任何一门学科都有它基本的知识结构,而Dubbo作为一款优秀的微服务框架,自然也有着其领域的基础知识。所谓万丈高楼平地起,想把Dubbo用得游刃有余,对基础知识的深刻理解就尤为重要了。
举一个最基础的问题:Dubbo的总体架构是什么样?一定有初学者或者面试官问过你吧,但常年忙着写业务代码逻辑,对于这样的提问,想必你是既熟悉又陌生,有种欲言又止的感觉,心里清楚却又无法一气呵成地向他人讲清楚。
没关系,今天,我们就一起来回顾Dubbo的基础知识体系,温故知新,之后我们碰到的一些异常或者问题时,就能快速定位问题归属于Dubbo的哪个角色,找准方向力求解决。
总体架构
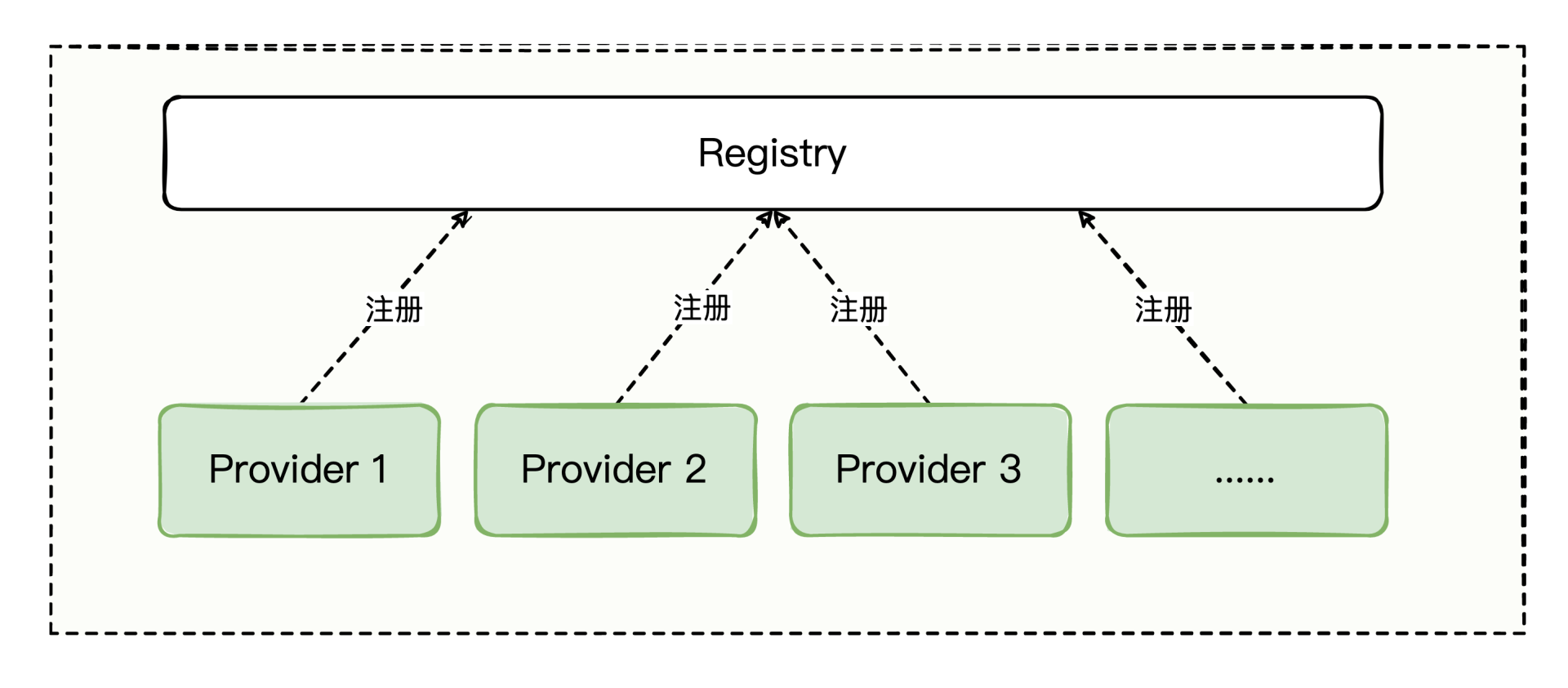
我们知道,Dubbo的主要节点角色有五个:
Container:服务运行容器,为服务的稳定运行提供运行环境。
Provider:提供方,暴露接口提供服务。
Consumer:消费方,调用已暴露的接口。
Registry:注册中心,管理注册的服务与接口。
Monitor:监控中心,统计服务调用次数和调用时间。
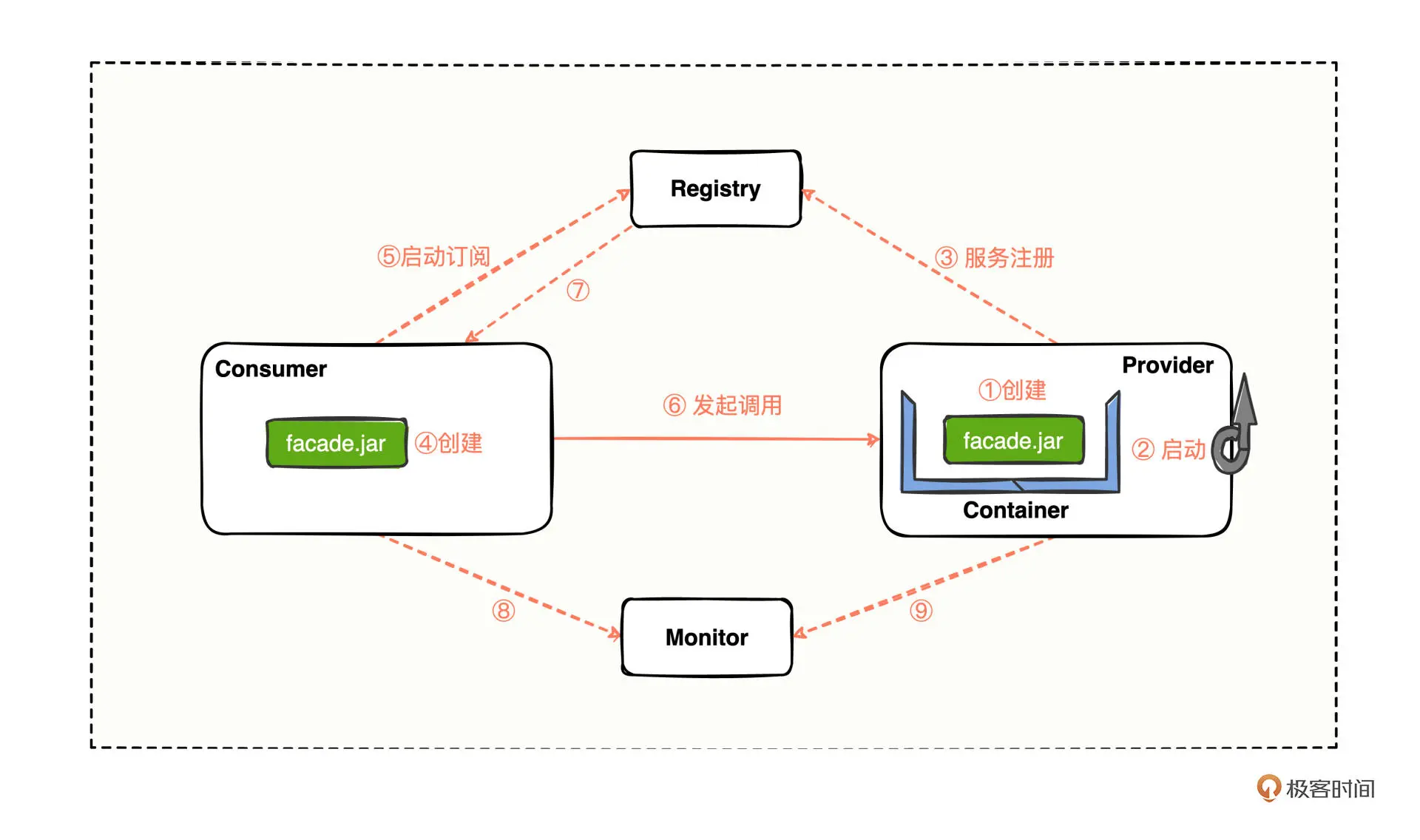
我们画一张Dubbo的总体架构示意图,你可以清楚地看到每个角色大致的交互方式
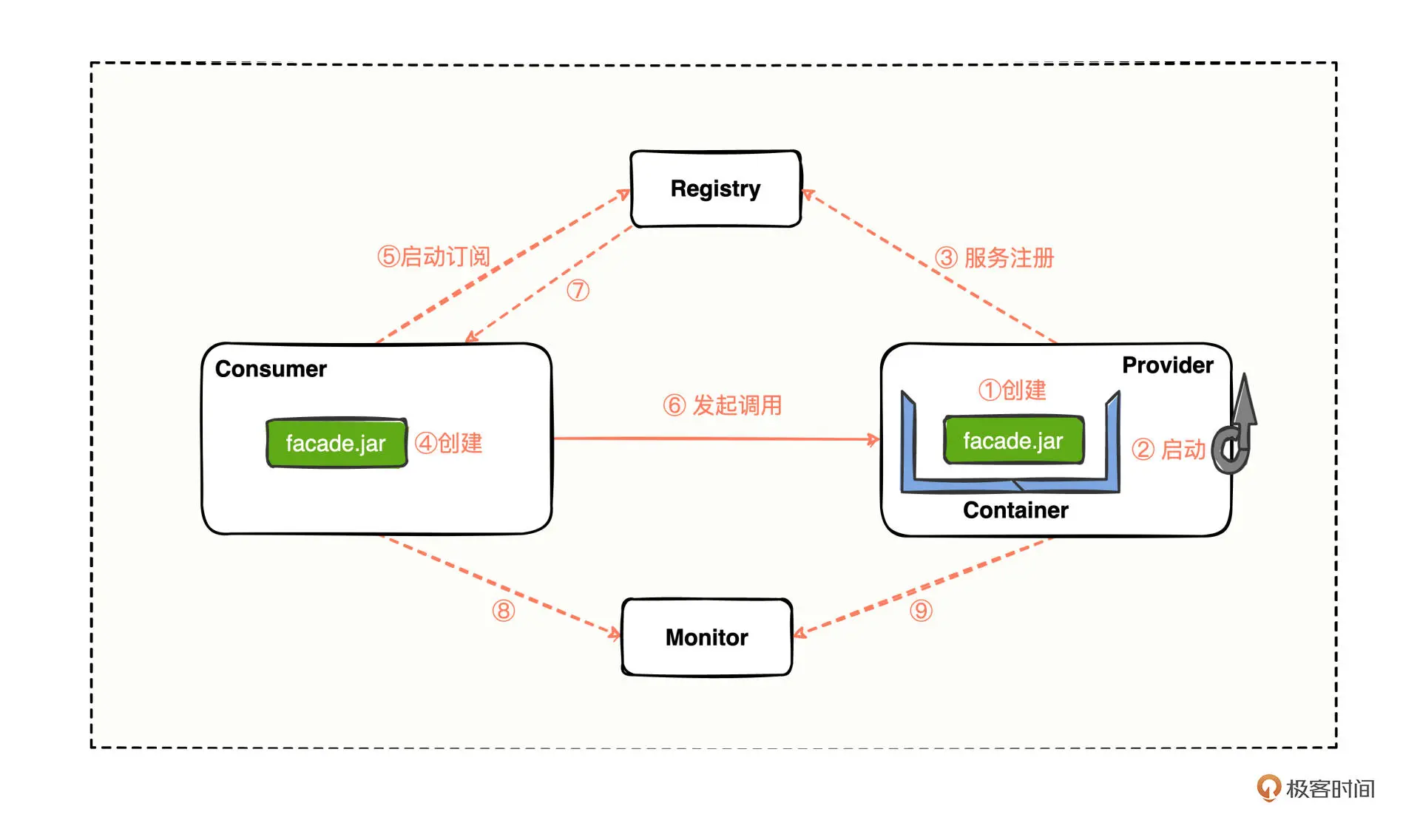
对于一个Dubbo项目来说,我们首先会从提供方进行工程创建(第 ① 步),并启动工程(第 ② 步)来进行服务注册(第 ③ 步),接着会进行消费方的工程创建(第 ④ 步)并启动订阅服务(第 ⑤ 步)来发起调用(第 ⑥ 步),到这里,消费方就能顺利调用提供方了。
消费方在运行的过程中,会感知注册中心的服务节点变更(第 ⑦ 步),最后消费方和提供方将调用的结果指标同步至监控中心(第 ⑧⑨ 步)。
在这样的完整流程中, 每个角色在Dubbo架构体系中具体起到了什么样的作用?每一步我们有哪些操作注意点呢? 带着问题,我们通过实操来仔细分析。
1. Container 服务运行容器
首先,提供方、消费方的正常运转,离不开一个大前提——运行的环境。
我们需要一个容器来承载应用的运行,可以是 Tomcat 容器,也可以是 Jetty 容器,还可以是 Undertow 容器等等,只要能负责启动、加载,并运行服务提供者来提供服务就可以了。
2. Provider 提供方
有了Container为服务的稳定运行提供环境后,我们就可以开始新建工程了。
第 ① 步,先自己新建一个提供方的工程,引用一个 facade.jar 包来对外暴露服务,编写的关键代码如下:
///////////////////////////////////////////////////
// 提供方应用工程的启动类
///////////////////////////////////////////////////
// 导入启动提供方所需要的Dubbo XML配置文件
@ImportResource("classpath:dubbo-04-xml-boot-provider.xml")
// SpringBoot应用的一键式启动注解
@SpringBootApplication
public class Dubbo04XmlBootProviderApplication {
public static void main(String[] args) {
// 调用最为普通常见的应用启动API
SpringApplication.run(Dubbo04XmlBootProviderApplication.class, args);
// 启动成功后打印一条日志
System.out.println("【【【【【【 Dubbo04XmlBootProviderApplication 】】】】】】已启动.");
}
}
///////////////////////////////////////////////////
// 提供方应用工程的Dubbo XML配置文件内容:dubbo-04-xml-boot-provider.xml
///////////////////////////////////////////////////
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:dubbo="http://dubbo.apache.org/schema/dubbo"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.3.xsd
http://dubbo.apache.org/schema/dubbo
http://dubbo.apache.org/schema/dubbo/dubbo.xsd">
<!-- 注册中心的地址,通过 address 填写的地址提供方就可以联系上 zk 服务 -->
<dubbo:registry address="zookeeper://127.0.0.1:2181"></dubbo:registry>
<!-- 提供者的应用服务名称 -->
<dubbo:application name="dubbo-04-xml-boot-provider"></dubbo:application>
<!-- 提供者需要暴露服务的协议,提供者需要暴露服务的端口 -->
<dubbo:protocol name="dubbo" port="28040"></dubbo:protocol>
<!-- 提供者暴露服务的全路径为 interface 里面的内容 -->
<dubbo:service interface="com.hmilyylimh.cloud.facade.demo.DemoFacade"
ref="demoFacade"></dubbo:service>
<!-- 提供者暴露服务的业务实现逻辑的承载体 -->
<bean id="demoFacade" class="com.hmilyylimh.cloud.xml.demo.DemoFacadeImpl"></bean>
</beans>
将提供方应用启动的代码、Dubbo配置文件内容编写好后,就准备 第 ② 步 启动了。
如果你现在运行 Dubbo04XmlBootProviderApplication 启动类,会直接遇到非法状态异常:
java.lang.IllegalStateException: java.lang.IllegalStateException: zookeeper not connected
at org.apache.dubbo.config.deploy.DefaultApplicationDeployer.prepareEnvironment(DefaultApplicationDeployer.java:678) ~[dubbo-3.0.7.jar:3.0.7]
at org.apache.dubbo.config.deploy.DefaultApplicationDeployer.startConfigCenter(DefaultApplicationDeployer.java:261) ~[dubbo-3.0.7.jar:3.0.7]
at org.apache.dubbo.config.deploy.DefaultApplicationDeployer.initialize(DefaultApplicationDeployer.java:185) ~[dubbo-3.0.7.jar:3.0.7]
这是因为不做任何超时时间设置时,ConfigCenterConfig#checkDefault 方法中会默认超时时间为 30秒,然后将“30秒”传给 CuratorFramework 让它在有限的时间内连接上注册中心,若30秒还没有连接上的话,就抛出了这里你看到的非法状态异常,提示 zookeeper not connected,表示注册中心没有连接上。
所以接下来我们需要做的就是,自己启动一个 ZooKeeper 注册中心,然后再次运行启动类,就能看到启动成功的打印信息:
2022-11-11 23:57:27.261 INFO 12208 --- [ main] .h.c.x.Dubbo04XmlBootProviderApplication : Started Dubbo04XmlBootProviderApplication in 5.137 seconds (JVM running for 6.358)
2022-11-11 23:57:27.267 INFO 12208 --- [pool-1-thread-1] .b.c.e.AwaitingNonWebApplicationListener : [Dubbo] Current Spring Boot Application is await...
【【【【【【 Dubbo04XmlBootProviderApplication 】】】】】】已启动.
接下来的 第 ③ 步 是在提供方启动的过程中进行的。启动成功后,你可以通过 ZooKeeper 中自带的 zkCli.cmd 或 zkCli.sh 连上注册中心,查看提供方在注册中心留下了哪些痕迹,如图:

