KahaDB 是 Apache ActiveMQ 默认的消息存储机制,它是一个高性能、事务性的消息存储解决方案。KahaDB 旨在提供比以前的存储机制(如 AMQ Message Store 或者 JDBC 持久化)更好的性能和稳定性。下面是 KahaDB 的一些关键特性和工作原理:
KahaDB 特性
高效率:KahaDB 设计为高效的日志结构存储系统,适合大量写入操作。
持久性:所有数据都持久化到磁盘上,确保即使在服务器崩溃后也能恢复数据。
事务支持:支持 JMS 事务,确保消息的一致性和可靠性。
索引:使用 B-Tree 索引来快速定位消息。
易于备份:可以很容易地进行文件级别的备份。
低延迟:通过缓存频繁访问的数据来减少磁盘 I/O。
存储结构
KahaDB 将数据组织成一系列的日志文件(log files),每个文件都是固定大小的。当一个日志文件被填满时,一个新的日志文件会被创建。这些日志文件包含实际的消息内容以及相关的元数据信息。此外,还有一个索引文件用于快速查找特定的消息。
日志文件
日志文件保存了所有的消息记录。
每个日志文件都有一个唯一的序列号。
日志文件是循环使用的,旧的日志文件在没有未完成事务的情况下会被删除以释放空间。
索引文件
索引文件维护了一个从消息ID到其在日志文件中位置的映射。
这使得消息能够迅速地被检索出来。
配置选项
KahaDB 提供了一些配置选项来调整其行为,以适应不同的需求。以下是一些常用的配置参数:
directory:指定 KahaDB 数据文件存放的目录。maxLogSize:设置单个日志文件的最大大小,默认通常是 32MB。checkpointInterval:定义检查点之间的间隔时间或消息数量。检查点用于将内存中的状态刷新到磁盘。cleanupInterval:清理过期文件的时间间隔。enableIndex:是否启用索引功能,默认是启用的。indexWriteBatchSize:索引写入批处理大小,用于优化索引写入性能。
示例配置
在 activemq.xml 中,可以通过如下方式配置 KahaDB:
<persistenceAdapter>
<kahaDB directory="${activemq.data}/kahadb" />
</persistenceAdapter>如果你想要自定义更多的配置项,可以这样做:
<persistenceAdapter>
<kahaDB directory="${activemq.data}/kahadb"
maxLogSize="32 mb"
checkpointInterval="5000"
cleanupInterval="30000"
enableIndex="true"
indexWriteBatchSize="1000"/>
</persistenceAdapter>性能调优
日志文件大小:适当增大
maxLogSize可以减少日志文件的数量,从而降低文件切换带来的开销。检查点频率:合理设置
checkpointInterval以平衡内存使用与磁盘I/O之间的关系。索引策略:根据实际情况决定是否需要开启索引,如果不需要快速查找消息,则可以考虑关闭索引来提高写入性能。
通过以上配置和调优,可以更好地利用 KahaDB 来满足不同应用场景下的性能和可靠性要求。如果您有更具体的场景或者遇到特定的问题,请告诉我,我可以提供更加针对性的建议。
KahaDB 简介
KahaDB 是 ActiveMQ 默认的持久化存储方式。它是一种基于文件的存储机制,具有高性能和可靠性的特点。它的设计目标是提供高效的消息存储和检索,适用于各种消息传递场景。
它将消息存储在磁盘上的文件中,通过日志文件和索引文件来管理消息。这种存储方式能够在保证消息持久化的同时,提供较快的读写速度。
存储结构
数据文件:
KahaDB 主要的数据文件是日志文件(通常以
.log为扩展名)。消息在被生产者发送到 ActiveMQ 后,会按照顺序写入这些日志文件中。每个日志文件有一定的大小限制,当达到这个限制时,会创建新的日志文件。例如,默认情况下,日志文件大小为 32MB。这些日志文件采用顺序写入的方式,这使得写入操作非常高效。就像在一本日记本上按顺序记录信息一样,新的消息会依次添加到日志文件的末尾。
索引文件:
为了能够快速地查找消息,KahaDB 使用索引文件(通常以
.idx为扩展名)。索引文件记录了消息在日志文件中的位置等关键信息。当需要检索消息时,ActiveMQ 会首先查询索引文件,然后根据索引找到对应的日志文件位置,从而快速获取消息。例如,索引文件就像是一本书的目录,通过目录可以快速定位到书中具体内容的页码,在 KahaDB 中就是定位消息在日志文件中的位置。
事务支持
KahaDB 支持事务操作。当生产者发送一批消息作为一个事务时,这些消息在写入日志文件的过程中会遵循事务的规则。如果事务提交成功,消息会被持久化存储;如果事务回滚,已经写入日志文件的消息(在未提交状态下)会被撤销。
例如,在一个金融交易系统中,银行转账操作可能涉及多个消息(如从一个账户扣除金额,向另一个账户添加金额)。这些消息可以作为一个事务发送到 ActiveMQ,使用 KahaDB 存储。如果转账过程中出现问题,事务回滚,KahaDB 会确保消息不会被错误地持久化,保证数据的一致性。
恢复机制
在系统故障或 ActiveMQ 重启后,KahaDB 具有良好的恢复机制。它会根据日志文件和索引文件来恢复消息队列的状态。在恢复过程中,会检查日志文件中未完成的事务等情况,将消息队列恢复到一个一致的状态。
