MCA高级架构师-架构师进阶-存储中间件
81_HTAP-TIDB-5.x原理及实战
"81_HTAP-TIDB-5.x原理及实战" 这个标题看起来像是一个关于TiDB 5.x版本的HTAP(Hybrid Transactional/Analytical Processing,混合事务处理与分析处理)技术的教程或者课程名称。HTAP是一个数据库系统架构的概念,旨在提供同时支持在线事务处理(OLTP)和在线分析处理(OLAP)的能力。这意味着同一个系统可以处理日常的读写操作(如银行转账、订单处理等),同时也能够高效地执行复杂的查询和数据分析任务。
TiDB(tidb.io)是一个开源的新一代分布式数据库,它兼容MySQL协议和语法,支持水平扩展、强一致性的分布式事务、以及在线DDL操作等功能。TiDB的设计目标是为了解决大规模数据集上的实时分析和事务处理的需求,因此非常适合HTAP场景。
TiDB HTAP原理
TiDB HTAP架构通常包含以下几个关键组件:
TiDB Server - 负责SQL解析、查询优化和分发。
TiKV - 一个分布式的键值存储系统,提供了事务的一致性和隔离性。
TiFlash - 一个MPP(Massively Parallel Processing,大规模并行处理)引擎,用于加速OLAP查询,它可以复制TiKV中的数据,并允许查询直接在TiFlash上执行,以获得更快的响应时间。
PD (Placement Driver) - 负责集群状态管理、成员变更、以及调度决策。
通过将TiKV作为事务处理的主要存储层,而将TiFlash作为分析查询的加速器,TiDB能够在一个统一的架构中提供两种不同的服务,减少了数据复制和迁移的成本,提高了系统的整体效率。
实战应用
在实战应用中,使用TiDB进行HTAP开发通常涉及以下几个步骤:
环境搭建 - 安装配置TiDB集群,包括TiDB Server, TiKV, TiFlash 和 PD。
数据建模 - 根据业务需求设计合理的表结构和索引。
数据导入 - 使用工具如
tidb lightning快速导入大量数据。事务处理 - 利用TiDB的事务一致性来保证数据的正确性。
分析查询 - 利用TiFlash来进行复杂的数据分析,提高查询性能。
监控与调优 - 监控系统运行状况,并根据需要调整参数以优化性能。
如果你正在寻找具体的编程代码段,或者是关于如何实施某个特定功能的详细指南,可以具体说明你的需求,这样我可以提供更加针对性的帮助。
83_mycat,sharding-jdbc从入门到精通
Mycat2应用与实战教程
讲师(庆哥)
1.Mycat2概述
1.1 什么是MyCat
官网: http://mycatone.top/
Mycat 是基于 java 语言编写的数据库中间件,是一个实现了 MySQL 协议的服务器,前端用户可以把它看作是一个数据库代理,用 MySQL 客户端工具和命令行访问,而其后端可以用 MySQL 原生协议与多个 MySQL 服务器通信,也可以用 JDBC 协议与大多数主流数据库服务器通信,其核心功能是分库分表和读写分离,即将一个大表水平分割为 N 个小表,存储在后端 MySQL 服务器里或者其他数据库里。
MyCat 是基于阿里开源的 Cobar 产品而研发,Cobar 的稳定性、可靠性、优秀的架构和性能以及众多成熟的使用案例使得 MyCat 变得非常的强大。
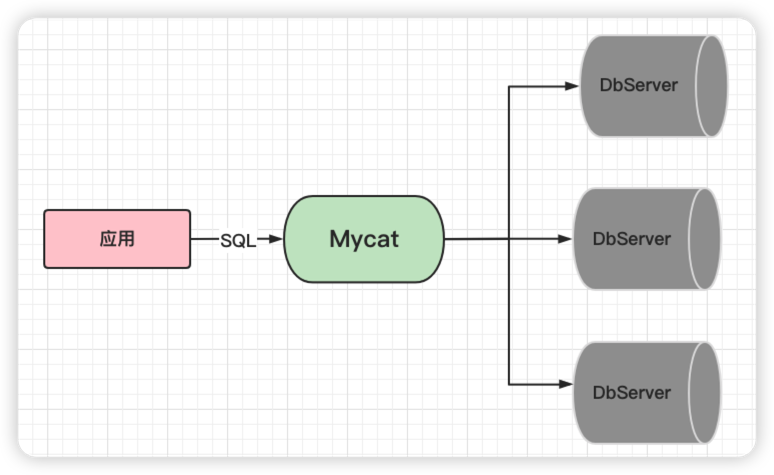
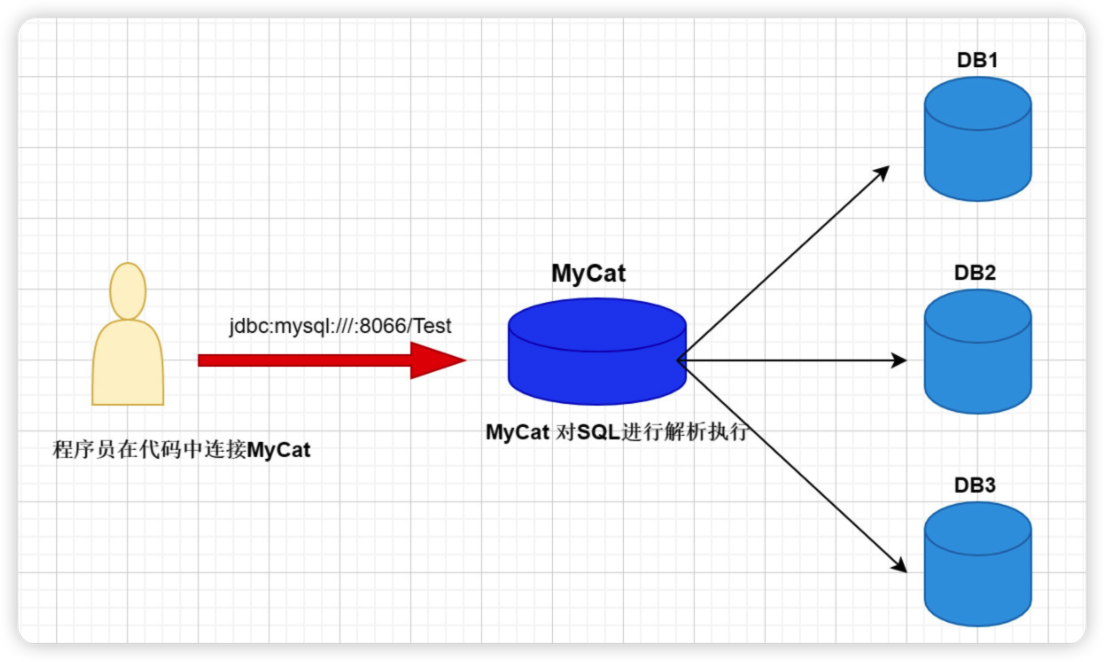
Mycat对于我们Java程序员来说,就是一个近似等于 MySQL 的数据库服务器,你可以用连接 MySQL 的方式去连接 Mycat(除了端口不同,默认的Mycat 端口是 8066 而非MySQL 的 3306,因此需要在连接字符串上增加端口信息)。
1.2 Mycat的作用
1.2.1 数据分片
数据分片包括里:垂直分片和水平分片,垂直分片包括:垂直分库和垂直分表,水平分片包括: 水平分库和水平分表。
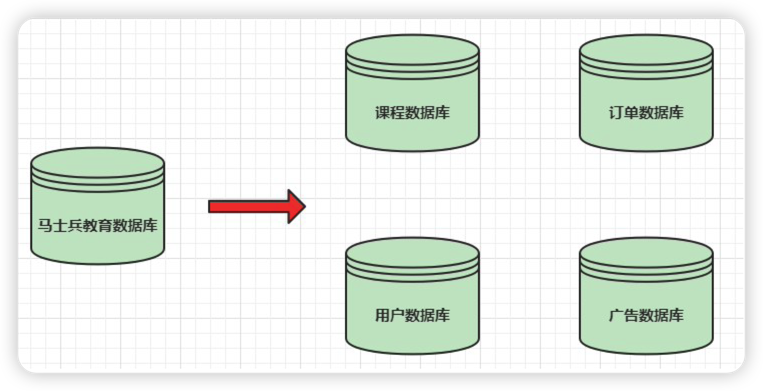
1)垂直分库
数据库中不同的表对应着不同的业务,垂直切分是指按照业务的不同将表进行分类,分布到不同的数据库上面
将数据库部署在不同服务器上,从而达到多个服务器共同分摊压力的效果
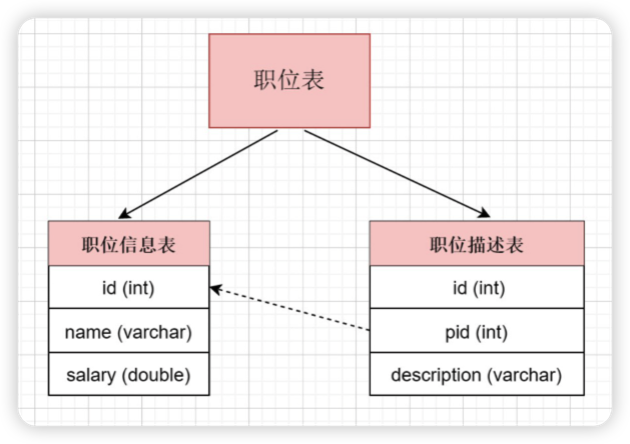
2)垂直分表
表中字段太多且包含大字段的时候,在查询时对数据库的IO、内存会受到影响,同时更新数据时,产生的binlog文件会很大,MySQL在主从同步时也会有延迟的风险。
将一个表按照字段分成多表,每个表存储其中一部分字段。
对职位表进行垂直拆分, 将职位基本信息放在一张表, 将职位描述信息存放在另一张表
œ垂直拆分带来的一些提升
解决业务层面的耦合,业务清晰
能对不同业务的数据进行分级管理、维护、监控、扩展等
高并发场景下,垂直分库一定程度的提高访问性能
垂直拆分没有彻底解决单表数据量过大的问题
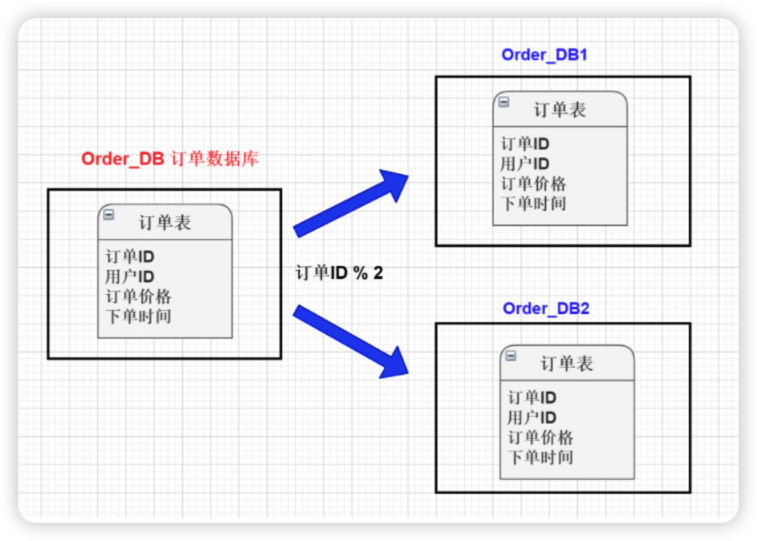
3) 水平分库
将单张表的数据切分到多个服务器上去,每个服务器具有相应的库与表,只是表中数据集合不同。 水平分库分表能够有效的缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬件资源等的瓶颈.