通过 ls / 查看根目录,我们发现 Dubbo 注册了两个目录,/dubbo 和 /services 目录:

这是 Dubbo 3.x 推崇的一个应用级注册新特性,在不改变任何 Dubbo 配置的情况下,可以兼容一个应用从 2.x 版本平滑升级到 3.x 版本,这个新特性主要是为了将来能支持十万甚至百万的集群实例地址发现,并且可以与不同的微服务体系实现地址发现互联互通。
但这里有个小问题了,控制提供方应用到底应该接口级注册,还是应用级注册,还是两个都注册呢?
你可以通过在提供方设置 dubbo.application.register-mode 属性来自由控制,设置的值有3 种:
interface:只接口级注册。
instance:只应用级注册。
all:接口级注册、应用级注册都会存在,同时也是默认值。
3. Consumer 消费方
提供方启动完成后,我们就可以接着新建消费方的工程了。
第 ④ 步,在新建的消费方工程中,同样需要引用 facade.jar 来进行后续的远程调用,你可以参考要编写的关键代码:
///////////////////////////////////////////////////
// 消费方应用工程的启动类
///////////////////////////////////////////////////
// 导入启动消费方所需要的Dubbo XML配置文件
@ImportResource("classpath:dubbo-04-xml-boot-consumer.xml")
// SpringBoot应用的一键式启动注解
@SpringBootApplication
public class Dubbo04XmlBootConsumerApplication {
public static void main(String[] args) {
// 调用最为普通常见的应用启动API
ConfigurableApplicationContext ctx =
SpringApplication.run(Dubbo04XmlBootConsumerApplication.class, args);
// 启动成功后打印一条日志
System.out.println("【【【【【【 Dubbo04XmlBootConsumerApplication 】】】】】】已启动.");
// 然后向提供方暴露的 DemoFacade 服务进行远程RPC调用
DemoFacade demoFacade = ctx.getBean(DemoFacade.class);
// 将远程调用返回的结果进行打印输出
System.out.println(demoFacade.sayHello("Geek"));
}
}
///////////////////////////////////////////////////
// 消费方应用工程的Dubbo XML配置文件内容:dubbo-04-xml-boot-consumer.xml
///////////////////////////////////////////////////
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:dubbo="http://dubbo.apache.org/schema/dubbo"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.3.xsd
http://dubbo.apache.org/schema/dubbo
http://dubbo.apache.org/schema/dubbo/dubbo.xsd">
<!-- 消费者的应用服务名称,最好是大家当前应用归属的系统名称 -->
<dubbo:application name="dubbo-04-xml-boot-consumer"></dubbo:application>
<!-- 注册中心的地址,通过 address 填写的地址提供方就可以联系上 zk 服务 -->
<dubbo:registry address="zookeeper://127.0.0.1:2181"></dubbo:registry>
<!-- 引用远程服务 -->
<dubbo:reference id="demoFacade"
interface="com.hmilyylimh.cloud.facade.demo.DemoFacade">
</dubbo:reference>
</beans>
把消费方应用启动的代码、Dubbo配置文件内容编写好后,我们就准备启动了。
不过在启动之前,如果提供方还没有启动,也就是说提供方还没有发布 DemoFacade 服务,这个时候,我们启动消费方会看到这样的报错信息:
java.lang.IllegalStateException: Failed to check the status of the service com.hmilyylimh.cloud.facade.demo.DemoFacade. No provider available for the service com.hmilyylimh.cloud.facade.demo.DemoFacade from the url consumer://192.168.100.183/com.hmilyylimh.cloud.facade.demo.DemoFacade?application=dubbo-04-xml-boot-consumer&background=false&dubbo=2.0.2&interface=com.hmilyylimh.cloud.facade.demo.DemoFacade&methods=sayHello,say&pid=11876&qos.enable=false®ister.ip=192.168.100.183&release=3.0.7&side=consumer&sticky=false×tamp=1668219196431 to the consumer 192.168.100.183 use dubbo version 3.0.7
at org.apache.dubbo.config.ReferenceConfig.checkInvokerAvailable(ReferenceConfig.java:545) ~[dubbo-3.0.7.jar:3.0.7]
at org.apache.dubbo.config.ReferenceConfig.init(ReferenceConfig.java:293) ~[dubbo-3.0.7.jar:3.0.7]
at org.apache.dubbo.config.ReferenceConfig.get(ReferenceConfig.java:219) ~[dubbo-3.0.7.jar:3.0.7]
又看到了非法状态异常的类,告诉我们检查 DemoFacade 的状态失败了,并提示 No provider available 说明还暂时没有提供者,导致消费方无法启动成功。
怎么解决这个问题呢?我们可以考虑 3 种方案:
方案1:将提供方应用正常启动起来即可。
方案2:可以考虑在消费方的Dubbo XML配置文件中,为 DemoFacade 服务添加
check="false"的属性,来达到启动不检查服务的目的,即:
<!-- 引用远程服务 -->
<dubbo:reference id="demoFacade" check="false"
interface="com.hmilyylimh.cloud.facade.demo.DemoFacade">
</dubbo:reference>
方案3:也可以考虑在消费方的Dubbo XML配置文件中,为整个消费方添加
check="false"的属性,来达到启动不检查服务的目的,即:
<!-- 为整个消费方添加启动不检查提供方服务是否正常 -->
<dubbo:consumer check="false"></dubbo:consumer>
这 3 种方法,我们结合实际日常开发过程分析一下。
方案1,耦合性太强,因为提供方没有发布服务而导致消费方无法启动,有点说不过去。
方案2,需要针对指定的服务级别设置“启动不检查”,但一个消费方工程,会有几十上百甚至上千个提供方服务配置,一个个设置起来特别麻烦,而且一般我们也很少会逐个设置。
方案3,是我们比较常用的一种设置方式,保证不论提供方的服务处于何种状态,都不能影响消费方的启动,而且只需要一条配置,没有方案2需要给很多个提供方服务挨个配置的困扰。
不过这里为了正常演示,我们还是按照方案1中规中矩的方式来,先把提供方应用启动起来,再启动消费方,接下来你就能看到消费方启动成功的日志打印信息,并且也成功调用了提供方的服务,日志信息就是这样:
2022-11-12 10:38:18.758 INFO 11132 --- [pool-1-thread-1] .b.c.e.AwaitingNonWebApplicationListener : [Dubbo] Current Spring Boot Application is await...
