2. KafkaProducer:生产者业务线程
生产者主流程
这里我介绍一下生产者发送消息的主逻辑。下面的图简单描述了消息发送的每一个环节,希望你能结合前面的课程对生产者发送消息的流程有较为深刻的理解。
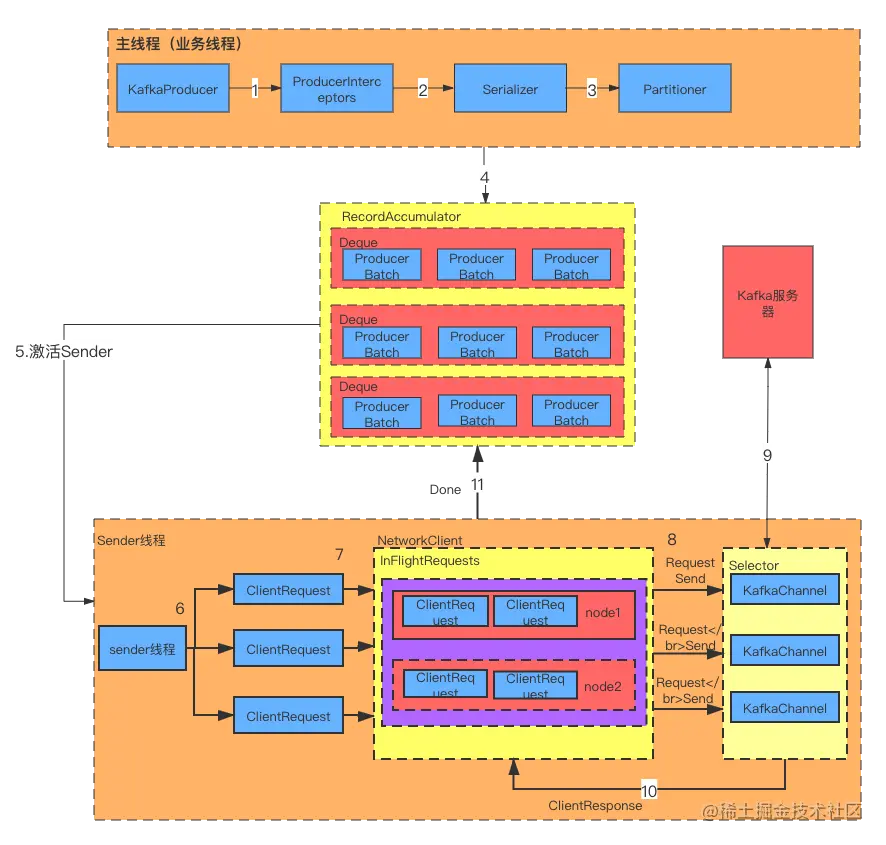
我描述下每个步骤。
ProducerInterceptors:作为拦截器对消息进行拦截,拦截器的主要作用是按照一定的规则统一对消息进行处理。比如要统一给所有消息加全局id,这样消息发送的时候,调用者就不用考虑生成全局id的事情,完全交给拦截器去做。
Serializer:序列化器。对消息的key和value进行序列化。因为在网络传输中数据是以字节码的形式传输的,所以要用序列化器对数据进行序列化。
Partitioner: 分区器。消息发送的时候要确定发送到哪个分区,分区器通过算法给消息分配主题分区。
RecordAccumulator:消息积累器。按分区收集消息,实现消息的异步批量发送。
Sender:消息发送器。从RecordAccumulator批量获取消息。
构造ClientRequest。ClientRequest是客户端请求。
将ClientRequest交给NetworkClient,准备发送。
NetworkClient将请求放入KafkaChannel的缓存,等待发送。
KafkaChannel执行网络IO,发送请求。
NetworkClient收到服务端的响应,调用ClientRequest的回调方法。
调用ProducerBatch的回调方法,最终会调用到用户在发送消息时注册的回调方法。
KafkaProducer 是 Apache Kafka 中的一个客户端库,用于将数据发送到 Kafka 集群。生产者业务线程通常是指在应用程序中负责创建消息并将其发送给 Kafka 服务器的线程。下面是一些关于 KafkaProducer 的关键点:
配置:
在创建
KafkaProducer实例之前,需要设置一系列的配置参数,如bootstrap.servers(指定Kafka集群地址)、key.serializer和value.serializer(定义键值对序列化方式)等。创建实例:
使用配置好的参数来初始化一个
KafkaProducer对象。发送消息:
生产者可以通过调用
send()方法异步地发送消息到指定的主题。该方法接受一个ProducerRecord对象作为参数。可以选择为
send()方法提供回调函数,以便处理发送成功或失败的情况。事务性消息:
如果需要保证消息的一致性和完整性,可以开启事务支持,通过
initTransactions()开始事务,并使用beginTransaction(),commitTransaction()和abortTransaction()来管理事务。关闭生产者:
当不再需要使用生产者时,应该正确地关闭它,以确保所有未完成的请求都能得到处理。这通常是通过调用
close()方法实现的。错误处理:
处理可能发生的异常和错误情况是非常重要的,比如网络问题或者分区不可用等。
性能优化:
可以调整缓冲区大小、批处理数量、压缩类型等配置来优化性能。
重试机制:
设置重试次数和策略可以帮助处理暂时性的错误,比如短暂的网络中断。
拦截器:
可以通过实现
org.apache.kafka.clients.producer.ProducerInterceptor接口来自定义拦截器,在消息发送前后执行特定逻辑。在实际应用中,你可能会有一个或多个业务线程持续不断地产生数据,并通过
KafkaProducer将这些数据发送到Kafka主题中。为了确保高效可靠的数据传输,你需要根据你的具体需求合理地设计和配置生产者。如果你有关于如何编写具体的代码示例或者其他更详细的问题,请告诉我!
类KafkaProducer
了解完以上主流程和步骤之后,接下来我们分析一下KafkaProducer的源码。
重要字段
public class KafkaProducer<K, V> implements Producer<K, V> {
//生产者的id
private final String clientId;
//分区器
private final Partitioner partitioner;
//最大的消息长度,默认1M
private final int maxRequestSize;
//对应BufferPool的缓存区大小
private final long totalMemorySize;
//生产者元数据
private final ProducerMetadata metadata;
//消息累加器
private final RecordAccumulator accumulator;
//执行发送消息的类
private final Sender sender;
//执行Sender发送消息的线程
private final Thread ioThread;
//消息压缩的类型
private final CompressionType compressionType;
//key序列化器
private final Serializer<K> keySerializer;
//value序列化器
private final Serializer<V> valueSerializer;
//生产者客户端参数配置
private final ProducerConfig producerConfig;
//等待元数据更新的最大时间,默认1分钟
private final long maxBlockTimeMs;
//拦截器
private final ProducerInterceptors<K, V> interceptors;
private final ApiVersions apiVersions;
private final TransactionManager
这些重要字段的含义和关键点如下。
clientId:生产者客户端的id。partitioner:分区器。基于一定的算法把消息分配到某一个分区。maxRequestSize:消息的最大长度,默认1M。totalMemorySize:发送消息的缓冲区大小,默认32M。metadata:集群的元数据。accumulator:RecordAccumulator类对象。负责缓冲消息。sender:Sender类对象。负责发送消息。ioThread:KafkaThread类对象,在这里负责封装Sender类。compressionType:消息压缩的类型。keySerializer:key的序列化器。valueSerializer:value的序列化器。producerConfig:生产者客户端的配置参数。maxBlockTimeMs:等待元数据更新的最长时间,默认1分钟。interceptors:拦截器。负责在消息发送前或响应接收后统一对消息进行拦截和处理。
分析
KafkaProducer的源码可以帮助我们深入理解其内部工作原理,以及如何实现高效的异步消息发送机制。下面我会简要概述 KafkaProducer 源码中的一些关键组件和流程。请注意,由于 Kafka 版本迭代较快,这里以一个相对通用的视角来描述。1. 初始化
当创建一个新的
KafkaProducer实例时,会调用构造函数,并传入配置参数。这些配置包括但不限于bootstrap.servers,key.serializer,value.serializer等。构造函数主要做以下几件事情:
验证并设置默认配置。
创建
Metadata对象,用于跟踪集群元数据(如主题分区信息)。根据配置初始化网络客户端
NetworkClient。如果启用了事务,则初始化事务管理器。
设置拦截器链。
2. 发送消息
当调用
send()方法时,实际发生的是:
构建
ProducerRecord对象。如果有拦截器,先执行拦截器逻辑。
将记录添加到缓存队列中等待处理。
如果需要立即刷新或队列已满,则触发批量发送过程。
批量发送通过
NetworkClient向对应的 broker 发送请求。关键方法
doSend(ProducerRecord<K, V> record, Callback callback): 这是真正处理发送请求的方法。它将记录转换为可序列化的格式,并将其放入相应的缓冲区中。
accumulator.append(tp, timestamp, serializedKey, serializedValue, interceptCallback, remainingWaitMs): 在这个过程中,accumulator是用来累积待发送的消息的。它根据目标分区将消息组织成批次。3. 异步处理与回调
KafkaProducer使用了线程池来进行后台操作,比如定时刷新、发送心跳等。当消息被成功发送或者遇到错误时,可以通过传递给
send()方法的Callback接口进行通知。4. 元数据更新
Metadata组件负责定期从 Kafka 集群获取最新的元数据信息,比如新的 broker 节点加入或离开集群、主题分区的变化等。生产者会在每次尝试发送失败后检查是否需要更新元数据。
5. 关闭
调用
close()方法时,生产者会尝试完成所有未决的发送请求,然后关闭资源。可以指定一个超时时间来等待所有挂起的操作完成;如果超过该时间仍有未完成的操作,那么它们会被中断。
以上是对 KafkaProducer 内部结构的一个高层次概览。如果你对特定部分或更详细的实现感兴趣,例如具体的算法逻辑、并发控制机制或是性能优化点,请告诉我,我可以提供更加具体的信息。此外,直接查看 Apache Kafka 的官方 GitHub 仓库中的源代码也是深入了解的好方法。
构造方法
生产者发送消息会涉及很多的组件,KafkaProducer类的构造方法就是初始化生产消息需要的组件。你先看下源码:
KafkaProducer(Map<String, Object> configs,
Serializer<K> keySerializer,
Serializer<V> valueSerializer,
ProducerMetadata metadata,
KafkaClient kafkaClient,
ProducerInterceptors<K, V> interceptors,
Time time) {
ProducerConfig config = new ProducerConfig(ProducerConfig.appendSerializerToConfig(configs, keySerializer,
valueSerializer));
try {
//1.用户自定义参数
Map<String, Object> userProvidedConfigs = config.originals();
this.producerConfig = config;
this.time = time;
String transactionalId = (String) userProvidedConfigs.get(ProducerConfig.TRANSACTIONAL_ID_CONFIG);
//2.获取配置参数。
this.clientId = config.getString(ProducerConfig.CLIENT_ID_CONFIG);
LogContext logContext;
......忽略
//3.获取分区器。
this.partitioner = config.getConfiguredInstance(ProducerConfig.PARTITIONER_CLASS_CONFIG, Partitioner.class);
//4.失败重试的退避时间。默认100ms
long retryBackoffMs = config.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG);
//5.定义key和value的序列化器
if (keySerializer == null) {
this.keySerializer = config.getConfiguredInstance(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
Serializer.class);
this.keySerializer.configure(config.originals(Collections.singletonMap(ProducerConfig.CLIENT_ID_CONFIG, clientId)), true);
} else {
config.ignore(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG);
this.keySerializer = keySerializer;
}
if (valueSerializer == null) {
this.valueSerializer = config.getConfiguredInstance(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
Serializer.class);
this.valueSerializer.configure(config.originals(Collections.singletonMap(ProducerConfig.CLIENT_ID_CONFIG, clientId)), false);
} else {
config.ignore(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG);
this.valueSerializer = valueSerializer;
}
userProvidedConfigs.put(ProducerConfig.CLIENT_ID_CONFIG, clientId);
ProducerConfig configWithClientId = new ProducerConfig(userProvidedConfigs, false);
