3.4.1 Memcached协议
Memcached 是一个高性能的分布式内存缓存系统,主要用于加速动态 Web 应用程序通过减轻数据库负载。它通过在 RAM(随机存取存储器)中缓存数据和对象来减少对数据库或其他较慢存储系统的重复访问。下面是关于 Memcached 的一些关键点:
用途
性能优化:通过将经常访问的数据存储在内存中,减少对后端系统的请求,如数据库,从而提高应用程序的速度。
负载均衡:通过减少数据库查询次数来平衡服务器负载。
技术特点
键值存储:Memcached 使用简单的键值存储模型,其中数据以键值对的形式存储和检索。
分布式:可以部署在多台服务器上,实现数据的分布式存储。
无状态服务:Memcached 服务器是无状态的,每个实例都可以独立运行,不需要了解其他实例的状态。
架构
客户端-服务器模型:Memcached 服务器负责存储数据,而客户端应用程序则通过网络连接与这些服务器进行通信。
协议
ASCII 协议:最初使用的协议是基于文本的简单 ASCII 协议。
二进制协议:后来引入了更高效的二进制协议,提供更好的性能。
数据结构
键值对:数据以字符串形式的键与任意类型的数据(值)关联起来进行存储。
过期时间:可以为缓存项设置过期时间,过期后数据会被自动删除,以保持内存的有效利用。
可扩展性
水平扩展:可以通过添加更多的服务器节点来扩展 Memcached 集群,实现线性的性能增长。
自动分片:数据自动分布在集群中的多个服务器上,无需手动管理。
缓存机制
LRU(最近最少使用)算法:当内存空间不足时,Memcached 使用 LRU 算法来决定哪些缓存项应该被替换掉。
支持的语言
广泛支持:Memcached 提供了许多编程语言的客户端库,包括 PHP、Python、Java 和 C++ 等。
安装与配置
安装:可以通过包管理器或从源代码编译安装 Memcached。
配置:可以通过命令行参数或配置文件进行基本配置,例如监听端口、最大内存限制等。
Memcached是一个开源的高性能分布式内存缓存系统,用于加速动态Web应用。它通过将数据库查询结果、API调用结果或其他数据缓存到内存中,减少对数据库的访问频率,从而提高应用的响应速度。以下是Memcached缓存中间件及其协议详解:
Memcached缓存中间件详解
工作原理:Memcached的核心是一个Key-Value存储系统,支持set、get、delete、incr/decr等基本操作。缓存机制采用LRU(Least Recently Used,最近最少使用)算法管理缓存数据。
架构:由多个缓存节点和客户端组成,每个缓存节点独立运行,负责处理客户端的请求。客户端通过一致性哈希算法将数据分布到不同的缓存节点上。
安装与配置:安装方法因操作系统而异,配置文件通常位于/etc/memcached.conf,包括指定内存分配大小、监听端口等。
使用方法:支持基本操作如set、get、delete,以及进阶操作如设置过期时间、批量操作等。Memcached提供了丰富的API,易于集成到各种编程语言中。
应用场景:广泛应用于缓存数据库查询结果、API调用结果等,以提高应用性能和响应速度。
Memcached协议详解
文本协议:Memcached使用简单的文本协议进行通信,命令以\r\n结尾,数据可以用\r、\n或\r\n表示数据部分的结束。
二进制协议:二进制协议是在v1.4之后才支持的,具有更低的性能延迟和更好的可扩展性。协议包由包头、命令行的额外数据、key和value组成。
通过上述详解,可以看出Memcached不仅是一个高性能的缓存系统,其简单的协议和灵活的配置也使其易于在各种应用场景中使用。
Memcached 是一个高性能的、多线程的、基于事件处理机制的键值 (key-value) 缓存系统。它被设计用于加速动态 Web 应用程序,通过将数据缓存在内存中来减少对后端数据库的请求次数。以下是关于 Memcached 的详细介绍:
性能特点
高性能:由于 Memcached 将数据存储在内存中,因此具有非常快的访问速度。
多线程:Memcached 采用多线程模型来处理并发的客户端请求,这使得它可以有效地利用多核处理器的优势。
基于事件处理机制:Memcached 使用事件驱动架构来管理网络连接和内部数据操作,这种架构非常适合处理大量并发连接。
架构与工作原理
客户端-服务器模型:Memcached 通常作为服务器组件运行,客户端应用程序通过网络与之通信。
键值存储:数据以键值对的形式存储。每个键是一个字符串,与一个值相关联,这个值可以是任何类型的数据,例如字符串、数字或序列化的对象。
分布式缓存:Memcached 支持水平扩展,即可以通过添加更多的 Memcached 服务器来扩展缓存容量。
自动分片:数据自动分布在集群中的多个服务器上,不需要手动管理数据的分布。
无状态服务:每个 Memcached 服务器都是无状态的,这意味着它们不需要了解其他服务器的状态或数据,这简化了集群的管理。
协议
ASCII 协议:Memcached 最初使用的协议是基于文本的简单 ASCII 协议,它易于理解和调试。
二进制协议:为了提高性能,Memcached 后来引入了更高效的二进制协议,它减少了网络传输的开销。
命令集
Memcached 支持多种命令,例如:
get: 获取一个或多个键对应的值。set: 设置一个键的值。add: 如果键不存在,则设置一个键的值。replace: 如果键已存在,则替换键的值。delete: 删除一个键。incr/decr: 对数值类型的键进行递增或递减操作。
缓存机制
过期时间:可以为每个缓存项设置过期时间,过期后数据将被自动删除。
LRU 算法:当内存空间不足时,Memcached 使用 LRU(最近最少使用)算法来决定哪些缓存项应该被替换掉。
安装与配置
安装:可以通过包管理器或从源代码编译安装 Memcached。
配置:可以通过命令行参数或配置文件进行基本配置,例如监听端口、最大内存限制等。
支持的语言
广泛的客户端库:Memcached 提供了许多编程语言的客户端库,包括 PHP、Python、Java 和 C++ 等。
使用场景
数据库查询结果缓存:存储经常查询的结果,减少数据库访问。
会话数据存储:存储用户的会话数据。
临时数据存储:存储一些临时数据,如验证码等。
如果您需要更具体的配置或使用方面的指导,请随时告诉我!