4) 水平分表
针对数据量巨大的单张表(比如订单表),按照规则把一张表的数据切分到多张表里面去。 但是这些表还是在同一个库中,所以库级别的数据库操作还是有IO瓶颈。
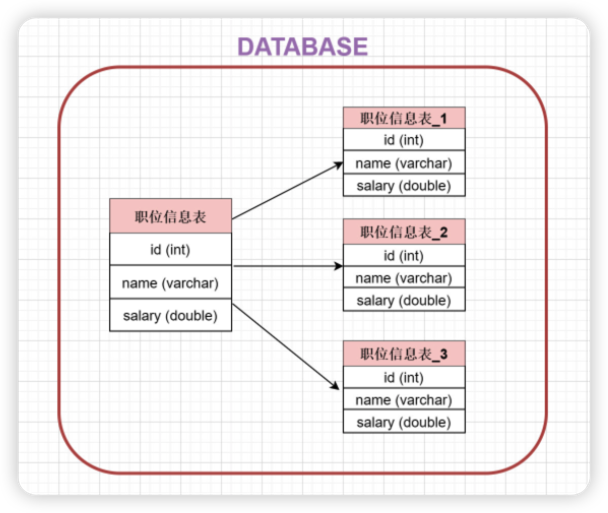
总结
垂直分表: 将一个表按照字段分成多表,每个表存储其中一部分字段。
垂直分库: 根据表的业务不同,分别存放在不同的库中,这些库分别部署在不同的服务器.
水平分库: 把一张表的数据按照一定规则,分配到不同的数据库,每一个库只有这张表的部分数据.
水平分表: 把一张表的数据按照一定规则,分配到同一个数据库的多张表中,每个表只有这个表的部分数据.
1.2.2 读写分离
读写分离指的是:主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
注意: 读写分离的数据节点中的数据内容是一致,所以要先搭建主从复制架构
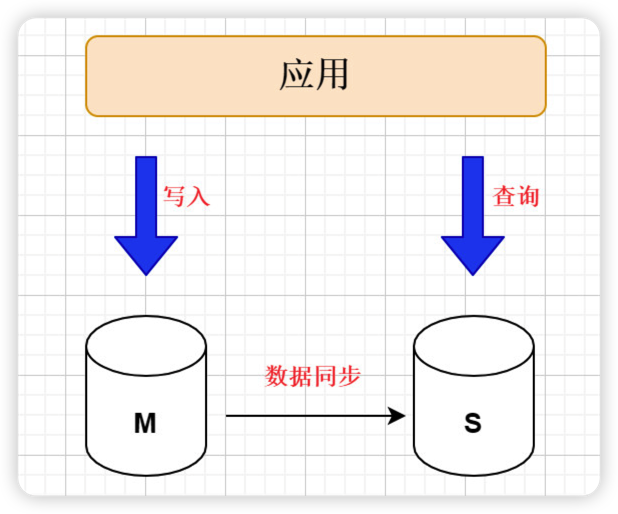
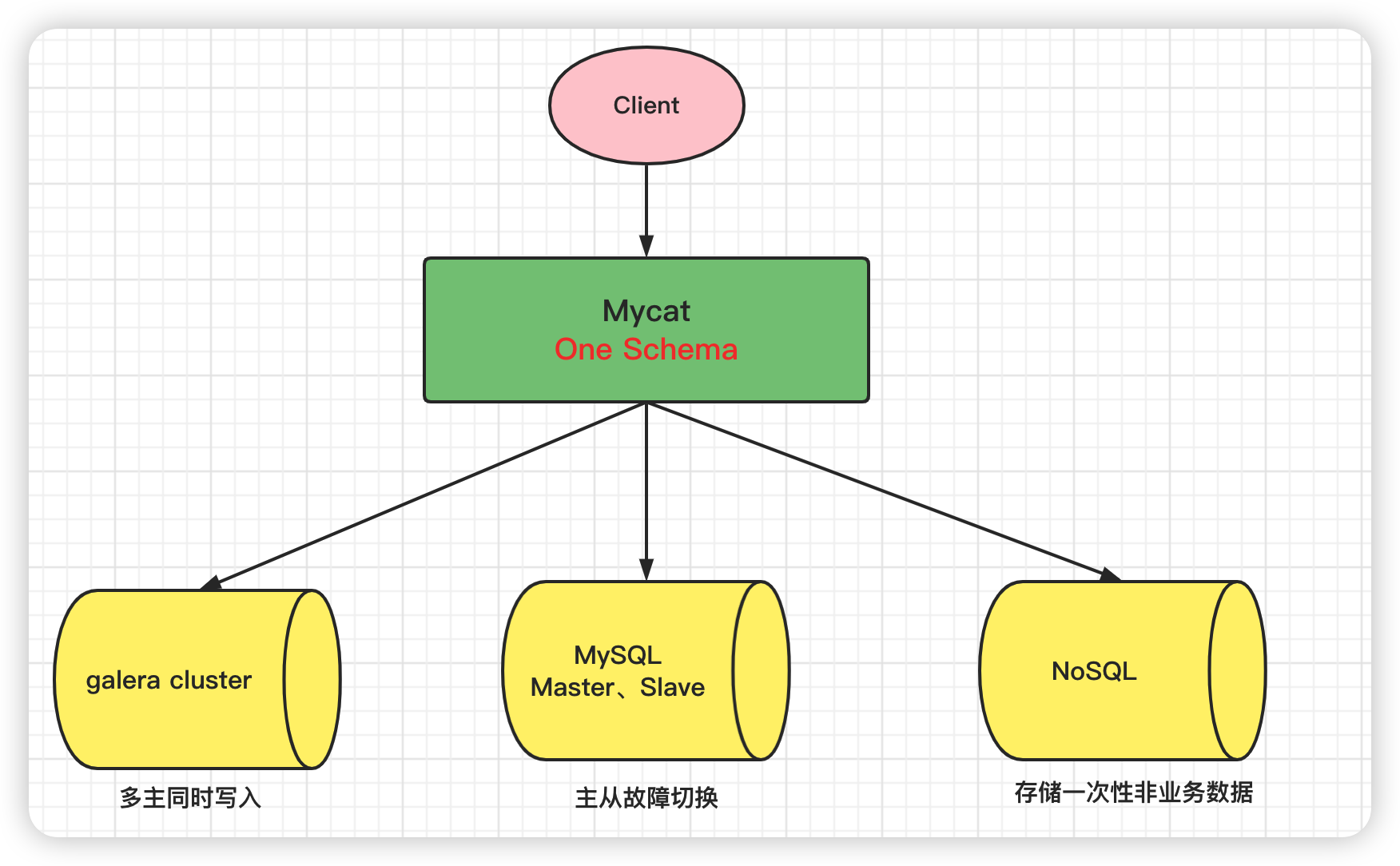
1.2.3 多数据源整合
Java工程里需要同时控制(连接)多个数据源:
业务需要。比如项目里要实现两个DB的双写/数据迁移,或者微服务边界划分不清使得一个工程直连了多个DB。
读写分离。大型一点的网站,为了提升DB的吞吐量和性能以及高可用性,数据库一般都会采用集群部署(1个Master+N个Slave模式)。
NoSQL数据库。使用NOSQL数据库存储大量的一次性非业务数据,比如日志类的数据
1.3 Mycat与ShardingJDBC的区别
mycat是一个中间件的第三方应用,sharding-jdbc是一个jar包
使用mycat时不需要修改代码,而使用sharding-jdbc时需要修改代码
Mycat 是基于 Proxy,它复写了 MySQL 协议,将 Mycat Server 伪装成一个 MySQL 数据库,而 Sharding-JDBC 是基于 JDBC 的扩展,是以 jar 包的形式提供轻量级服务的。
Mycat(proxy中间件层)
Sharding-jdbc(应用层):

1.4 Mycat2新特性
Mycat2的提升: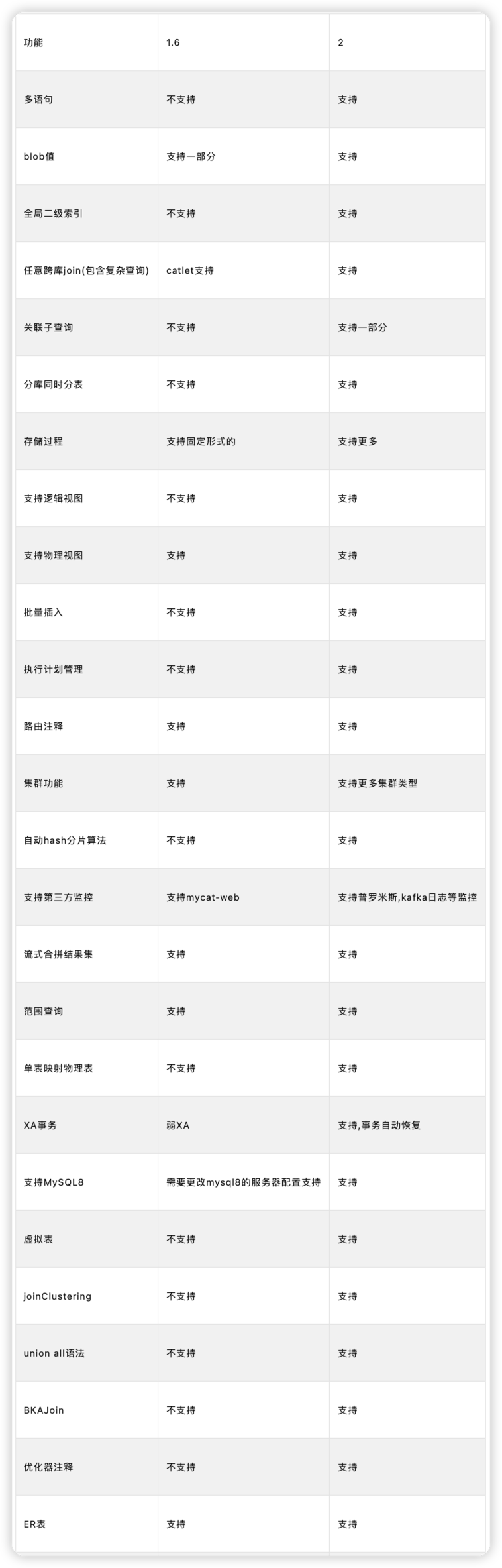
新特性总结
多语句,指的是可以批量执行建表语句
支持blob,blob二进制大对象
全局二级索引,用全局二级索引后,能有效减少全表扫描,对于减少连接使用,减少计算节点与存储节点的数据传输有帮助.