//6.定义拦截器列表
List<ProducerInterceptor<K, V>> interceptorList = (List) configWithClientId.getConfiguredInstances(
ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, ProducerInterceptor.class);
if (interceptors != null)
this.interceptors = interceptors;
else
this.interceptors = new ProducerInterceptors<>(interceptorList);
ClusterResourceListeners clusterResourceListeners = configureClusterResourceListeners(keySerializer,
valueSerializer, interceptorList, reporters);
//7.最大请求大小。默认1M,这个值有些小,在实际生产环境中经常会比这个参数大,我们一般设置为10M
this.maxRequestSize = config.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG);
//8.消息缓冲区大小。默认是32M,如果有特殊的需要我们可以修改
this.totalMemorySize = config.getLong(ProducerConfig.BUFFER_MEMORY_CONFIG);
//9.获取压缩类型
this.compressionType = CompressionType.forName(config.getString(ProducerConfig.COMPRESSION_TYPE_CONFIG));
//10.获取请求最长
this.maxBlockTimeMs = config.getLong(ProducerConfig.MAX_BLOCK_MS_CONFIG);
//11.设置消息投递超时时间
int deliveryTimeoutMs = configureDeliveryTimeout(config, log);
this.apiVersions = new ApiVersions();
this.transactionManager = configureTransactionState(config, logContext);
//12.定义缓冲区
this.accumulator = new RecordAccumulator(logContext,
config.getInt(ProducerConfig.BATCH_SIZE_CONFIG),
this.compressionType,
lingerMs(config),
retryBackoffMs,
deliveryTimeoutMs,
metrics,
PRODUCER_METRIC_GROUP_NAME,
time,
apiVersions,
transactionManager,
new BufferPool(this.totalMemorySize, config.getInt(ProducerConfig.BATCH_SIZE_CONFIG), metrics, time, PRODUCER_METRIC_GROUP_NAME));
List<InetSocketAddress> addresses = ClientUtils.parseAndValidateAddresses(
config.getList(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG),
config.getString(ProducerConfig.CLIENT_DNS_LOOKUP_CONFIG));
//13,metadata包含了kafka集群元素信息,主要有:kafka集群的节点有哪些,有哪些topic
//每个topic有哪些分区,topic的ISR列表,ISR列表分布在哪些节点上,leader partition在哪些节点上。
//要想获得metadata需要向集群请求获得。
if (metadata != null) {
this.metadata = metadata;
} else {
this.metadata = new ProducerMetadata(retryBackoffMs,
config.getLong(ProducerConfig.METADATA_MAX_AGE_CONFIG),
config.getLong(ProducerConfig.METADATA_MAX_IDLE_CONFIG),
logContext,
clusterResourceListeners,
Time.SYSTEM);
this.metadata.bootstrap(addresses);
}
this.errors = this.metrics.sensor("errors");
//14.初始化sender线程类
this.sender = newSender(logContext, kafkaClient, this.metadata);
String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
this.ioThread.start();
config.logUnused();
AppInfoParser.registerAppInfo(JMX_PREFIX, clientId, metrics, time.milliseconds());
log.debug("Kafka producer started");
} catch (Throwable t) {
close(Duration.ofMillis(0), true);
throw new KafkaException("Failed to construct kafka producer", t);
}
}
第一步,得到用户自定义的参数,用户自定义的参数是从客户端加载配置文件读出来的。
第二步,获取配置的客户端生产者的id。
第三步,获取分区器。分区器是可以用户自己定义的,如果没有自定义的分区器就会用自定义的分区器。分区器是用来给消息分配要发送主题的分区的。
第四步,获取失败重试的退避时间。在客户端请求服务端时,可能因为网络或服务端不能正常对外提供服务造成请求超时。一般情况下,请求失败一次会重试,但是如果重试的频率过高有可能造成服务端网络拥堵。所以,重试必须要等一段时间再请求,这就是重试退避时间的由来,Kafka默认是100ms。
接下来,会初始化key的序列化器和value的序列化器。key和value的序列化器是用户在定义KafkaProducer的时候自定义的。
第七步,是消息大小的最大值。默认是1M,如果超过了最大值会报异常。在生产环境中1M一般是不够用的,建议大家配置10M的大小。
第八步,设置缓冲区的大小,默认是32M。
第九步,设置消息压缩的类型。默认是none,表示默认不压缩。在消息发送的过程中,为了提升发送消息的吞吐量会把消息进行压缩再发送。可以定义我们认为合适的压缩类型。
第十步,设置最大的阻塞时间,默认60S。这里的最大阻塞时间是指从消息开始发送到把消息发送到缓存区消耗的最大时间。
第十一步,设置消息投递超时时间,默认120S。消息投递时间是从发送到收到响应的时间。
第十二步,初始化accumulator,设置了几个参数,我选几个重要的讲下。
batchSize:批次大小,默认16k。lingerMs:消息批次延迟多久再发送。因为如果消息生产比较慢,而发送比较频繁会造成许多批次没有装满消息就发送出去了,设置延迟时间后批次会尽量积累较多的消息再发送出去。优点是减少了网络请求的次数,缺点是消息发送会人为地延迟。
第十三步,初始化元数据对象,metadata是保存在客户端内存中,并与服务端真实的元数据保持准实时数据一致。metadata包含了Kafka集群元素信息,主要有:Kafka集群的节点有哪些,有哪些topic,每个topic有哪些分区,topic的ISR列表,ISR列表分布在哪些节点上,leader partition在哪些节点上,等等。
metadata的数据是要通过网络请求服务端获得的,这里做的仅仅是初始化,而初始化MetaData的时候会设置几个重要参数。
retryBackoffMs:重试退避时间。默认100MS。metadata的数据是请求服务端获得的,这就有可能失败,失败就会涉及到重试,重试太频繁会导致网络拥堵等问题,所以要设置合适的重试间隔时间。metadata.max.age.ms:元数据过期时间。默认5分钟。由于分区变动或机器中有的机器宕机等原因造成元数据的变动,为了保持一致,客户端需要定时请求服务端更新元数据,这里设置的参数就是元数据过期时间。
第十四步,初始化sender,同时也初始化了sender的底层组件NetworkClient,NetworkClient为Sender提供了网络IO的功能。
第十五步,封装并启动sender线程。用ioThread线程类封装Sender线程类,并用ioThread从后台启动Sender线程类。
好,KafkaProducer的字段和构造方法介绍完了,下面介绍异步发送消息的方法。
方法doSend()
这个方法的功能是把消息发送到缓冲区,然后直接返回而不会真的发送消息,而真正的发送是等待Sender线程把消息从缓冲区取出来再发送。相当于异步发送消息。这样的异步发送消息的设计性能和效率都很高。好,下面是发送消息的源码,我来给大家讲解一下。
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
try {
throwIfProducerClosed();
long nowMs = time.milliseconds();
ClusterAndWaitTime clusterAndWaitTime;
try {
//1.等待元数据更新
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), nowMs, maxBlockTimeMs);
} catch (KafkaException e) {
if (metadata.isClosed())
throw new KafkaException("Producer closed while send in progress", e);
throw e;
}
nowMs += clusterAndWaitTime.waitedOnMetadataMs;
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);
Cluster cluster = clusterAndWaitTime.cluster;
byte[] serializedKey;
//2.序列化key
try {
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +
" specified in key.serializer", cce);
}
byte[] serializedValue;
//3.序列化 value
try {
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +
" specified in value.serializer", cce);
}
//4.消息路由到分区。
int partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
setReadOnly(record.headers());
Header[] headers = record.headers().toArray();
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),
compressionType, serializedKey, serializedValue, headers);
//5.验证消息的大小
ensureValidRecordSize(serializedSize);
long timestamp = record.timestamp() == null ? nowMs : record.timestamp();
if (log.isTraceEnabled()) {
log.trace("Attempting to append record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition);
}
// 6.把回调方法和拦截器组装成一个对象
Callback interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
if (transactionManager != null && transactionManager.isTransactional()) {
transactionManager.failIfNotReadyForSend();
}
// 7.把消息加到缓冲区中
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, true, nowMs);
if (result.abortForNewBatch) {
int prevPartition = partition;
partitioner.onNewBatch(record.topic(), cluster, prevPartition);
partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
if (log.isTraceEnabled()) {