[](@replace=0### Memcached协议详解
Memcached使用两种协议进行通信:文本协议和二进制协议。
文本协议Memcached的文本协议是一种简单、直观的协议,用于与Memcached服务器进行通信。该协议包括以下部分:
命令:如`<a>Memcached的文本协议是一种简单、直观的协议,用于与Memcached服务器进行通信。该协议包括以下部分:
命令:如
set、get、delete、incr、decr等,用于执行不同的操作。键(Key):用于标识存储在Memcached中的数据。
值(Value):与键关联的数据。
过期时间(Expiration Time):可选参数,用于指定数据在Memcached中的有效时间。
分隔符:用于分隔命令、键、值和其他参数。
文本协议的命令格式如下:
<command> <key> <flags> <expiration time> <bytes> [\r\n]
<value> [\r\n]例如,以下命令将一个键值对存储到Memcached中:
set my_key 0 0 5\r\n
hello\r\n以下命令从Memcached中获取键为my_key的值:
get my_key\r\n二进制协议
Memcached的二进制协议是在Memcached 1.4版本中引入的,旨在提高性能和可扩展性。二进制协议使用二进制格式传输数据,减少了文本协议中的字符编码和解码的开销。
二进制协议的结构如下:
<binary header> <command> <key> <flags> <expiration time> <bytes> <value>其中,<binary header>包含了一些元数据,如协议版本、命令类型、键的长度等。
二进制协议的命令格式如下:
<command> <key> <flags> <expiration time> <bytes> <value>例如,以下命令将一个键值对存储到Memcached中:
<command> <key> <flags> <expiration time> <bytes> <value>以下命令从Memcached中获取键为my_key的值:
<command> <key> <flags> <expiration time> <bytes> <value>Memcached与Redis的比较
功能:Redis提供了比Memcached更丰富的功能,如支持复杂的数据结构(如链表、集合、哈希表等)、事务、持久化、主从复制等。
性能:在某些情况下,Redis的性能可能优于Memcached,尤其是在处理复杂数据结构和大量数据时。
内存管理:Redis使用自己的内存管理策略,而Memcached使用Slab Allocation机制。
协议:Memcached使用文本协议和二进制协议,而Redis使用自己的协议。
安全性:Redis提供了更多的安全选项,如密码认证、SSL/TLS加密等。
社区支持:Redis和Memcached都有活跃的社区支持,但Redis的社区可能更加活跃。
总之,Redis和Memcached各有优势,选择哪一个取决于具体的应用场景和需求。
Memcached 和 Redis 都是非常流行的内存数据存储系统,但它们的设计理念和实现细节有所不同。下面是对 Memcached 协议的详细解析以及与 Redis 的比较。
Memcached 协议
Memcached 支持两种主要的网络协议:ASCII 协议和二进制协议。
ASCII 协议
特点:
基于文本的协议,易于理解和调试。
每个命令和响应都由一个换行符 (
\r\n) 分隔。
命令格式:
command key [flags] [expiration_time] [bytes] [noreply]\r\nget key [key ...]\r\nset key flags expiration bytes [noreply]\r\nadd key flags expiration bytes [noreply]\r\nreplace key flags expiration bytes [noreply]\r\ndelete key [quiet]\r\nincr|decr key value [expiration]\r\n
响应格式:
VALUE key flags bytes [cas]\r\nEND\r\nNOT_STORED\r\nSTORED\r\nEXISTS\r\nDELETED\r\nNOT_FOUND\r\nCLIENT_ERROR message\r\nSERVER_ERROR message\r\n
二进制协议
特点:
更高效,因为它是基于二进制的,减少了网络传输的开销。
支持 CAS(Compare-and-Swap)操作,可以防止缓存中的数据被并发更新。
命令格式:
每个命令由一个固定长度的头部和一个可变长度的主体组成。
头部包含命令标识符、关键字长度、额外数据长度、命令类型等信息。
主体包含了实际的命令数据。
Memcached 与 Redis 的比较
数据类型
Memcached:
支持简单的键值对数据结构。
Redis:
支持多种数据类型,如字符串、列表、集合、哈希表、有序集合等。
协议
Memcached:
支持 ASCII 和二进制协议。
Redis:
使用基于文本的 Redis 协议,也称为 RESP(Redis Serialization Protocol)。
功能
Memcached:
主要用于缓存,功能相对简单。
Redis:
功能更丰富,除了缓存之外还可以作为消息队列、发布/订阅系统等。
性能
Memcached:
通常具有更高的吞吐量,特别是在读取密集的应用场景中。
Redis:
在写入密集的应用场景中表现更好,因为 Redis 支持持久化和事务。
持久化
Memcached:
不支持数据持久化,重启服务后数据会丢失。
Redis:
支持 RDB 快照和 AOF 日志两种持久化方式。
扩展性
Memcached:
支持水平扩展,可以通过添加更多的 Memcached 服务器来扩展缓存容量。
Redis:
支持主从复制和集群模式,但实现更为复杂。
其他特性
Memcached:
使用 LRU 算法来管理内存。
Redis:
支持多种内存管理策略,如 LRU、LFU(Least Frequently Used)等。
示例
以下是一个使用 ASCII 协议的 Memcached 命令示例,向 Memcached 存储一个键值对:
set test_key 0 0 5
hello这里的命令说明如下:
set表示设置命令。test_key是要设置的键。0表示没有特殊标志。读/写速度内存使用情况磁盘 I/O 转储.伸缩性.请遵循站内知识共享协议,出处:http://1.13.19.192:8089/archives/ji-zhong-shi-huan-cun-redis;站点:1.13.19.192:8089
0表示该值永远不会过期。5表示要发送的值的字节数。hello是要存储的值。
Redis 示例
Redis 使用不同的命令集,以下是一个简单的 Redis 命令示例,设置一个键值对:
SET mykey "Hello"
GET mykey结论
Memcached 和 Redis 都是非常强大的工具,选择哪一个取决于您的具体需求。如果只需要简单的缓存功能并且对性能有极高要求,那么 Memcached 是一个不错的选择。如果需要更丰富的数据结构和更高级的功能,Redis 则更适合。
如果您需要更具体的配置或使用方面的指导,请随时告诉我!