比如,如果系统突然断电,ActiveMQ 重新启动后,KahaDB 会重新读取日志文件和索引文件,将消息重新加载到内存中的消息队列,确保消息不会丢失,并且消息的顺序和之前保持一致。
性能优化
缓存机制:KahaDB 可以利用操作系统的缓存来提高性能。当频繁访问某些消息时,这些消息可能会被缓存在操作系统的内存中,下次访问时可以直接从缓存中获取,减少磁盘 I/O 操作。
日志文件大小调整:合理调整日志文件的大小也可以优化性能。如果日志文件过小,会导致频繁创建新的日志文件,增加文件管理的开销;如果日志文件过大,在恢复等操作时可能会花费更多的时间。需要根据实际的消息流量等情况来设置合适的日志文件大小。
一、KahaDB 存储方式的优缺点
(一)优点
高性能
基于文件的顺序写入方式使 KahaDB 在消息存储时有出色的性能。因为顺序写入磁盘在大多数情况下比随机写入快得多,它减少了磁盘磁头的寻道时间。例如,在一个高并发消息发送的场景下,消息能够快速地被写入到日志文件中,像一条流水线上的产品依次被放置到存储仓库一样高效。
它还利用了操作系统的缓存机制来提高读取性能。当消息被频繁访问时,操作系统会将这些消息缓存到内存中,下次读取时就可以直接从内存中获取,减少了磁盘 I/O 操作,从而提高了整体性能。
可靠性高
KahaDB 支持事务处理,能够确保消息在发送过程中的一致性。例如,在一个包含多个消息的复杂业务流程中,如电商系统中的订单处理流程,包括下单、库存扣减、支付等多个消息,如果这些消息作为一个事务发送,KahaDB 可以保证它们要么全部成功存储(事务提交),要么全部不存储(事务回滚),有效防止数据不一致的情况。
它的恢复机制强大,在系统故障或 ActiveMQ 重启后,能根据日志文件和索引文件完整地恢复消息队列的状态。即使遇到突然断电等意外情况,重新启动 ActiveMQ 后,消息也不会丢失,并且消息的顺序和之前保持一致,就像有一个自动备份和恢复的安全网一样保障消息的完整性。
易于管理和维护
作为基于文件的存储方式,它的存储结构相对简单。数据文件(日志文件)和索引文件的组织方式直观,便于理解。例如,管理员可以直接查看磁盘上的日志文件大小、数量等信息来了解存储状态。
与一些复杂的数据库存储方式相比,不需要复杂的数据库管理知识和操作,降低了管理成本。
(二)缺点
扩展性有限
随着消息数据量的不断增大,尤其是在处理海量消息的场景下,基于文件的 KahaDB 可能会遇到性能瓶颈。例如,当存储的消息数量达到一定规模后,文件系统的性能可能会下降,索引文件的查找效率也可能会降低,因为文件数量过多会增加文件系统的负担。
它在分布式环境下的扩展性不如一些专门的分布式存储系统。如果需要构建大规模的分布式消息队列系统,KahaDB 可能无法满足横向扩展的需求。
缺乏高级查询功能
KahaDB 主要是为了高效的消息存储和检索而设计,它的查询功能相对简单。与数据库系统相比,它不能像 SQL 数据库那样支持复杂的查询条件和聚合操作。例如,很难对存储的消息内容进行复杂的筛选,如按照消息中的多个字段进行联合查询等操作。
二、优化 KahaDB 性能的方法
合理调整日志文件大小
根据消息流量和存储硬件的性能来设置日志文件大小。如果消息产生速度较快,且磁盘 I/O 性能较好,可以适当增大日志文件大小。例如,默认日志文件大小是 32MB,可以根据实际情况调整到 64MB 或 128MB 等。但要注意,过大的日志文件在恢复操作时可能会花费更多时间。
优化操作系统缓存
确保操作系统有足够的内存用于缓存 KahaDB 的数据。可以通过调整操作系统的内存管理参数来实现。例如,在 Linux 系统中,可以调整
swappiness参数来控制内存交换的频率,减少不必要的磁盘交换操作,提高缓存性能。
定期清理过期消息
对于一些有过期时间限制的消息,如消息队列中的临时通知消息等,应该及时清理。可以通过设置 ActiveMQ 的消息过期策略,定期删除过期的日志文件和相关索引,减少存储占用,提高存储效率。
使用更快的存储设备
考虑将 KahaDB 存储在高速磁盘或固态硬盘(SSD)上。SSD 相比传统机械硬盘具有更快的读写速度,能够显著提高 KahaDB 的性能,尤其是在磁盘 I/O 密集型的场景下。
三、ActiveMQ 支持的其他持久化存储方式
AMQ 消息存储
这是 ActiveMQ 早期的一种存储方式。它将消息存储在基于文件的数据库中,这种存储方式在存储结构上比较简单。但与 KahaDB 相比,它的性能和灵活性稍差。例如,它在处理大量并发消息存储和检索时可能会出现性能问题,并且在恢复机制等方面也不如 KahaDB 完善。
JDBC 存储
ActiveMQ 支持通过 JDBC 将消息存储到关系数据库中,如 MySQL、Oracle 等。这种方式的优点是可以利用数据库的强大功能,如事务处理、复杂查询和备份恢复等。例如,在一些对数据一致性和完整性要求极高的企业级应用中,可以将消息存储在 Oracle 数据库中,利用 Oracle 的高级事务管理和数据安全机制。
不过,它的性能可能会受到数据库性能的限制。由于关系数据库的写入操作相对复杂,可能会比 KahaDB 等基于文件的存储方式慢,尤其是在高并发消息写入场景下。同时,还需要配置和维护相应的数据库环境。
KahaDB 存储方式的优缺点
优点:
高性能:KahaDB 专为高吞吐量设计,特别是对于写入密集型的应用程序。它通过使用日志结构存储和内存映射文件来提高性能。
可靠性:支持事务处理,确保消息的一致性和完整性。