log.trace("Retrying append due to new batch creation for topic {} partition {}. The old partition was {}", record.topic(), partition, prevPartition);
}
interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, false, nowMs);
}
if (transactionManager != null && transactionManager.isTransactional())
transactionManager.maybeAddPartitionToTransaction(tp);
// 8.唤醒sender线程。
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
return result.future;
} catch (ApiException e) {
log.debug("Exception occurred during message send:", e);
if (callback != null)
callback.onCompletion(null, e);
this.errors.record();
this.interceptors.onSendError(record, tp, e);
return new FutureFailure(e);
} catch (InterruptedException e) {
this.errors.record();
this.interceptors.onSendError(record, tp, e);
throw new InterruptException(e);
} catch (KafkaException e) {
this.errors.record();
this.interceptors.onSendError(record, tp, e);
throw e;
} catch (Exception e) {
this.interceptors.onSendError(record, tp, e);
throw e;
}
}
我们来分析下发送消息的逻辑。
第一步,调用waitOnMetadata()方法同步等待拉取元数据,如果生产端内存中没有主题相关的分区就会发送网络请求服务端更新最新的元数据信息。同时会把最大阻塞时间参数maxBlockTimeMs传进去,在方法waitOnMetadata()返回后根据方法耗费的时间计算阻塞时间还剩多少,剩余等待时间等于最大阻塞时间减去等待元数据更新的时间。
第二步,根据提供的序列化类型序列化key。
第三步,根据提供的序列化类型序列化value。
第四步,获取消息要路由到的分区。根据消息,序列化后的key、value、元数据分配对应的分区。
第五步,计算序列化后的消息大小,判断是否超出对消息大小的限制。具体判断逻辑如下:
private void ensureValidRecordSize(int size) {
//消息大小的限制,默认1M
if (size > maxRequestSize)
throw new RecordTooLargeException("The message is " + size +
" bytes when serialized which is larger than " + maxRequestSize + ", which is the value of the " +
ProducerConfig.MAX_REQUEST_SIZE_CONFIG + " configuration.");
//缓冲区大小限制,默认32M
if (size > totalMemorySize)
throw new RecordTooLargeException("The message is " + size +
" bytes when serialized which is larger than the total memory buffer you have configured with the " +
ProducerConfig.BUFFER_MEMORY_CONFIG +
" configuration.");
}
主要有两个条件的限制。
maxRequestSize:默认1M,可以根据实际情况配置。大于这个数就会抛出相应的异常。
totalMemorySize:默认32M,可以根据实际情况配置。大于这个数就会抛出相应的异常。
第六步,把回调方法和拦截器组装成一个对象。后面的步骤会统一给消息配置上这个对象。回调方法是为了收到响应时返回生产者响应的数据,拦截器对响应的数据有过滤功能。
第七步,把消息加到缓冲区的批次里。
第八步,唤醒sender线程。加入到缓存区以后,根据返回判断缓存区对应的批次是否满了或新创建了数据,如果满足条件说明满足发送条件了,这时候要唤醒sender线程,sender线程会从缓冲区抽取批次进程发送。
确实,
doSend()方法是 Kafka 生产者实现异步消息发送机制的关键部分。这个方法不会立即把消息发送到 Kafka 服务器,而是将消息放入一个缓冲区中,并且几乎立即返回给调用者。实际的消息发送是由另一个后台线程(通常称为 Sender 线程)来处理的。这种设计有几个优点:
提高吞吐量:通过批量发送消息而不是一条条地发送,可以显著减少网络开销,从而提高整体吞吐量。
降低延迟:主线程(即应用程序的业务线程)不需要等待消息真正被发送出去,这可以大大降低应用程序的响应时间。
资源利用率:Sender 线程可以在后台高效地管理多个连接和消息的发送,这样可以更好地利用系统资源。
下面是
doSend()方法在 KafkaProducer 中的大致工作流程:doSend() 方法的主要步骤
序列化键值对:
将传入的
ProducerRecord的 key 和 value 进行序列化,转换为字节数组形式。拦截器处理:
如果配置了拦截器,那么会在消息被加入到缓冲区之前执行拦截器链上的逻辑。
分配分区:
如果
ProducerRecord没有指定目标分区,则根据配置的分区策略选择一个合适的分区。创建批次:
创建一个新的或使用现有的
RecordBatch对象来存放待发送的消息。根据配置的批处理大小、压缩类型等因素,决定是否将当前记录添加到现有批次中还是创建新的批次。
加入缓冲区:
将包含新记录的批次添加到内存中的缓冲区(accumulator)中。
触发发送:
更新内部状态以标记需要发送的数据已准备好。
如果满足某些条件(如缓存达到一定大小),可能会立即触发 Sender 线程尝试发送这些数据。
回调设置:
设置好回调函数,以便在消息成功发送或失败时通知应用程序。
Sender 线程的工作
定时唤醒:Sender 线程通常会定期检查是否有新的数据需要发送。
从缓冲区取出数据:它会从 accumulator 中取出准备好的批次。
构建请求:构造适当的
ProduceRequest,并将其发送到相应的 Kafka broker。处理响应:接收来自 broker 的响应,并根据结果更新元数据、重试发送等。
执行回调:如果配置了回调函数,则在此处执行回调。
通过这种方式,KafkaProducer 实现了一个高效的异步消息发送架构,使得生产者能够快速响应,同时保证了高吞吐量和低延迟。
获取分区
接下来我们根据源码讨论下分区,doSend()方法的第四步是选择消息要发送的分区,我们从这里开始分析,如下面的源码所示:
private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) {
Integer partition = record.partition();
return partition != null ?
partition :
partitioner.partition(
record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);
}
先判断消息里是否指定了要发送的partition,如果指定了,就用指定的partition;如没有指定,则用分区器选择分区。当我们没有指定分区器的时候,会用默认的分区器DefaultPartitioner。
类DefaultPartitioner
接下来我们分析下DefaultPartitioner的源码中的分区方法partition()。
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster,
int numPartitions) {
//如果没有key就用stickyPartition的策略选取分区
if (keyBytes == null) {
return stickyPartitionCache.partition(topic, cluster);
}
// hash the keyBytes to choose a partition
// 如果有key,就用key对分区数哈希取模获取分区
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
如果有key,就用key对分区数哈希取模获取分区,如果没有key就用stickyPartition的策略选取分区。
我们接下来分析stickyPartition的策略,stickyPartition的策略是在StickyPartitionCache类里实现的。
类StickyPartitionCache
这个类的核心逻辑就是当存在无key的序列消息时,我们消息发送的分区优先保持粘连,如果当前分区下的batch已经满了或者 linger.ms延迟时间已到开始发送,就会重新启动一个新的分区。流程图如下:
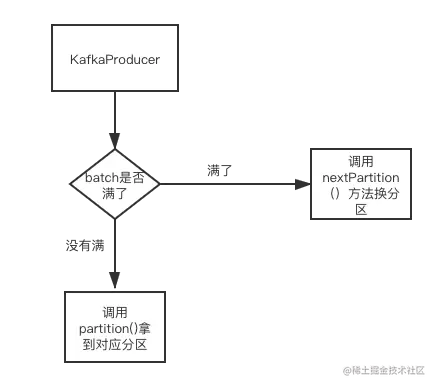
这样设计的好处是:可以最大限度地保障每个batch的消息足够多,并且不至于会有过多的空batch提前申请,因为轮询分区模式下,一组序列消息总是会被分散到各个分区中,会导致每个batch的消息不够大,最终会导致客户端请求频次过多,而Sticky的模式可以降低请求频次。
源码在下面,我给大家讲解一下:
public class StickyPartitionCache {
//保存给主题分配的对应分区的集合。
private final ConcurrentMap<String, Integer> indexCache;
public StickyPartitionCache() {
this.indexCache = new ConcurrentHashMap<>();
}
//返回主题对应的分区
public int partition(String topic, Cluster cluster) {
Integer part = indexCache.get(topic);
if (part == null) {
return nextPartition(topic, cluster, -1);
}
return part;
}
//换取topic对应发送分区
public int nextPartition(String topic, Cluster cluster, int prevPartition) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
Integer oldPart = indexCache.get(topic);
Integer newPart = oldPart;
// 分区没有设置对应的分区或因为新的批次触发了需要换分区的需求
if (oldPart == null || oldPart == prevPartition) {
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
//没有可用的分区
if (availablePartitions.size() < 1) {
Integer random = Utils.toPositive(ThreadLocalRandom.current().nextInt());
newPart = random % partitions.size();
//只有一个可用的分区
} else if (availablePartitions.size() == 1) {
newPart = availablePartitions.get(0).partition();
} else {
// 1.newPart == null:给新主题申请发送分区
// 2.newPart.equals(oldPart):对于原来就分配了分区的会循环哈希到跟上个不一样的分区
while (newPart == null || newPart.equals(oldPart)) {
Integer random = Utils.toPositive(ThreadLocalRandom.current().nextInt());
newPart = availablePartitions.get(random % availablePartitions.size()).partition();
}
}
if (oldPart == null) {
indexCache.putIfAbsent(topic, newPart);
} else {
//有可能被别的线程提前申请了新的分区
indexCache.replace(topic, prevPartition, newPart);
}
return indexCache.get(topic);
}
//返回要发送的分区
return indexCache.get(topic);
}
}
字段indexCache。这是一个map集合,key是主题,value是要发送到这个主题的分区编号。
方法partition()。如果indexCache中有主题对应的分区,就返回这个分区;如果没有,就给新的主题申请分区.