您提供的信息非常详细,下面我将为您进行概述:读/写速度内存使用情况磁盘 I/O 转储.伸缩性.
请遵循站内知识共享协议,出处:http://1.13.19.192:8089/archives/ji-zhong-shi-huan-cun-redis;站点:1.13.19.192:8089
Memcached概述
Memcached是一个高性能的分布式内存缓存系统,旨在通过缓存数据库查询结果、API调用结果或其他数据来加速动态Web应用。它通过TCP/UDP或Unix Domain Socket与客户端通信,并默认监听11211端口。Memcached采用libev事件处理框架来处理并发请求。
Memcached支持的协议
Memcached支持两种主要的通信协议:
文本协议:
文本协议是Memcached最初使用的协议,也是最广泛使用的协议之一。
它基于简单的文本命令和响应格式,易于理解和实现。
文本协议的命令格式和协议规范在Memcached的官方文档中有详细的描述。
由于文本协议的可读性和易调试性,它在开发和测试环境中非常受欢迎。
二进制协议:
二进制协议是在Memcached 1.4版本中引入的,旨在提供更高的性能和更紧凑的数据传输。
二进制协议使用二进制格式传输数据,减少了文本协议中的字符编码和解码的开销。
二进制协议具有更低的性能延迟和更好的可扩展性,因此在生产环境中通常优先选择二进制协议。
二进制协议的命令格式和数据结构在Memcached的官方文档中也有详细的描述。
Memcached的工作原理
Memcached的核心是一个Key-Value存储系统,支持基本的缓存操作,如set、get、delete、incr/decr等。它采用LRU(Least Recently Used,最近最少使用)算法来管理缓存数据,确保最常用的数据保留在内存中。
Memcached的架构
Memcached由多个缓存节点和客户端组成。每个缓存节点独立运行,负责处理客户端的请求。客户端通过一致性哈希算法将数据分布到不同的缓存节点上,从而实现数据的分布式存储和访问。
Memcached的应用场景
Memcached广泛应用于缓存数据库查询结果、API调用结果、会话数据等,以提高应用性能和响应速度。它特别适用于高并发、读多写少的应用场景。
通过上述概述,可以看出Memcached不仅是一个高性能的缓存系统,其简单的协议和灵活的配置也使其易于在各种应用场景中使用。
Memcached 是一个高性能、分布式内存对象缓存系统,用于加速动态 Web 应用程序通过减轻数据库负载。它支持两种主要的网络协议:文本协议(Text Protocol)和二进制协议(Binary Protocol)。这两种协议在功能上基本相同,但在实现细节上有很大的不同。
文本协议 (Text Protocol)
可读性:由于使用 ASCII 编码,文本协议的命令和响应都是可读的字符串形式,易于调试和理解。
效率:文本协议在解析和序列化数据时相对低效,因为需要处理 ASCII 字符串。
扩展性:对于一些较新的特性或复杂操作的支持不如二进制协议灵活。
安全性:没有加密选项,所有通信都是明文传输。
二进制协议 (Binary Protocol)
效率:二进制协议通过更紧凑的数据格式和更少的解析开销提高了性能。它直接使用字节表示命令和数据,减少了序列化和反序列化的开销。
扩展性:支持更多的特性,如增加了一些额外的操作码来支持更复杂的操作,并且可以更容易地添加新特性。
安全性:提供了加密选项,例如 TLS/SSL 加密连接,增加了数据传输的安全性。
复杂性:二进制协议的实现比文本协议更为复杂,因为它涉及到更多底层细节的处理。
总结
性能:二进制协议通常比文本协议更快,尤其是在高并发场景下。
兼容性:大多数 Memcached 客户端都支持这两种协议,但某些老版本客户端可能只支持文本协议。
开发难度:文本协议对开发者来说更加友好,而二进制协议则更适合追求极致性能的应用。
选择哪种协议取决于您的具体需求:如果您需要更好的性能和安全性,可以选择二进制协议;如果您更注重开发的便捷性和调试的容易程度,则可以考虑使用文本协议。
Memcached是一个高性能的分布式内存缓存系统,它支持两种协议:文本协议和二进制协议。这两种协议在Memcached中各有特点和适用场景。
Memcached文本协议
特点:文本协议以换行表示一个请求结束,请求内部参数以空格分隔。这种协议简单易懂,易于调试和实现。
优缺点:
优点:协议简单,易于理解和实现,适合开发和调试。
缺点:由于文本协议的数据量相对较大,因此在网络传输时可能会造成一定的带宽浪费,且服务器端解析文本协议会消耗更多的CPU资源。
适用场景:适合开发初期或者对协议兼容性要求较高的场景。
Memcached二进制协议
特点:二进制协议以最小数据量表达所有信息,服务器解析请求时做的是数学比较而不是字符串比较,因此效率更高。
优缺点:
优点:数据传输效率高,CPU消耗低,适合高并发场景。
缺点:协议较难理解和实现,扩展性较差,一旦协议定死,难以适应不同的场景需求。
适用场景:适合对性能有较高要求的场景,尤其是高并发、大数据量的应用场景。
选择建议
性能要求:如果系统对性能有较高要求,尤其是在高并发环境下,推荐使用二进制协议。
开发和调试:如果项目处于开发初期,或者需要频繁进行协议调试,文本协议可能更合适。
兼容性:如果系统需要与多种不同的客户端和服务器兼容,文本协议可能提供更广泛的兼容性。
总的来说,Memcached的文本协议和二进制协议各有优势,选择哪种协议取决于具体的应用场景和需求。在追求高性能和低延迟的场景下,二进制协议是更优的选择;而在开发和调试阶段,或者需要考虑协议兼容性的情况下,文本协议可能更为合适。
Redis 和 Memcached 都是基于内存的数据存储系统。Memcached是高性能分布式内存缓存服务,其本质上就是一个内存key-value数据库。Redis是一个开源的key-value存储系统。与Memcached类似,Redis将大部分数据存储在内存中,支持的数据类型包括:字符串、哈希表、链表、集合、有序集合以及基于这些数据类型的相关操作。那么,Memcached与Redis有什么区别呢?