支持任意跨库跨表join查询
支持跨库跨表的关联子查询
支持分库同时分表,把分库分表合一,统一规划
存储过程: 存储过程支持多结果集返回、支持接收affectRow
支持逻辑视图
支持批量插入: 支持rewriteInsertBatchedStatementBatch参数(设置为true),用于提高批量插入性能。
支持执行计划管理:Mycat2的执行计划管理主要作用是管理执行计划,加快SQL到执行计划的转换。
路由注释,Mycat2对于路由注释的支持更加快捷方便,减少繁琐的配置
自动hash分片算法: 由1.6版本的手动配置算法,到2.0的自动hash分
支持第三方工具
单表映射物理表,可以直接将单表映射到物理表,更快速的创建数据库表
XA事务,首先数据库要支持XA事务
支持MySQL8
2.环境准备
2.1 准备测试环境
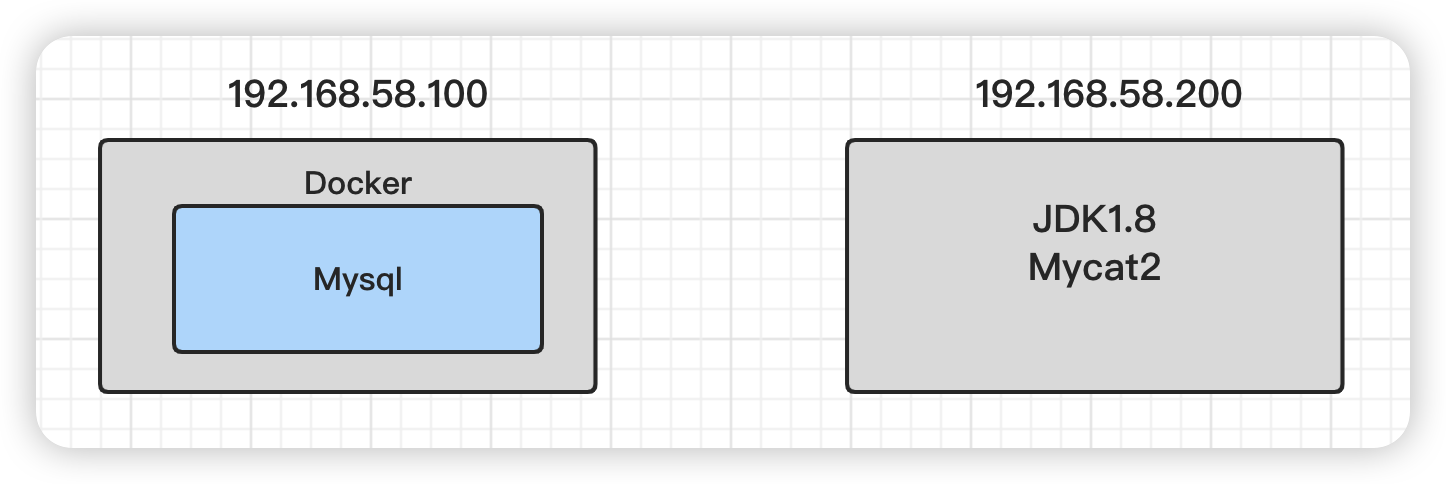
1)搭建两台虚拟机,分别部署MySQL和Mycat2
192.168.58.100服务器上的MySQL要部署到docker中,方便后面我们快速搭建MySQL集群, 并且MySQL的版本使用MySQL8。192.168.58.200服务器,安装Mycat2之前要安装JDK,并且必须选择JDK1.8 避免出现其他问题。
2.2 Docker基本使用
1)安装docker
# 1、yum 包更新到最新
yum update
# 2、安装需要的软件包, yum-util 提供yum-config-manager功能,另外两个是devicemapper驱动依赖的
yum install -y yum-utils device-mapper-persistent-data lvm2
# 3、 设置yum源
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
# 4、 安装docker,出现输入的界面都按 y
yum install -y docker-ce
# 5、 查看docker版本,验证是否验证成功
docker -v2)镜像加速方案
默认情况,将从docker hub(https://hub.docker.com/)下载docker镜像太慢,一般都会配置镜像加速器;
建议配置阿里云镜像加速,编辑该文件:
vim /etc/docker/daemon.json 在该文件中输入如下内容:
{
"registry-mirrors": ["https://3ad96kxd.mirror.aliyuncs.com"]
}配置完成记得刷新配置
sudo systemctl daemon-reload
sudo systemctl restart docker3)镜像相关命令
查看镜像 docker images
搜索镜像 docker search imageName
拉取镜像 docker pull imageName:version
删除镜像 docker rmi imageId rmi-->remove Image
4)查看容器
查看正在运行的容器
docker ps查看所有容器(查看正在运行的和已经停止运行的)
docker ps –a
docker ps -all查看最后一次运行的容器
docker ps –l查看停止的容器
docker ps -f status=exited5)创建容器命令
docker run 参数 镜像名称:镜像标签 /bin/bash创建容器常用的参数说明:
-i:表示运行容器,如果不加该参数那么只是通过镜像创建容器,而不启动。
-t:表示容器启动后会进入其命令行。加入这两个参数后,容器创建就能登录进去。即分配一个伪终端(如果只加it两个参数,创建后就会自动进去容器)。
-d:在run后面加上-d参数,则会创建一个守护式容器在后台运行(这样创建容器后不会自动登录容器)。
--name :为创建的容器命名。
-v:表示目录映射关系(前者是宿主机目录,后者是映射到宿主机上的目录),可以使用多个-v做多个目录或文件映射。注意:最好做目录映射,在宿主机上做修改,然后共享到容器上。
-p:表示端口映射,前者是宿主机端口,后者是容器内的映射端口。可以使用多个-p做多个端口映射,例如:可以将Docker中Tomcat容器的8080端口映射到宿主机上的某一个端口8080,那么以后访问tomcat只需要:http://宿主机的IP:8080/
进入容器之后,初始化执行的命令:/bin/bash;可写可不写6) 删除指定的容器,正在运行的容器无法删除
#删除容器
docker rm 容器名称(容器ID)
#删除镜像
docker rmi 镜像ID(镜像名称)2.3 Docker部署单机MySQL
搜索mysql镜像
docker search mysql拉取
mysql8镜像
docker pull mysql:8.0.29使用docker方式创建MySQL服务器
注意:如果此时防火墙是开启的,则先关闭防火墙,并重启docker,否则后续安装的MySQL无法启动
#关闭docker
systemctl stop docker
#关闭防火墙
systemctl stop firewalld
#永久关闭
systemctl disable firewalld
#启动docker
systemctl start docker在docker中创建并启动MySQL服务器:端口3310
docker run -d \
-p 3310:3306 \
-v /msb/mysql/conf:/etc/mysql/conf.d \
-v /msb/mysql/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
--name msb-mysql \
mysql:8.0.29参数说明:
-p 3310:3306:表示端口映射,前者是宿主机端口,后者是容器内的映射端口,将容器的 3306 端口映射到宿主机的 3310 端口。
-v /msb/mysql/conf:/etc/mysql/conf.d: 配置文件映射,
:前面是宿主机目录,:后面是映射到宿主机上的文件,这样就可以在宿主机上做修改,然后共享到容器上-v /msb/mysql/data:/var/lib/mysql :数据文件目录映射,避免容器出现问题,导致数据丢失。
-e MYSQL_ROOT_PASSWORD=123456:初始化 root 用户的密码。
--name msb-mysql :容器名称
mysql:8.0.29 :镜像名称
进入容器,操作mysql
docker exec –it msb-mysql /bin/bash使用Navicat连接容器中的mysql 因为我们做了端口映射,所以连接的是192.168.58.100:3310
3.Mycat2 安装与启动
3.1 制作安装包
Mycat2不提供安装包,只提供核心JAR包,JAR包可以独立运行,安装包是使用Java Service Wrapper做壳的,如果需要安装包,需要自己制作。
JAR可以作为Java库引入自己业务项目中使用,Mycat2中的各个组件的设计都是可以独立使用的
步骤如下:
下载对应的tar或zip安装包,以及对应的jar包
zip包地址:http://dl.mycat.io/2.0/install-template/mycat2-install-template-1.20.zip
jar包地址:http://dl.mycat.io/2.0/1.21-release/mycat2-1.21-release-jar-with-dependencies-2022-3-14.jar
解压下载下来的zip包, 然后将下载好的jar包放入到 mycat/lib 目录下,如下图:

上传到Linux,这里我们将MyCat上传到192.168.58.200,这台服务器。Mycat 作为数据库中间件要和数据库部署在不同机器上。
# 授予 bin 目录下所有命令 可执行权限
[root@localhost mycat]# chmod +x bin/*安装 JDK1.8
1.查看云端yum库中目前支持安装的jdk软件包
yum search java|grep jdk
2.选择版本安装jdk
yum install -y java-1.8.0-openjdk*
3.安装完成后,验证是否安装成功
java -version
4.查找jdk安装位置
find / -name 'java'
默认安装路径一般为:
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.151-5.b12.el7_4.x86_64/jre/bin/java3.2 启动MyCat
1)MyCat需要连接的MySQL数据库中,创建用户,并赋予权限 (也可以直接使用root用户)
-- 修改默认密码校验方式
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
-- 用户名mycat,密码123456
CREATE USER 'mycat'@'%' IDENTIFIED BY '123456';
-- 官方文档强调要给root账号添加XA RECOVER权限
GRANT XA_RECOVER_ADMIN ON *.* TO 'root'@'%';
-- 视情况给mycat赋予权限
GRANT ALL PRIVILEGES ON *.* TO 'mycat'@'%' ;
flush privileges;2)配置mycat要连接的数据源
mycat连接真正数据库的信息目录是在 /mycat/conf/datasources
配置原型库的数据源信息 prototypeDs.datasource.json, 主要是 url、user、password这三个参数
{
"dbType":"mysql",
"idleTimeout":60000,
"initSqls":[],
"initSqlsGetConnection":true,
"instanceType":"READ_WRITE",
"maxCon":1000,
"maxConnectTimeout":3000,
"maxRetryCount":5,
"minCon":1,
"name":"prototypmysql
"password":"123456",
"type":"JDBC",
"url":"jdbc:mysql://192.168.58.100:3310/mysql?useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8",
"user":"mycat",
"weight":0
}3)mycat相关命令
进入bin目录
./mycat status 状态
./mycat start 启动
./mycat stop 停止
./mycat restart 重启服务
./mycat pause 暂停4)Mycat用户配置
文件目录及配置文件
cd /root/software/mycat/conf/users
[root@localhost users]# ll
总用量 4
-rw-r--r--. 1 root root 107 12月 3 04:06 root.user.json
[root@localhost users]# vim root.user.json 只需要配置用户名,密码
{
"dialect":"mysql",
"ip":null,
"password":"123456",
"transactionType":"xa",
"username":"root"
}5)启动mycat,使用图形工具链接,mycat默认端口8066

3.3 连接Mycat
1)连接成功后,创建执行下面的建库建表语句
-- 创建数据库
CREATE DATABASE user_db CHARACTER SET utf8;
-- 创建表
CREATE TABLE users (
id INT(11) PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20) DEFAULT NULL,
age INT(11) DEFAULT NULL
);
-- 插入数据
