsetCommitCompletion>类对象。这是一个线程安全的队列,队列的元素是提交offset后处理响应的回调对象。OffsetCommitCompletion是发出提交offset的请求后,会把处理响应的回调对象放到这个队列里。isLeader:是否被Group Coordinator选为leader consumer。metadataSnapshot:保存分区信息,用来监控分区信息是否变了,如果变了就需要重新分配主题分区,也就是rebalance。groupMetadata:保存着消费者组的id、消费者的id等元数据。
总结
这节课我们介绍了ConsumerCoordinator的工作原理,对相关名词进行了解释,包括offset管理、什么是GroupCoordinator、如何找到GroupCoordinator、消费者重平衡的原理,以及发生消费者重平衡的场景。
然后,还讲解了ConsumerCoordinator以及抽象类AbstractCoordinator的核心字段。
总之,希望你能够对什么是消费者协调器、消费者协调器的工作原理有一定的理解,这也是我们接下来几节课的基础。下一节课,我们就开始消费者重平衡的学习了。