1、数据操作不同
与Memcached仅支持简单的key-value结构的数据记录不同,Redis支持的数据类型要丰富得多。Memcached基本只支持简单的key-value存储,不支持枚举,不支持持久化和复制等功能。Redis支持服务器端的数据操作相比Memcached来说,拥有更多的数据结构和并支持更丰富的数据操作,支持list、set、sorted set、hash等众多数据结构,还同时提供了持久化和复制等功能。而通常在Memcached里,使用者需要将数据拿到客户端来进行类似的修改再set回去,这大大增加了网络IO的次数和数据体积。在Redis中,这些复杂的操作通常和一般的GET/SET一样高效。所以,如果需要缓存能够支持更复杂的结构和操作, Redis会是更好的选择。
2、内存管理机制不同
在Redis中,并不是所有的数据都一直存储在内存中的。这是和Memcached相比一个最大的区别。当物理内存用完时,Redis可以将一些很久没用到的value交换到磁盘。Redis只会缓存所有的key的信息,如果Redis发现内存的使用量超过了某一个阀值,将触发swap的操作,Redis根据“swappability = age*log(size_in_memory)”计算出哪些key对应的value需要swap到磁盘。然后再将这些key对应的value持久化到磁盘中,同时在内存中清除。这种特性使得Redis可以保持超过其机器本身内存大小的数据。
而Memcached默认使用Slab Allocation机制管理内存,其主要思想是按照预先规定的大小,将分配的内存分割成特定长度的块以存储相应长度的key-value数据记录,以完全解决内存碎片问题。
从内存利用率来讲,使用简单的key-value存储的话,Memcached的内存利用率更高。而如果Redis采用hash结构来做key-value存储,由于其组合式的压缩,其内存利用率会高于Memcached。
3、性能不同
由于Redis只使用单核,而Memcached可以使用多核,所以平均每一个核上Redis在存储小数据时比Memcached性能更高。而在100k以上的数据中,Memcached性能要高于Redis,虽然Redis也在存储大数据的性能上进行了优化,但是比起Memcached,还是稍有逊色。
4、集群管理不同
Memcached是全内存的数据缓冲系统,Redis虽然支持数据的持久化,但是全内存毕竟才是其高性能的本质。作为基于内存的存储系统来说,机器物理内存的大小就是系统能够容纳的最大数据量。如果需要处理的数据量超过了单台机器的物理内存大小,就需要构建分布式集群来扩展存储能力。
Memcached本身并不支持分布式,因此只能在客户端通过像一致性哈希这样的分布式算法来实现Memcached的分布式存储。相较于Memcached只能采用客户端实现分布式存储,Redis更偏向于在服务器端构建分布式存储。
小结:Redis和Memcached哪个更好?
Redis更多场景是作为Memcached的替代者来使用,当需要除key-value之外的更多数据类型支持或存储的数据不能被剔除时,使用Redis更合适。如果只做缓存的话,Memcached已经足够应付绝大部分的需求,Redis 的出现只是提供了一个更加好的选择。总的来说,根据使用者自身的需求去选择才是最合适的。
提前缓存技术,很多PHP工作者都会优先想到Reids和Memcached这两个老牌缓存组件。
有一些刚接触缓存技术的新人会认为Redis跟Memcached,只有在内存分配,工作机制上有区别而已,使用场景都是一样的,其实不然。
很多人不清楚,其实Memcached要比Redis早诞生了10年,而Redis是参照Memcached的应用场景加以改良之后,所诞生的新一代组件,所以现在的产品开发,几乎都放弃Memcached,直接选项Redis了。
1、技术选型
当我们讨论改进性能的时候,这是每次技术讨论中最常见的一个问题。每当性能需要改善时,采用缓存常常是迈出的第一步。
与此同时,选择Memcached 或者 Redis 通常是第一个需要考虑的地方。
哪个能给我们提供更佳的性能?它们的优点和缺点又是什么?
在设计任何缓存系统时,我们考虑如下几点:
读/写速度内存使用情况磁盘 I/O 转储.伸缩性.2、相似之处
Memcached/Redis 两者都提供基于内存的、键-值数据存储,尽管Redis更准确的说是结构化数据存储。
Redis是内存中的结构化数据存储器,用于数据库、缓存、消息代理。
两者(Memcached/Redis)都属于数据管理方案中的NoSQL家族,都是基于键-值存储的。
它们都在内存中保存数据,当然使它们作为缓存层特别有用。
截至今日,Memcached提供的每项主要功能及其优势,都是Redis功能和特性的子集。
任何用例中可能使用Memcached的地方都可以对等的使用Redis(因为前面提到后,Redis就是参考Memcached诞生的新一代组件)。
它们都是闪电般快速的高速缓存组件。
但Memcached提供支持的功能只是Redis拥有功能的冰山一角。
Memcached是一个基于易失性内存的键-值存储器。
Redis一样可以做到(跟Memcached做得一样好),但是它还是一个结构化数据服务器。
3、那Memcached还有什么用?