易于管理:基于文件的日志结构使得备份和恢复操作相对简单。
低延迟:通过缓存机制减少磁盘 I/O,从而降低访问延迟。
自动清理:能够自动删除过期或不再需要的数据文件。
缺点:
空间占用:随着时间的推移,如果不定期进行维护(如压缩),KahaDB 可能会占用大量的磁盘空间。
恢复时间:在服务器崩溃后重新启动时,恢复过程可能会比较慢,特别是在有大量未提交事务的情况下。
扩展性限制:虽然适合单节点部署,但当数据量极大或者需要跨多个节点分布时,KahaDB 的扩展性不如某些分布式存储方案。
如何优化 KahaDB 的性能
调整日志文件大小:
增大
maxLogSize参数可以减少文件切换频率,但也会增加单个文件的大小。找到一个平衡点是关键。
合理设置检查点间隔:
checkpointInterval控制着何时将内存中的状态刷新到磁盘上。频繁的检查点会增加磁盘 I/O,而过于稀疏则可能导致更多的数据丢失风险。
索引策略:
根据应用需求决定是否启用索引。如果不需要快速查找消息,则可以考虑关闭索引来提高写入性能。
定期维护:
定期运行
compact操作以合并日志文件并释放空间。使用
cleanup来清除过期或无用的数据。
硬件优化:
使用高速 SSD 而不是传统的 HDD 来加快 I/O 速度。
确保有足够的内存用于缓存和减少磁盘访问。
配置 JVM 参数:
优化 JVM 的堆内存设置,避免因垃圾回收导致的停顿。
启用 G1 GC 或 ZGC 等现代垃圾收集器以提高性能。
ActiveMQ 支持的其他持久化存储方式
除了 KahaDB 之外,ActiveMQ 还支持以下几种持久化存储方式:
AMQ Message Store:这是早期版本中默认的消息存储机制,现已不推荐使用,因为它的性能和可维护性都不如 KahaDB。
JDBC Persistence Adapter:通过 JDBC 访问关系数据库(如 MySQL, PostgreSQL)来存储消息。这种方式提供了强大的查询能力和灵活性,但可能引入额外的延迟。
LevelDB Store:基于 Google 的 LevelDB 键值存储引擎,适用于需要快速读写的场景。
Memory Persistence Adapter:所有消息都保存在内存中,这提供了非常高的读写速度,但一旦服务重启,所有未被消费的消息都会丢失。
Journal Persistence Adapter:类似于 KahaDB,但是更老的一种日志式存储方式。
Replicated LevelDB Store:结合了 LevelDB 和复制技术,可以在多台机器之间同步消息,提供高可用性。
选择哪种持久化方式取决于您的具体需求,包括对性能、可靠性和易管理性的考量。例如,如果您需要高度可靠的持久化存储,并且可以接受稍慢一点的性能,那么 JDBC 存储适配器可能是合适的选择;如果您追求极致的性能并且可以容忍偶尔的数据丢失,则可以考虑使用内存持久化适配器。
kahaDB
kahaDB是一个基于文件,支持事务的、可靠,高性能,可扩展的消息存储器,目前是activeMQ默认的持久化方式,配置也十分简单
<persistenceAdapter><kahaDB directory="${activemq.data}/kahadb"/></persistenceAdapter>以上配置是将存储目录设置为${activemq.data}/kahadb。
存储目录下文件说明:
db.data:索引文件,本质上是BTree的实现,存储到了db-*.log消息文件的索引。db.redo:用来进行数据恢复的redo文件db-*.log:存储消息内容的文件,包括消息元数据、订阅关系、事务等数据。lock:表示已启动一个实例。
kahaDB配置支持的参数:
底层实现
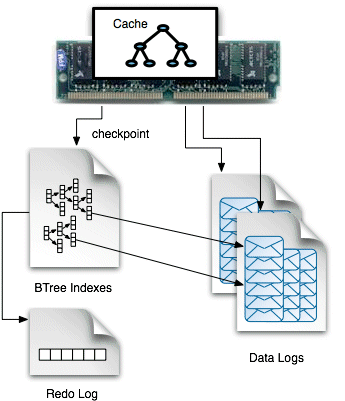
从上图中可以看出:图中各个部分与KahaDB配置的存储目录下的文件是一 一对应的。
①在内存(cache)中的那部分B-Tree是Metadata Cache
通过将索引缓存到内存中,可以加快查询的速度(quick retrival of message data)。但是需要定时将 Metadata Cache 与 Metadata Store同步。
这个同步过程就称为:check point。由checkpointInterval选项 决定每隔多久时间进行一次checkpoint操作。
②BTree Indexes则是保存在磁盘上的,称为Metadata Store,它对应于文件db.data,它就是对Data Logs以B树的形式 索引。有了它,Broker(消息服务器)可以快速地重启恢复,因为它是消息的索引,根据它就能恢复出每条消息的location。
如果Metadata Store被损坏,则只能扫描整个Data Logs来重建B树了,这个过程是很复杂且缓慢的。
③Data Logs则对应于文件 db-*.log,默认是32MB
Data Logs以日志形式存储消息,它是生产者生产的数据的真正载体。
The data logs are used to store data in the form of journals,
where events of all kinds—messages, acknowledgments, subscriptions, subscription cancellations, transaction boundaries, etc.