方法nextPartiion()。调用这个方法的时机有两个:一个是主题对应的发送分区为空,需要新分配分区;另一个是KafkaProducer写缓冲区时一个批次满了需要换批次,这时也需要换主题对应的分区。
总结
在这节课中,我首先给你讲解了主线程和Sender线程的工作流程,以及涉及到的模块。然后根据源码介绍了KafkaProducer是如何把消息发送到缓存区的,包括获取元数据、序列化key和value、选择分区、验证消息大小是否合法、唤醒Sender线程。最后,还分析了Kafka默认分区的逻辑,以及sticky partition给网络性能带来的好处。
在 Kafka 中,消息是按照主题(topic)进行分类的,而每个主题又可以划分为多个分区(partition)。当生产者发送消息时,它需要决定将消息发送到哪个分区。这个过程通常称为“分区选择”或“分区分配”。doSend() 方法中的第四步就是确定消息应该发送到哪个分区。
分区选择的过程
在 doSend() 方法中,如果 ProducerRecord 已经指定了分区(即 partition 字段不为 null),那么就直接使用该分区。如果没有指定分区,则会根据配置的分区器(partitioner)来决定分区。
1. 检查是否已经指定了分区
如果
ProducerRecord中的partition字段已经被设置,那么直接使用这个分区。
int partition = record.partition();
if (partition == Metadata.INVALID_PARTITION) {
// 分区未指定,需要通过分区器来选择一个分区
}2. 使用分区器选择分区
如果没有指定分区,Kafka 会使用默认的分区器
DefaultPartitioner或者用户自定义的分区器。默认分区器会根据键(key)来进行分区选择。如果键为 null,则会采用轮询的方式选择分区;如果键不为 null,则会对键进行哈希处理,并根据结果选择分区。
// 获取集群元数据
Cluster cluster = metadata.fetch();
// 获取主题的所有分区信息
List<PartitionInfo> partitions = cluster.partitionsForTopic(record.topic());
// 根据 key 和分区数选择一个分区
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = counter.getAndIncrement();
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(record.topic());
if (availablePartitions.size() > 0) {
partition = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(partition).partition();
} else {
// no partitions are available, give a non-available partition
partition = Utils.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
long hash = Utils.murmur2(keyBytes);
partition = Math.abs(hash) % numPartitions;
}3. 自定义分区器
用户可以通过实现
org.apache.kafka.clients.producer.Partitioner接口来自定义分区逻辑。这允许更复杂的分区策略,比如基于特定业务逻辑来分配分区。
分区器接口示例
public interface Partitioner {
/**
* Compute the partition for the given record.
*/
public abstract int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
/**
* This is called when partitioner is closed
*/
public void close();
/**
* This is called to configure the partitioner with the configs the user provided
*/
public void configure(Map<String, ?> configs);
}示例:自定义分区器
假设我们想要创建一个简单的自定义分区器,它总是将奇数键值的消息发送到偶数编号的分区,将偶数键值的消息发送到奇数编号的分区:
public class CustomPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if ((Integer)key % 2 == 0)
return 1; // 假设至少有两个分区
else
return 0;
}
@Override
public void close() {}
@Override
public void configure(Map<String, ?> configs) {}
}然后在生产者的配置中设置这个自定义分区器:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.IntegerSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("partitioner.class", "com.example.CustomPartitioner");
KafkaProducer<Integer, String> producer = new KafkaProducer<>(props);这样,每当发送消息时,就会使用自定义的分区器来决定消息应该发送到哪个分区。
3.消息在缓冲区是如何存储的?
我们知道 Kafka 是一个吞吐量很高的消息队列,在生产者这里也有体现。其实,高吞吐最普遍的实现是异步、批量和压缩。从这节课开始在讲解的过程中,会涉及 Kafka 生产端发送消息时实现异步、批量和压缩的代码设计。下面给大家简单讲一下生产者发送消息时是如何实现异步发送和批量发送的。
异步发送:对于生产者异步发送来说,Kafka生产者有同步和异步两种方式来发送消息,但实际上都是通过异步方式实现的。也就是说,生产者主线程发送后不会阻塞,而是继续发送下条消息,并通过回调方法异步处理响应从而判断消息是否发送成功,而真正发送消息的是Sender 的子线程。这样设计的好处是业务发送消息和网络发送消息解耦,能够提升消息发送的速度。批量发送:Kafka生产者会把消息暂时保存在缓冲区中,然后满足一定条件时, Sender 的子线程把消息批量发送给 Kafka 服务端。批量发送的好处是能够减少网络请求的次数,进而提升网络吞吐量。消息压缩:生产者负责根据配置的压缩算法,消费者拉取消息时进行解压,服务端存储的消息都是压缩过得。通过消息压缩减少了网络带宽和磁盘的使用效率。
那缓冲区的消息都在哪里呢?它们又是怎样被管理的呢?
RecordAccumulator 类
缓存的消息主要位于 RecordAccumulator 类中,所以在学习消息缓冲之前你还得先了解下RecordAccumulator处理消息缓冲的流程,如下图所示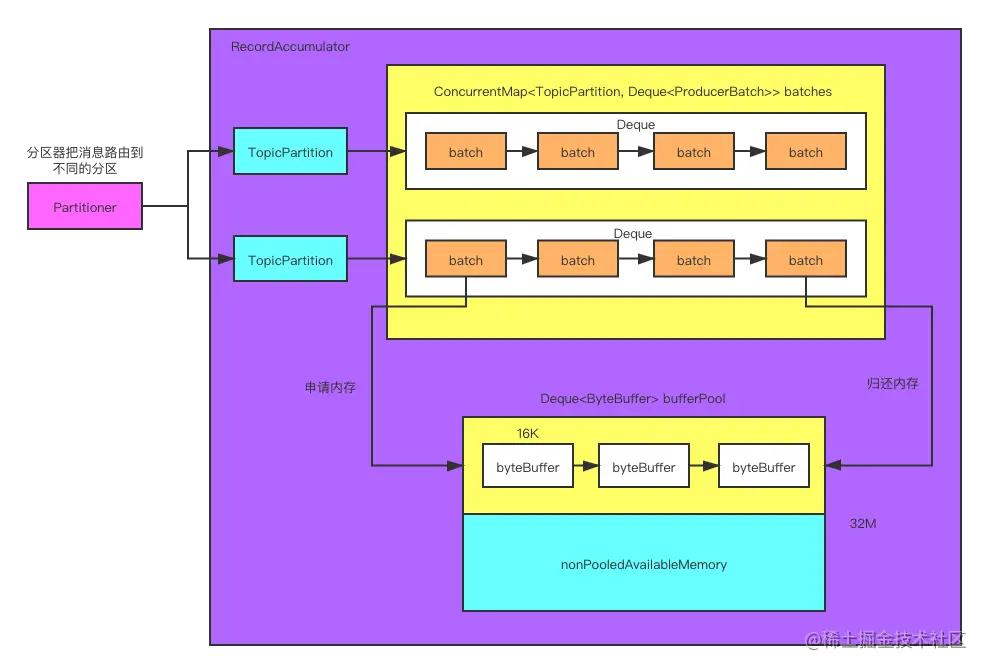
从流程图中,我们可以得出以下信息:
在RecordAccumulator中有一个CopyOnWriteMap集合batches。key是主题分区,value是ProducerBatch队列,每个分区都对应一个队列。队列中的元素是批次 ProducerBatch,消息就是封装在这些批次里进行缓存的。
当生产者生产消息时,消息会通过分区器Partitioner保存在不同的队列里。如果消息的大小比一个批次的空间小,那么一个批次里就会有多个消息。
要通过ProducerBatch缓存数据,那我们就需要申请内存空间,内存空间的申请是通过内存缓存池bufferPool实现的。
从以上的讲解我们可以看出,RecordAccumulator中有三个重要的组件:消息批次ProducerBatch、Kafka自定义的保存批次的集合CopyOnWriteMap和缓存池BufferPool。
今天这一讲我们会重点讲解其中的消息批次ProducerBatch以及ProducerBatch底层依赖的类,这是消息缓冲的最小单位,也是发送消息的最小单位。另外两个组件会在下一节课讲解,这两个组件分别是:
CopyOnWriteMap。实现了对缓冲区的管理,同时在并发场景下性能很好。缓冲池bufferPool。缓冲池bufferPool预先申请了固定大小的内存,缓冲区需要内存的时候可以从bufferPool申请内存,内存用完了可以释放回bufferPool,这样的设计可以避免内存对象反复申请和销毁,从而提升性能。
确实,RecordAccumulator 是 Kafka 生产者中用于临时存储待发送消息的核心组件。它通过 CopyOnWriteMap 来管理不同主题和分区的消息批次,并使用 BufferPool 来高效地管理内存分配。下面详细解释这三个组件的作用以及它们是如何协同工作的。
1. 消息批次 ProducerBatch
定义:
ProducerBatch是一个内部类,用于表示一批将要发送到 Kafka 服务器的消息。结构: 它包含了一系列的消息记录、相关的元数据(如偏移量、时间戳等),以及一些辅助信息(如压缩类型)。
功能:
封装多条消息以便批量发送。
支持压缩以减少网络传输开销。
提供方法来序列化和反序列化消息。
2. 保存批次的集合 CopyOnWriteMap
定义:
CopyOnWriteMap是 Kafka 内部实现的一种线程安全的映射表,用于在并发环境中管理RecordAccumulator中的消息批次。结构: 键是
TopicPartition对象,值是一个双端队列Deque<ProducerBatch>。功能:
线程安全: 由于生产者可能有多个线程同时写入不同的分区,
CopyOnWriteMap保证了读写操作的线程安全性。快速查找: 提供快速的查找机制,使得 Sender 线程可以迅速找到需要发送的批次。
批次管理: 允许按主题和分区组织消息批次,方便管理和发送。
3. 缓存池 BufferPool
定义:
BufferPool是 Kafka 内部实现的一个内存池,用于管理ProducerBatch的内存分配。结构: 它维护了一个缓存池,用于存储可重用的内存块。
功能:
内存复用: 通过重用内存块,减少频繁的内存分配和回收带来的开销。
内存限制: 可以设置总的内存限制,避免占用过多系统资源。
高效分配: 提供高效的内存分配和释放机制,确保在高吞吐量情况下也能快速响应。
工作流程
消息生成:
应用程序调用
KafkaProducer.send()方法生成消息。消息通过序列化转换为字节数组。
分区选择:
如果消息没有指定分区,则通过
Partitioner选择一个合适的分区。
批次创建:
根据选定的分区,从
CopyOnWriteMap中获取或创建对应的Deque<ProducerBatch>。如果当前批次未满且有足够的空间容纳新消息,则将消息添加到现有批次中;否则,创建一个新的
ProducerBatch并将其加入队列。
内存分配:
创建
ProducerBatch时,会从BufferPool中申请所需的内存空间。如果
BufferPool中有可用的内存块,则直接使用;如果没有,则分配新的内存块。
Sender 线程处理:
后台的 Sender 线程定期检查
RecordAccumulator,从CopyOnWriteMap中取出准备好的ProducerBatch。使用
NetworkClient发送这些批次到相应的 Kafka 服务器。
内存释放:
当批次成功发送或失败后,释放该批次占用的内存,并将其返回给
BufferPool以便后续重用。
总结
ProducerBatch用于封装和管理一批消息。CopyOnWriteMap用于按主题和分区组织和管理这些批次。BufferPool用于高效地管理内存分配,确保内存使用的效率和性能。
这种设计使得 Kafka 生产者能够高效地批量发送消息,同时保持良好的性能和较低的延迟。如果你对某个具体部分有更多的疑问或者需要更详细的代码示例,请告诉我!