【【【【【【 Dubbo04XmlBootConsumerApplication 】】】】】】已启动.
Hello Geek, I'm in 'dubbo-04-xml-boot-provider' project.
现在,消费方能成功启动了,接下来就要去注册中心订阅服务了,也就是 第 ⑤ 步,这一步也是在消费方启动的过程中进行的。启动成功后,你可以通过 ZooKeeper 中自带的 zkCli.cmd 或 zkCli.sh 连上注册中心,查看消费方在注册中心留下了哪些痕迹:

我们发现消费方也会向注册中心写数据,通过 ls /dubbo/metadata/com.hmilyylimh.cloud.facade.demo.DemoFacade 可以看到,有 consumer 目录,还有对应的消费方 URL 注册信息, 所以通过一个 interface,我们就能从注册中心查看有哪些提供方应用节点、哪些消费方应用节点。
而前面提到 Dubbo 3.x 推崇的一个应用级注册新特性,在消费方侧也存在如何抉择的问题,到底是订阅接口级注册信息,还是订阅应用级注册信息呢,还是说有兼容方案?
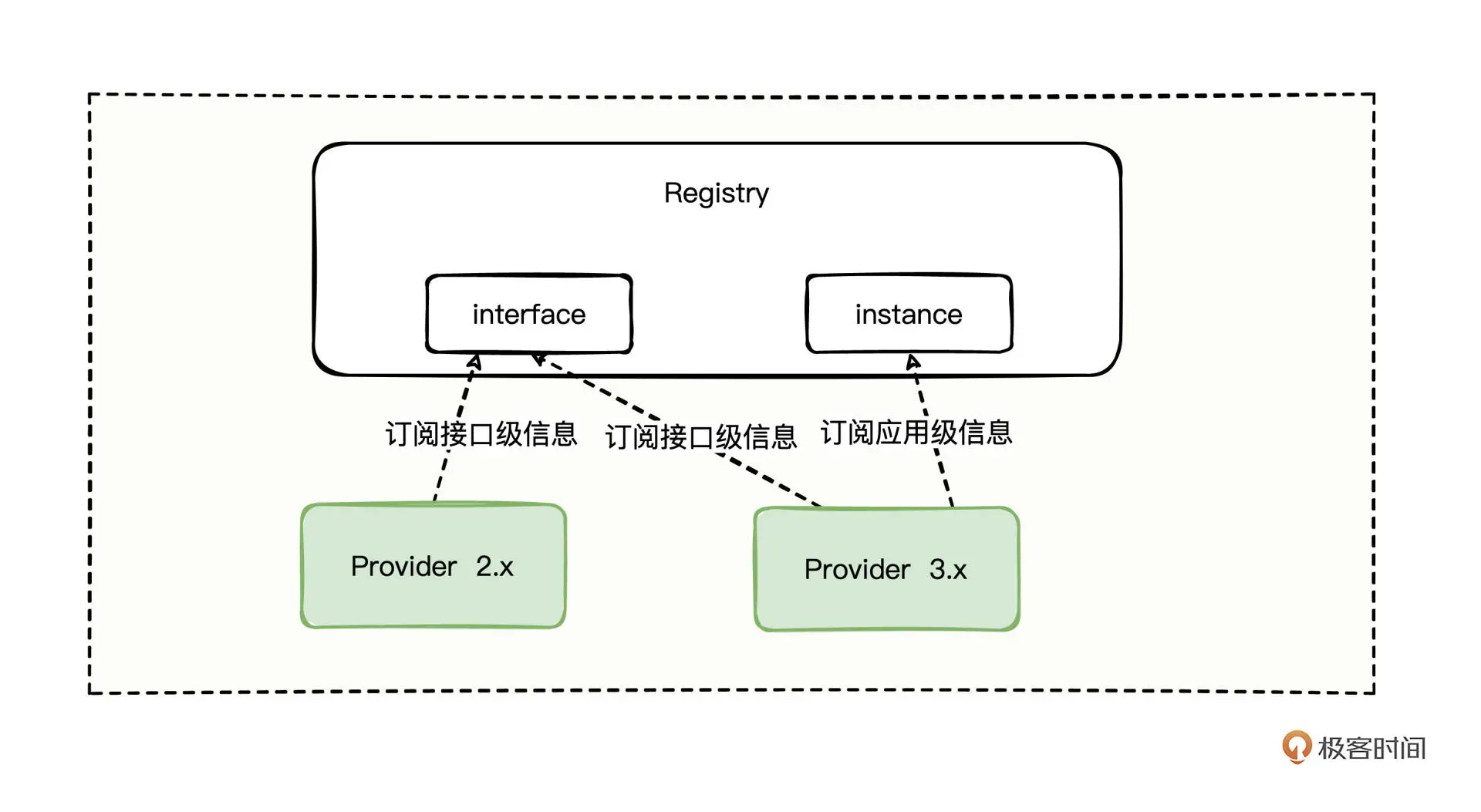
其实Dubbo也为我们提供了过渡的兼容方案,你可以通过在消费方设置 dubbo.application.service-discovery.migration 属性来兼容新老订阅方案,设置的值同样有 3 种:
FORCE_INTERFACE:只订阅消费接口级信息。
APPLICATION_FIRST:注册中心有应用级注册信息则订阅应用级信息,否则订阅接口级信息,起到了智能决策来兼容过渡方案。
FORCE_APPLICATION:只订阅应用级信息。
到现在提供方完成了启动和注册,消费方完成了启动和订阅,接下来消费方就可以向提供方发起调用了,也就是 第 ⑥ 步。
消费方向提供方发起远程调用的环节,调用的代码也非常简单:
// 然后向提供方暴露的 DemoFacade 服务进行远程RPC调用
DemoFacade demoFacade = ctx.getBean(DemoFacade.class);
// 将远程调用返回的结果进行打印输出
System.out.println(demoFacade.sayHello("Geek"));
区区两行代码,就跨越了网络从提供方那边拿到了结果,非常方便简单。
不过总有调用不顺畅的时候,尤其是在提供方服务有点耗时的情况下,你可能会遇到这样的异常信息:
Exception in thread "main" org.apache.dubbo.rpc.RpcException: Failed to invoke the method sayHello in the service com.hmilyylimh.cloud.facade.demo.DemoFacade. Tried 3 times of the providers [192.168.100.183:28040] (1/1) from the registry 127.0.0.1:2181 on the consumer 192.168.100.183 using the dubbo version 3.0.7. Last error is: Invoke remote method timeout. method: sayHello, provider: DefaultServiceInstance{serviceName='dubbo-04-xml-boot-provider', host='192.168.100.183', port=28040, enabled=true, healthy=true, metadata={dubbo.endpoints=[{"port":28040,"protocol":"dubbo"}], dubbo.metadata-service.url-params={"connections":"1","version":"1.0.0","dubbo":"2.0.2","release":"3.0.7","side":"provider","port":"28040","protocol":"dubbo"}, dubbo.metadata.revision=7c65b86f6f680876cbb333cb7c92c6f6, dubbo.metadata.storage-type=local}}, service{name='com.hmilyylimh.cloud.facade.demo.DemoFacade',group='null',version='null',protocol='dubbo',params={side=provider, application=dubbo-04-xml-boot-provider, release=3.0.7, methods=sayHello,say, background=false, deprecated=false, dubbo=2.0.2, dynamic=true, interface=com.hmilyylimh.cloud.facade.demo.DemoFacade, service-name-mapping=true, generic=false, anyhost=true},}, cause: org.apache.dubbo.remoting.TimeoutException: Waiting server-side response timeout by scan timer. start time: 2022-11-12 13:50:44.215, end time: 2022-11-12 13:50:45.229, client elapsed: 1 ms, server elapsed: 1013 ms, timeout: 1000 ms, request: Request [id=3, version=2.0.2, twoway=true, event=false, broken=false, data=RpcInvocation [methodName=sayHello, parameterTypes=[class java.lang.String], arguments=[Geek], attachments={path=com.hmilyylimh.cloud.facade.demo.DemoFacade, remote.application=dubbo-04-xml-boot-consumer, interface=com.hmilyylimh.cloud.facade.demo.DemoFacade, version=0.0.0, timeout=1000}]], channel: /192.168.100.183:57977 -> /192.168.100.183:28040
at org.apache.dubbo.rpc.cluster.support.FailoverClusterInvoker.doInvoke(FailoverClusterInvoker.java:114)
at org.apache.dubbo.rpc.cluster.support.AbstractClusterInvoker.invoke(AbstractClusterInvoker.java:340)
... 36 more
Caused by: java.util.concurrent.ExecutionException: org.apache.dubbo.remoting.TimeoutException: Waiting server-side response timeout by scan timer. start time: 2022-11-12 13:50:44.215, end time: 2022-11-12 13:50:45.229, client elapsed: 1 ms, server elapsed: 1013 ms, timeout: 1000 ms, request: Request [id=3, version=2.0.2, twoway=true, event=false, broken=false, data=RpcInvocation [methodName=sayHello, parameterTypes=[class java.lang.String], arguments=[Geek], attachments={path=com.hmilyylimh.cloud.facade.demo.DemoFacade, remote.application=dubbo-04-xml-boot-consumer, interface=com.hmilyylimh.cloud.facade.demo.DemoFacade, version=0.0.0, timeout=1000}]], channel: /192.168.100.183:57977 -> /192.168.100.183:28040