---are stored in a rolling log④Redo Log则对应于文件 db.redo
redo log的原理用到了“Double Write”。关于“Double Write”可参考
简要记录下自己的理解:因为磁盘的页大小与操作系统的页大小不一样,磁盘的页大小一般是16KB,而OS的页大小是4KB。而数据写入磁盘是以磁盘页大小为单位进行的,即一次写一个磁盘页大小,这就需要4个OS的页大小(4*4=16)。如果在写入过程中出现故障(突然断电)就会导致只写入了一部分数据(partial page write)
而采用了“Double Write”之后,将数据写入磁盘时,先写到一个Recovery Buffer中,然后再写到真正的目的文件中。在ActiveMQ的源码PageFile.java中有相应的实现。
扩展知识:Linux中的日志文件系统:因为Linux的 ext文件系统采用索引节点来存储文件的元数据,每次数据写入磁盘之后,需要更新索引节点表。而写入磁盘与更新索引节点表并不是“原子操作”,比如,在数据写入磁盘后,系统发生故障,之前写入的数据就再也找不到了。
因此,日志文件系统给Linux系统增加了一层安全性:数据写入存储设备之前,先将数据(或者只将索引节点信息写日志)写入到临时文件中,该临时文件称日志。如果在数据写入时发生故障,还可以通过日志来进行一定的恢复。
您提到的日志文件系统(Journaling File System)在 Linux 中确实提供了一种机制来提高数据的一致性和可靠性。这种机制通过记录文件系统的更改操作,确保即使在系统崩溃后也能恢复到一致的状态。下面是关于日志文件系统的一些扩展知识:
日志文件系统的工作原理
日志记录:
在进行任何文件系统修改之前,先将这些修改的操作记录在一个称为“日志”(journal)的特殊区域。
日志中记录了即将对文件系统进行的更改,包括元数据和实际数据。
写入数据:
实际的数据写入操作会在日志记录之后进行。
如果写入过程中发生故障(如断电),可以通过日志中的记录来恢复未完成的操作。
提交事务:
一旦数据成功写入磁盘,相关的日志条目会被标记为已提交。
如果系统崩溃,重启时会检查日志,根据未提交的日志条目回滚或重做操作,以确保文件系统的一致性。
常见的日志文件系统
ext3:
是 ext2 文件系统的扩展版本,增加了日志功能。
提供了三种日志模式:
journal,ordered, 和writeback。journal模式下,所有数据和元数据都记录在日志中,提供最高级别的数据一致性。ordered模式下,仅元数据记录在日志中,但保证数据在元数据更新前写入磁盘。writeback模式下,仅元数据记录在日志中,不保证数据的顺序写入。
ext4:
是 ext3 的进一步改进版本,提供了更好的性能和更多的特性。
支持更大的文件系统和更大的文件大小。
引入了延迟分配、多块分配等技术,提高了性能。
XFS:
是一种高性能的日志文件系统,最初由 SGI 开发。
设计用于处理大文件和高并发访问。
提供了快速的恢复时间,因为其日志结构允许并行回放日志条目。
JFS (Journaled File System):
由 IBM 开发,设计用于大型服务器环境。
提供了高度可靠的数据完整性保障。
支持动态扩展文件系统大小而不中断服务。
Btrfs (B-tree File System):
是一种较新的日志文件系统,旨在替代 ext4。
提供了许多高级特性,如快照、在线碎片整理、透明压缩等。
使用 B-tree 结构来管理元数据,支持高效的数据管理和查询。
日志文件系统的优势
数据一致性:确保在系统崩溃后,文件系统能够恢复到一致的状态。
快速恢复:通过日志回放,可以在短时间内恢复文件系统。
减少 fsck 时间:传统的非日志文件系统在崩溃后需要运行
fsck来检查和修复文件系统,而日志文件系统可以大大减少这个过程的时间。
总结
日志文件系统通过引入日志机制,显著提高了 Linux 系统的数据一致性和可靠性。不同的日志文件系统各有特点,可以根据具体的应用需求选择合适的文件系统。例如,对于需要高性能和大文件处理的场景,XFS 是一个不错的选择;而对于需要高级特性和灵活管理的场景,Btrfs 可能更合适。理解这些文件系统的特性和工作原理有助于更好地配置和优化您的 Linux 系统。
ext3 文件系统
概述:
ext3 是 ext2 文件系统的扩展版本,它最大的改进就是加入了日志功能。这种日志功能使得文件系统在面对意外情况(如系统突然断电、软件崩溃等)时,能够更好地保证数据的完整性和一致性。
日志模式:
journal 模式:
在这种模式下,所有的数据和元数据在修改之前都会被完整地记录在日志中。这就相当于在进行每一个文件系统操作之前,都详细地记录下了 “操作计划” 和 “操作涉及的数据内容”。例如,当你要修改一个文件的内容并且更新它的元数据(如文件大小、修改时间等)时,这些信息都会先记录在日志里。这种模式提供了最高级别的数据一致性保障。因为无论是数据本身还是关于数据的描述信息都有记录,所以在系统崩溃后恢复时,可以根据日志准确地还原所有操作,就像按照详细的施工图纸重建建筑一样。
ordered 模式:
此模式下仅将元数据记录在日志中,但有一个重要的保证,那就是数据在元数据更新之前会被写入磁盘。这是一种在性能和数据一致性之间的平衡。比如,当创建一个新文件时,文件的数据会先写入磁盘,然后才会在日志中记录这个文件的元数据(如文件名、权限等)更新情况。这种方式可以在一定程度上减少日志记录的数据量,提高系统的性能,同时也能保证数据和元数据之间的顺序关系,使得文件系统在恢复时能够根据数据的实际写入情况和元数据的记录来还原正确的文件状态。
writeback 模式:
同样是仅记录元数据在日志中,但与 ordered 模式不同的是,它不保证数据的顺序写入。这种模式下,元数据的更新记录在日志中,但是数据写入磁盘的顺序和时间没有严格的要求。这使得系统在写入操作上有更高的灵活性,性能可能会更好,但数据一致性的保证相对较弱。例如,在系统负载较高,对性能要求较为迫切的场景下,writeback 模式可能会被使用,但同时需要承担一定的数据风险,因为在系统崩溃后可能需要更多的恢复操作来确保文件系统的正确状态。
ext4 文件系统
概述:
ext4 是 ext3 的进一步改进版本,它在性能和功能上都有了显著的提升。它继承了 ext3 的日志功能,并在此基础上进行了优化和扩展,使得文件系统能够更好地适应现代计算机系统的需求。
性能提升方面:
支持更大的文件系统和文件大小:随着计算机存储技术的发展,用户对存储容量的需求越来越大。ext4 文件系统能够支持更大的文件系统容量和单个文件大小。例如,它可以支持文件系统大小达到 1EB(1EB = 1024PB,1PB = 1024TB),单个文件大小可以达到 16TB。这使得它能够满足如大型数据中心、海量存储服务器等场景下对大文件和大容量存储的需求。
引入新的性能优化技术:
延迟分配:ext4 采用了延迟分配技术,它不会立刻为新创建的文件分配磁盘空间,而是等到数据真正要写入磁盘时才进行分配。这样做的好处是可以减少磁盘碎片的产生,提高磁盘空间的利用率。例如,当你创建一个新文件但还没有写入任何数据时,ext4 不会立即为这个文件划分磁盘空间,而是在你开始写入数据后,根据实际写入的数据量和顺序来合理地分配磁盘块,使得磁盘空间的分配更加高效。
多块分配:该技术允许一次为文件分配多个连续的磁盘块。这对于连续写入的数据(如大型视频文件、数据库备份文件等)非常有利,可以减少磁头的寻道时间,从而提高写入速度。例如,当你要写入一个大文件时,ext4 可以一次性为这个文件分配多个相邻的磁盘块,使得数据能够快速地连续写入这些磁盘块,就像在高速公路上连续行驶而不用频繁变道一样,提高了文件写入的效率。
XFS 文件系统
概述:
XFS 最初是由 SGI 开发的高性能日志文件系统。它的设计目标是能够高效地处理大文件和高并发访问的情况,特别适用于服务器和高性能计算环境。
性能特点:
处理大文件和高并发能力强:在处理大文件方面,XFS 具有出色的性能。它采用了优化的文件分配策略,可以快速地为大文件分配连续的磁盘空间,使得大文件的读写速度非常快。例如,在存储和读取大型多媒体文件(如高清电影、大型数据库文件等)时,XFS 能够充分发挥其优势。在高并发访问场景下,XFS 通过先进的锁机制和缓存管理技术,能够有效地支持多个用户或进程同时对文件系统进行读写操作。就像一个大型商场的多个出入口同时开放,能够高效地处理大量顾客进出一样,XFS 可以应对复杂的高并发情况。
恢复特性:
快速恢复时间:XFS 的日志结构设计允许在系统崩溃后进行并行回放日志条目。这意味着在恢复文件系统时,它可以同时处理多个日志记录,大大加快了恢复的速度。相比其他文件系统,这种并行恢复机制就像多条救援通道同时工作,能够在更短的时间内使文件系统恢复到一致的状态,减少系统停机时间,对于需要高可用性的服务器系统来说是非常重要的优势。
JFS 文件系统
概述:
JFS 是由 IBM 开发的日志文件系统,主要是为大型服务器环境设计的。它注重提供高度可靠的数据完整性保障,以满足企业级服务器对数据安全和稳定性的严格要求。
数据完整性保障:
JFS 通过严谨的日志记录和恢复机制来确保数据的完整性。在文件系统操作过程中,所有重要的操作都会被详细地记录在日志中,并且在系统崩溃后可以根据这些日志准确地恢复文件系统的状态。例如,在金融交易服务器或者企业数据存储服务器等对数据准确性要求极高的场景中,JFS 能够保证即使在遇到硬件故障或者软件问题导致系统崩溃时,数据也不会丢失或者损坏,为企业的数据资产提供了坚实的保护。
可扩展性:
支持动态扩展文件系统大小而不中断服务:这是 JFS 的一个重要特点。在企业服务器的运行过程中,随着业务的发展和数据量的增加,可能需要不断地扩大文件系统的容量。JFS 允许在不中断服务器正常服务的情况下,动态地扩展文件系统的大小。这就好比在一个正在营业的商场中,可以在不影响顾客购物的情况下对商场进行扩建,使得服务器的维护和升级更加方便,不会因为文件系统容量的限制而影响业务的正常运行。
ext3 文件系统
ext3 是 ext2 文件系统的扩展版本,增加了日志功能以提高数据的一致性和可靠性。它是 Linux 系统中广泛使用的一种文件系统。
特点:
日志支持:通过日志记录文件系统的更改操作,确保在系统崩溃后能够快速恢复。
三种日志模式:
journal:所有数据和元数据都记录在日志中,提供最高级别的数据一致性。ordered:仅元数据记录在日志中,但保证数据在元数据更新前写入磁盘。writeback:仅元数据记录在日志中,不保证数据的顺序写入。
向后兼容:ext3 完全兼容 ext2,可以直接将 ext2 文件系统转换为 ext3。
性能:虽然增加了日志功能,但在某些情况下可能不如 ext4 和 XFS 高效。
优点:
可靠性:日志功能显著提高了数据的一致性和可靠性。
兼容性:可以无缝地从 ext2 升级到 ext3。
缺点:
性能:相比 ext4 和 XFS,在处理大量小文件时性能较差。
限制:最大文件系统大小和文件大小有限制(通常最大文件系统大小为 16TB,最大文件大小为 2TB)。
ext4 文件系统
ext4 是 ext3 的进一步改进版本,提供了更好的性能和更多的特性。它是现代 Linux 发行版中的默认文件系统之一。
特点:
更大的文件系统和文件大小:支持高达 1EB 的文件系统和高达 16TB 的单个文件。
延迟分配:在实际写入数据之前延迟分配块,从而提高空间利用率和性能。
多块分配:一次分配多个连续的数据块,减少碎片并提高性能。
在线碎片整理:可以通过
e4defrag工具进行在线碎片整理。持久预分配:预先分配空间以避免未来的碎片。
快速 fsck:更快的文件系统检查工具
fsck。
优点:
高性能:在处理大量小文件时比 ext3 更高效。
更大的容量:支持更大的文件系统和文件大小。
更好的碎片管理:通过多种技术减少碎片,提高性能。
缺点:
复杂性:相比 ext3,实现更加复杂,可能会引入新的错误。
兼容性:虽然与 ext3 兼容,但一些高级特性可能需要特定的内核支持。
XFS 文件系统
XFS 是由 Silicon Graphics 开发的一种高性能日志文件系统,设计用于处理大文件和高并发访问。它在企业级应用中非常流行。
特点:
高性能:特别适合处理大文件和高 I/O 负载。
日志功能:支持元数据和数据的日志记录,确保数据一致性。
动态扩展:可以在不停机的情况下扩展文件系统大小。
快照:支持创建文件系统的快照,便于备份和恢复。
分布式事务:支持分布式事务处理,适用于集群环境。
直接 I/O:支持直接 I/O 操作,绕过缓存,提高性能。
优点:
高性能:在处理大文件和高 I/O 负载时表现出色。
可扩展性:支持动态扩展文件系统大小。
可靠性:日志功能和快照支持提高了数据的安全性。
缺点:
碎片管理:在处理大量小文件时可能会出现碎片问题。
复杂性:配置和管理相对复杂,需要更多的专业知识。
JFS (Journaled File System)
JFS 是由 IBM 开发的一种日志文件系统,最初用于 AIX 操作系统,后来移植到 Linux。它旨在提供高度可靠的数据完整性保障。
特点:
日志功能:支持元数据和数据的日志记录,确保数据一致性。
