Elasticsearch 是一个基于 Lucene 的分布式搜索和分析引擎,它能够快速地存储、搜索和分析大量数据。在 Elasticsearch 中,查询可以分为两个主要部分:query 和 filter。其中,filter 部分是用于过滤文档的,而这些过滤条件通常不会影响相关性评分(即它们不计算分数)。由于这个特性,Elasticsearch 可以对 filter 进行缓存,从而提高查询性能。
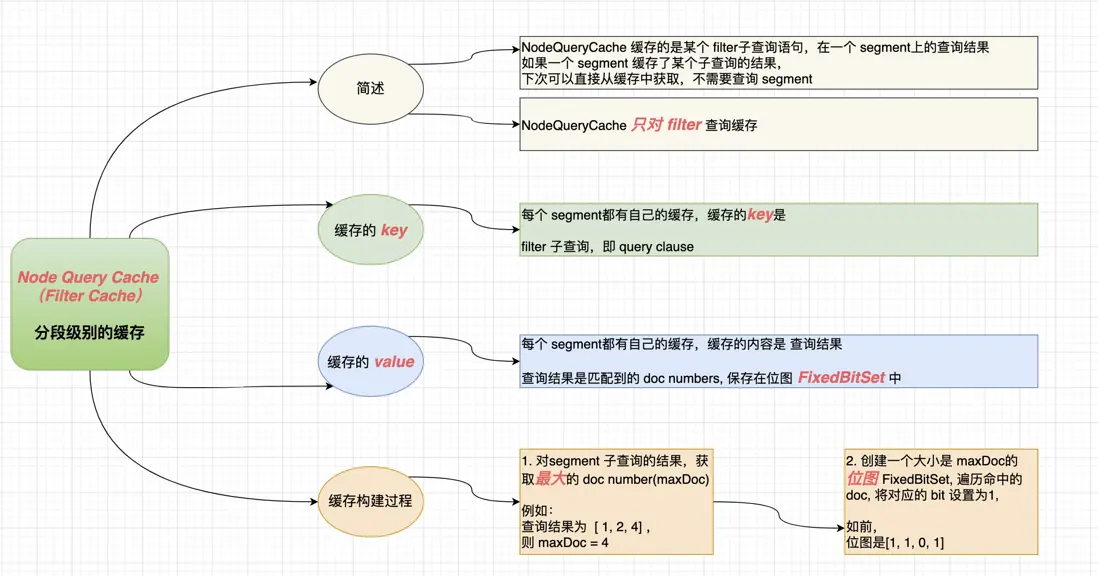
Filter 缓存机制
Filter Cache:
在较早版本的 Elasticsearch 中,存在一种称为
filter cache的缓存机制,它会自动缓存那些被频繁使用的过滤器结果。但是从 Elasticsearch 5.0 开始,这种特定的
filter cache已经被移除。取而代之的是更灵活和高效的缓存策略。
Segment-level Filtering:
现代版本的 Elasticsearch 使用了段级别的过滤优化。当索引中的文档发生变化时,Lucene 会创建新的段而不是更新现有段。每个段都包含了一个倒排索引,它可以用来非常快地执行过滤操作。
对于静态或几乎不变的过滤器,如地理围栏或时间范围过滤,Elasticsearch 会在内存中为这些过滤器创建位集(bitset),这样在每次需要应用相同的过滤条件时,就可以直接重用这些位集来跳过不必要的文档,大大提高了效率。
Node Query Cache:
虽然不再是专门针对过滤器的缓存,但节点查询缓存(Node Query Cache)可以缓存整个查询的结果。这包括了查询阶段产生的结果以及过滤阶段的输出。
如果你的查询完全相同,并且底层的数据没有改变,那么下一次同样的查询将会从缓存中读取结果,避免重新计算。
Request Cache:
请求缓存(Request Cache)位于每个分片级别,可以缓存那些产生可重复结果的请求。这对于聚合查询特别有用,因为它可以缓存聚合桶和其他不需要重新计算的信息。
当使用相同的参数进行相同的请求时,如果数据未更改,Elasticsearch 将返回缓存的结果,而不必重新执行整个查询过程。
缓存配置
你可以通过调整 Elasticsearch 的设置来控制缓存行为。例如,可以通过修改
indices.requests.cache.size来调整请求缓存的大小。对于节点查询缓存,可以通过
index.queries.cache.size参数进行配置。
注意事项
缓存并不是适用于所有场景。对于经常变动的数据,过度依赖缓存可能导致缓存失效频繁,反而影响性能。
监控缓存的命中率是很重要的,因为低命中率可能意味着缓存配置不当或者不适合当前的工作负载。
在某些情况下,显式地禁用缓存可能是合理的,特别是当你知道数据集变化非常频繁,缓存带来的好处微乎其微时。
总之,Elasticsearch 的缓存机制是为了提升查询性能设计的,尤其是在处理大量的过滤条件时。合理利用这些缓存机制可以显著提高系统的响应速度。不过,也需要根据实际应用场景仔细考虑是否开启及如何配置缓存。
Elasticsearch 的 filter 缓存机制是一种性能优化策略,用于提高查询速度。当 Elasticsearch 执行查询时,它会根据查询条件对文档进行过滤。Filter 缓存机制通过缓存这些过滤结果,以便在后续相同的查询中重用,从而减少计算开销。