at java.base/java.util.concurrent.CompletableFuture.reportGet(CompletableFuture.java:395)
at java.base/java.util.concurrent.CompletableFuture.get(CompletableFuture.java:2093)
... 24 more
Caused by: org.apache.dubbo.remoting.TimeoutException: Waiting server-side response timeout by scan timer. start time: 2022-11-12 13:50:44.215, end time: 2022-11-12 13:50:45.229, client elapsed: 1 ms, server elapsed: 1013 ms, timeout: 1000 ms, request: Request [id=3, version=2.0.2, twoway=true, event=false, broken=false, data=RpcInvocation [methodName=sayHello, parameterTypes=[class java.lang.String], arguments=[Geek], attachments={path=com.hmilyylimh.cloud.facade.demo.DemoFacade, remote.application=dubbo-04-xml-boot-consumer, interface=com.hmilyylimh.cloud.facade.demo.DemoFacade, version=0.0.0, timeout=1000}]], channel: /192.168.100.183:57977 -> /192.168.100.183:28040
at org.apache.dubbo.remoting.exchange.support.DefaultFuture.doReceived(DefaultFuture.java:212)
at org.apache.dubbo.remoting.exchange.support.DefaultFuture.received(DefaultFuture.java:176)
... 29 more
首先是 RpcException 远程调用异常,发现 Tried 3 times 尝试了 3 次调用仍然拿不到结果。再看 TimeoutException 异常类, client elapsed: 1 ms, server elapsed: 1013 ms, timeout: 1000 ms,提示消费方在有限的 1000ms 时间内未拿到提供方的响应而超时了。
源码中默认的超时时间,可以从这段代码中查看,是 1000ms:
private DefaultFuture(Channel channel, Request request, int timeout) {
// 省略了其他逻辑代码
// 源码中 int DEFAULT_TIMEOUT = 1000 是这样的默认值
// 重点看这里,这里当任何超时时间未设置时,就采用源码中默认的 1000ms 为超时时效
this.timeout = timeout > 0 ? timeout : channel.getUrl().getPositiveParameter(TIMEOUT_KEY, DEFAULT_TIMEOUT);
// 省略了其他逻辑代码
}
对于这种情况,如果你预估可以稍微把超时时间设置长一点,可以在消费方的Dubbo XML配置文件中,为 DemoFacade 服务添加 timeout="5000" 的属性,来达到设置超时时间为5000ms 的目的,即:
<!-- 引用远程服务 -->
<dubbo:reference id="demoFacade" timeout="5000"
interface="com.hmilyylimh.cloud.facade.demo.DemoFacade">
</dubbo:reference>
正常情况下5000ms足够了,但有些时候网络抖动延时增大,需要稍微重试几次,你可以继续设置 retries="3" 来多重试3次,即:
<!-- 引用远程服务 -->
<dubbo:reference id="demoFacade" timeout="5100" retries="3"
interface="com.hmilyylimh.cloud.facade.demo.DemoFacade">
</dubbo:reference>
除了网络抖动影响调用,更多时候可能因为有些服务器故障了,比如消费方调着调着,提供方突然就挂了,消费方如果换台提供方,继续重试调用一下也许就正常了,所以你可以继续设置 cluster="failover" 来进行故障转移,比如:
<!-- 引用远程服务 -->
<dubbo:reference id="demoFacade" cluster="failover" timeout="5000" retries="3"
interface="com.hmilyylimh.cloud.facade.demo.DemoFacade">
</dubbo:reference>
当然故障转移只是一种手段,目的是当调用环节遇到一些不可预估的故障时,尽可能保证服务的正常运行,就好比这样的调用形式:
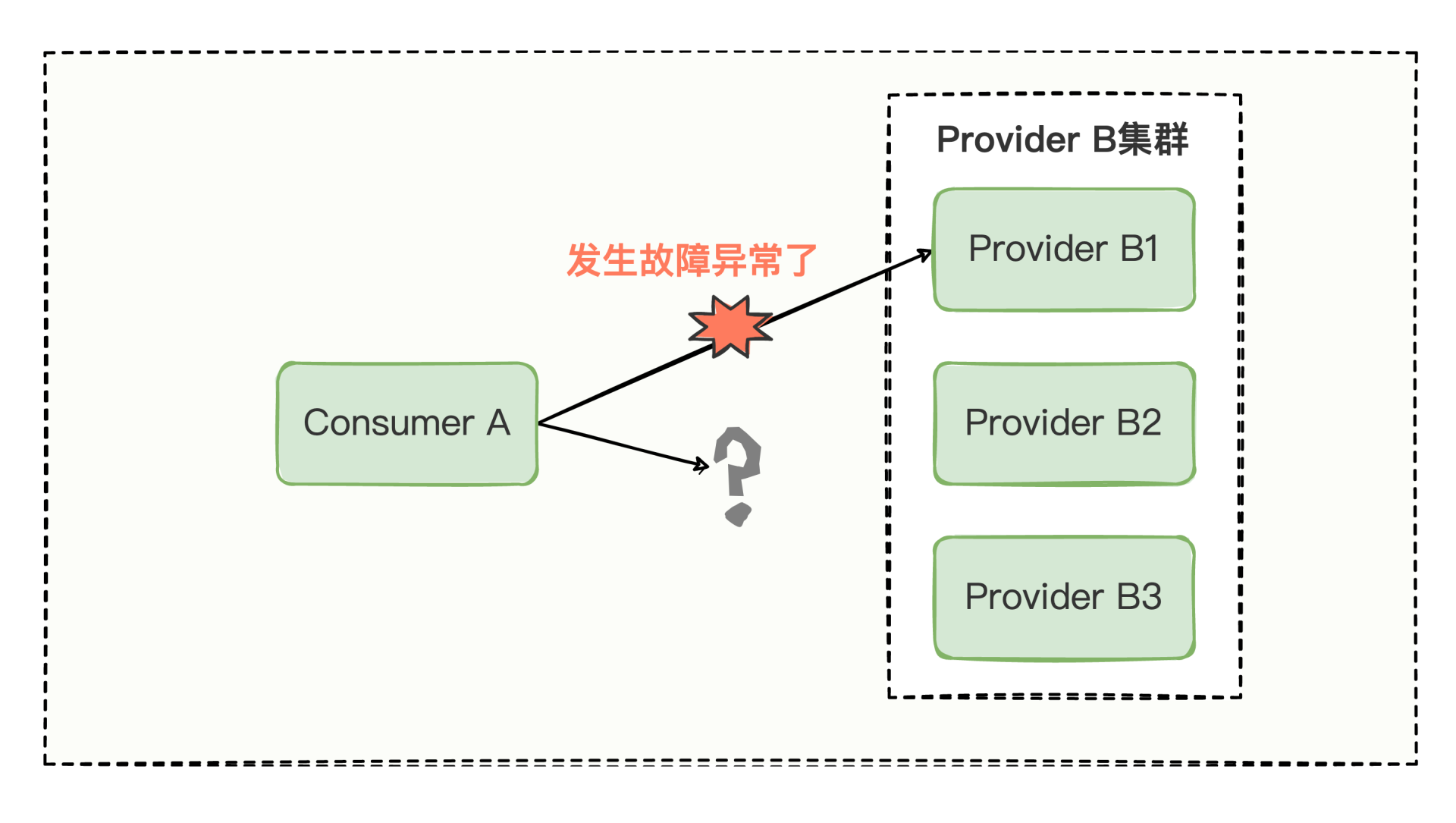
Dubbo 框架为了尽可能保障运行,除了有 failover 故障转移策略,还有许多的容错策略,我们常用的比如:
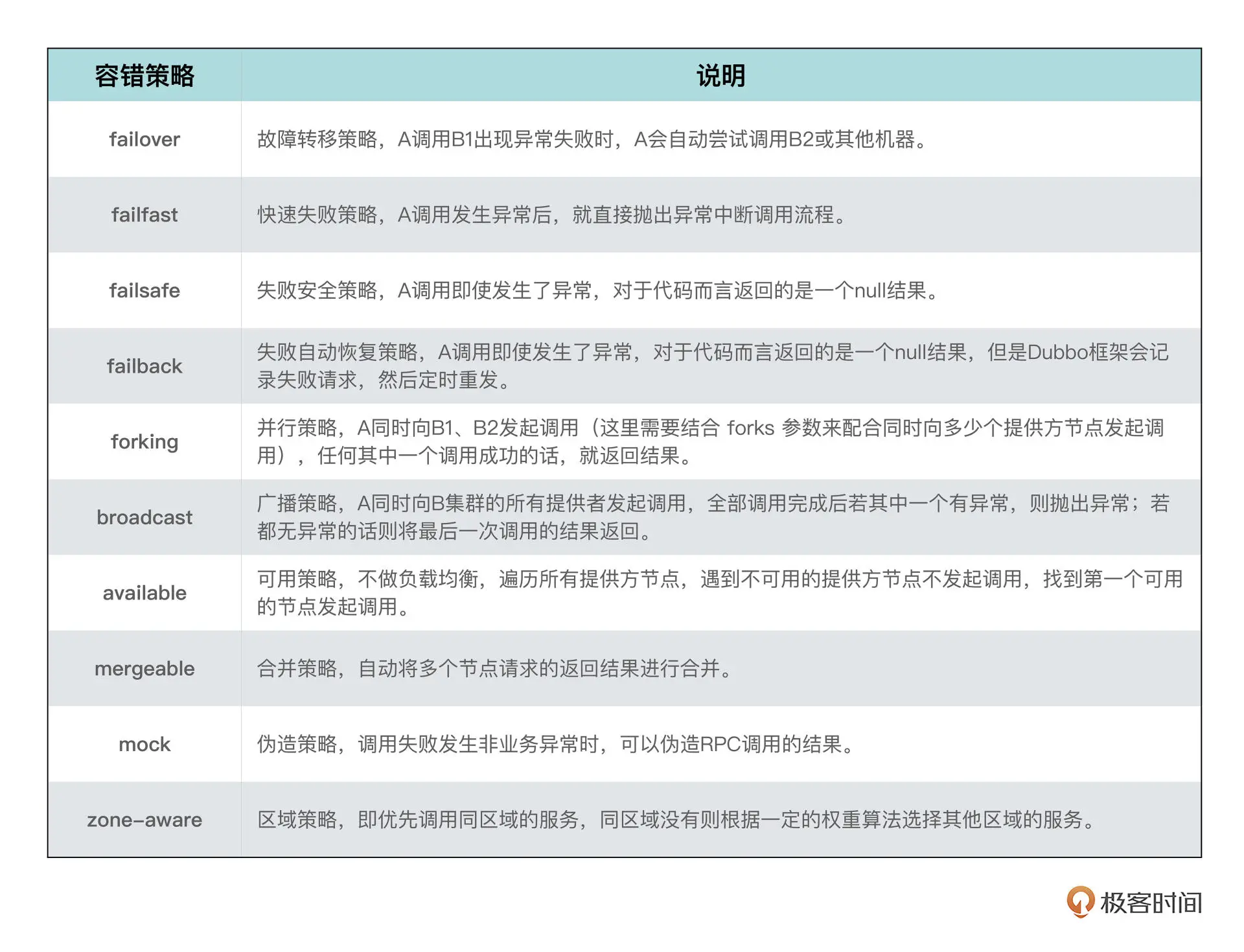
容错设置帮我们尽可能保障服务稳定调用,但调用也有流量高低之分,流量低的时候可能你发现不了什么特殊情况,一旦流量比较高,你可能会发现提供方总是有那么几台服务器流量特别高,另外几个服务器流量特别低。
这是因为Dubbo默认使用的是 loadbalance="random" 随机类型的负载均衡策略,为了尽可能雨露均沾调用到提供方各个节点,你可以继续设置 loadbalance="roundrobin" 来进行轮询调用,比如:
<!-- 引用远程服务 -->
<dubbo:reference id="demoFacade" loadbalance="roundrobin"
interface="com.hmilyylimh.cloud.facade.demo.DemoFacade">
</dubbo:reference>
你发现了吗,一个简单的远程RPC调用,我们在梳理的过程中联想到了各式各样的考量因素。感兴趣的话,你可以研究 dubbo:reference/、dubbo:method/ 这 2 个标签,能发现很多让你意想不到的有趣属性。
到这里调用就完成了,很多人会认为,当消费方能调用提供方就没其他角色什么事了。如果这样想,可就大错特错。我们继续看最后两个关键节点:Registry 注册中心、Monitor 监控中心。
4. Registry 注册中心
前面我们只是新增并注册了一个提供方,当我们逐渐增加节点的时候:
提供方节点在增加,/dubbo 和 /services 目录的信息也会随之增多,那消费方怎么知道提供方有新节点增加了呢?