在 Kafka 生产者中,消息并不是直接发送到 Kafka 服务器的,而是先被放入一个缓冲区(也称为累加器
accumulator),然后由后台的 Sender 线程定期从这个缓冲区中取出消息并发送到 Kafka 服务器。这个过程是异步的,可以显著提高生产者的性能和吞吐量。消息在缓冲区中的存储
1. 缓冲区结构
累加器 (Accumulator): 这是一个内存中的数据结构,用于临时存储待发送的消息。它按照主题和分区来组织消息,确保每个分区的消息可以被一起发送。
批次 (Batch): 在累加器中,消息是以批次的形式存储的。每个批次包含一组将要发送到同一个主题和分区的消息。批次有助于减少网络 I/O 开销,因为多个小消息可以被打包成一个大请求进行传输。
2. 消息如何进入缓冲区
当调用
KafkaProducer.send()方法时,消息会被序列化,并根据配置的分区策略分配到相应的分区。分配好分区后,消息会被加入到对应的主题和分区的批次中。如果该分区还没有创建批次,则会创建一个新的批次。
如果批次已满或达到了最大等待时间(由
linger.ms参数控制),则该批次会被标记为可发送状态。3. 批次管理
大小限制: 批次有大小限制(通过
batch.size配置项设置),当批次达到这个大小时,即使没有达到linger.ms的等待时间,也会被发送出去。压缩: 根据
compression.type配置,批次中的消息可能会被压缩以节省带宽。超时处理: 如果某个批次在一段时间内(由
max.block.ms控制)没有被发送出去,生产者可能会抛出异常或阻塞。4. 发送流程
Sender 线程: 后台有一个 Sender 线程负责从累加器中取出已经准备好发送的批次,并将其发送到 Kafka 服务器。
元数据更新: 在发送之前,Sender 线程会检查当前的集群元数据是否是最新的,如果不是,则会更新元数据。
网络客户端 (NetworkClient): Sender 线程使用
NetworkClient来与 Kafka 服务器进行通信,发送ProduceRequest并接收响应。缓冲区的内部实现细节
RecordAccumulator 类是累加器的具体实现。它维护了一个双层映射结构:外层是主题,内层是分区。
每个分区都有一个
Deque<RecordBatch>结构,用于存储该分区的所有批次。
RecordBatch是实际存储消息的地方,它包含了消息的数据、偏移量信息以及其他元数据。总结
消息在缓冲区中是以批次的形式存储的,每个批次代表了一组即将发送到相同主题和分区的消息。
缓冲区的设计使得生产者可以在不阻塞主线程的情况下高效地批量发送消息。
Sender 线程负责从缓冲区中取出批次并发送给 Kafka 服务器,同时处理网络 I/O 和错误重试等逻辑。
这种设计不仅提高了消息发送的效率,还减少了网络延迟,从而使得 Kafka 生产者能够支持高吞吐量的应用场景。
,我们开始学习表示消息批次的类 ProducerBatch,我们先看一下ProducerBatch相关类的关系图:
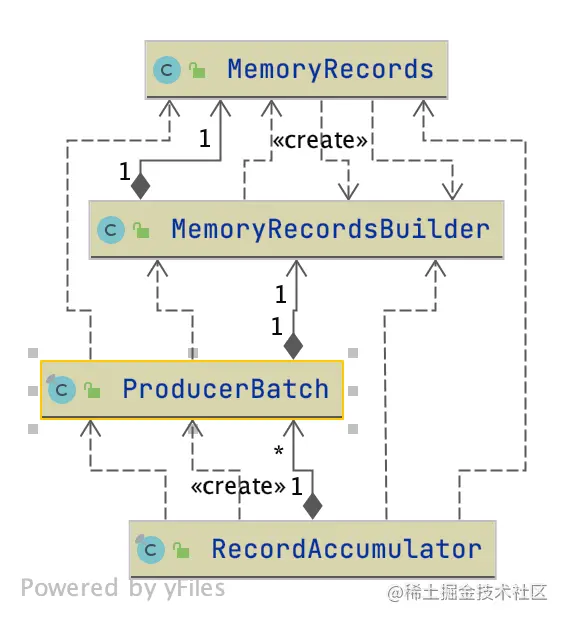
我来讲解一下这个类图:RecordAccumulator通过ProducerBatch保存一批消息,ProducerBatch依赖MemoryRecordBuilder构建MemoryRecords用来保存数据,所以MemoryRecords才是真正保存消息的地方。
也就是说,要想理解消息批次ProducerBatch,我们还要理解MemoryRecords、MemoryRecordBuilder。因此,这里我们先讲解MemoryRecords,然后讲解MemoryRecordBuilder,最后讲解ProducerBatch。
好,我们开始讲解MemoryRecords 类
好的,让我们从 MemoryRecords 类开始讲解。MemoryRecords 是 Kafka 中用于在内存中存储和操作消息记录的核心类。它提供了对消息的高效读写操作,并支持压缩功能。
MemoryRecords 类
MemoryRecords 是一个抽象类,它代表了一组按顺序排列的消息记录(records)。这些记录可以被压缩或不压缩地存储在内存中。MemoryRecords 提供了多种方法来创建、读取和操作这些记录。
主要特性
压缩支持:
MemoryRecords支持多种压缩格式,如 GZIP、Snappy 和 LZ4。压缩可以显著减少网络传输的数据量,提高整体性能。
高效的读写操作:
通过使用直接字节缓冲区(DirectByteBuffer),
MemoryRecords提供了高效的内存访问和操作。它支持随机访问和顺序访问,使得读取特定消息记录变得简单。
元数据管理:
每个
MemoryRecords实例都包含一些元数据,如偏移量、时间戳等,这些信息对于消息的处理和管理非常重要。
构造函数和主要方法
构造函数:
MemoryRecords通常不是直接实例化的,而是通过其子类(如DefaultRecordBatch)或工厂方法创建的。
主要方法:
writeTo(ByteBuffer buffer): 将MemoryRecords的内容写入给定的ByteBuffer。iterator(): 返回一个迭代器,用于遍历MemoryRecords中的所有记录。validBytes(): 返回MemoryRecords中有效数据的长度。isCompressed(): 判断MemoryRecords是否是压缩的。compressionType(): 返回MemoryRecords使用的压缩类型。sizeInBytes(): 返回MemoryRecords在内存中的大小。hasLogAppendTime(): 判断MemoryRecords是否包含日志追加时间。logAppendTime(): 获取日志追加时间。
MemoryRecordBuilder 类
MemoryRecordBuilder 是用于构建 MemoryRecords 的工具类。它允许你逐步添加消息记录,并最终生成一个 MemoryRecords 实例。
主要方法
添加记录:
append(Record record): 添加一条记录到MemoryRecordBuilder中。appendWithOffset(long offset, long timestamp, byte[] key, byte[] value, Header[] headers): 添加一条带有指定偏移量、时间戳、键值对和头信息的记录。
构建
MemoryRecords:build(): 根据当前添加的记录生成一个MemoryRecords实例。buildWithPadding(int size): 生成一个MemoryRecords实例,并确保其大小至少为指定的size。
获取状态信息:
sizeInBytes(): 返回当前MemoryRecordBuilder中所有记录的总大小。estimatedSizeInBytesUpperBound(): 返回一个估计的上界大小,包括可能的额外开销。
ProducerBatch 类
ProducerBatch 是 Kafka 生产者用来表示一批将要发送到 Kafka 服务器的消息的内部类。它依赖于 MemoryRecords 来实际存储消息数据。
主要特性
消息批次:
ProducerBatch包含一组消息记录,这些记录被封装在一个MemoryRecords实例中。
批处理属性:
ProducerBatch保存了一些批处理相关的属性,如目标主题分区、是否已准备好发送等。
内存管理:
ProducerBatch与BufferPool协同工作,以高效地管理和重用内存。
主要方法
构造函数:
ProducerBatch(TopicPartition partition, ByteBuffer buffer, int maxAllowedSize, CompressionType compressionType, TimestampType timestampType, boolean isTransactional, long baseOffset, long producerId, short producerEpoch, boolean isControlBatch): 创建一个新的ProducerBatch实例。
主要方法:
done(): 标记该批次已经准备好发送。drain(): 将MemoryRecords的内容写入给定的ByteBuffer。remainingCapacity(): 返回ProducerBatch还能容纳多少数据。records(): 返回ProducerBatch中的MemoryRecords实例。partition(): 返回目标主题分区。setException(RuntimeException exception): 设置异常,表示该批次在发送过程中遇到了问题。exception(): 获取该批次的异常信息。
总结
MemoryRecords: 用于在内存中存储和操作消息记录,支持压缩和高效的读写操作。
MemoryRecordBuilder: 用于构建
MemoryRecords,允许逐步添加记录并生成MemoryRecords实例。ProducerBatch: 用于表示一批将要发送到 Kafka 服务器的消息,依赖
MemoryRecords存储实际的消息数据,并与BufferPool协同工作以管理内存。
理解这三个组件是如何协同工作的,可以帮助我们更好地了解 Kafka 生产者如何高效地批量发送消息。如果你有更具体的问题或者需要进一步的代码示例,请告诉我!