以下是 Elasticsearch filter 缓存机制的详细解释:
1. Filter 缓存的工作原理
缓存存储:Elasticsearch 使用内存来存储过滤器的结果。这些缓存结果通常存储在内存中的
filter_cache中。缓存键:每个过滤器的结果都有一个唯一的键,这个键通常由过滤器的类型和参数组成。
缓存命中:当一个新的查询到达时,Elasticsearch 会检查其过滤器是否已经在缓存中。如果是,则直接使用缓存的结果,而不是重新计算。
缓存失效:如果索引的数据发生变化(例如,通过索引新的文档或删除现有文档),相关的过滤器缓存可能会失效。
2. 缓存的类型
Elasticsearch 主要有两种类型的过滤器缓存:
节点级过滤器缓存(Node Query Cache):这是默认的缓存机制,适用于所有节点上的所有查询。它存储了过滤器结果的位图(bitmaps),可以快速地进行布尔运算。
分片级过滤器缓存(Shard Request Cache):这种缓存机制在每个分片级别上工作,适用于特定分片上的重复查询。它存储了查询结果的摘要,而不是完整的结果集。
3. 配置和使用
启用/禁用缓存:可以通过设置索引级别的参数来启用或禁用过滤器缓存。例如:
PUT /my_index/_settings { "index.requests.cache.enable": true }调整缓存大小:可以通过 JVM 参数来调整 Elasticsearch 可用的堆内存大小,从而间接影响过滤器缓存的大小。例如:
-Xms4g -Xmx4g监控缓存:可以使用 Elasticsearch 的监控 API 来查看缓存的命中率和状态,以便进行性能调优。
4. 注意事项
内存使用:过滤器缓存会占用 JVM 堆内存,因此需要合理配置以避免内存溢出。
数据一致性:由于缓存是基于数据的快照,因此在数据频繁更新的场景下,缓存可能会很快失效,导致缓存效果不佳。
适用场景:过滤器缓存特别适用于那些查询模式固定且数据变化不频繁的场景。
5. 示例
假设有一个查询如下:
{
"query": {
"bool": {
"must": { "match": { "title": "Elasticsearch" } },
"filter": [
{ "term": { "status": "published" } },
{ "range": { "publish_date": { "gte": "now-1d/d" } } }
]
}
}
}在这个查询中,term 和 range 过滤器可能会被缓存,以便在后续相同的查询中重用。
总之,Elasticsearch 的 filter 缓存机制是一种强大的工具,可以显著提高查询性能,但也需要根据具体的使用场景和数据特性进行适当的配置和管理。
Elasticsearch的filter的caching(缓存)机制详解
这篇文章详细介绍了Elasticsearch中filter的缓存机制,旨在通过缓存优化查询性能。
1. Elasticsearch Filter的基本概念:
- Filter的作用:用于过滤出符合特定条件的文档,不计算相关性分数,也不排序。
- Filter与Query的区别:Query不仅过滤文档,还计算相关性分数并进行排序;Filter仅过滤文档。
2. Bitset的使用:
- 构建Bitset:为每个匹配的文档列表构建一个二进制数组(bitset),标识文档是否匹配某个条件。