这就需要注册中心出场了。注册中心之所以成为一个注册的集中地带,有着它不可或缺的责任。当服务新增或减少,其实,Dubbo默认的注册中心ZooKeeper有另外一层通知机制,也就是 第 ⑦ 步。
比如 DemoFacade 有新的提供方节点启动了,那么 /dubbo/com.hmilyylimh.cloud.facade.demo.DemoFacade/providers 目录下会留下新节点的 URL 痕迹,也就相当于 /dubbo/com.hmilyylimh.cloud.facade.demo.DemoFacade 目录节点有变更。
ZooKeeper 会将目录节点变更的事件通知给到消费方,然后消费方去 ZooKeeper 中拉取 DemoFacade 最新的所有提供方的节点信息放到消费方的本地,这样消费方就能自动感知新的提供方节点的存在了。
5. Monitor 监控中心
服务调用失败不可避免,当服务的调用成功或者失败时,机器本身或者使用功能的用户是能感知到的,那我们怎么在第一时间察觉某些服务是否出了问题了呢?
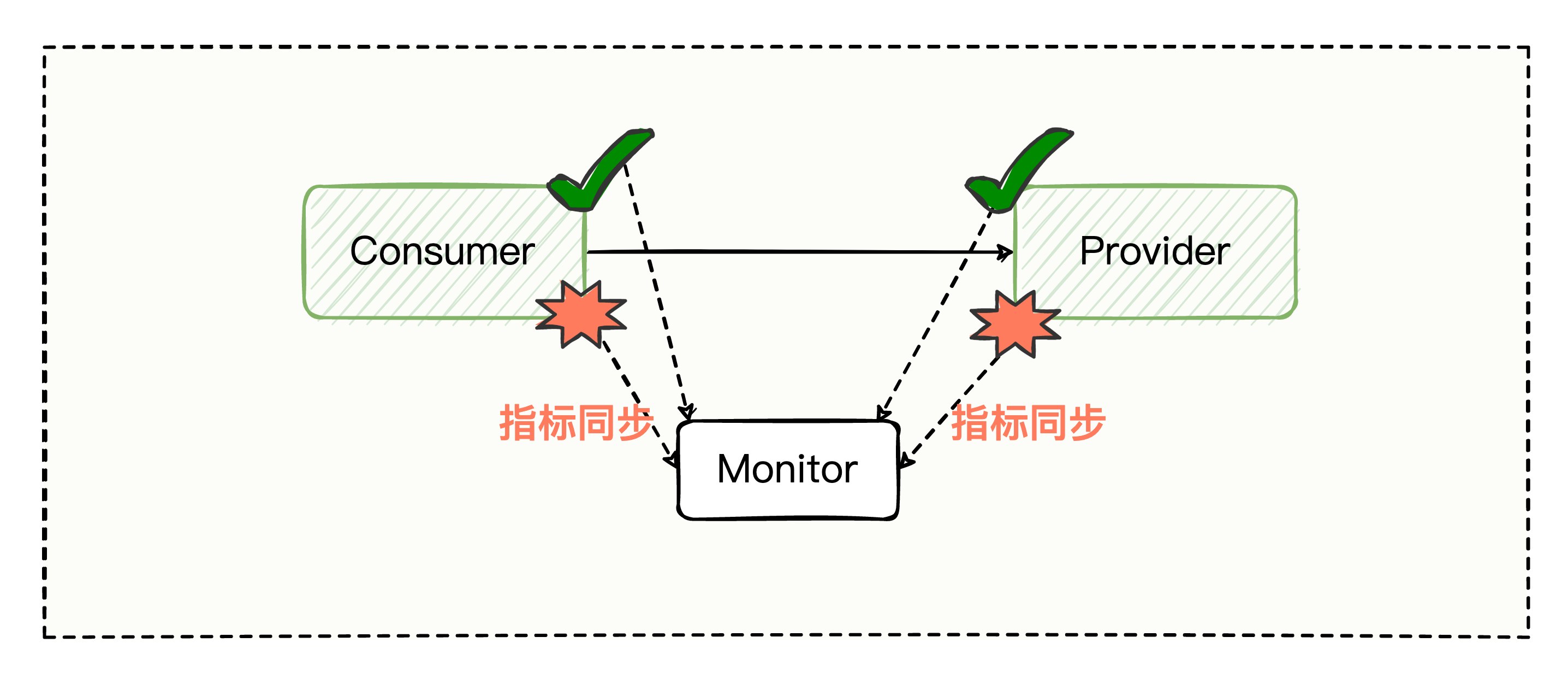
不管是提供方服务,还是消费方服务,如果在处理调用过程中发生了异常,可以将服务的调用成功数、失败数、服务调用的耗时时间上送给监控中心,也就是 第 ⑧⑨ 步。
这样一来,我们通过在监控中心设置不同的告警策略,就能在第一时间感知到一些异常问题的存在,争取在用户上报问题之前尽可能最快解决异常现象。
总结
我们通过新建一个Dubbo项目回顾了Dubbo的总体架构,主要有五个角色,Provider 暴露接口提供服务,Consumer 调用已暴露的接口,Registry 管理注册的服务与接口,Monitor 统计服务调用次数和调用时间,Container 为服务的稳定运行提供运行环境。
今天只是把各个环节涉及的基础知识点粗略过了一遍,如果你对每个环节的细节存有疑问,也不用担心,后面我们会深入学习。
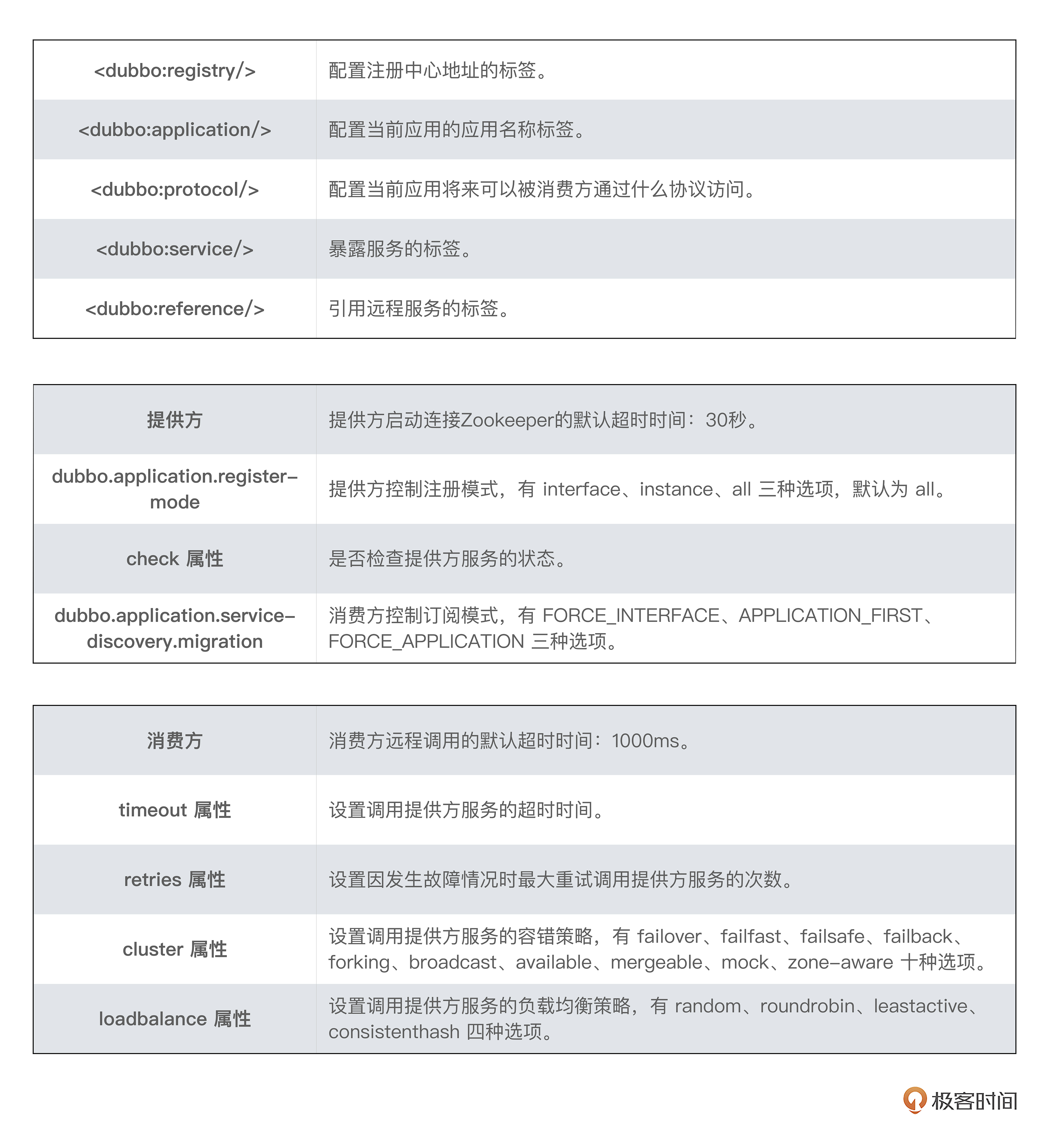
这里也总结一下今天涉及的基础知识点,你可以边看边回顾:
02|异步化实践:莫名其妙出现线程池耗尽怎么办?
今天我们来探索Dubbo框架的第一道特色风味,异步化实践。
Dubbo以前作为一个高性能的RPC框架,现在已然上升成为了一个微服务框架,但本质还是用来提供RPC服务的,这就势必存在同步调用和异步调用的方式。
同步调用方式比较简单直接,但我们也常常遇到因为调用量增加,原本不出幺蛾子的功能突然爆发问题的情况。比如:
关于 Socket 的 BIO 程序,随着调用量的增加,为什么用着用着就出现了一些性能问题呢?
某部分非常复杂又有点耗时的功能,测试环境验证得好好的,一放到有着高流量的产线运行,为什么莫名其妙就出现线程池耗尽问题呢?