INSERT INTO users VALUES(NULL,'user1',20);
INSERT INTO users VALUES(NULL,'user2',21);
INSERT INTO users VALUES(NULL,'user3',22);2)在Mycat中执行成功,Mycat所代理的数据库中也会增加一个user_db数据库和users表
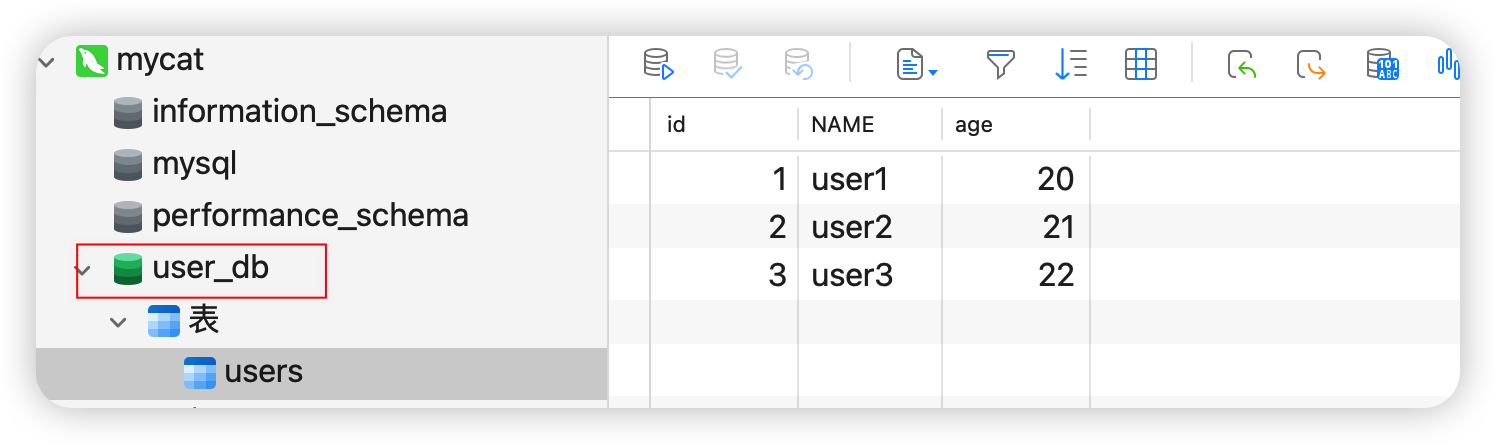
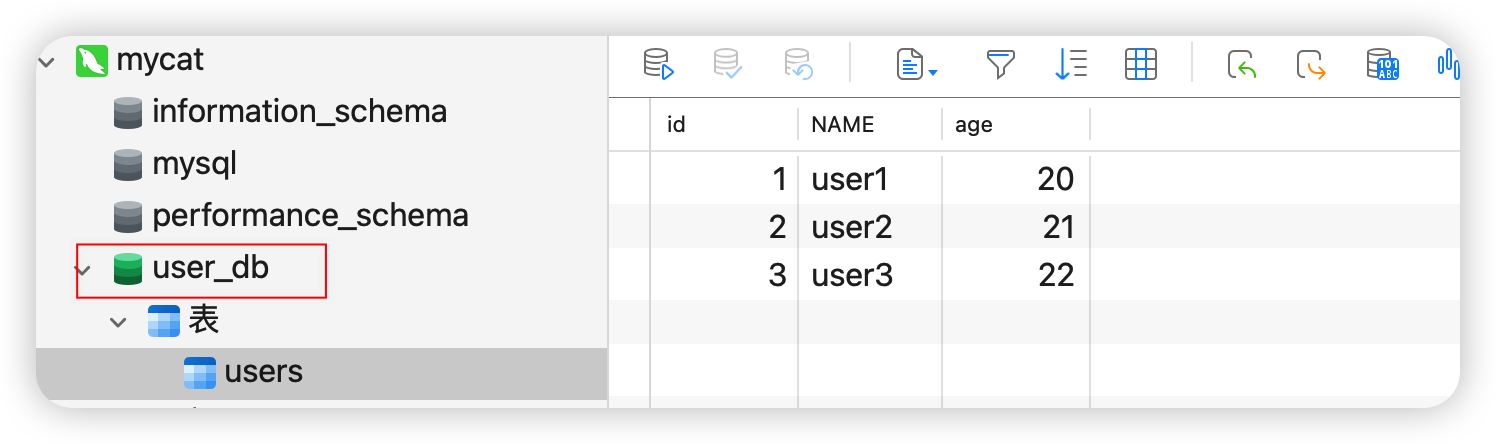
mycat.xa_log 是事务日志表会在Mycat2启动时候在存储节点上建立。
mycat.spm_plan mycat执行计划相关的表
4.Mycat2 核心概念
分库分表
按照一定的规则把数据库中的表拆分为多个带有数据库实例,物理库,物理表访问路径的分表。
逻辑库
对数据进行分片之后,从原来的与一个库,被切分为了多个分片数据库,所有的分片数据库构成了整个完整的数据库存储。Mycat在操作时,使用逻辑库代表整个完整的数据库集群,方便对于整个集群进行操作。
物理库
MySQL中真实存在的数据库
物理表
MySQL中真实存在的表
分片键
用于分片的数据库字段,是将数据库进行水平拆分的关键字段
例:将订单表的订单主键设置为分片键,根据订单主键进行取模分片。
物理分表
指的是已经进行数据拆分的,在数据库上面的物理表,是分片表的一个分区,多个物理分表中的数据汇总起来就是逻辑表的全部数据。
物理分库
一般是指包含多个分表的库,数据切分之后每一个大表被分不到不同的数据库上面,每个表分片所在的数据库就是物理分库。
单表
没有分片,没有数据冗余的表
全局表
变动不频繁
数据总量变化不大
经常被用来进行关联查询
比如说: 地址表 、字典表 这一类都是属于全局表,在每个数据库中都有这样一张或几张全局表,每个数据库中的全局表的数据是要保持一致的。
ER表
Mycat提出了基于E-R关系的数据分片策略,子表的记录与所有关联的父表的记录存放在同一个数据分片上,子表依赖于父表,通过表分组保证 数据的join不会跨库。
集群
多个数据节点组成的逻辑节点。
数据源
连接后端数据库的组件,它是数据库代理中连接后端数据库的客户端。
原型库
原型库是Mycat2后面的数据库,MySQL
5.Mycat2 核心配置文件
Mycat2作为一个数据库中间件,它所有的功能其实都是通过一些列配置文件定制一系列业务规则,通过与MySQL协作,提供具体的业务功能。所有Mycat2的所有功能都体现在他的配置文件中。
服务相关配置文件所在的目录是: mycat/conf

5.1 用户配置
1)配置用户相关信息的目录在: mycat/conf/users
2)命名方式:{用户名}.user.json
3)配置内容如下:
{
"dialect":"mysql",
"ip":null,
"password":"123456",
"transactionType":"xa",
"username":"root"
}
字段含义
ip:客户端访问ip,建议为空,填写后会对客户端的ip进行限制
username:用户名
password:密码
isolation:设置初始化的事务隔离级别
READ_UNCOMMITTED :1
READ_COMMITTED :2
REPEATED_READ:3,默认
SERIALIZABLE:4
tractionType:事务类型,可选值, 可以通过语句实现切换
set transaction policy ='xa'
set transaction.policy ='proxy'
proxy 表示本地事务,在涉及大于1个数据库的事务, commit阶段失败会导致不一致,但是兼容性最好xa事务,需要确认存储节点集群类型是否支持XA.5.2 数据源配置
配置Mycat连接的数据源信息 1)所在目录 mycat/conf/datasources 2)命名方式 {数据源名字} . datasource.json 3)配置内容如下:
{
"dbType":"mysql",
"idleTimeout":60000,
"initSqls":[],
"initSqlsGetConnection":true,
"instanceType":"READ_WRITE",
"maxCon":1000,
"maxConnectTimeout":3000,
"maxRetryCount":5,
"minCon":1,
"name":"prototypeDs",
"password":"123456",
"type":"JDBC",
"url":"jdbc:mysql://192.168.58.100:3310/mysql?useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8",
"user":"mycat",
"weight":0
}
字段含义
dbType:数据库类型,mysql
name:用户名
password:密码
type:数据源类型,默认JDBC
url:访问数据库地址
idleTimeout:空闲连接超时时间
initSqls:初始化sql
initSqlsGetConnection:对于jdbc每次获取连接是否都执行initSqls
nstanceType:配置实例只读还是读写, 可选值:READ_WRITE,READ,WRITE
weight:负载均衡权重
连接相关配置
"maxCon": 100,
"maxConnectTimeout" : 3000,
"RetryCount" : 5,
"minCon": 1,5.3 集群配置
1)配置集群信息,所在目录 mycat/conf/clusters 2)命名方式:{集群名字} . cluster.json 3)配置内容如下:
{
"clusterType":"MASTER_SLAVE", //主从集群
"heartbeat":{ //心跳检查
"heartbeatTimeout":1000,
"maxRetry":3,
"minSwitchTimeInterval":300,
"slaveThreshold":0
},
"masters":[
"prototypeDs" //主节点
],
"maxCon":200,
"name":"prototype",
"readBalanceType":"BALANCE_ALL", //负载均衡策略
"switchType":"SWITCH" //表示进行主从切换
}
字段含义
clusterType:集群类型,可选值:
SINGLE_NODE:单一节点
MASTER_SLAVE:普通主从
JSTER:garela- cluster/PXC 集群
MHA: MHA集群
MGR: MGR集群
readBalanceType:查询负载均衡策略,可选值:
BALANCE_ALL(默认值),获取集群中所有数据源
BALANCE_ALL_READ,获取集群中允许读的数据源
BALANCE_READ_WRITE,获取集群中允许读写的数据源,但允许读的数据源优先
BALANCE_NONE,获取集群中允许写数据源,即主节点中选择
switchType:切换类型5.4 逻辑库表
1)配置逻辑库表,实现分库分表,所在目录 mycat/conf/schemas 2)命名方式 {库名} . schema.json 3)配置内容如下:
vim mysql.schema.json
{
"customTables":{},
"globalTables":{}, //全局表配置
"normalProcedures":{},
"normalTables":{ // MySQL中真实表信息
"users":{
//建表语句
"createTableSQL":"CREATE TABLE user_db.users (\n\tid INT(11) PRIMARY KEY AUTO_INCREMENT,\n\tNAME VARCHAR(20) DEFAULT NULL,\n\tage INT(11) DEFAULT NULL\n)",
"locality":{
"schemaName":"user_db", //物理库
"tableName":"users", //物理表
"targetName":"prototype" //指向集群或者数据源
}
}
},
"schemaName":"user_db",
"shardingTables":{}, //分片表配置
"views":{}
}
//详细分库分表配置,后面的内容会有讲解注意:配置的schema的逻辑库逻辑表必须在原型库(prototype)中有对应的物理库物理表,否则不能启动
5.Mycat2实现读写分离
读写分离原理:读写分离就是让主库处理事务性操作,从库处理select查询。数据库复制被用来把事务性查询导致的数据变更同步到从库,同时主库也可以select查询。
实现读写分离是基于MySQL的主从复制架构的,通过一主多从的配置方式,可以将查询请求均匀的分散到多个数据副本,能够进一步的提升系统的处理能力。 所以这里我们先要搭建一下MySQL的主从复制集群。

5.1 Docker搭建MySQL主从复制集群
5.1.1 MySQL主从同步原理
MySQL通过binlog完成主备同步,实现最终一致性。
Mysql 中有一种日志叫做 binlog(二进制日志)。这个日志会记录下所有修改了数据库的SQL 语句(insert,update,delete,create/alter/drop table, grant 等等)
主从复制的原理其实就是把主服务器上的 binlog 复制到从服务器上执行一遍,这样从服务器上的数据就和主服务器上的数据相同了。
与主从复制相关的线程有三个
主库上的dump_thread
备库上的io_thread、sql_thread
与主从复制相关的日志有binlog、relaylog
binlog: 记录数据库的写入操作,以二进制的形式保存在日志文件;
relaylog: Slave 接收 Master 的同步日志,会先放到中继日志 relay log 里, slave 的读操作也会基于 relay log。
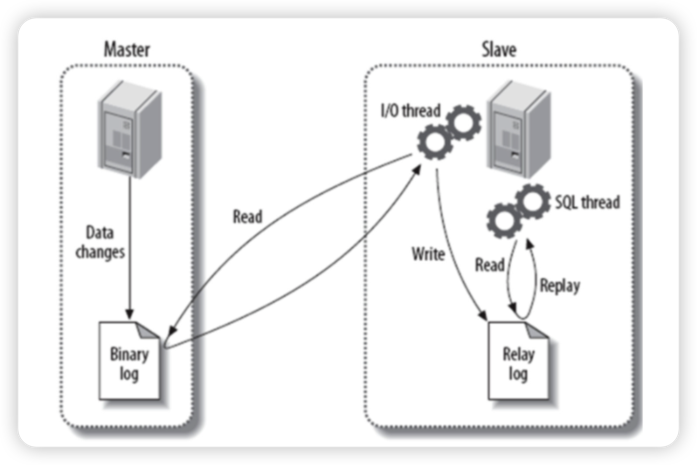
master将数据改变记录到
二进制日志(binary log)中。当slave上执行
start slave命令之后,slave会创建一个IO 线程用来连接master,请求master中的binlog。当slave连接master时,master会创建一个 **
binlog dump 线程,用于发送 binlog 的内容。在读取 binlog 的内容的操作中,会对主节点上的 binlog 加锁,当读取完成并发送给从服务器后解锁。IO 线程接收主节点 binlog dump 进程发来的更新之后,保存到
中继日志(relay log)中。slave的
SQL线程,读取relay log日志,并解析成具体操作,从而实现主从操作一致,最终数据一致。
主从部署必要条件
主库开启binlog日志(设置log-bin参数)
主从server-id不同
从库服务器能连通主库
服务器创建方式
使用
docker方式创建MySQL服务器,主从服务器IP一致,使用端口号区分。
5.1.2 主服务器搭建
在docker中创建并启动MySQL主服务器:
端口3306
docker run -d \
-p 3306:3306 \
-v /msb/mysql/master/conf:/etc/mysql/conf.d \
-v /msb/mysql/master/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
--name msb-mysql-master \
mysql:8.0.29创建MySQL主服务器配置文件
默认情况下MySQL的binlog日志是自动开启的,可以通过如下配置定义一些可选配置
vim /msb/mysql/master/conf/my.cnf
[mysqld]
# 服务器唯一id,默认值1
server-id=1
# 设置日志格式,默认值ROW
binlog_format=STATEMENT
# 二进制日志名,默认binlog
# log-bin=binlog
# 设置需要复制的数据库,默认复制全部数据库
#binlog-do-db=mytestdb