- 遍历Bitset:优先从最稀疏的bitset开始遍历,以减少不必要的数据扫描。
3. Caching机制:
- 缓存策略:跟踪最近256个查询中的过滤条件,超过一定次数的bitset会被缓存。
- 缓存对象:缓存的是bitset而不是完整的文档列表,以节省内存空间。
- 缓存条件:对于小于1000个文档或小于索引总大小3%的segment,不进行缓存。
4. 缓存更新:
- 自动更新:当文档新增或修改时,对应的bitset会自动更新。
- 缓存失效:缓存的数据在特定条件下会失效,以确保数据的准确性。
5. 实际应用示例:
- 示例1:搜索特定日期范围的文档,构建bitset并遍历以找到匹配的文档。
- 示例2:在多个filter条件下搜索文档,利用bitset进行高效过滤。
6. Filter与Query的执行顺序:
- Filter优先级:Filter通常在Query之前执行,以减少需要处理的数据量。
- 性能优化:通过Filter过滤后再进行Query,可以提高查询效率。
7. 常见过滤器类型:
- 范围过滤器:过滤指定范围内的文档。
- 存在过滤器:过滤包含特定字段的文档。
- 缺失过滤器:过滤缺少特定字段的文档。
- 前缀过滤器:过滤以特定前缀开头的文档。
- 正则表达式过滤器:过滤符合正则表达式的文档。
8. 总结:
- 缓存的重要性:通过缓存bitset,可以避免重复扫描倒排索引,提高查询性能。
- 注意事项:对于小segment和不常用的filter条件,不进行缓存以节省资源。
通过这些内容,读者可以更好地理解Elasticsearch中filter的缓存机制及其在实际应用中的重要性。
直接举例说明
1.假设现在要在倒排索引中去搜索字符串(xxx)
比如如下有个倒排索引列表:
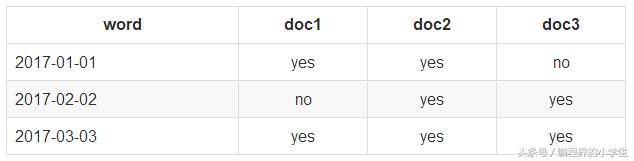
我现在要搜索:2017-02-02
去倒排索引中找,发现对应的document list是doc2和doc3
2.为每个在倒排索引中搜索到的结果,构建一个bitset使我们找到的doc list构建一个bitset,就是一个二进制数组,数组每个元素都是0或1。用来标识一个doc对一个filter条件是否匹配,如果匹配就是1,不匹配就是0
[0,1,1]
doc1:不匹配这个filter的
doc2和doc3:匹配这个filter的
尽可能用简单的数据结构去实现复杂的功能,可以节省内存空间,提升性能
3.遍历每个过滤条件对应的bitset,优先从最稀疏的开始搜索,查找满足所有条件的document,一次性其实可以在一个search请求中,发出多个filter条件,每个filter条件都会对应一个bitsite,遍历每个filter条件对应的bitset,先从最稀疏的开始遍历
[0, 0, 0, 1, 0, 0]:比较稀疏
[0, 1, 0, 1, 0, 1]
先遍历比较稀疏的bitset,就可以先过滤掉尽可能多的数据 遍历所有的bitset,找到匹配所有filter条件的doc
请求:filter,postDate=2017-01-01,userID=1
postDate: [0, 0, 1, 1, 0, 0]
userID: [0, 1, 0, 1, 0, 1]
遍历完两个bitset之后,找到的匹配所有条件的doc。就是doc4,就可以将doc4作为结果返回给client了