这么说有点抽象,我们结合具体代码来看看。相信你肯定写过这样的代码:
@DubboService
@Component
public class AsyncOrderFacadeImpl implements AsyncOrderFacade {
@Override
public OrderInfo queryOrderById(String id) {
// 这里模拟执行一段耗时的业务逻辑
sleepInner(5000);
OrderInfo resultInfo = new OrderInfo(
"GeekDubbo",
"服务方异步方式之RpcContext.startAsync#" + id,
new BigDecimal(129));
return resultInfo;
}
}
这就是Dubbo服务提供方的一个普通的耗时功能服务,在 queryOrderById 中执行一段耗时的业务逻辑后,拿到 resultInfo 结果并返回。
但如果queryOrderById这个方法的调用量上来了,很容易导致Dubbo 线程池耗尽。
因为Dubbo 线程池总数默认是固定的,200个,假设系统在单位时间内可以处理500个请求,一旦queryOrderById 的请求流量上来了,极端情况下,可能会出现200个线程都在处理这个耗时的任务,那么剩下的300个请求,即使是不耗时的功能,也很难有机会拿到线程资源。所以,紧接着就导致Dubbo 线程池耗尽了。
为了让这种耗时的请求尽量不占用公共的线程池资源,我们就要开始琢磨异步了。
我们来尝试一下把这段代码优化成异步形式。
如何异步处理服务
你也许会说,这有什么难的,早在 Java 入门的时候我们就学过,通过 new Thread 并传入 Runnable 实现类可以实现异步处理。所以,这里直接把 queryOrderById 的逻辑全部包在 new Thread 的 run 方法中不就完事了么?
信心满满的你,可能会写出这样的代码:
@DubboService
@Component
public class AsyncOrderFacadeImpl implements AsyncOrderFacade {
@Override
public OrderInfo queryOrderById(String id) {
new Thread(new Runnable() {
@Override
public void run() {
// 这里模拟执行一段耗时的业务逻辑
sleepInner(5000);
OrderInfo resultInfo = new OrderInfo(
"GeekDubbo",
"服务方异步方式之RpcContext.startAsync#" + id,
new BigDecimal(129));
return resultInfo;
}
}).start();
return ???
}
}
修改的重点就是在 queryOrderById 中 new 了一个 Thread 并传入了 Runnable 内部类来处理。
不过这么修改后,你遇到了两个报红的地方,开始犯难了:
问题1:Thread 中 Runnable 的 run 方法,怎么把 resultInfo 结果返回给到 queryOrderById 方法的 OrderInfo 返回值呢?
问题2:new Thread 的 start 方法算是开启了异步,可是 start 方法一旦执行就好比开启了异步分支逻辑,最终的“ return ???”该返回什么呢?
问题2暂时还没有想到什么好的方式,但问题1倒是有思路了,我们都知道,创建线程的方式有 new Thread、Runnable、Callable 这么几种,既然 Runnable 无法返回结果对象,而 Callable 是支持有返回值的,那第一想法自然是换成 Callable,这下总可以可以把 resultInfo 返回了吧。
但你一旦决定要使用 Callable 的时候,按前面代码的写法是 要和 Thread 类结合使用的,所以紧接着我们就得问问 Thread 这个类是否答应,来看看 Thread 类的一些 API:
java.lang.Thread#Thread()
java.lang.Thread#Thread(java.lang.Runnable)
java.lang.Thread#Thread(java.lang.ThreadGroup, java.lang.Runnable)
java.lang.Thread#Thread(java.lang.String)
java.lang.Thread#Thread(java.lang.ThreadGroup, java.lang.String)
java.lang.Thread#Thread(java.lang.Runnable, java.lang.String)
java.lang.Thread#Thread(java.lang.ThreadGroup, java.lang.Runnable, java.lang.String)
java.lang.Thread#Thread(java.lang.ThreadGroup, java.lang.Runnable, java.lang.String, long)
java.lang.Thread#Thread(java.lang.ThreadGroup, java.lang.Runnable, java.lang.String, long, boolean)
java.lang.Thread#currentThread
java.lang.Thread#yield
java.lang.Thread#sleep(long)
java.lang.Thread#sleep(long, int)
java.lang.Thread#onSpinWait
java.lang.Thread#start
java.lang.Thread#run
java.lang.Thread#stop
java.lang.Thread#interrupt
java.lang.Thread#interrupted
java.lang.Thread#suspend
java.lang.Thread#resume
java.lang.Thread#activeCount
java.lang.Thread#enumerate
java.lang.Thread#countStackFrames
java.lang.Thread#join(long)
java.lang.Thread#join(long, int)
java.lang.Thread#join()
java.lang.Thread#dumpStack
java.lang.Thread#checkAccess
java.lang.Thread#toString
java.lang.Thread#holdsLock
从 Thread 的 API 列表中,可以发现 Thread 类自始至终都没有接收 Callable 类型的构造方法,那么,使用 Callable 这条路我们要彻底放弃了。
既然支持有返回值的Callable不可行,也找不到替换,是否可以尝试直接替换掉 new Thread 走异步的新方式呢?
其实除了显性地通过 new Thread 来处理异步的形式,还可以通过隐性的方式来处理异步形式。 一谈到隐性方式来处理异步,相信你也马上想到了——线程池,线程池就是妥妥的异步方式了,应该可以实现吧。
我们再来尝试一下改用线程池的实现逻辑方式:
@DubboService
@Component
public class AsyncOrderFacadeImpl implements AsyncOrderFacade {
@Override
public OrderInfo queryOrderById(String id) {
// 创建线程池对象
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
cachedThreadPool.execute(new Runnable() {
@Override
public void run() {
// 这里模拟执行一段耗时的业务逻辑
sleepInner(5000);
OrderInfo resultInfo = new OrderInfo(
"GeekDubbo",
"服务方异步方式之RpcContext.startAsync#" + id,
new BigDecimal(129));
System.out.println(resultInfo);
}
});
return ???;
}
} 这段代码在 queryOrderById 中创建了一个线程池,然后将 Runnable 内部类放到线程池中去执行。
但这么修改后,你发现还是遇到了之前类似的问题:
问题3:还是 Runnable 老问题,虽然放到了 cachedThreadPool 线程池中去执行了,但是这个 resultInfo 结果还是没有办法返回。
问题4:再次遇到了 cachedThreadPool.execute 方法一旦执行就好比开启了异步分支逻辑,那么最终的 “ return ???” 这个地方该返回什么呢?
我们还得继续想办法。
两种思路
现在遇到的核心问题是异步化的时候无法返回结果,怎么办?
之前我们一直沿着返回值这个方向思考,但已经选择了线程池的实现,如果能有一个存储媒介来存储异步化的结果,然后再想办法把存储媒介中的数据取出来返回回去,岂不是更好?
于是现在的思路就变成了: 在 queryOrderById 方法中开始异步化分支处理,紧接着在异步化分支中得到异步结果,然后把异步结果存储到某个地方,最后再看看谁可以取出这个异步结果并返回。
可是谁有这个能力可以感知到这个异步结果呢?我们仔细思考提供方接收请求的整个流程。

这里其实有两种方案,一种是看提供方的所有方法,在处理请求时有没有共同的必经之路,或者第二种也可以看在响应数据时有没有共同的API可以直接返回数据。我们就这两种思路仔细分析。
1. 处理请求时共同的必经之路
探索接收请求的整个流程,想找到必经之路,就相当于寻找一种可以拦截所有方法的流程机制,如果你能想到拦截,问题就好办了,在拦截处想办法拿到异步结果并返回就可以了,大致流程就像这样
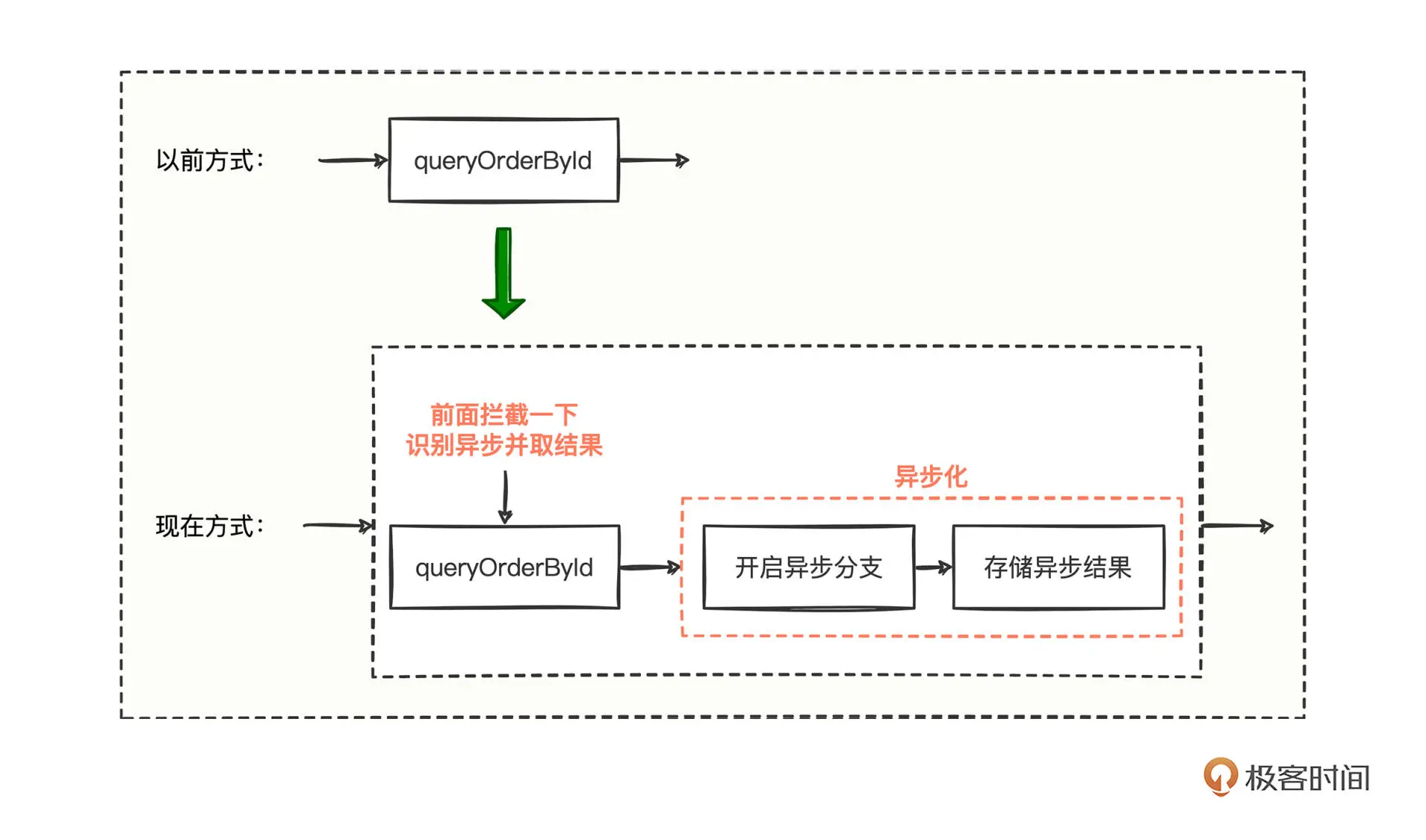
调用前后的形式有了明显变化,按照正常的调用思维,queryOrderById 的方法一定会被拦截到。但这里有个问题我们需要认真思考,能拦截到什么呢?