# 设置不需要复制的数据库
#binlog-ignore-db=mysql
#binlog-ignore-db=infomation_schema重启MySQL容器
docker ps
docker restart msb-mysql-masterbinlog格式说明:
binlog_format=STATEMENT:日志记录的是主机数据库的
写指令,性能高,但是now()之类的函数以及获取系统参数的操作会出现主从数据不同步的问题。binlog_format=ROW(默认):日志记录的是主机数据库的
写后的数据,批量操作时性能较差,解决now()或者 user()或者 @@hostname 等操作在主从机器上不一致的问题。binlog_format=MIXED:是以上两种level的混合使用,有函数用ROW,没函数用STATEMENT,但是无法识别系统变量
登录MySQL主服务器
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
#启动容器,在容器内访问MySQL env LANG=C.UTF-8 避免容器中显示中文乱码
[root@localhost ~]# docker exec -it msb-mysql-master env LANG=C.UTF-8 /bin/bash
bash-4.4# mysql -uroot -p
Enter password: 输入密码
#修改默认密码校验方式
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';在主数据库上, 创建一个允许从数据库来访问的用户账号
用户:
msb_slave密码:
123456主从复制使用
REPLICATION SLAVE赋予权限
-- 创建slave用户
CREATE USER 'msb_slave'@'%';
-- 设置密码
ALTER USER 'msb_slave'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
-- 授予复制权限
GRANT REPLICATION SLAVE ON *.* TO 'msb_slave'@'%';
-- 刷新权限
FLUSH PRIVILEGES;主机中查询master状态
执行完此步骤后,不要再操作主服务器,防止主服务器状态值变化,可以选择锁住主服务器
-- 执行以下命令锁定数据库以防止写入数据。
FLUSH TABLES WITH READ LOCK;到主服务器上查看主机状态, 记录File和Position对应的值
-- 在主机查看mater状态
SHOW MASTER STATUS;
+---------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+---------------+----------+--------------+------------------+-------------------+
| binlog.000003 | 1092 | | | |
+---------------+----------+--------------+------------------+-------------------+
+---------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+---------------+----------+--------------+------------------+-------------------+
| binlog.000003 | 1345 | | | |
+---------------+----------+--------------+------------------+-------------------+5.1.3 从服务器搭建
我们可以选择配置多台从服务器,配置方式都是一样的。
在docker中创建并启动MySQL从服务器:名称
msb-mysql-slave1, 端口3307
docker run -d \
-p 3307:3306 \
-v /msb/mysql/slave1/conf:/etc/mysql/conf.d \
-v /msb/mysql/slave1/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
--name msb-mysql-slave1 \
mysql:8.0.29
docker run -d \
-p 3308:3306 \
-v /msb/mysql/slave2/conf:/etc/mysql/conf.d \
-v /msb/mysql/slave2/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
--name msb-mysql-slave2 \
mysql:8.0.29创建slave1的配置文件
vim /msb/mysql/slave1/conf/my.cnf
vim /msb/mysql/slave2/conf/my.cnf配置下面的内容
[mysqld]
# 服务器唯一id,每台服务器的id必须不同,如果配置其他从机,注意修改id
server-id=2
[mysqld]
server-id=3重启从服务器
docker restart msb-mysql-slave1
docker restart msb-mysql-slave2登录MySQL主服务器
[root@localhost ~]# docker exec -it msb-mysql-slave1 env LANG=C.UTF-8 /bin/bash
bash-4.4# mysql -uroot -p
Enter password: 输入密码
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
[root@localhost ~]# docker exec -it msb-mysql-slave2 env LANG=C.UTF-8 /bin/bash
bash-4.4# mysql -uroot -p
Enter password: 输入密码
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';在从机上配置主从关系
CHANGE MASTER TO MASTER_HOST='192.168.58.100',
MASTER_USER='msb_slave',MASTER_PASSWORD='123456', MASTER_PORT=3306,
MASTER_LOG_FILE='binlog.000003',MASTER_LOG_POS=1345; 启动从服务器,查看状态
START SLAVE;
-- 查看状态(不需要分号)
SHOW SLAVE STATUS\G5.1.4 主从同步测试
在主库创建数据库、表,插入数据,测试从库是否同步数据
-- 创建数据库
CREATE DATABASE user_db CHARACTER SET utf8;
-- 创建表
CREATE TABLE users (
id INT(11) PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20) DEFAULT NULL,
age INT(11) DEFAULT NULL
);
-- 插入数据
INSERT INTO users VALUES(NULL,'user1',20);
INSERT INTO users VALUES(NULL,'user2',21);
INSERT INTO users VALUES(NULL,'user3',22);5.1.5 停止和重置
需要的时候,可以使用如下SQL语句
-- 在从机上执行。功能说明:停止I/O 线程和SQL线程的操作。
stop slave;
-- 在从机上执行。功能说明:用于删除SLAVE数据库的relaylog日志文件,并重新启用新的relaylog文件。
reset slave;
-- 在主机上执行。功能说明:删除所有的binglog日志文件,并将日志索引文件清空,重新开始所有新的日志文件。
-- 用于第一次进行搭建主从库时,进行主库binlog初始化工作;
reset master;5.1.6 常见问题解决
启动主从同步后,常见错误是 Slave_IO_Running: No 或者 Connecting 的情况
 解决方案1:
解决方案1:
首先停掉Slave服务
-- 在从机停止slave
stop slave;到主服务器上查看主机状态, 记录File和Position对应的值
-- 在主机查看mater状态
SHOW MASTER STATUS;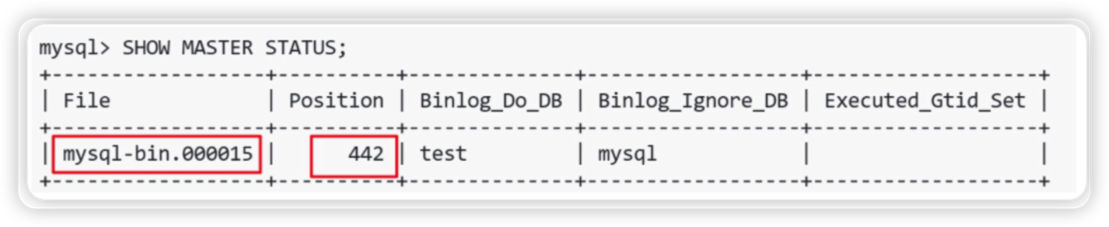
然后到slave服务器上执行手动同步:
-- MASTER_LOG_FILE和MASTER_LOG_POS与主库保持一致
CHANGE MASTER TO MASTER_HOST='192.168.58.100',
MASTER_USER='slave',
MASTER_PASSWORD='123456',
MASTER_PORT=3306,
MASTER_LOG_FILE='mysql-bin.000015',
MASTER_LOG_POS=442,
MASTER_CONNECT_RETRY=10;解决方案2
程序可能在slave上进行了写操作
也可能是slave机器重起后,事务回滚造成的.
一般是事务回滚造成的,解决办法
mysql> slave stop;
mysql> set GLOBAL SQL_SLAVE_SKIP_COUNTER=1;
mysql> slave start;5.2 Mycat2读写分离配置 (一主两从)
在⼀些⼤型⽹站业务场景中,单台数据库提供的并发量已经⽆法满⾜业务需求;为了提供数据库的并发能⼒和负载能⼒,⼀般通过读写分离来实现。
当我们的数据库实现读写分离的时候,在应⽤中需要对数据源进⾏切换, MyCat能够帮我们更好的实现数据源的动态切换,也就是应⽤程序只需要连接MyCat中间件,⾃动帮我们读取读写的数据库。
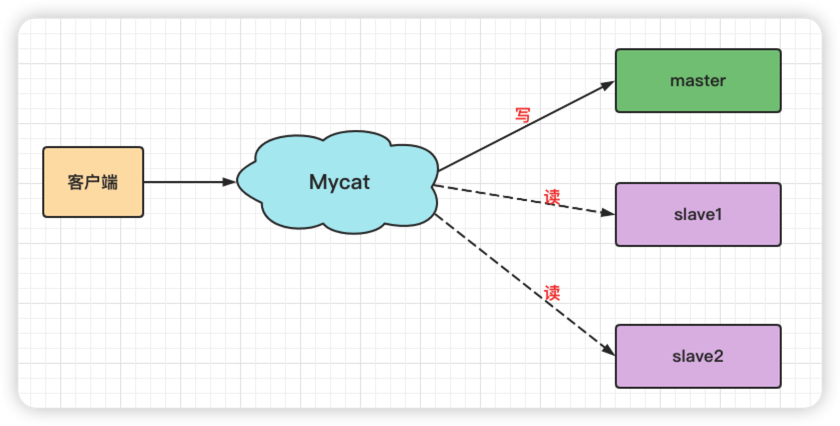
5.2.1 配置Mycat2原型库的数据源(database)信息
在主节点(主库)创建mycat数据库,供mycat内部使用,Mycat 在启动时,会自动在原型库下创建其运行时所需的数据表。
CREATE DATABASE mycat CHARACTER SET utf8;创建一个读写分离的测试库
CREATE DATABASE rw_db CHARACTER SET utf8;配置原型库的数据源信息prototypeDs.datasource.json
{
"dbType":"mysql",
"idleTimeout":60000,
"initSqls":[],
"initSqlsGetConnection":true,
"instanceType":"READ_WRITE",
"maxCon":1000,
"maxConnectTimeout":3000,
"maxRetryCount":5,
"minCon":1,
"name":"prototypeDs",
"password":"123456",
"type":"JDBC",
"url":"jdbc:mysql://192.168.58.100:3306/mycat?useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8",
"user":"root",
"weight":0
}5.2.2 配置 master和slave 数据库的数据源信息(一主两从)
首先将原型库配置文件拷贝两份,并修改名称
cp prototypeDs.datasource.json master.datasource.json
cp prototypeDs.datasource.json slave01.datasource.json