4.caching bitset
跟踪query,在最近256个query中超过一定次数的过滤条件,缓存其bitset。对于小segment(<1000,或<3%),不缓存bitset。
比如postDate=2017-01-01, [0,0,1,1,0,0],可以缓存在内存中,这样下次如果再有这个条件过来的时候,就不用重新扫描倒排索引,不用反复生成bitset,可以大幅度提升性能。
在最近的256个filter中,有某个filter超过了一定的次数,次数不固定,就会自动缓存这个filter对应的bitset
lter针对小segment获取到的结果,可以不缓存,segment记录数<1000,或者segment大小<index总大小的3%
segment数据量很小,此时哪怕是扫描也很快;segment会在后台自动合并,小segment很快就会跟其他小segment合并成大segment,此时就缓存也没有什么意义,segment很快就消失了
针对一个小segment的bitset,[0, 0, 1, 0]
filter比query的好处就在于会caching,但是之前不知道caching的是什么东西,实际上并不是一个filter返回的完整的doc list数据结果。而是filter bitset缓存起来。下次不用扫描倒排索引了。
5. filter大部分情况下来说,在query之前执行,先尽量过滤掉尽可能多的数据
query:是会计算doc对搜索条件的relevance score,还会根据这个score去排序
filter:只是简单过滤出想要的数据,不计算relevance score,也不排序
6. 如果document有新增或修改,那么cached bitset会被自动更新
postDate=2017-01-01,[0, 0, 1, 0]
document,id=5,postDate=2017-01-01,会自动更新到postDate=2017-01-01这个filter的bitset中,全自动,缓存会自动更新。postDate=2017-01-01的bitset,[0, 0, 1, 0, 1]
document,id=1,postDate=2016-12-30,修改为postDate-2017-01-01,此时也会自动更新bitset,[1, 0, 1, 0, 1]
7. 以后只要是有相同的filter条件的,会直接来使用这个过滤条件对应的cached bitset
elasticsearch实际总结(4)—— 查询缓存
一、参考
二、Shard request cache
分片级别的查询缓存,每个分片都有自己的缓存
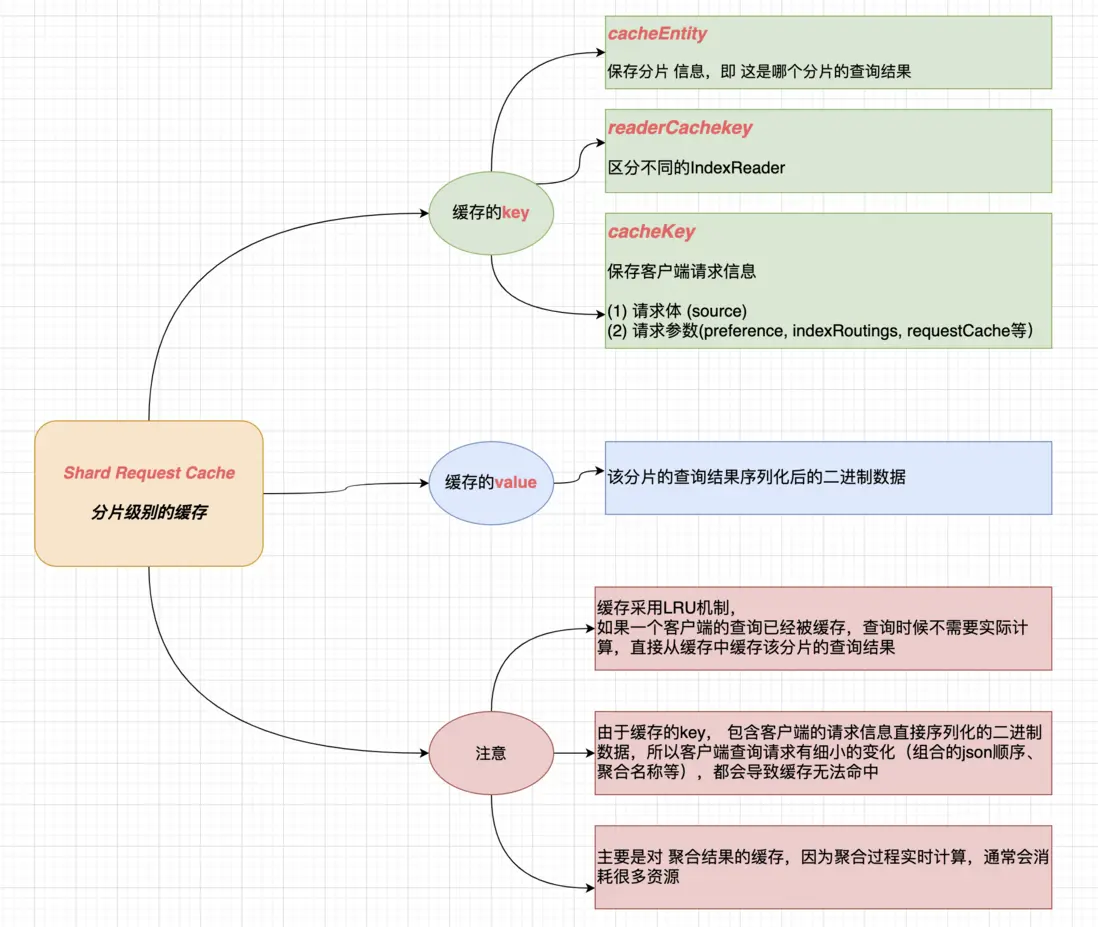
Shard request cache 是 Elasticsearch 中一种重要的缓存机制,它位于每个分片(shard)级别,用于缓存那些产生可重复结果的请求。这种缓存对于提高查询性能非常有用,尤其是在处理频繁执行且数据集相对静态或变化不大的场景时。
Shard Request Cache 的作用
减少计算开销:当相同的查询被执行多次时,如果底层的数据没有发生变化,那么缓存可以避免重复计算。
加速响应时间:通过直接从缓存中获取结果,减少了对倒排索引的访问和数据处理的时间,从而显著提高查询速度。
使用场景