因为 queryOrderById 走了异步分支,可能导致最终什么也没拦截到,所以我们要让拦截处想办法感知到 queryOrderById 内部实现是否走了异步处理,从代码层面上, 就得引入一个变量,让拦截处一旦感知到业务接口(比如这里的queryOrderById) 开启了异步化模式处理,就可以理所当然地直接从存储异步结果的地方,把结果取回并返回。
这个思路看上去可行,我们接着看第二种思路,探索发送响应数据共同经历的API。
2. 响应数据时共同的API
既然数据要发送回去,就需要经过网络传输,那就一定与网络模块脱不了干系。Dubbo框架中的网络模块,默认是netty网络通信模块,所以只要想办法把数据通过netty发送回去,也是可以做到返回异步结果的。
兴奋的你构思出了大致流程:
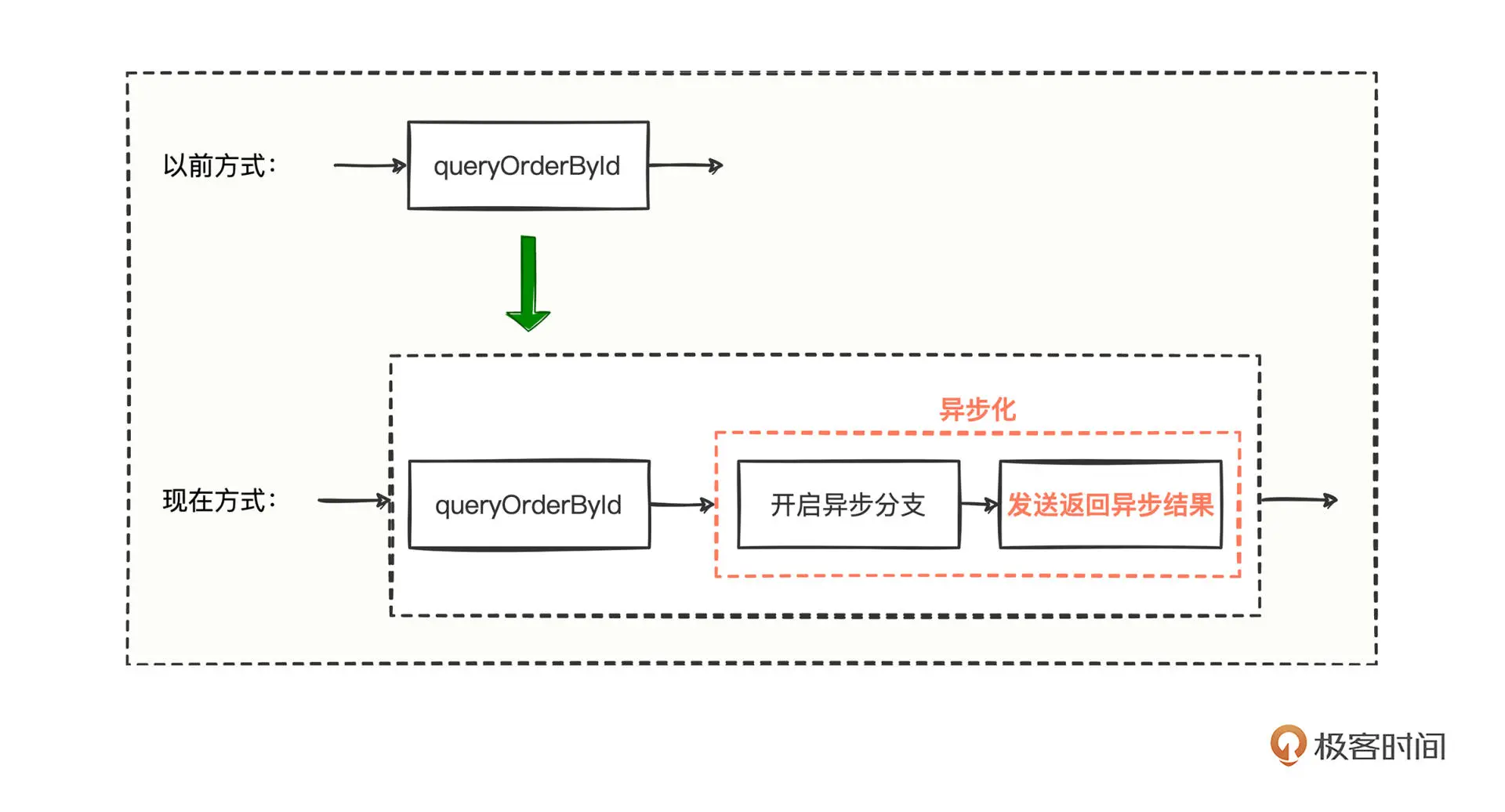
流程图变化不大,只是在异步化的地方,需要将异步化的结果直接发送返回给到调用方。其实有点像 BIO 程序,在ServerSocket#accept 方法返回值中得到 recvSocket 句柄,然后将该 recvSocket 句柄传入到异步化的逻辑中,待异步化逻辑处理完得到结果后,再调用 recvSocket 将结果写回去。
但是想拿到Dubbo中接收请求连接的 recvSocket 句柄对象,可不是一件简单的事情。毕竟Dubbo框架的存在就是为了帮你封装了一系列网络通信细节,可我们想拿通信句柄,岂不是和Dubbo框架对着干么?
其实所有框架都是一样的, 如果没有驾驭底层源码的强悍能力,最好还是不要试图干预框架底层去实现一些业务逻辑的操作;即使有能力,也得站在上帝视角审视一下, 你的改动是否符合框架的设计理念,不然很可能改得一团糟,花了大量时间,效果还不咋地。
所以这里我们直接干预Dubbo底层的通信句柄有点不太合适,第二种思路不可行,还是要转向第一种思路——拦截。
如何实现拦截并返回结果
对于拦截来说,首先我们要解决感知异步化模式处理的变量问题,而且这个变量还不能引发多线程问题。
因为这个变量和当前处理业务的线程息息相关,我们要么借助本地线程 ThreadLocal 来存储,要么借助处理业务的上下文对象来存储。
如果借助本地线程 ThreadLocal 来存储,又会遇到 queryOrderById 所在的线程与 cachedThreadPool 中的线程相互通信的问题。因为 ThreadLocal 存储的内容位于线程私有区域,从代码层面则体现在 java.lang.Thread#threadLocals 这个私有变量上,这也决定了,不同的线程,私有区域是无法相互访问的。
所以这里 采用上下文对象来存储,那异步化的结果也就毋庸置疑存储在上下文对象中。
好,我们再来顺一遍流程,首先拦截识别异步,当拦截处发现有异步化模式的变量,从上下文对象中取出异步化结果并返回。
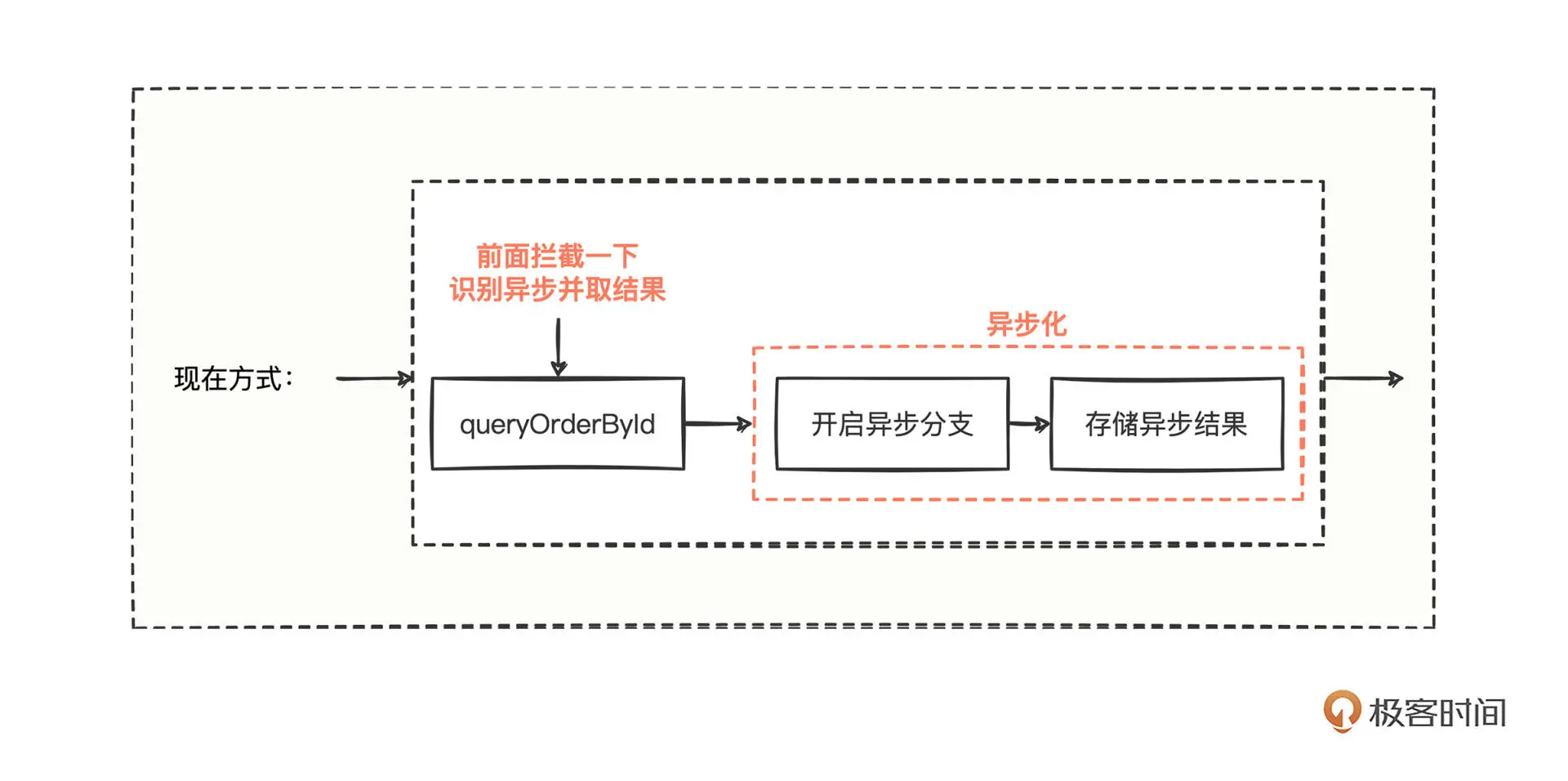
乍一看好像没什么问题,之前的问题1~4也都解决了。
但注意一点, 凡是异步问题,都需要考虑当前线程如何获取其他线程内数据,所以这里我们要思考:如果异步化处理有点耗时,拦截处从异步化结果中取不到结果该怎么办呢?不停轮询等待吗?还是要作何处理呢?
这个问题抽象一下其实就是:A线程执行到某个环节,需要B线程的执行结果,但是B线程还未执行完,A线程是如何应对的?所以,本质回归到了多线程通信上。
要实现线程间的通信,想必你能说出一堆方案来,但是我们这里关注尽可能用较少的代码使A线程拿到B线程的结果,B线程需要执行的时间可长可短,但有个度。所以问题就变成了:A线程在一定时间内获取B线程的结果,指定时间内拿到结果则万事大吉,否则该抛错还是得抛错。
那么现在就需要你思考了: JDK 并发相关的所有类,哪个是可以在多线程中充当存储媒介而且还支持一定时间内返回结果的?