cp prototypeDs.datasource.json slave02.datasource.json配置主库
vim master.datasource.json{
"dbType":"mysql",
"idleTimeout":60000,
"initSqls":[],
"initSqlsGetConnection":true,
"instanceType":"READ_WRITE",
"maxCon":1000,
"maxConnectTimeout":3000,
"maxRetryCount":5,
"minCon":1,
"name":"master",
"password":"123456",
"type":"JDBC",
"url":"jdbc:mysql://192.168.58.100:3306/rw_db?useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8",
"user":"root",
"weight":0
}配置从库1
vim slave01.datasource.json{
"dbType":"mysql",
"idleTimeout":60000,
"initSqls":[],
"initSqlsGetConnection":true,
"instanceType":"READ",
"maxCon":1000,
"maxConnectTimeout":3000,
"maxRetryCount":5,
"minCon":1,
"name":"slave01",
"password":"123456",
"type":"JDBC",
"url":"jdbc:mysql://192.168.58.100:3307/rw_db?useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8",
"user":"root",
"weight":0
}配置从库2
vim slave02.datasource.json{
"dbType":"mysql",
"idleTimeout":60000,
"initSqls":[],
"initSqlsGetConnection":true,
"instanceType":"READ",
"maxCon":1000,
"maxConnectTimeout":3000,
"maxRetryCount":5,
"minCon":1,
"name":"slave02",
"password":"123456",
"type":"JDBC",
"url":"jdbc:mysql://192.168.58.100:3308/rw_db?useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8",
"user":"root",
"weight":0
}5.2.3 配置 master和slave 数据源的集群(cluster)信息
复制 master-slave.cluster.json
cp prototype.cluster.json master-slave.cluster.json注意:这里不要删除 prototype.cluster.json,否则启动 Mycat 时会报错
vim master-slave.cluster.json{
"clusterType":"MASTER_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetry":3,
"minSwitchTimeInterval":300,
"slaveThreshold":0
},
"masters":[
"master"
],
"replicas":[
"slave01",
"slave02"
],
"maxCon":200,
"name":"master-slave",
"readBalanceType":"BALANCE_ALL_READ",
"switchType":"NOT_SWITCH"
}
{
//集群类型:SINGLE_NODE(单节点)、MASTER_SLAVE(普通主从)、GARELA_CLUSTER(garela cluster/PXC集群)等
"clusterType":"MASTER_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetry":3,
"minSwitchTimeInterval":300,
"slaveThreshold":0
},
"masters":[
// 主节点数据源名称
"master"
],
"replicas":[
// 从节点数据源名称
"slave01",
"slave02"
],
"maxCon":200,
// 集群名称。在后面配置物理库(schema)时会用到
"name":"master-slave",
//查询负载均衡策略
"readBalanceType":"BALANCE_ALL_READ",
// NOT_SWITCH(不进行主从切换)、SWITCH(进行主从切换)
"switchType":"NO_SWITCH"
}参数说明
readBalanceType: 查询负载均衡策略
BALANCE_ALL(默认值): 获取集群中所有数据源
BALANCE_ALL_READ:获取集群中允许读的数据源
BALANCE_READ_WRITE:获取集群中允许读写的数据源,但允许读的数据源优先
BALANCE_NONE:获取集群中允许写数据源,即主节点中选择
switchType: 主从切换设置
NOT_SWITCH:不进行主从切换
SWITCH:进行主从切换5.2.4 配置物理库(schema)和 Mycat 中数据源/数据源集群的关系
cd /root/software/mycat/conf/schemas
vim master_slave.schema.json
{
"schemaName": "rw_db",
"targetName": "master-slave",
"normalTables": {}
}
{
// 物理库
"schemaName": "rw_db",
// 指向集群,或者数据源
"targetName": "master-slave",
// 这里可以配置数据表相关的信息,在物理表已存在或需要启动时自动创建物理表时配置此项
"normalTables": {}
}5.2.5 修改 Mycat 登录用户信息
vim root.user.json{
"dialect":"mysql",
"ip":null,
"password":"123456",
"transactionType":"xa",
"username":"root"
}5.2.6 测试一主两从-读写分离
Step1 :通过Navicat连接Mycat数据库
Step2 :执行建表语句
-- 创建表
CREATE TABLE products (
pid INT(11) PRIMARY KEY AUTO_INCREMENT,
pname VARCHAR(20) DEFAULT NULL
); Step3 :执行插入和查询语句语句
-- 插入数据
INSERT INTO products VALUES(NULL,'phone');
INSERT INTO products VALUES(NULL,'book');
INSERT INTO products VALUES(NULL,'gun');
-- 查询数据
select * from products;Step4 : 开启主从的日志
#日志输出到表中 对应的表是mysql.general_log
SET GLOBAL log_output = 'TABLE';
#打开general_log,重启后失效
SET GLOBAL general_log = 'ON';
SET GLOBAL general_log = 'OFF'; #关闭Step5 : 查询主从各自的日志信息
general log 通用日志: 会记录所有MySQL的SQL。
默认不开启,对性能有影响,只在排查错误时开启,使用完关闭。
SELECT event_time,
user_host,
thread_id,
server_id,
command_type,
CAST(argument AS CHAR(500) CHARACTER SET utf8mb4) argument
FROM mysql.general_log
ORDER BY event_time DESC;表字段含义。
event_time:查询日志记录到表的那一刻的log_timestamps系统变量值,用于标记查询日志记录何时入库。
user_host: 表示该查询日志记录的来源,其中有用户名和主机名信息。
thread_id:表示该查询日志记录执行时的process_id。
server_id:表示执行该查询的数据库实例ID。
command_type:表示该查询的command类型,通常都为query。
argument:表示执行查询的SQL语句文本。
5.3 Docker搭建MySQL主从复制集群 (双主双从)
5.3.1 双主双从架构介绍
虽然一主一从或一主多从集群解决了并发读的问题,但由于主节点只有一台,如果主节点宕机了,则数据库的写操作便无法完成,从而无法做到高可用。
因此,接下来我们来完成Mysql双主双从的集群搭建,双主双从的原理很简单,相当于有两个一主一从,然后两个主节点再互为主从,互相复制数据,然后借助MyCat的机制,先把一台主作为写库,另一台主和两台从作为读库,当作为写库的主宕机后,另一台主则作为写库提供服务,从而实现高可用。如下图所示

5.3.2 双主MySQL配置
1) 将之前搭建的MySQL集群拍摄快照, 然后删除。使用Docker命令,创建两个新的主机,分别是:
msb-mysql-master1
msb-mysql-master2
docker run -d \ -p 3310:3306 \ -v /msb/mysql/master1/conf:/etc/mysql/conf.d \ -v /msb/mysql/master1/data:/var/lib/mysql \ -e MYSQL_ROOT_PASSWORD=123456 \ --name msb-mysql-master1 \ mysql:8.0.29 docker run -d \ -p 3311:3306 \ -v /msb/mysql/master2/conf:/etc/mysql/conf.d \ -v /msb/mysql/master2/data:/var/lib/mysql \ -e MYSQL_ROOT_PASSWORD=123456 \ --name msb-mysql-master2 \ mysql:8.0.292) 配置Master1,修改配置文件
vim /msb/mysql/master1/conf/my.cnf[mysqld] #开启二进制日志 log-bin=mysql-bin #设置服务id server-id=1 # 设置不要复制的数据库 binlog-ignore-db=mysql binlog-ignore-db=performance_schema binlog-ignore-db=sys #设置需要复制的数据库 binlog-do-db=mydb #设置logbin格式;可选值:STATEMENT、ROW、MIXED binlog_format=STATEMENT # 作为从数据库的时候,有写入操作也要更新二进制日志文件 log-slave-updates # 自增长字段从哪个数开始 auto-increment-offset=1 # 自增长字段每次递增的量 auto-increment-increment=2MySQL 配置参数 -- logs-slave-updates
正常情况下,一个
slave节点是不会将其从master节点同步的数据更新操作记录至自己的二进制日志bin-log中的。在多主的场景下,各