MemoryRecords类
MemoryRecords类是保存了多个消息的集合,底层封装了JavaNIO的ByteBuffer用来存储消息数据。
MemoryRecordsBuilder类的创建就是依赖于MemoryRecords里的方法builder()。builder() 方法的源码如下:
public static MemoryRecordsBuilder builder(ByteBuffer buffer,
byte magic,
CompressionType compressionType,
TimestampType timestampType,
long baseOffset,
long logAppendTime,
long producerId,
short producerEpoch,
int baseSequence,
boolean isTransactional,
boolean isControlBatch,
int partitionLeaderEpoch) {
return new MemoryRecordsBuilder(buffer, magic, compressionType, timestampType, baseOffset,
logAppendTime, producerId, producerEpoch, baseSequence, isTransactional, isControlBatch, partitionLeaderEpoch,
buffer.remaining());
}
这段代码还是比较好理解的,可以看到,builder()方法会根据分配到的ByteBuffer、消息版本、消息压缩类型、基本位移等参数构建出MemoryRecordsBuilder类。
MemoryRecordsBuilder类
MemoryRecordsBuilder类封装了向ByteBuffer里写数据的功能。我们先学习相关字段和构造方法,再通过学习重要方法学习这个类具体做了哪些事情。
字段
关于 MemoryRecordsBuilder 对应的字段,你可以参考下面这段代码:
public class MemoryRecordsBuilder implements AutoCloseable {
//禁止写入的输出流
private static final DataOutputStream CLOSED_STREAM = new DataOutputStream(new OutputStream() {
@Override
public void write(int b) {
throw new IllegalStateException("MemoryRecordsBuilder is closed for record appends");
}
});
//消息压缩类型
private final CompressionType compressionType;
// kafka对OutputStream接口的实现类,实现了对bytebuffer的扩容
private final ByteBufferOutputStream bufferStream;
// 消息的版本
private final byte magic;
// ByteBuffer的初始位置
private final int initialPosition;
//基本位移
private final long baseOffset;
//追加消息的时间
private final long logAppendTime;
//是否是控制类的批次
private final boolean isControlBatch;
//分区leader的版本
private final int partitionLeaderEpoch;
//写模型下的limit
private final int writeLimit;
//batch头大小
private final int batchHeaderSizeInBytes;
// 评估压缩率
private float estimatedCompressionRatio = 1.0F;
// 给ByteBuffer增加压缩的功能
private DataOutputStream appendStream;
// 这个批次是否是事务的一部分
private boolean isTransactional;
// 生产者id
private long producerId;
// 生产者版本
private short producerEpoch;
// 批次序列号
private int baseSequence;
// 压缩前要写入的消息体大小
private int uncompressedRecordsSizeInBytes = 0;
// 记录数
private int numRecords = 0;
// 实际压缩率
private float actualCompressionRatio = 1;
//最后的偏移量
private Long lastOffset = null;
//第一次追加消息的时间戳
private Long firstTimestamp = null;
//真正保存消息的地方
private MemoryRecords builtRecords;
//是否终止
private boolean aborted = false;
这里我们只讲解其中的几个重点字段,其他的都比较好理解,这里我就不赘述了。
CLOSED_STREAM:写操作关闭的输出流。在关闭某个ByteBuffer的时候会把ByteBuffer对应的输出流设置为CLOSED_STREAM,防止再向 ByteBuffer 中写数据,否则就会抛出异常。CompressionType:枚举类。指消息的压缩类型。有5 种压缩类型:NONE、GZIP、SNAPPY、LZ4、ZSTD。NONE表示数据不压缩,其他4个分别对应不同的压缩类型。bufferStream:类型是ByteBufferOutputStream类。ByteBufferOutputStream继承了OutputStream并封装了ByteBuffer,除了对ByteBuffer基本操作的封装,还增加了对ByteBuffer扩容的功能。
ByteBuffer 扩容的功能是ByteBufferOutputStream 类对OutputStream类的一个增强功能,实现了对ByteBuffer的扩容,代码如下:
private void expandBuffer(int remainingRequired) {
//1.评估需要多少空间
int expandSize = Math.max((int) (buffer.limit() * REALLOCATION_FACTOR), buffer.position() + remainingRequired);
//2.申请新的ByteBuffer
ByteBuffer temp = ByteBuffer.allocate(expandSize);
//3.获得写模式的limit
int limit = limit();
//4.把写状态转换为读状态
buffer.flip();
//5.读到temp里
temp.put(buffer);
//6.改成写时候的limit
buffer.limit(limit);
//7.更新原来的buffer的position,防止重复消费
buffer.position(initialPosition);
buffer = temp;
}
第一步,计算需要扩容多少,在扩容因子(默认1.1倍)和真正需要多少字节之间选择最大值。因为扩容需要耗费一定的系统资源,如果每次按实际数据大小扩容每次没有预先分配的空间,这样会造成频繁扩容而浪费资源,有个扩容因子避免了这种情况。
第二步,根据扩容多少申请新的ByteBuffer,所谓扩容就是按照扩容后大小重新申请一个空的ByteBuffer,再把原来ByteBuffer的数据拷贝进去。
最后,把ByteBuffer的引用buffer指向新申请的ByteBuffer。
构造方法
MemoryRecordsBuilder 类的构造方法初始化了几个重要的参数,我给你分析一下:
public MemoryRecordsBuilder(ByteBufferOutputStream bufferStream,
byte magic,
CompressionType compressionType,
TimestampType timestampType,
long baseOffset,
long logAppendTime,
long producerId,
short producerEpoch,
int baseSequence,
boolean isTransactional,
boolean isControlBatch,
int partitionLeaderEpoch,
int writeLimit) {
......忽略
//1.计算Batch头的长度
this.batchHeaderSizeInBytes = AbstractRecords.recordBatchHeaderSizeInBytes(magic, compressionType);
//调整position
bufferStream.position(initialPosition + batchHeaderSizeInBytes);
this.bufferStream = bufferStream;
//增加压缩的功能
this.appendStream = new DataOutputStream(compressionType.wrapForOutput(this.bufferStream, magic));
}
首先计算Batch头的长度,因为不同消息版本batch头的大小都是固定的,所有调整bufferStream的position,让position跳过batch的头部,这样就可以直接写消息的数据了。appendStream为bufferStream增加了压缩功能,ByteBuffer、bufferStream和appendStream三者的关系我用下面这张图来表示:
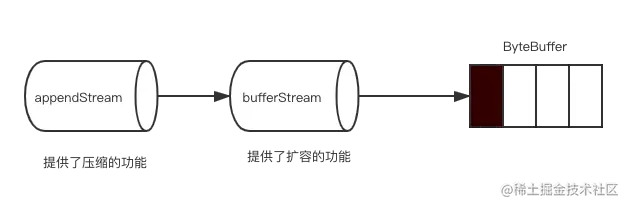
重要方法
appendDefaultRecord()是向缓存写入消息体的方法,代码如下:
private void appendDefaultRecord(long offset, long timestamp, ByteBuffer key, ByteBuffer value,
Header[] headers) throws IOException {
//1.检查是否可以写
ensureOpenForRecordAppend();
//2.计算要写多少偏移量
int offsetDelta = (int) (offset - baseOffset);
//3.计算这次写和第一次写之间的时间差
long timestampDelta = timestamp - firstTimestamp;
//4.把消息写入appendStream,并返回压缩前的消息大小
int sizeInBytes = DefaultRecord.writeTo(appendStream, offsetDelta, timestampDelta, key, value, headers);
//5.消息写入成功后更新相关的数据
recordWritten(offset, timestamp, sizeInBytes);
}
首先,判断是否可写,再计算要写的位移大小,以及这次写入和第一次写的时间差。然后,把位移大小、时间差、key、value、头信息写入appendStream,并返回写入的字节大小。最后,更新相关的数据,如写入消息数、byteBuffer里未压缩前的消息大小、追加信息的时间戳等。
ProducerBatch类
好了,现在来分析ProducerBatch。在介绍 ProducerBatch 之前,我们先介绍下 ProducerBatch 依赖的一个重要组件 ProduceRequestResult。
ProduceRequestResult类
ProduceRequestResult是异步获取消息生产结果的类。
ProduceRequestResult、FutureRecordMetadata、RecordMetadata 是配合起来给 ProducerBatch 使用的。类关系图如下:
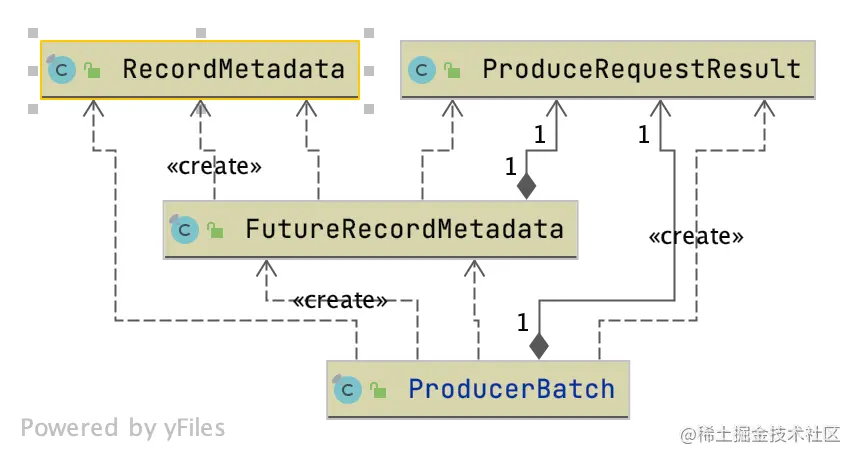
ProduceRequestResult 并没有实现 java.util.concurrent.Future 的接口,但是通过一个 count 为 1 的 CountDownLatch 对象间接地实现了 Future 的功能。
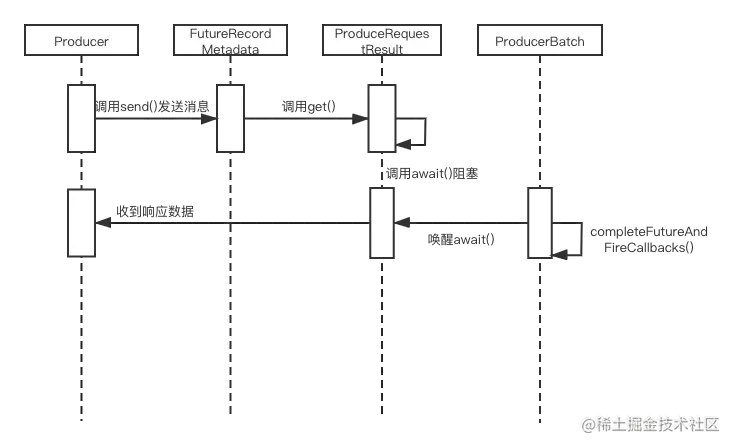
当生产者同步发送消息时会调用 FutureRecordMetadata 的 get() 方法,get() 方法会间接调用 ProduceRequestResult.await(),线程就会等待服务端的响应。当服务端响应来到的时候,无论 ProducerBatch 正常响应或非正常响应都会调用 ProduceRequestResult.done() 方法,而 ProduceRequestResult.done() 方法又是调用了 CountDownLatch 的 countDown() 唤醒了阻塞的主线程。流程图如下:
producerBatch是生产者消息缓存的最小单位,一个producerBatch会存放一个或多个消息,我们也把producerBatch称为批次。
字段
我们先分析相关字段:
//批次最终状态
private enum FinalState { ABORTED, FAILED, SUCCEEDED }
//批次创建时间
final long createdMs;
//批次对应的分区
final TopicPartition topicPartition;
//请求结果的 future
final ProduceRequestResult produceFuture;
//生产者消息的回调方法保存在这里
private final List<Thunk> thunks = new ArrayList<>();
//封装了MemoryRecords对象,用来存储消息
private final MemoryRecordsBuilder recordsBuilder;
//batch的失败重试次数
private final AtomicInteger attempts = new AtomicInteger(0);
//是否是分裂后的批次
private final boolean isSplitBatch;
//ProducerBatch的最终状态
private final AtomicReference<FinalState> finalState = new AtomicReference<>(null);
//保存Record的个数