当缓存相对较小和使用静态的数据时候,比如HTML代码片段,Memcached可能更为可取。
Memcached内部的内存管理在最简单的用例中更为有效,因为它的元数据消耗相对更少的内存资源。
当数据尺寸是动态的时候,Memcached的内存管理效率下降的很快,此时Memcached的内存会变成碎片。
而且,大的数据集经常牵扯到数据序列化,总是需要更多的空间来存储。
如果你使用Memcached,数据会随着重启动而丢失,重建缓存是个代价高昂的过程(通俗点说,就是Memcached对于频繁更新的内存,重建缓存是一个大的开销)。
Memcached比Redis更具优势的另一个场景在伸缩性。
因为Memcached是多线程的,所以你可以通过给它更多计算资源让它轻松扩展。
Redis是单线程的,可以通过集群无损水平扩展。
集群是一个有效的扩展方案,但是相对来说配置、操作复杂。
Memcached不支持复制功能(数据从一台机器自动复制到另外一台)。
Memcached 非常适合处理高流量的网站。它可以一次性读取大量的信息,并在优秀的反应时间内返回。
Redis不但能处理高流量的读,还能处理繁重的写入。
4、通俗的讲点区别
1、Redis和Memcache都是将数据存放在内存中,都是内存数据库。不过memcache还可用于缓存其他东西,例如图片、视频等等;
2、Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储;
3、虚拟内存–Redis当物理内存用完时,可以将一些很久没用到的value 交换到磁盘;
4、过期策略–memcache在set时就指定,例如set key1 0 0 8,即永不过期。Redis可以通过例如expire 设定,例如expire name 10;
5、分布式–设定memcache集群,利用magent做一主多从;redis可以做一主多从。都可以一主一从;
6、存储数据安全–memcache挂掉后,数据没了;redis可以定期保存到磁盘(持久化);
7、灾难恢复–memcache挂掉后,数据不可恢复; redis数据丢失后可以通过aof恢复;
8、Redis支持数据的备份,即master-slave模式的数据备份;
9、应用场景不一样:Redis出来作为NoSQL数据库使用外,还能用做消息队列、数据堆栈和数据缓存等;Memcached适合于缓存SQL语句、数据集、用户临时性数据、延迟查询数据和session等。
5、使用场景
1、如果有持久方面的需求或对数据类型和处理有要求的应该选择redis。
2、如果简单的key/value 存储应该选择Memcached。
6、简单举个例子
在电子商务类的网站中,一般都有分类,然后还有搜索结果列表。
针对这种情况下,我们对分类的数据,可以使用Memcached,因为分类数据一般不会改变,读多写少,直接存储在Memcached中,每次查询都只需要从Memcached中获取就可以了。
那如果是缓存用户的登陆信息,减少我们业务频繁读取用户表的数据,对于这种缓存数据需要频繁读取更新的列表。
那就应该使用Redis,因为数据的读写,都是很频繁的。
7、结论
在当今这个大的开发环境下,Memcached的市场份额已经越来越低了。
Redis与Memcached相比,性能和内存使用情况相当相似。
除非你已经在Memcached上投入了大笔资金,否则向前推进使用Redis是显而易见的解决方案。
不仅Redis是更好的选择,它还支持全新类型的用例和使用模式。
下面时几个Redis可能会非常有用的一些示例应用程序:
电子商务应用:大多数的电子商务应用量级比较重,Redis可以提升你的页面加载速度。你可以存储所有的配置文件到Redis,从内存中读取这些配置信息速度会非常快速。你也可以在Redis中存储完整的页面缓存,因为它的键值容量很大。你也可以存储会话信息到Redis。物联网应用:在物联网应用中,物联网设备非常频繁的发送数据到服务器,比如每秒钟数千条。在把它们存储到任何持久性存储器之前,你可以先把这些高容量的原始数据推送到Redis。实时分析:可以在Memcached上实现一个实时的分析引擎,以数据库为后盾。但是Redis非常擅长统计列表和一系列事物。在所有的Redis功能特性中,它对键值进行排序的能力超过了Memcached,还有计算一组页面的点击次数等数据,然后将这些数字汇总进入分析系统。这些数据可通过工作人员输入到更大的分析引擎,在这些应用场合选择Redis是正确的决定之一。最后一件事:不管你选择什么,缓存系统都不是数据库。你不能光靠缓存,系统同时需要缓存和数据库。