聚合查询:对于经常使用的聚合查询,如按时间范围、地理位置等进行的统计分析,request cache 可以缓存这些聚合桶的结果。
过滤条件:对于常用的过滤条件,特别是那些基于静态数据的过滤器,使用 request cache 可以快速返回结果。
读密集型应用:在读取操作远多于写入操作的应用场景中,利用 request cache 能够大幅提升整体性能。
配置与管理
启用/禁用:
默认情况下,request cache 是开启的。你可以在创建索引时通过设置
index.requests.cache.enable: true来显式地启用它。如果需要全局关闭,可以在
elasticsearch.yml文件中设置indices.requests.cache.enabled: false。调整缓存大小:
你可以通过设置
indices.requests.cache.size参数来控制整个集群的 request cache 大小。例如,设置为50%意味着将 JVM 堆内存的一半分配给 request cache。对于特定索引,可以通过
PUT /my_index/_settings设置index.requests.cache.size来指定该索引的 request cache 大小。清理缓存:
当索引中的文档发生更新时,相关的 request cache 会被自动清除。此外,也可以手动清理某个索引的缓存,使用
_cache/clearAPI,如POST /my_index/_cache/clear?request=true。监控缓存状态:
通过
GET /_nodes/stats/indices/request_cache或者GET /<index>/_stats/request_cache端点可以查看当前 request cache 的状态信息,包括命中率、缓存条目数量等指标。监控缓存命中率有助于评估缓存配置是否合理。一个较高的命中率通常意味着良好的性能表现,但如果命中率过低,则可能需要考虑优化查询或者增加缓存容量。
注意事项
数据变更影响:当索引中的数据发生变化时,相关的 request cache 会被清空。因此,在数据频繁更新的情况下,request cache 的效果会大打折扣。
内存使用:request cache 会占用 JVM 堆内存,因此在资源有限的环境中需要谨慎设置其大小,以避免因缓存过大导致其他服务受到影响。
适用性:并非所有类型的查询都适合使用 request cache。例如,对于实时性要求极高或数据变化非常频繁的情况,过度依赖缓存反而可能导致性能下降。
总之,合理地利用 shard request cache 可以极大地提升 Elasticsearch 查询性能,特别是在处理大量读操作和复杂聚合查询的场景下。同时,需要注意根据实际业务需求和数据特点灵活调整缓存策略,以达到最佳的性能优化效果。
Shard Request Cache(分片请求缓存)是Elasticsearch中的一种缓存机制,用于缓存分片级别的查询结果。这种缓存机制可以显著提高查询性能,特别是在重复执行相同查询的情况下。
工作原理
缓存对象:
Shard Request Cache缓存的是分片级别的查询结果,而不是整个索引的结果。
缓存的数据包括文档ID和它们的得分(如果查询涉及评分)。
缓存策略:
缓存是基于请求的,只有当查询请求满足一定条件时,结果才会被缓存。
默认情况下,Elasticsearch会缓存那些返回结果数量较少的查询(例如,使用