master节点其实又相互作为另一方的slave节点进行着数据的一致性同步操作。例如masterA会以slave的角色同步masterB上的数据,masterB也会以slave的角色同步masterA上的数据,如果没有开启logs-slave-updates参数配置,则masterA\masterB虽然也能保证数据的一致性和完整性,但二者的bin-log中都只记录了作用在自身实例上的数据更新操作。
-- masterA 插入数据row1,并记录到binlog
masterA insert row1 bin-logA add row1
-- masterB 插入数据row2,并记录到binlog
masterB insert row2 bin-logB add row2
-- masterA 同步数据row2,但是没有记录到binlog
masterA replicate row2 from masterB But bin-logA will not log this update
-- masterB 同步数据row1,但是没有记录到binlog
masterB replicate row1 from masterA But bin-logB will not log this update
-- slaveA只能同步row1到binlog
slaveA replicate row1 form bin-logA
-- slaveB只能同步row2到binlog
slaveB replicate row2 form bin-logB因为主从复制是使用 bin-log 完成的,masterA masterB 互补同步数据时并没有将对方同步的数据写入自己的 bin-log,则会导致自己的从实例只能同步到集群的部分数据。
3) 配置Master2,修改配置文件 vim /msb/mysql/master2/conf/my.cnf
[mysqld]
#开启二进制日志
log-bin=mysql-bin
#设置服务id
server-id=2
# 设置不要复制的数据库
binlog-ignore-db=mysql
binlog-ignore-db=performance_schema
binlog-ignore-db=sys
#设置需要复制的数据库
binlog-do-db=mydb
#设置logbin格式;可选值:STATEMENT、ROW、MIXED
binlog_format=STATEMENT
# 作为从数据库的时候,有写入操作也要更新二进制日志文件
log-slave-updates
# 自增长字段从哪个数开始
auto-increment-offset=2
# 自增长字段每次递增的量
auto-increment-increment=25.3.3 双从MySQL配置
1) 使用Docker命令,创建两个新的从机,分别是:
msb-mysql-slave1
msb-mysql-slave2
docker run -d \
-p 3312:3306 \
-v /msb/mysql/slave1/conf:/etc/mysql/conf.d \
-v /msb/mysql/slave1/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
--name msb-mysql-slave1 \
mysql:8.0.29
docker run -d \
-p 3313:3306 \
-v /msb/mysql/slave2/conf:/etc/mysql/conf.d \
-v /msb/mysql/slave2/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
--name msb-mysql-slave2 \
mysql:8.0.292)配置slave1,修改配置文件 vim /msb/mysql/slave1/conf/my.cnf
[mysqld]
#开启二进制日志
log-bin=mysql-bin
#设置服务id
server-id=3
#启用中继日志
relay-log=mysql-relay3)配置slave2,修改配置文件 vim /msb/mysql/slave2/conf/my.cnf
[mysqld]
#开启二进制日志
log-bin=mysql-bin
#设置服务id
server-id=4
#启用中继日志
relay-log=mysql-relay5.3.4 重启双主、双从MySQL服务
docker restart msb-mysql-master1
docker restart msb-mysql-master2
docker restart msb-mysql-slave1
docker restart msb-mysql-slave25.3.5 创建授权账号
在Master1节点的MySQL上建立帐户并授权,用于登录主节点,进行数据同步复制
[root@localhost ~]# docker exec -it msb-mysql-master1 env LANG=C.UTF-8 /bin/bash
bash-4.4# mysql -uroot -p
Enter password: 输入密码
mysql> ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
# 授权主备复制专用账号
mysql> CREATE USER 'slave1'@'%' IDENTIFIED BY '123456';
mysql> GRANT REPLICATION SLAVE ON *.* TO 'slave1'@'%';
mysql> ALTER USER 'slave1'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
# 刷新权限
mysql> FLUSH PRIVILEGES;在Master2节点的MySQL上建立帐户并授权,用于登录主节点,进行数据同步复制
[root@localhost ~]# docker exec -it msb-mysql-master2 env LANG=C.UTF-8 /bin/bash
bash-4.4# mysql -uroot -p
Enter password: 输入密码
mysql> ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
# 授权主备复制专用账号
mysql> CREATE USER 'slave2'@'%' IDENTIFIED BY '123456';
mysql> GRANT REPLICATION SLAVE ON *.* TO 'slave2'@'%';
mysql> ALTER USER 'slave2'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
# 刷新权限
mysql> FLUSH PRIVILEGES;
查询Master1的状态:show master status;,记录下File和Position的值

mysql> show master status;
+------------------+----------+--------------+------------------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------------------+-------------------+
| mysql-bin.000001 | 157 | mydb | mysql,performance_schema,sys | |
+------------------+----------+--------------+------------------------------+-------------------+查询Master2的状态:show master status;,分别记录下File和Position的值

mysql> show master status;
+------------------+----------+--------------+------------------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------------------+-------------------+
| mysql-bin.000001 | 157 | mydb | mysql,performance_schema,sys | |
+------------------+----------+--------------+------------------------------+-------------------+
5.3.6 设置从库向主库同步/复制数据
操作slava1
[root@localhost ~]# docker exec -it msb-mysql-slave1 env LANG=C.UTF-8 /bin/bash
bash-4.4# mysql -uroot -p
Enter password: 输入密码
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
CHANGE MASTER TO MASTER_HOST='192.168.58.100',
MASTER_USER='slave1',
MASTER_PASSWORD='123456',
MASTER_PORT=3310,
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=1451; 操作slava2
[root@localhost ~]# docker exec -it msb-mysql-slave2 env LANG=C.UTF-8 /bin/bash
bash-4.4# mysql -uroot -p
Enter password: 输入密码
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
CHANGE MASTER TO MASTER_HOST='192.168.58.100',
MASTER_USER='slave2',
MASTER_PASSWORD='123456',
MASTER_PORT=3311,
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=1452; 分别启动两从MySQL服务的复制功能,查看服务器状态;Slave_IO_Runing和 Slave_SQL_Runing都为Yes说明同步成功
start slave;查看双从服务器状态
show slave status\G;slave1状态
slave2状态
出现异常:
ERROR 1872 (HY000): Slave failed to initialize relay log info structure from the repository
复制代码解决方案:
stop slave;
start slave;
or
reset slave;
start slave;5.3.7 配置双主互相复制
master1复制master2,master2复制Master1
操作master1
CHANGE MASTER TO MASTER_HOST='192.168.58.100',
MASTER_USER='slave2',
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=1452,
MASTER_PORT=3311;操作Master2
CHANGE MASTER TO MASTER_HOST='192.168.58.100',
MASTER_USER='slave1',
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=1451,
MASTER_PORT=3310;分别启动两主MySQL服务的复制功能,查看从服务器状态:Slave_IO_Runing和 Slave_SQL_Runing都为Yes说明同步成功
start slave;查看从服务器状态
show slave status;