8、你需要注意
总体上看,Redis功能特性远优于Memcached,完全是下一代产品。
选择哪个使用似乎答案很明确。
但是必须指出,Redis的单线程设计,同时也带来了一些重要的隐患。
Redis有数据持久化功能,这个功能与Redis的单线程特性结合,就成了Redis故障的高发区域。
默认的RDB持久化会阻塞线程,使得Redis对正常请求无法响应,在高流量网站上容易出现大量请求错误。
这在系统中称为“涌现”,当然这是坏的一个。
当然后来Redis也发展出了AOF持久化方式(默认没有打开,要手工开启),一定程度上减缓了Redis的持久化问题。
Redis会fork一个子进程来单独处理持久化。
可是fork功能并非无代价,它一样有消耗内存资源,影响主程序响应请求的问题。
阻塞是Redis应用的噩梦,跟Node.js一样。
所以出现故障的时候,可以多在这个角度上分析原因,也许能很快的解决。
例如,分布式Redis多机部署,通过负载降低单机处理压力。
Redis 和 Memcached 都是基于内存的数据存储系统。Memcached是高性能分布式内存缓存服务,其本质上就是一个内存key-value数据库。Redis是一个开源的key-value存储系统。与Memcached类似,Redis将大部分数据存储在内存中,支持的数据类型包括:字符串、哈希表、链表、集合、有序集合以及基于这些数据类型的相关操作。
区别
1、Redis和Memcache都是将数据存放在内存中,都是内存数据库。不过memcache还可用于缓存其他东西,例如图片、视频等等;
2、Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储;
3、虚拟内存–Redis当物理内存用完时,可以将一些很久没用到的value 交换到磁盘;
4、过期策略–memcache在set时就指定,例如set key1 0 0 8,即永不过期。Redis可以通过例如expire 设定,例如expire name 10;
5、分布式–设定memcache集群,利用magent做一主多从;redis可以做一主多从。也可以一主一从;
6、存储数据安全–memcache挂掉后,数据没了;redis可以定期保存到磁盘(持久化);
7、灾难恢复–memcache挂掉后,数据不可恢复; redis数据丢失后可以通过aof恢复;
8、Redis支持数据的备份,即master-slave模式的数据备份;
9、应用场景不一样:Redis出来作为NoSQL数据库使用外,还能用做消息队列、数据堆栈和数据缓存等;Memcached适合于缓存SQL语句、数据集、用户临时性数据、延迟查询数据和session等。
使用场景
1、如果有持久方面的需求或对数据类型和处理有要求的应该选择redis。 2、如果简单的key/value 存储应该选择memcached。
3.4.2 Memcached工作原理及优缺点
Memcached 多线程和状态机
网络模型
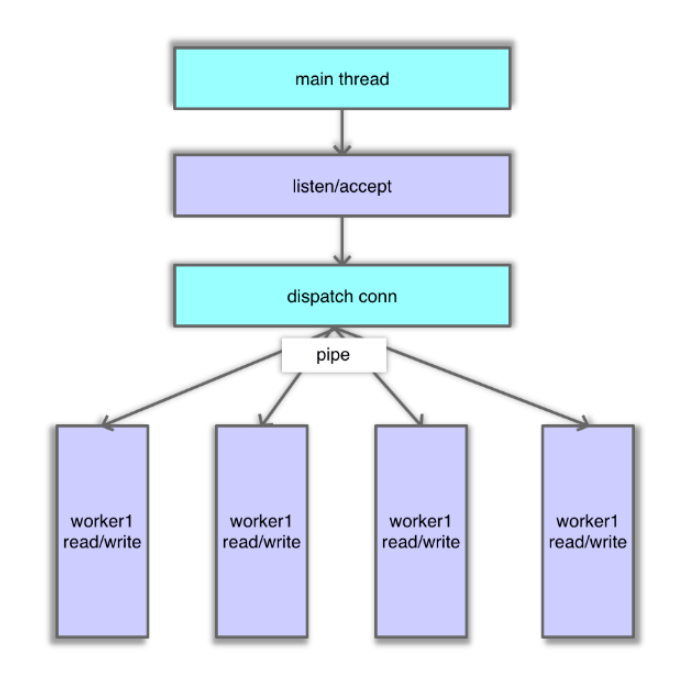
Mc 的 IO 处理线程分主线程和工作线程,每个线程各有一个 event_base,来监听网络事件。主线程负责监听及建立连接。工作线程负责对建立的连接进行网络 IO 读取、命令解析、处理及响应。
主线程
主线程在监听端口时,当有连接到来,主线程 accept 该连接,并将连接调度给工作线程。调度处理逻辑,主线程先将 fd 封装成一个 CQ_ITEM 结构,并存入新连接队列中,然后轮询一个工作线程,并通过管道向该工作线程发送通知。工作线程监听到通知后,会从新连接队列获取一个连接,然后开始从这个连接读取网络 IO 并处理,如下图所示。主线程的这个处理逻辑主要在状态机中执行,对应的连接状态为 conn_listening。