size=0的查询)。
缓存命中:
当相同的查询再次执行时,Elasticsearch会首先检查缓存中是否存在结果。
如果存在,直接从缓存中获取结果,而不需要重新执行查询。
缓存失效:
缓存的结果会在以下情况下失效:
相关的分片被删除或重新分配。
缓存的数据被新的数据覆盖。
缓存达到其最大大小限制。
配置和使用
启用和禁用缓存:
可以通过设置
index.requests.cache.enable来启用或禁用分片请求缓存。默认情况下,这个设置是启用的。
配置缓存大小:
可以通过设置
index.requests.cache.size来配置缓存的最大大小。默认情况下,缓存大小是1%的堆内存。
使用示例:
以下是一个简单的示例,展示如何使用Shard Request Cache:
GET /my_index/_search?request_cache=true { "query": { "match_all": {} }, "size": 0 }
注意事项
缓存命中率:
缓存命中率取决于查询的重复性。如果查询非常独特,缓存可能不会带来显著的性能提升。
内存使用:
缓存会占用内存资源,因此需要合理配置缓存大小,以避免内存不足的问题。
数据一致性:
由于缓存的数据可能会过时,因此在某些情况下,可能需要手动清除缓存以确保数据的一致性。
通过合理使用Shard Request Cache,可以显著提高Elasticsearch的查询性能,特别是在处理大量重复查询的场景中。
2.1 缓存策略
并不是所有的分片级查询都会被缓存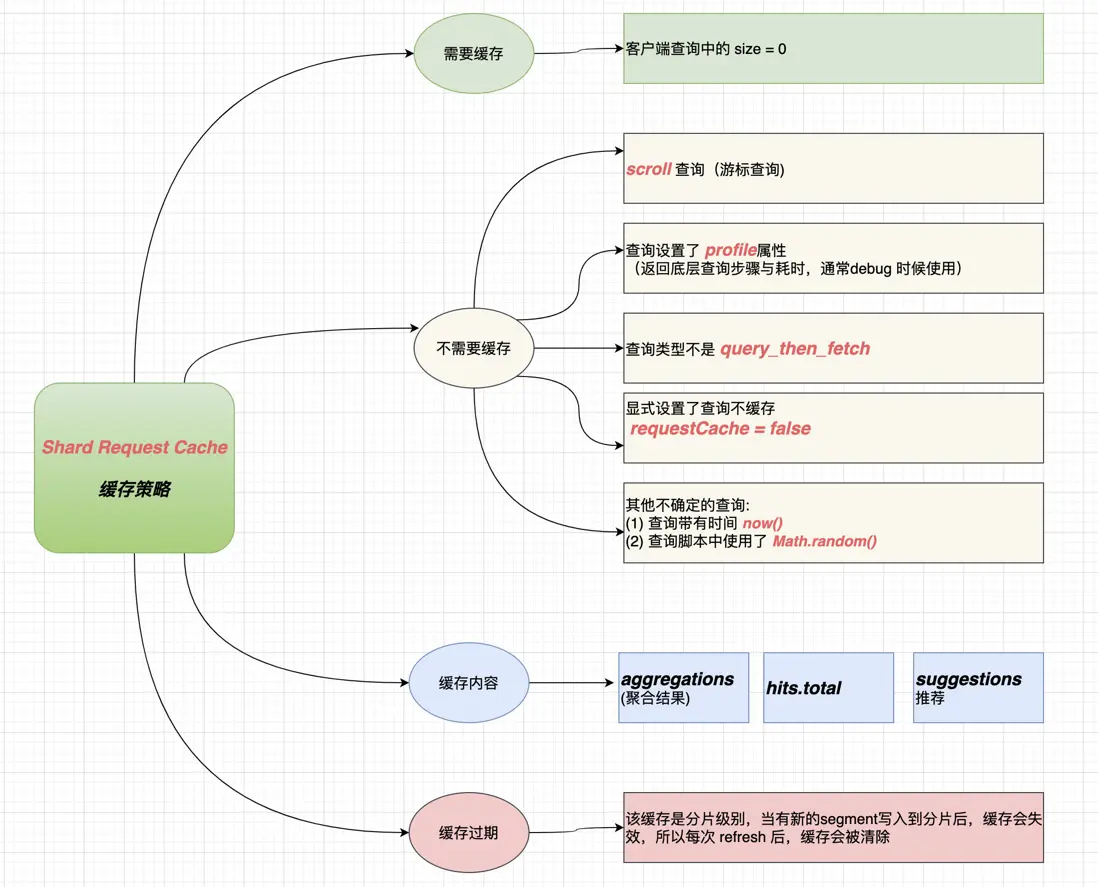
es并不是所有的分片级查询都会被缓存
确实,Elasticsearch并不会缓存所有的分片级查询。缓存机制是针对特定的查询类型和配置进行优化的。以下是一些影响分片级查询缓存的因素:
1. 查询类型
全量查询:对于返回大量结果的查询(例如,
_search请求),缓存可能不会生效,因为结果集太大,不适合缓存。计数查询:对于返回计数的查询(例如,
_count请求),Elasticsearch会缓存结果,因为这些查询通常返回较小的结果集。聚合查询:对于返回聚合结果的查询,缓存机制可能会有所不同,具体取决于聚合的类型和配置。
2. 缓存配置
缓存大小:通过设置
index.requests.cache.size可以配置缓存的最大大小。如果缓存空间不足,较旧的缓存项可能会被清除。缓存策略:可以通过设置
index.requests.cache.expire_after来配置缓存的过期时间。超过这个时间的缓存项将被自动清除。缓存启用/禁用:可以通过设置
index.requests.cache.enable来启用或禁用分片请求缓存。3. 查询参数
request_cache参数:在执行查询时,可以通过设置request_cache=true来显式启用缓存。如果设置为false,则不会使用缓存。
size参数:对于返回结果的查询,如果size=0,表示只返回计数而不返回实际文档,这种情况下缓存可能会生效。4. 数据变化
分片数据变化:如果分片的数据发生了变化(例如,新增、修改或删除文档),相关的缓存项会被自动失效。
索引重建:当索引被重建或重新分配时,所有相关的缓存项都会被清除。
5. 查询的唯一性
唯一性查询:对于非常独特的查询,缓存可能不会带来显著的性能提升,因为这些查询不太可能再次执行。