高性能:优化了 I/O 性能,特别是在处理大文件时。
可扩展性:支持较大的文件系统和文件大小。
快速恢复:通过日志回放,可以在短时间内恢复文件系统。
快照:支持创建文件系统的快照,便于备份和恢复。
内存映射:支持内存映射 I/O,提高性能。
优点:
可靠性:高度可靠的日志机制,确保数据一致性。
高性能:优化了 I/O 性能,特别是在处理大文件时。
快照支持:便于备份和恢复。
缺点:
社区支持:相比 ext4 和 XFS,JFS 在 Linux 社区中的支持较少。
使用率:在 Linux 系统中的使用率相对较低。
总结
ext3 提供了基本的日志功能,适合需要简单可靠性的场景。
ext4 在 ext3 的基础上增加了更多特性和性能优化,是现代 Linux 发行版的默认选择。
XFS 专为高性能和大文件处理设计,适用于企业级应用。
JFS 提供了高度可靠的数据完整性保障,但社区支持和使用率相对较低。
选择哪种文件系统取决于具体的应用需求,例如对性能、可靠性和可扩展性的要求。理解每种文件系统的特性和优缺点有助于做出合适的选择。
下面是对 KahaDB 存储机制的各个部分与存储目录下的文件对应关系以及相关概念的进一步解释和补充:
KahaDB 存储结构
KahaDB 的存储结构主要包括以下几个部分:
Metadata Cache (内存中的 B-Tree)
这是内存中缓存的一部分,用于加速消息索引的查找。
通过将索引数据保留在内存中,可以大大提高检索速度。
checkpointInterval参数决定了 Metadata Cache 与磁盘上的 Metadata Store 同步的频率。这个同步过程被称为检查点(checkpoint),它确保了即使发生崩溃也能从最近的检查点恢复。
Metadata Store (B-Tree Indexes)
对应于磁盘上的
db.data文件。它以 B-Tree 形式存储了对 Data Logs 的索引。
这个索引使得 Broker 在重启时能够快速定位到每条消息的位置,从而加快恢复过程。
如果
db.data文件损坏,则需要扫描所有的日志文件来重建索引,这是一个耗时的过程。
Data Logs (db-*.log)
默认情况下,每个日志文件大小为 32MB。
日志文件用于以滚动日志的形式存储消息及其相关信息,如确认、订阅、取消订阅等。
每当一个日志文件被填满后,就会创建一个新的日志文件。
这些日志文件是实际的消息数据载体,包含了所有持久化的消息。
Redo Log (db.redo)
Redo log 是为了防止在写入过程中出现部分页写入(partial page write)问题而设计的。
当向 Data Logs 写入数据时,先将数据写入 redo log,然后再写入 Data Logs。
如果在写入过程中发生了故障(例如突然断电),可以通过 redo log 来恢复未完成的写操作。
这种技术称为“双重写”(Double Write),它保证了数据的一致性和完整性。
关于 Double Write 技术
Double Write 技术的核心思想是在写入数据之前,先将数据写入一个专门的日志文件(redo log),然后再将数据写入实际的数据文件。这样做的好处是:
防止部分页写入:如果在写入过程中发生故障,导致只有一部分数据被写入,可以通过 redo log 中的数据来恢复完整的信息。
提高数据一致性:确保即使在异常情况下,数据也是一致的。
简化恢复过程:由于有完整的 redo log,恢复过程变得更加简单和可靠。
总结
KahaDB 通过结合内存中的元数据缓存、磁盘上的索引和日志文件,提供了一个高效且可靠的持久化存储解决方案。合理配置这些参数(如 maxLogSize, checkpointInterval 等)可以帮助优化性能并确保系统的稳定性。同时,使用 Redo Log 和 Double Write 技术可以有效避免部分页写入问题,进一步增强了系统的健壮性。
确实,KahaDB 的一些设计原则和机制与 MySQL 有一些相似之处,尤其是在数据持久化、索引管理和事务处理方面。下面是 KahaDB 和 MySQL 在这些方面的比较:
数据持久化
KahaDB:
使用日志结构存储(log-structured storage)来保存消息数据。
日志文件(Data Logs,
db-*.log)是主要的数据载体,类似于 MySQL 的二进制日志(binary log)。Redo Log (
db.redo) 类似于 MySQL 的 InnoDB 存储引擎中的 redo log,用于在崩溃恢复时重做未完成的事务。
MySQL:
InnoDB 存储引擎使用双写缓冲区(doublewrite buffer)来防止部分页写入问题。
二进制日志(binary log)记录了所有更改数据库状态的操作,用于复制和恢复。
InnoDB 还有回滚日志(undo log),用于支持事务的回滚操作。
索引管理
KahaDB:
使用 B-Tree 结构在内存中缓存索引(Metadata Cache),并在磁盘上持久化索引(Metadata Store,
db.data)。检查点(checkpoint)机制定期将内存中的索引同步到磁盘,以确保数据一致性。
MySQL:
InnoDB 存储引擎也使用 B-Tree 结构来管理索引。
索引可以存储在内存中(如缓冲池)以加快访问速度,并且会定期刷新到磁盘。
InnoDB 也有检查点机制,用于将脏页从缓冲池刷回到磁盘上的表空间文件。
事务处理
KahaDB:
支持 JMS 事务,确保消息的一致性和完整性。
使用两阶段提交协议(2PC)来保证分布式事务的一致性。
MySQL:
InnoDB 存储引擎支持 ACID 事务,确保原子性、一致性、隔离性和持久性。
使用多版本并发控制(MVCC)来提高并发性能。
支持多种事务隔离级别(读未提交、读已提交、可重复读、串行化)。
性能优化
KahaDB:
可以通过调整日志文件大小(
maxLogSize)、检查点间隔(checkpointInterval)等参数来优化性能。使用内存映射文件和缓存机制来减少 I/O 开销。
MySQL:
可以通过调整缓冲池大小、日志文件大小、InnoDB 配置参数等来优化性能。
使用查询缓存、连接池等技术来提高响应速度。
备份与恢复
KahaDB:
可以通过备份整个数据目录来实现数据备份。
使用检查点和日志文件来进行崩溃恢复。
MySQL:
提供多种备份方式,包括物理备份(如 mysqldump)和逻辑备份(如 XtraBackup)。
使用二进制日志和 InnoDB 的 redo log 来进行崩溃恢复和基于时间点的恢复。