工作线程
工作线程监听到主线程的管道通知后,会从连接队列弹出一个新连接,然后就会创建一个 conn 结构体,注册该 conn 读事件,然后继续监听该连接上的 IO 事件。后续这个连接有命令进来时,工作线程会读取 client 发来的命令,进行解析并处理,最后返回响应。工作线程的主要处理逻辑也是在状态机中,一个名叫 drive_machine 的函数。
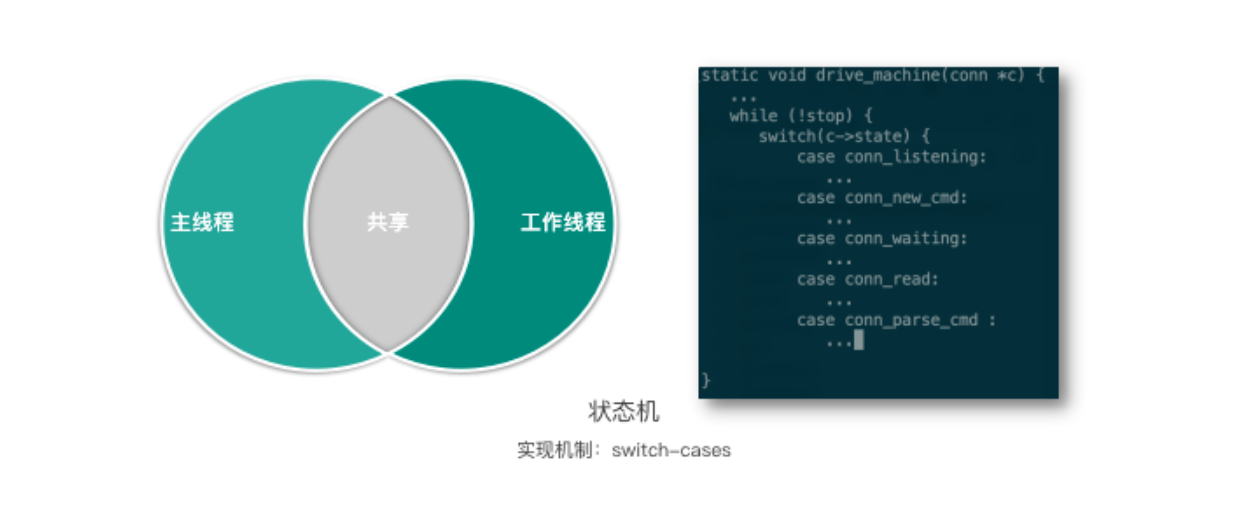
状态机
这个状态机由主线程和工作线程共享,实际是采用 switch-case 来实现的。状态机函数如下图所示,switch 连接的 state,然后根据连接的不同状态,执行不同的逻辑操作,并进行状态转换。接下来我们开始分析 Mc 的状态机。
工作线程状态事件及逻辑处理
conn_new_cmd
主线程通过调用 dispatch_conn_new,把新连接调度给工作线程后,worker 线程创建 conn 对象,这个连接初始状态就是 conn_new_cmd。除了通过新建连接进入 conn_new_cmd 状态之外,如果连接命令处理完毕,准备接受新指令时,也会将连接的状态设置为 conn_new_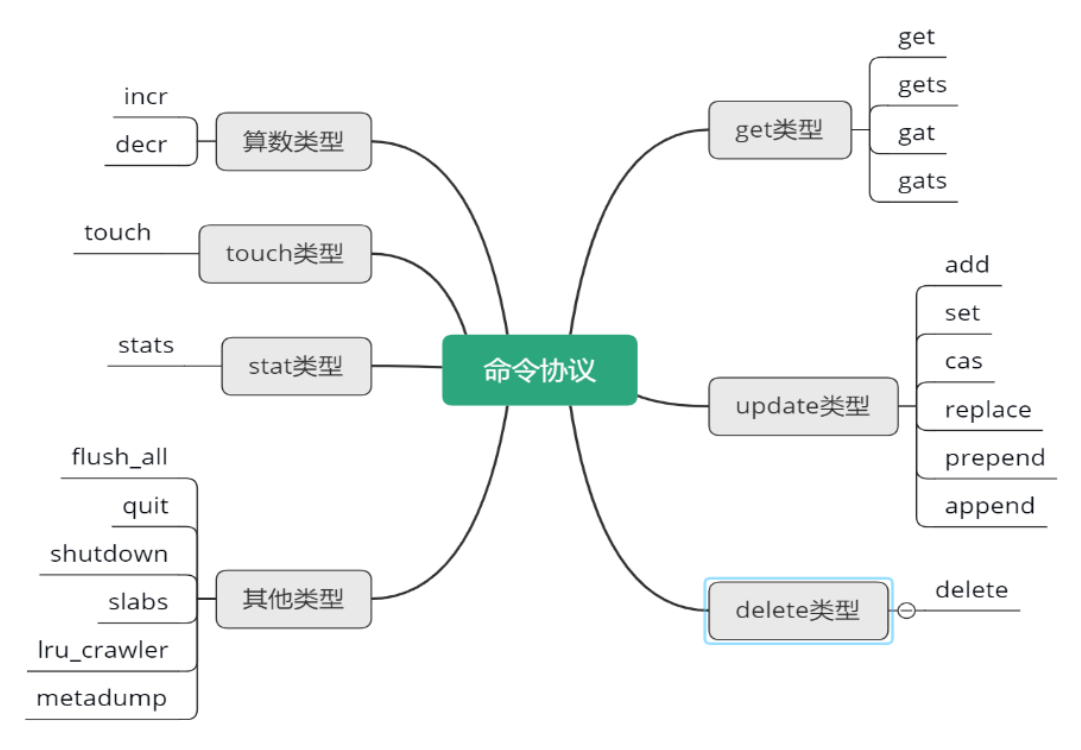 cmd 状态。
cmd 状态。
进入 conn_new_cmd 后,工作线程会调用 reset_cmd_handler 函数,重置 conn 的 cmd 和 substate 字段,并在必要时对连接 buf 进行收缩。因为连接在处理 client 来的命令时,对于写指令,需要分配较大的读 buf 来存待更新的 key value,而对于读指令,则需要分配较大的写 buf 来缓冲待发送给 client 的 value 结果。持续运行中,随着大 size value 的相关操作,这些缓冲会占用很多内存,所以需要设置一个阀值,超过阀值后就进行缓冲内存收缩,避免连接占用太多内存。在后端服务以及中间件开发中,这个操作很重要,因为线上服务的连接很容易达到万级别,如果一个连接占用几十 KB 以上的内存,后端系统仅连接就会占用数百 MB 甚至数 GB 以上的内存空间。
conn_parse_cmd
工作线程处理完 conn_new_cmd 状态的主要逻辑后,如果读缓冲区有数据可以读取,则进入 conn_parse_cmd 状态,否则就会进入到 conn_waiting 状态,等待网络数据进来。
conn_waiting
连接进入 conn_waiting 状态后,处理逻辑很简单,直接通过 update_event 函数注册读事件即可,之后会将连接状态更新为 conn_read。
conn_read
当工作线程监听到网络数据进来,连接就进入 conn_read 状态。对 conn_read 的处理,是通过 try_read_network 从 socket 中读取网络数据。如果读取失败,则进入 conn_closing 状态,关闭连接。如果没有读取到任何数据,则会返回 conn_waiting,继续等待 client 端的数据到来。如果读取数据成功,则会将读取的数据存入 conn 的 rbuf 缓冲,并进入 conn_parse_cmd 状态,准备解析 cmd。
conn_parse_cmd
conn_parse_cmd 状态的处理逻辑就是解析命令。工作线程首先通过 try_read_command 读取连接的读缓冲,并通过 \n 来分隔数据报文的命令。如果命令首行长度大于 1024,关闭连接,这就意味着 key 长度加上其他各项命令字段的总长度要小于 1024 字节。当然对于 key,Mc 有个默认的最大长度,key_max_length,默认设置为 250 字节。校验完毕首行报文的长度,接下来会在 process_command 函数中对首行指令进行处理。