示例
以下是一个示例,展示如何配置和使用分片请求缓存:
PUT /my_index { "settings": { "index.requests.cache.enable": true, "index.requests.cache.size": "10%" } } GET /my_index/_search?request_cache=true { "query": { "match_all": {} }, "size": 0 }在这个示例中,我们启用了分片请求缓存,并将缓存大小设置为索引总内存的10%。然后,我们执行一个返回计数的查询,并显式启用缓存。
总之,Elasticsearch的分片级查询缓存机制是针对特定查询类型和配置进行优化的,不是所有的分片级查询都会被缓存。合理配置和使用缓存可以显著提高查询性能。
确实,Elasticsearch 的 shard request cache 并不是所有分片级的查询都会被缓存。请求缓存(request cache)有一些特定的行为和限制条件,这些决定了哪些查询会被缓存以及何时会被清除。以下是一些关键点:
不会被缓存的情况
包含
now或now-XXX的日期表达式:
如果查询中包含了动态的时间表达式,如
now-1d/d,这样的查询结果会随时间而变化,因此不会被缓存。基于
_version的查询:
如果查询依赖于文档版本号(_version),因为每次更新后版本号都会改变,所以这类查询不会被缓存。
脚本字段:
如果查询中使用了脚本字段(script fields),由于脚本可能产生不同的输出,这些查询也不会被缓存。
排序和评分:
涉及到排序(sort)或评分(score)的查询通常不会被缓存,因为它们的结果可能会根据数据的变化而不同。
聚合中的脚本:
如果在聚合中使用了脚本,那么这个聚合的结果不会被缓存。
非确定性函数:
任何使用非确定性函数的查询都不会被缓存,例如随机数生成器等。
滚动搜索:
滚动搜索(scroll search)的结果不会被缓存,因为它涉及到大量的数据遍历,而且滚动上下文本身是临时的。
索引级别设置禁用:
如果某个索引显式地禁用了请求缓存(通过设置
index.requests.cache.enable: false),那么该索引上的所有查询都不会被缓存。查询参数影响:
查询时使用的某些参数,如
size、from等,如果这些参数发生变化,即使查询条件相同,也会导致缓存失效。缓存清理
数据变更:当索引中的数据发生更改时(新增、删除或更新文档),相关的缓存条目将被自动清除。
手动清理:可以通过 API 手动清理缓存,例如使用
_cache/clearAPI 来清除特定索引或整个集群的请求缓存。监控与调优
监控缓存状态:通过 Elasticsearch 提供的统计信息来监控缓存的状态,包括命中率、缓存大小等。
调整缓存大小:根据实际需要调整
indices.requests.cache.size参数,以确保有足够的内存空间用于缓存,同时避免占用过多资源。理解这些规则可以帮助你更好地设计查询,并利用请求缓存来优化性能。对于那些不适合缓存或者缓存效果不佳的查询,可以考虑其他优化手段,比如合理的设计索引结构、使用合适的分析器等。
三、Node Query Cache
NodeQueryCache是在Lucene层面实现的,默认开启,ES层面会进行一些策略控制和信息统计