int recordCount;
//最大Record字节数
int maxRecordSize;
//最后一次失败重试发送的时间戳
private long lastAttemptMs;
//最后一次发送的时间戳
private long lastAppendTime;
//Sender线程拉取批次的时间
private long drainedMs;
//是否失败重试过
private boolean retry;
重点字段的解释如下:
topicPartition:批次对应的分区。
produceFuture:ProduceRequestResult类对象。
thunks:
List<Thunk>类型。Thunk是用来存储消息的callback和响应数据的。recordsBuilder:封装了用来存储消息的ByteBuffer。
attempts:batch的失败重试次数。
isSplitBatch:Bool类型。表示是否是因单个消息过大一个而ProducerBatch存不下,而分裂成多个ProducerBatch存储的情况。
retry:是否失败重试过。
重要方法
关于 ProducerBatch 的方法,这里我们重点讲解以下三个:tryAppend()、done() 和 completeFutureAndFireCallbacks()。
tryAppend()是向producerBatch追加消息的方法,源码如下:
public FutureRecordMetadata tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers, Callback callback, long now) {
//1.检验是否有空间
if (!recordsBuilder.hasRoomFor(timestamp, key, value, headers)) {
return null;
} else {
//2.把消息加入ProducerBatch对应的MemoryRecords中
Long checksum = this.recordsBuilder.append(timestamp, key, value, headers);
this.maxRecordSize = Math.max(this.maxRecordSize, AbstractRecords.estimateSizeInBytesUpperBound(magic(),
recordsBuilder.compressionType(), key, value, headers));
this.lastAppendTime = now;
//3.构建FutureRecordMetadata对象
FutureRecordMetadata future = new FutureRecordMetadata(this.produceFuture, this.recordCount,
timestamp, checksum,
key == null ? -1 : key.length,
value == null ? -1 : value.length,
Time.SYSTEM);
//4.加入thunks
thunks.add(new Thunk(callback, future));
this.recordCount++;
return future;
}
}
可以看到 tryAppend() 方法的执行逻辑是这样的:先检测producerBatch里是否有空间存这条消息,如果有空间会调用recordsBuilder的append()方法把消息写入缓存;然后构建FutureRecordMetadata类对象future,把future和消息的callback作为参数构建Thunk类对象,并放入thunks集合中。
这个方法让生产者主线程完成了消息的缓存,但是并没有实现真正的网络发送。
接下来我们再来说说done()这个方法 。当调用done()方法时说明客户端已经收到这个批次的响应,这才调用这个方法来完成回调。相关代码如下所示:
public boolean done(long baseOffset, long logAppendTime, RuntimeException exception) {
//1.设定batch的最终状态
final FinalState tryFinalState = (exception == null) ? FinalState.SUCCEEDED : FinalState.FAILED;
if (tryFinalState == FinalState.SUCCEEDED) {
log.trace("Successfully produced messages to {} with base offset {}.", topicPartition, baseOffset);
} else {
log.trace("Failed to produce messages to {} with base offset {}.", topicPartition, baseOffset, exception);
}
if (this.finalState.compareAndSet(null, tryFinalState)) {
//2.执行回调
completeFutureAndFireCallbacks(baseOffset, logAppendTime, exception);
return true;
}
......忽略
return false;
}
具体逻辑是:先根据是否有异常设定batch的最终状态,如果没有异常,batch的最终状态就是SUCCEEDED,否则是FAILED,然后就执行回调方法。
可以看到,这里的回调方法是completeFutureAndFireCallbacks(),下面我们就来分析下这个方法。
completeFutureAndFireCallbacks()方法有两个功能:完成future和调用回调方法。其源代码如下所示:
//执行ProduceBatch中所有的回调,并执行ProduceRequestResult的done()方法,
private void completeFutureAndFireCallbacks(long baseOffset, long logAppendTime, RuntimeException exception) {
//1.设置produceFuture的相关数据
produceFuture.set(baseOffset, logAppendTime, exception);
// execute callbacks
//2.轮询thunks集合,调用callback
for (Thunk thunk : thunks) {
try {
if (exception == null) {
//3.获取消息元数据
RecordMetadata metadata = thunk.future.value();
if (thunk.callback != null)
//4.调用回调方法
thunk.callback.onCompletion(metadata, null);
} else {
if (thunk.callback != null)
thunk.callback.onCompletion(null, exception);
}
} catch (Exception e) {
log.error("Error executing user-provided callback on message for topic-partition '{}'", topicPartition, e);
}
}
//4.释放主线程的阻塞
produceFuture.done();
}
这里的执行逻辑可总结为如下:首先设置produceFuture的相关数据,包括基本位移、消息追加的时间、异常,这些数据都是给回调方法用的;然后,轮询thunks集合里的元素调用回调方法;最后,释放主线程的await()阻塞。
总结
这一讲我给大家讲解了RecordAccumlator整体流程,消息通过分区器判断属于哪个分区,然后发往缓存区中分区对应的队列中。对于源码的讲解,涉及了缓存存储底层的两个关键类MemoryRecords和MemoryRecordsBuilder,同时讲解了appendStream,bufferStream,ByteBuffer三者的关系。然后又讲了ProduceRequestResult、FutureRecordMetadata和RecordMetadata这三个类,这三个类在一起实现了收到响应后的回调方法。最后,给大家讲解了producerBatch如何缓存消息、如何处理响应,以及如何调用回调方法的。
确实,ProduceRequestResult 通过 CountDownLatch 实现了类似于 java.util.concurrent.Future 的功能,即使它并没有直接实现 Future 接口。这种设计允许生产者在同步发送消息时能够阻塞等待服务端的响应。下面是这个机制的具体工作流程和相关代码逻辑的详细解释。
ProduceRequestResult 和 CountDownLatch
CountDownLatch: 这是一个同步辅助类,用于在完成一组正在其他线程中执行的操作之前,使当前线程等待。
CountDownLatch初始化时会设置一个计数器,每次调用countDown()方法时,计数器减一。当计数器达到零时,所有因调用await()方法而阻塞的线程将被释放。ProduceRequestResult: 这是 Kafka 生产者内部的一个类,用于处理从 Kafka 服务器返回的响应。它使用
CountDownLatch来实现等待响应的功能。
工作流程
创建 ProduceRequestResult:
当生产者发送一条消息时,会创建一个
ProduceRequestResult对象。该对象包含一个
CountDownLatch,初始计数为 1。
同步发送消息:
如果生产者选择同步发送消息(即调用
send(record, callback)并传入null作为回调),则会创建一个FutureRecordMetadata对象。FutureRecordMetadata内部持有一个ProduceRequestResult对象。
调用 get() 方法:
调用
FutureRecordMetadata.get()方法时,实际上会间接调用ProduceRequestResult.await()方法。ProduceRequestResult.await()方法会调用CountDownLatch.await(),从而阻塞当前线程,直到计数器归零。
处理服务端响应:
当 Sender 线程从 Kafka 服务器接收到响应时,无论响应是成功还是失败,都会调用
ProduceRequestResult.done()方法。ProduceRequestResult.done()方法会调用CountDownLatch.countDown(),将计数器减 1。
唤醒阻塞的主线程:
一旦
CountDownLatch的计数器归零,所有因await()方法而阻塞的线程将被唤醒。阻塞的主线程继续执行,并可以获取到响应结果。
示例代码
以下是一个简化的示例,展示了 ProduceRequestResult 和 CountDownLatch 的使用方式:
import java.util.concurrent.CountDownLatch;
public class ProduceRequestResult {
private final CountDownLatch latch = new CountDownLatch(1);
private RecordMetadata metadata;
private Exception exception;
public void await() throws InterruptedException {
latch.await();
}
public void done(RecordMetadata metadata, Exception exception) {
this.metadata = metadata;
this.exception = exception;
latch.countDown();
}
public RecordMetadata getMetadata() {
return metadata;
}
public Exception getException() {
return exception;
}
}
public class FutureRecordMetadata {
private final ProduceRequestResult result;
public FutureRecordMetadata(ProduceRequestResult result) {
this.result = result;
}
public RecordMetadata get() throws InterruptedException {
result.await();
if (result.getException() != null) {
throw new RuntimeException(result.getException());
}
return result.getMetadata();
}
}
// 使用示例
public static void main(String[] args) throws InterruptedException {
// 假设已经创建了 KafkaProducer 和 Record
KafkaProducer<String, String> producer = ...;
ProducerRecord<String, String> record = ...;
// 创建 ProduceRequestResult
ProduceRequestResult requestResult = new ProduceRequestResult();
// 发送消息
producer.send(record, (metadata, exception) -> {
requestResult.done(metadata, exception);
});
// 同步等待响应
FutureRecordMetadata future = new FutureRecordMetadata(requestResult);
RecordMetadata metadata = future.get();
System.out.println("Message sent to partition: " + metadata.partition());
}在这个示例中,ProduceRequestResult 使用 CountDownLatch 来实现等待响应的功能。当 done() 方法被调用时,CountDownLatch 的计数器归零,从而唤醒等待的线程。
这种方式使得 Kafka 生产者能够在同步发送消息时阻塞等待响应,同时保持了异步处理的灵活性。如果你有更具体的问题或需要进一步的细节,请告诉我!