相信熟悉 JDK 的你已经想到了,非 java.util.concurrent.Future 莫属,这是 Java 1.5 引入的用于异步结果的获取,当异步执行结束之后,结果将会保存在 Future 当中。
但 java.util.concurrent.Future 是一个接口,我们得找一个它的实现类来用,也就是 java.util.concurrent.CompletableFuture,而且它的 java.util.concurrent.CompletableFuture#get(long timeout, TimeUnit unit) 方法支持传入超时时间,也正好适合我们的场景。
到这里,我们把遇到的问题都解决了,接下来就一起来看看该如何改造 queryOrderById 这个方法:
@DubboService
@Component
public class AsyncOrderFacadeImpl implements AsyncOrderFacade {
@Override
public OrderInfo queryOrderById(String id) {
// 创建线程池对象
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
// 开启异步化操作模式,标识异步化模式开始
AsyncContext asyncContext = RpcContext.startAsync();
// 利用线程池来处理 queryOrderById 的核心业务逻辑
cachedThreadPool.execute(new Runnable() {
@Override
public void run() {
// 将 queryOrderById 所在线程的上下文信息同步到该子线程中
asyncContext.signalContextSwitch();
// 这里模拟执行一段耗时的业务逻辑
sleepInner(5000);
OrderInfo resultInfo = new OrderInfo(
"GeekDubbo",
"服务方异步方式之RpcContext.startAsync#" + id,
new BigDecimal(129));
System.out.println(resultInfo);
// 利用 asyncContext 将 resultInfo 返回回去
asyncContext.write(resultInfo);
}
});
return null;
}
}
我们在 queryOrderById 中创建了一个线程池,然后把 Runnable 内部类放到线程池中去执行,并且存在一个上下文信息的传递动作,最后在 Runnable 实现类中,将异步结果写入到上下文对象。
核心实现就3点:
定义线程池对象,通过 RpcContext.startAsync 方法开启异步模式;
在异步线程中通过 asyncContext.signalContextSwitch 同步父线程的上下文信息;
在异步线程中将异步结果通过 asyncContext.write 写入到异步线程的上下文信息中。
我们最终实现的代码看似简单,如果研究其中的技术实现细节,现在你一定能发现别有一番风味。
这就是设计方式的问题,有的框架在设计功能时,呈现的形式是那么地讨人喜欢。 就像平时我们调用别人优秀开源框架的一个方法,你发现这个方法有个可选参数支持你传入一个 Executor 或 ExecutorService 对象,恰好能满足需求,你是不是会疑惑为什么别人要这么设计。
接下来就让我们来看看,Dubbo这个优秀框架,在源码层面是怎么实现异步的,和我们的思路异同点在哪里。
Dubbo异步实现原理
首先,还是定义线程池对象,在Dubbo中 RpcContext.startAsync 方法意味着异步模式的开启:
我们追踪源码的调用流程,可以发现最终是通过 CAS 原子性的方式创建了一个 java.util.concurrent.CompletableFuture 对象,这个对象就存储在当前的上下文 org.apache.dubbo.rpc.RpcContextAttachment 对象中。
然后,需要在异步线程中同步父线程的上下文信息:
 可以看到,Dubbo 框架,也是用的 asyncContext.signalContextSwitch 同步不同线程间的信息,也就是信息的拷贝,只不过这个拷贝需要利用到异步模式开启之后的返回对象 asyncContext。
可以看到,Dubbo 框架,也是用的 asyncContext.signalContextSwitch 同步不同线程间的信息,也就是信息的拷贝,只不过这个拷贝需要利用到异步模式开启之后的返回对象 asyncContext。
因为 asyncContext 富含上下文信息, 只需要把这个所谓的 asyncContext 对象传入到子线程中,然后将 asyncContext 中的上下文信息充分拷贝到子线程中,这样,子线程处理所需要的任何信息就不会因为开启了异步化处理而缺失。
最后的第三步就是在异步线程中,将异步结果写入到异步线程的上下文信息中:
// org.apache.dubbo.rpc.AsyncContextImpl#write
public void write(Object value) {
if (isAsyncStarted() && stop()) {
if (value instanceof Throwable) {
Throwable bizExe = (Throwable) value;
future.completeExceptionally(bizExe);
} else {
future.complete(value);
}
} else {
throw new IllegalStateException("The async response has probably been wrote back by another thread, or the asyncContext has been closed.");
}
}
Dubbo 用 asyncContext.write 写入异步结果,通过 write 方法的查看,最终我们的异步化结果是存入了 java.util.concurrent.CompletableFuture 对象中,这样拦截处只需要调用 java.util.concurrent.CompletableFuture#get(long timeout, TimeUnit unit) 方法就可以很轻松地拿到异步化结果了。
异步应用场景
Dubbo 的异步实现原理,相信你已经非常清楚了,那哪些应用场景可以考虑异步呢?我们还是结合源码思考。
第一,我们定义了线程池,你可能会认为定义线程池的目的就是为了异步化操作,其实不是,因为异步化的操作会使 queryOrderById 方法立马返回,也就是说,异步化耗时的操作并没有在 queryOrderById 方法所在线程中继续占用资源,而是在新开辟的线程池中占用资源。
所以 对于一些IO耗时的操作,比较影响客户体验和使用性能的一些地方,我们是可以采用异步处理的。
其次,因为 queryOrderById 开启异步操作后就立马返回了,queryOrderById 所在的线程和异步线程没有太多瓜葛,异步线程的完成与否,不太影响 queryOrderById 的返回操作。
所以, 若某段业务逻辑开启异步执行后不太影响主线程的原有业务逻辑,也是可以考虑采取异步处理的。
最后,在 queryOrderById 这段简单的逻辑中,只开启了一个异步化的操作,站在时序的角度上看,queryOrderById 方法返回了,但是异步化的逻辑还在慢慢执行着,完全对时序的先后顺序没有严格要求。所以, 时序上没有严格要求的业务逻辑,也是可以采用异步处理的。
总结
今天,我们从一段普通的提供方代码开始,分析遇到调用量暴涨后,如何进行异步化改造,以避免Dubbo线程池耗尽。改造核心有三要素:开启异步模式、衔接上下文信息、将结果写入到上下文中。
Dubbo的实现思路是,首先通过 RpcContext.startAsync 方法定义线程池对象开启异步模式;然后在异步线程中,通过 asyncContext.signalContextSwitch 同步父线程的上下文信息;最后将异步结果通过 asyncContext.write 写入到异步线程的上下文信息中,而存储异步结果的核心关键类是CompletableFuture。
异步的应用场景主要有3类:IO耗时、无业务牵连、无时序要求。
思考题
你已经学会了如何进行异步化改造,也了解了异步改造的核心重要类 CompletableFuture, 在这个核心类中还有很多好用的异步调用方法,为了帮助你深入理解,我设计了一道有趣的多任务场景题:
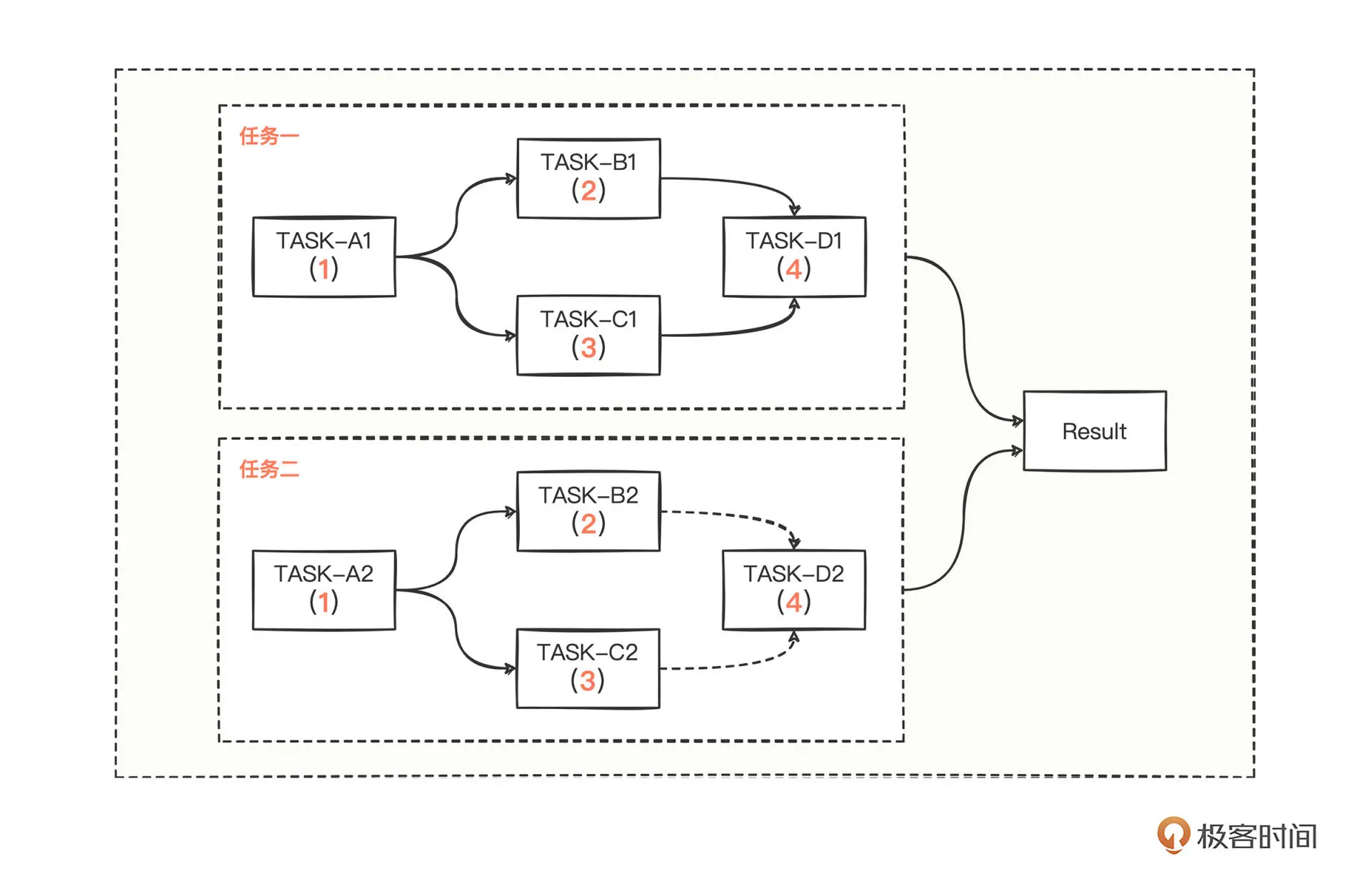
任务一:执行任务 TASK-A1,然后并发执行任务 TASK-B1、TASK-C1,再异步执行 TASK-D1;
任务二:执行任务 TASK-A2,然后并发执行任务 TASK-B2、TASK-C2,但是 TASK-B2、TASK-C2 中任意一个完成后,再异步执行 TASK-D2;
当两个任务完成之后,再执行 Result 得到最终结果,任务总超时时间设置为5s,超时则返回0。图中每个任务中的红色数字代表着每个任务的数值,请你针对图中的多任务复杂场景,充分利用 CompletableFuture 中的一些 API 编写出代码,并打印出最终的累加和。
期待看到你的思考,如果你对dubbo的异步化实践还有什么困惑,欢迎在留言区提问,我会第一时间回复。
如果觉得今天的内容对你有帮助,也欢迎分享给身边的朋友一起讨论。我们下一讲见。