小结
尽管 KahaDB 和 MySQL 在某些设计和实现细节上有相似之处,但它们服务于不同的目的。KahaDB 主要用于消息队列系统的持久化存储,而 MySQL 是一个通用的关系型数据库管理系统。两者都在各自的领域内提供了高效的持久化、索引管理和事务处理机制。理解这些相似之处有助于更好地配置和优化 KahaDB,特别是对于那些熟悉 MySQL 的用户来说,很多概念和技术都是相通的。
jms事务是什么
JMS 事务的定义
JMS(Java Message Service)事务是一种机制,用于确保在消息传递系统中,消息的生产和消费操作能够以原子性的方式执行。原子性意味着这些操作要么全部成功,要么全部失败,就像一个不可分割的整体。在 JMS 中,事务主要涉及消息生产者(Producer)发送消息和消息消费者(Consumer)接收并确认消息这两个关键操作。
例如,在一个电商系统中,当用户下单后,订单系统需要发送消息到库存系统通知扣减库存,同时发送消息到物流系统通知发货准备。这些消息的发送应该作为一个事务来处理,要么所有相关消息都成功发送,要么都不发送,以保证系统数据的一致性。
JMS 事务的工作原理
生产者事务:
当一个 JMS 生产者开启一个事务后,它会在事务上下文中发送消息。这些消息不会立即被发送到消息队列或主题(Topic),而是被暂存在本地缓存或者缓冲区中。例如,在 ActiveMQ 中,消息会被暂存在生产者端的内存缓存区域。
只有当生产者提交事务时,所有暂存的消息才会被一次性发送到消息服务器(如 ActiveMQ Broker)。如果生产者在事务过程中出现异常或者执行了回滚操作,那么所有暂存的消息都不会被发送,就好像这些消息从未被生产一样。
消费者事务:
对于消费者而言,事务同样重要。当消费者开启一个事务后,它从消息队列或主题中接收消息。这些消息在事务未提交之前,不会被标记为已接收状态。
如果消费者成功处理了消息并提交事务,那么消息服务器会将这些消息标记为已接收。但如果消费者在处理消息过程中出现异常或者执行了回滚操作,那么这些消息会被重新放回消息队列或主题中,等待下一次被消费,以确保消息不会因为异常情况而丢失。
JMS 事务的优势
数据一致性保证:
通过确保消息生产和消费操作的原子性,JMS 事务可以有效地防止消息丢失或者重复处理的情况。在复杂的分布式系统中,如金融交易系统、企业级应用集成等场景,这一点尤为重要。例如,在银行转账系统中,转账消息的发送和接收必须确保准确性,JMS 事务能够保证资金转账相关消息的正确处理,避免出现资金数据不一致的情况。
错误恢复和容错性:
当系统出现故障(如网络中断、应用程序崩溃等)时,JMS 事务可以帮助恢复系统状态。如果生产者在发送消息过程中出现故障,未提交的事务可以在系统恢复后重新执行或者回滚,避免了消息的混乱发送。对于消费者,故障恢复后可以重新处理未完成的消息事务,保证消息的正确消费。
JMS 事务与本地事务的比较
范围不同:
本地事务通常是指在单个数据库连接或者单个应用程序资源内的事务,它主要关注数据库操作的原子性,如数据库的插入、更新和删除操作。而 JMS 事务的范围涉及到消息的传递,包括消息生产者和消息消费者之间的操作,跨越了消息中间件和应用程序两个层面。
资源协调差异:
本地事务在协调数据库资源时,主要依靠数据库管理系统(DBMS)提供的事务机制,如 ACID 特性(原子性、一致性、隔离性、持久性)。JMS 事务需要协调消息中间件(如 ActiveMQ)和应用程序的操作,确保消息在发送和接收过程中的一致性,其实现方式和资源协调机制更为复杂,因为它涉及到消息队列、消息持久化存储等多个组件。
JMS(Java Message Service)事务是一种机制,用于确保一组消息操作要么全部成功,要么全部失败。这在需要保证数据一致性和完整性的应用中非常重要。JMS 事务通常与 JMS 会话(Session)相关联,通过会话来控制事务的开始、提交和回滚。
JMS 事务的主要特点
原子性:事务中的所有操作作为一个整体执行,要么全部成功,要么全部失败。
一致性:事务完成后,系统从一个一致状态转移到另一个一致状态。
隔离性:事务在执行过程中是隔离的,不受其他事务的影响。
持久性:一旦事务被提交,其结果就是永久的,即使系统崩溃也能恢复。
JMS 事务的类型
JMS 事务主要分为两种类型:
本地事务:只涉及单个 JMS 会话的事务。
XATransaction (分布式事务):跨越多个资源管理器(如数据库和消息队列)的事务,使用 XA 协议进行协调。
如何使用 JMS 事务
本地事务
以下是一个简单的示例,展示如何在 JMS 会话中使用本地事务:
import javax.jms.Connection;
import javax.jms.ConnectionFactory;
import javax.jms.JMSException;
import javax.jms.MessageProducer;
import javax.jms.Queue;
import javax.jms.Session;
import javax.jms.TextMessage;
import org.apache.activemq.ActiveMQConnectionFactory;
public class JmsTransactionExample {
public static void main(String[] args) {
Connection connection = null;
Session session = null;
try {
// 创建连接工厂
ConnectionFactory connectionFactory = new ActiveMQConnectionFactory("tcp://localhost:61616");
// 创建连接
connection = connectionFactory.createConnection();
connection.start();
// 创建事务性会话
session = connection.createSession(true, Session.SESSION_TRANSACTED);
// 获取目的地
Queue queue = session.createQueue("exampleQueue");
// 创建生产者
MessageProducer producer = session.createProducer(queue);
// 发送多条消息
for (int i = 0; i < 5; i++) {