好的,让我们从整体上梳理一下 RecordAccumulator 的工作流程,并详细讲解涉及的各个关键类和它们之间的关系。我们将按照以下顺序进行:
消息通过分区器判断属于哪个分区。
消息发往缓存区中分区对应的队列中。
缓存存储底层的关键类
MemoryRecords和MemoryRecordsBuilder。appendStream,bufferStream,ByteBuffer三者的关系。ProduceRequestResult,FutureRecordMetadata,RecordMetadata三个类及其回调机制。ProducerBatch如何缓存消息、处理响应以及调用回调方法。
1. 消息通过分区器判断属于哪个分区
当生产者发送一条消息时,首先需要确定这条消息应该发送到哪个分区。这个过程是通过 Partitioner 接口实现的。默认情况下,Kafka 使用 DefaultPartitioner,它根据消息的键(key)来选择分区。如果没有键,则使用轮询的方式选择分区。
int partition = partition(record, serializedKey, serializedValue, cluster);2. 消息发往缓存区中分区对应的队列中
一旦确定了分区,消息就会被添加到 RecordAccumulator 中对应分区的队列中。RecordAccumulator 维护了一个 ConcurrentMap<TopicPartition, Deque<ProducerBatch>>,其中 TopicPartition 是键,Deque<ProducerBatch> 是值。
// RecordAccumulator 类中的 append 方法
public FutureRecordMetadata append(TopicPartition tp, long timestamp, byte[] key, byte[] value, Header[] headers, Callback callback, long maxTimeToBlock) throws InterruptedException {
// 省略了一些代码...
synchronized (this) {
if (guaranteeMessageOrder) {
// 如果保证消息顺序,则等待前一个批次完成
while (incomplete && batches.get(tp).size() > 0)
wait();
}
// 获取或创建对应分区的队列
Deque<ProducerBatch> dq = getOrCreateDeque(tp);
// 尝试将消息添加到现有批次中
ProducerBatch last = dq.peekLast();
if (last != null) {
int size = last.tryAppend(timestamp, key, value, headers, interceptCallback, remainingWaitMs);
if (size >= 0) {
// 成功添加到现有批次
return new FutureRecordMetadata(last, cb, this, tp);
}
}
// 创建新的批次
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(key, value, headers));
log.trace("Allocating a new {} byte message buffer for topic {} partition {}", size, tp.topic(), tp.partition());
ByteBuffer buffer = free.allocate(size, maxTimeToBlock);
ProducerBatch batch = new ProducerBatch(tp, buffer, this.maxSize, this.compressionType, this.isTransactional, this.transactionManager.producerId(), this.accumulatorIdSequence.getAndIncrement());
FutureRecordMetadata future = new FutureRecordMetadata(batch, cb, this, tp);
batch.done(interceptCallback);
batch.tryAppend(timestamp, key, value, headers, interceptCallback, Long.MAX_VALUE);
dq.addLast(batch);
incomplete = true;
return future;
}
}3. 缓存存储底层的关键类 MemoryRecords 和 MemoryRecordsBuilder
MemoryRecords: 这是一个抽象类,表示一组按顺序排列的消息记录。它支持压缩和高效的读写操作。MemoryRecordsBuilder: 用于构建MemoryRecords实例,逐步添加消息记录。
MemoryRecords 类
主要方法:
writeTo(ByteBuffer buffer): 将MemoryRecords的内容写入给定的ByteBuffer。iterator(): 返回一个迭代器,用于遍历MemoryRecords中的所有记录。validBytes(): 返回MemoryRecords中有效数据的长度。isCompressed(): 判断MemoryRecords是否是压缩的。compressionType(): 返回MemoryRecords使用的压缩类型。sizeInBytes(): 返回MemoryRecords在内存中的大小。
MemoryRecordsBuilder 类
主要方法:
append(Record record): 添加一条记录到MemoryRecordsBuilder中。appendWithOffset(long offset, long timestamp, byte[] key, byte[] value, Header[] headers): 添加一条带有指定偏移量、时间戳、键值对和头信息的记录。build(): 根据当前添加的记录生成一个MemoryRecords实例。buildWithPadding(int size): 生成一个MemoryRecords实例,并确保其大小至少为指定的size。
4. appendStream, bufferStream, ByteBuffer 三者的关系
ByteBuffer: 底层的数据存储结构,用于高效地存储字节数据。bufferStream: 封装了ByteBuffer,提供了更高级别的写入接口,并支持自动扩容。appendStream: 封装了bufferStream,进一步提供了更高层次的消息追加功能。
这三个组件通过装饰器模式层层封装,形成了一个高效的消息写入链。
5. ProduceRequestResult, FutureRecordMetadata, RecordMetadata 三个类及其回调机制
ProduceRequestResult: 内部使用CountDownLatch来实现类似于Future的功能,等待服务端的响应。FutureRecordMetadata: 包装了ProduceRequestResult,提供了一个get()方法来阻塞等待响应。RecordMetadata: 表示消息在 Kafka 服务器上的元数据,如偏移量、分区等。
主要方法
ProduceRequestResult:await(): 阻塞等待服务端响应。done(RecordMetadata metadata, Exception exception): 处理服务端响应,唤醒等待的线程。
FutureRecordMetadata:get(): 阻塞等待并返回RecordMetadata。
RecordMetadata:提供了消息的元数据,如偏移量、分区等。
6. ProducerBatch 如何缓存消息、处理响应以及调用回调方法
缓存消息:
ProducerBatch使用MemoryRecordsBuilder来构建MemoryRecords,并将消息追加到MemoryRecords中。每个
ProducerBatch对应一个TopicPartition,并且包含一批消息记录。
处理响应:
当 Sender 线程从 Kafka 服务器接收到响应时,会调用
ProducerBatch的done()方法。done()方法会处理响应结果,并调用ProduceRequestResult的done()方法,从而唤醒等待的线程。
调用回调方法:
如果设置了回调函数,
ProducerBatch会在处理响应时调用回调函数,传递RecordMetadata或异常信息。
示例代码
public class ProduceRequestResult {
private final CountDownLatch latch = new CountDownLatch(1);
private RecordMetadata metadata;
private Exception exception;
public void await() throws InterruptedException {
latch.await();
}
public void done(RecordMetadata metadata, Exception exception) {
this.metadata = metadata;
this.exception = exception;
latch.countDown();
}
public RecordMetadata getMetadata() {
return metadata;
}
public Exception getException() {
return exception;
}
}
public class FutureRecordMetadata {
private final ProduceRequestResult result;
public FutureRecordMetadata(ProduceRequestResult result) {
this.result = result;
}
public RecordMetadata get() throws InterruptedException {
result.await();
if (result.getException() != null) {
throw new RuntimeException(result.getException());
}
return result.getMetadata();
}
}
public class ProducerBatch {
private final MemoryRecordsBuilder builder;
private final TopicPartition partition;
private final ProduceRequestResult result;
public ProducerBatch(TopicPartition partition, ByteBuffer buffer, int maxSize, CompressionType compressionType, boolean isTransactional, long producerId, short epoch, int baseSequence, long now) {
this.partition = partition;
this.builder = new MemoryRecordsBuilder(buffer, compressionType, now, false);
this.result = new ProduceRequestResult();
}
public int tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers, Callback callback, long maxTimeToBlock) {
// 尝试将消息追加到当前批次
if (builder.hasRoomFor(key, value, headers)) {
builder.appendWithOffset(offset, timestamp, key, value, headers);
return builder.sizeInBytes();
}
return -1;
}
public void done(Callback callback, RecordMetadata metadata, Exception exception) {
result.done(metadata, exception);
if (callback != null) {
callback.onCompletion(metadata, exception);
}
}
}总结
消息通过分区器判断属于哪个分区,然后被添加到
RecordAccumulator中对应分区的队列中。MemoryRecords和MemoryRecordsBuilder用于构建和存储消息记录。appendStream,bufferStream,ByteBuffer通过装饰器模式层层封装,实现了高效的消息写入。ProduceRequestResult,FutureRecordMetadata,RecordMetadata三个类协同工作,实现了收到响应后的回调机制。ProducerBatch负责缓存消息、处理响应以及调用回调方法。
通过这些组件的协同工作,Kafka 生产者能够高效地批量发送消息,并且支持同步和异步两种发送方式。希望这能帮助你更好地理解 Kafka 生产者的内部工作机制。如果你有更多具体的问题或需要进一步的细节,请告诉我!