process_command 用来处理 Mc 的所有协议指令,所以这个函数非常重要。process_command 会首先按照空格分拆报文,确定命令协议类型,分派给 process_XX_command 函数处理。
Mc 的命令协议从直观逻辑上可以分为获取类型、变更类型、其他类型。但从实际处理层面区分,则可以细分为 get 类型、update 类型、delete 类型、算术类型、touch 类型、stats 类型,以及其他类型。对应的处理函数为,process_get_command, process_update_command, process_arithmetic_command, process_touch_command 等。每个处理函数能够处理不同的协议,具体参见下图所示思维导图。
conn_parse_cmd
注意 conn_parse_cmd 的状态处理,只有读取到 \n,有了完整的命令首行协议,才会进入 process_command,否则会跳转到 conn_waiting,继续等待客户端的命令数据报文。在 process_command 处理中,如果是获取类命令,在获取到 key 对应的 value 后,则跳转到 conn_mwrite,准备写响应给连接缓冲。而对于 update 变更类型的指令,则需要继续读取 value 数据,此时连接会跳转到 conn_nread 状态。在 conn_parse_cmd 处理过程中,如果遇到任何失败,都会跳转到 conn_closing 关闭连接。
complete_nread
对于 update 类型的协议指令,从 conn 继续读取 value 数据。读取到 value 数据后,会调用 complete_nread,进行数据存储处理;数据处理完毕后,向 conn 的 wbuf 写响应结果。然后 update 类型处理的连接进入到 conn_write 状态。
conn_write
连接 conn_write 状态处理逻辑很简单,直接进入 conn_mwrite 状态。或者当 conn 的 iovused 为 0 或对于 udp 协议,将响应写入 conn 消息缓冲后,再进入 conn_mwrite 状态。
conn_mwrite
进入 conn_mwrite 状态后,工作线程将通过 transmit 来向客户端写数据。如果写数据失败,跳转到 conn_closing,关闭连接退出状态机。如果写数据成功,则跳转到 conn_new_cmd,准备下一次新指令的获取。
conn_closing
最后一个 conn_closing 状态,前面提到过很多次,在任何状态的处理过程中,如果出现异常,就会进入到这个状态,关闭连接,这个连接也就 Game Over 了。

Mc 命令处理全流程
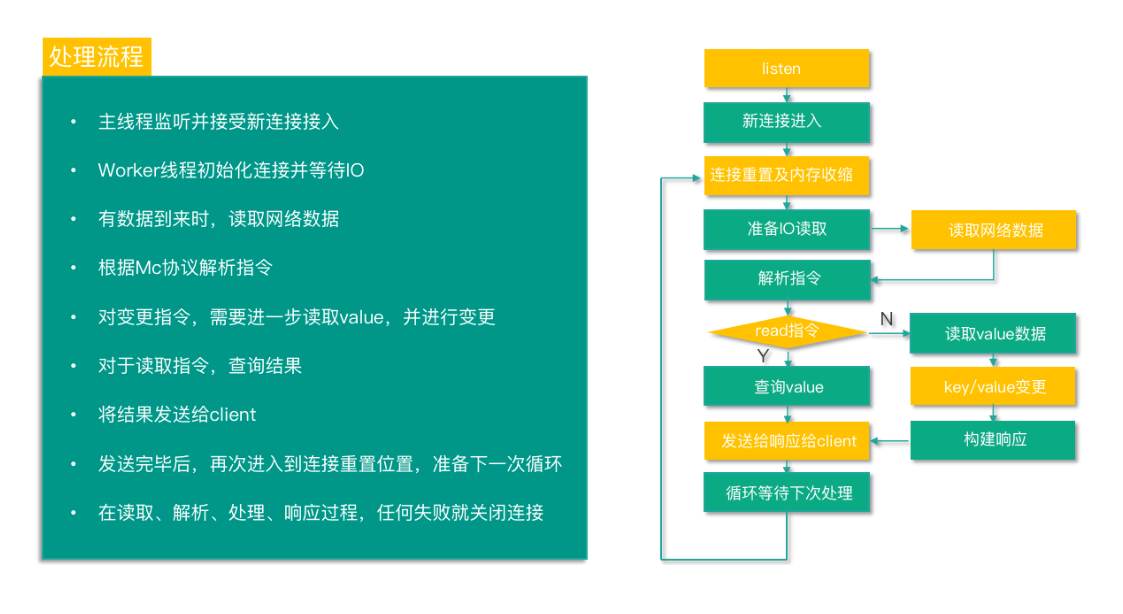
Mc 启动后,主线程监听并准备接受新连接接入。当有新连接接入时,主线程进入 conn_listening 状态,accept 新连接,并将新连接调度给工作线程。
Worker 线程监听管道,当收到主线程通过管道发送的消息后,工作线程中的连接进入 conn_new_cmd 状态,创建 conn 结构体,并做一些初始化重置操作,然后进入 conn_waiting 状态,注册读事件,并等待网络 IO。
有数据到来时,连接进入 conn_read 状态,读取网络数据。
读取成功后,就进入 conn_parse_cmd 状态,然后根据 Mc 协议解析指令。
对于读取指令,获取到 value 结果后,进入 conn_mwrite 状态。
对于变更指令,则进入 conn_nread,进行 value 的读取,读取到 value 后,对 key 进行变更,当变更完毕后,进入 conn_write,然后将结果写入缓冲。然后和读取指令一样,也进入 conn_mwrite 状态。
进入到 conn_mwrite 状态后,将结果响应发送给 client。发送响应完毕后,再次进入到 conn_new_cmd 状态,进行连接重置,准备下一次命令处理循环。
在读取、解析、处理、响应过程,遇到任何异常就进入 conn_closing,关闭连接