TextMessage message = session.createTextMessage("Message " + i);
producer.send(message);
System.out.println("Sent message: " + message.getText());
}
// 提交事务
session.commit();
System.out.println("Transaction committed successfully.");
} catch (JMSException e) {
e.printStackTrace();
if (session != null) {
try {
session.rollback(); // 回滚事务
System.out.println("Transaction rolled back due to an error.");
} catch (JMSException ex) {
ex.printStackTrace();
}
}
} finally {
if (connection != null) {
try {
connection.close();
} catch (JMSException e) {
e.printStackTrace();
}
}
}
}
}在这个示例中:
创建了一个事务性会话
session,并设置了true表示开启事务支持,Session.SESSION_TRANSACTED表示使用本地事务。在事务中发送了多条消息。
如果没有异常发生,则调用
session.commit()提交事务。如果发生异常,则调用
session.rollback()回滚事务。
分布式事务 (XA)
对于跨多个资源管理器的事务,可以使用 XA 事务。在这种情况下,你需要配置 JMS 会话为 XA 事务,并使用 JTA(Java Transaction API)来协调事务。
以下是使用 JTA 和 XA 事务的一个简单示例:
import javax.jms.Connection;
import javax.jms.ConnectionFactory;
import javax.jms.JMSException;
import javax.jms.MessageProducer;
import javax.jms.Queue;
import javax.jms.Session;
import javax.jms.TextMessage;
import javax.transaction.UserTransaction;
import org.apache.activemq.ActiveMQConnectionFactory;
import org.apache.activemq.ActiveMQXAConnectionFactory;
import bitronix.tm.BitronixTransactionManager;
import bitronix.tm.TransactionManagerServices;
public class JmsXATransactionExample {
public static void main(String[] args) {
Connection connection = null;
Session session = null;
UserTransaction utx = null;
try {
// 初始化 Bitronix 事务管理器
BitronixTransactionManager btm = TransactionManagerServices.getTransactionManager();
// 创建 XA 连接工厂
ConnectionFactory xacf = new ActiveMQXAConnectionFactory("tcp://localhost:61616");
// 开始事务
utx = btm.getUserTransaction();
utx.begin();
// 创建连接
connection = xacf.createConnection();
connection.start();
// 创建事务性会话
session = connection.createSession(true, Session.SESSION_TRANSACTED);
// 获取目的地
Queue queue = session.createQueue("exampleQueue");
// 创建生产者
MessageProducer producer = session.createProducer(queue);
// 发送多条消息
for (int i = 0; i < 5; i++) {
TextMessage message = session.createTextMessage("Message " + i);
producer.send(message);
System.out.println("Sent message: " + message.getText());
}
// 提交事务
utx.commit();
System.out.println("XA Transaction committed successfully.");
} catch (Exception e) {
e.printStackTrace();
if (utx != null) {
try {
utx.rollback(); // 回滚事务
System.out.println("XA Transaction rolled back due to an error.");
} catch (Exception ex) {
ex.printStackTrace();
}
}
} finally {
if (connection != null) {
try {
connection.close();
} catch (JMSException e) {
e.printStackTrace();
}
}
}
}
}在这个示例中:
使用了
ActiveMQXAConnectionFactory来创建 XA 连接工厂。使用了 Bitronix 事务管理器来管理 XA 事务。
通过
UserTransaction接口来控制事务的开始、提交和回滚。
总结
JMS 事务提供了强大的机制来确保消息操作的一致性和完整性。无论是本地事务还是分布式事务,都可以通过适当的配置和代码实现来满足不同的业务需求。理解这些概念和技术可以帮助你在实际应用中更好地利用 JMS 的功能。