show slave status\G;5.3.8 测试双主双从的同步复制
注意:在测试双主双从复制时,一定要确保每个节点MySQL的 Slave_IO_Runing和 Slave_SQL_Runing都为Yes。
在Master1节点新建库、新建表、插入数据
mysql> CREATE DATABASE mydb CHARACTER SET utf8;
Query OK, 1 row affected (0.01 sec)
mysql> use mydb;
Database changed
mysql> CREATE TABLE mytb(id INT,name VARCHAR(30));
Query OK, 0 rows affected (0.02 sec)
mysql> INSERT INTO mytb VALUES(1,'mycat');
Query OK, 1 row affected (0.01 sec)
mysql> select * from mytb;
+------+-------+
| id | name |
+------+-------+
| 1 | mycat |
+------+-------+
1 row in set (0.00 sec)在Master2和从机验证数据是否进行了复制
5.4 Mycat2读写分离配置 (双主两从)
5.4.1 配置Mycat2原型库的数据源(database)信息
在master1主节点创建mycat数据库,供mycat内部使用,Mycat 在启动时,会自动在原型库下创建其运行时所需的数据表。
CREATE DATABASE mycat CHARACTER SET utf8;配置原型库的数据源信息prototypeDs.datasource.json
{
"dbType":"mysql",
"idleTimeout":60000,
"initSqls":[],
"initSqlsGetConnection":true,
"instanceType":"READ_WRITE",
"maxCon":1000,
"maxConnectTimeout":3000,
"maxRetryCount":5,
"minCon":1,
"name":"prototypeDs",
"password":"123456",
"type":"JDBC",
"url":"jdbc:mysql://192.168.58.100:3310/mycat?useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8",
"user":"root",
"weight":0
}创建逻辑库
CREATE DATABASE mydb CHARACTER SET utf8;执行创建库语句后,将在 /mycat/conf/schemas/自动生成 mydb.schema.json文件
{
"customTables":{},
"globalTables":{},
"normalProcedures":{},
"normalTables":{},
"schemaName":"mydb",
"shardingTables":{},
"views":{}
}
customTables:mycat默认的表的配置
globalTables:全局表的配置
shardingTables:分片表的配置
normalTables:普通表的配置修改schema的配置,指定mydb逻辑库默认的targetName,mycat会自动加载mydb下已经有的物理表或者视图作为单表
{
"customTables":{},
"globalTables":{},
"normalProcedures":{},
"normalTables":{},
"schemaName":"mydb",
"targetName":"prototype"
"shardingTables":{},
"views":{}
}修改之后重启Mycat
[root@localhost bin]# ./mycat restart连接Mycat,然后进行查询
5.4.2 注解方式-配置 master和slave 数据库的数据源信息
添加Master1数据源
/*+ mycat:createDataSource{ "name":"write1","url":"jdbc:mysql://192.168.58.100:3310/mydb?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true", "user":"root","password":"123456" } */;添加Master2数据源
/*+ mycat:createDataSource{ "name":"write2","url":"jdbc:mysql://192.168.58.100:3311/mydb?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true", "user":"root","password":"123456" } */;添加Slave1数据源
/*+ mycat:createDataSource{ "name":"read1","url":"jdbc:mysql://192.168.58.100:3312/mydb?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true", "user":"root","password":"123456" } */;添加Slave2数据源
/*+ mycat:createDataSource{ "name":"read2","url":"jdbc:mysql://192.168.58.100:3313/mydb?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true", "user":"root","password":"123456" } */;查询配置数据源结果
/*+ mycat:showDataSources{} */;通过注释命名添加数据源后,在对应目录会生成相关配置文件,查看数据源配置文件:mycat/conf/datasources
[root@localhost conf]# cd datasources/
[root@localhost datasources]# ll
总用量 20
-rw-r--r--. 1 root root 422 12月 3 20:33 prototypeDs.datasource.json
-rw-r--r--. 1 root root 484 12月 3 20:56 read1.datasource.json
-rw-r--r--. 1 root root 484 12月 3 20:56 read2.datasource.json
-rw-r--r--. 1 root root 485 12月 3 20:53 write1.datasource.json
-rw-r--r--. 1 root root 485 12月 3 20:55 write2.datasource.json5.4.3 注解方式-配置 master和slave 数据源的集群(cluster)信息
使用mycat自带的默认集群:prototype,对其修改更新
/*! mycat:createCluster{"name":"prototype","masters":["write1","write2"],"replicas":["read1","read2","write2"]} */;查看配置集群信息
/*+ mycat:showClusters{} */;查看集群配置文件,发现集群配置信息已经更新
vim conf/clusters/prototype.cluster.json{
"clusterType":"MASTER_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetryCount":3,
"minSwitchTimeInterval":300,
"showLog":false,
"slaveThreshold":0.0
},
"masters":[
"write1",
"write2"
],
"maxCon":2000,
"name":"prototype",
"readBalanceType":"BALANCE_ALL",
"replicas":[
"read1",
"read2",
"write2"
],
"switchType":"SWITCH"
}5.4.4 读写分离测试
修改MySQL的配置文件:
my.cnf,设置logbin格式binlog_format=STATEMENT,重启MySQL,确保此时主从复制正常
binlog_format=STATEMENT:记录每一条 sql 语句,日志记录的是主机数据库的
写指令,性能高,但是now()之类的函数以及获取系统参数的操作会出现主从数据不同步的问题。
登录MyCat,向数据表插入
系统变量值,以此造成主从数据不一致,便于验证读写分离。
INSERT INTO mytb VALUES(2,@@hostname);登录双主双从MySQL4个库查看表数据
SELECT * FROM mytb;在Mycat里查询mytb表,可以看到查询语句在主从两个主机间切换
mysql> select * from mytb;
+----+--------------+
| id | name |
+----+--------------+
| 1 | mycat |
| 2 | 7d7d92ddd51e |
+----+--------------+
2 rows in set (0.04 sec)
mysql> select * from mytb;
+----+--------------+
| id | name |
+----+--------------+
| 1 | mycat |
| 2 | f1cc8223fc73 |
+----+--------------+
2 rows in set (0.04 sec)
mysql> select * from mytb;
+----+--------------+
| id | name |
+----+--------------+
| 1 | mycat |
| 2 | 7d7d92ddd51e |
+----+--------------+
2 rows in set (0.04 sec)
mysql> select * from mytb;
+----+--------------+
| id | name |
+----+--------------+
| 1 | mycat |
| 2 | f1cc8223fc73 |
+----+--------------+
2 rows in set (0.01 sec)
mysql> select * from mytb;
+----+--------------+
| id | name |
+----+--------------+
| 1 | mycat |
| 2 | 7d7d92ddd51e |
+----+--------------+
2 rows in set (0.01 sec)
mysql> select * from mytb;
+----+--------------+
| id | name |
+----+--------------+
| 1 | mycat |
| 2 | 83526eafc910 |
+----+--------------+
2 rows in set (0.01 sec)
6.MyCat2 实现分库分表
6.1 分库分表概念回顾
6.1.1 分库操作
水平分库:把同一个表的数据按一定规则拆到不同的数据库中
垂直分库:按照业务、功能模块将表进行分类,不同功能模块对应的表分到不同的库中
分库原则:将紧密关联关系的表划分在一个库里,没有关联关系的表可以分到不同的库里
6.1.2 分表操作
水平分表:在同一个数据库内,把同一个表的数据按一定规则拆到多个表中
垂直分表:将一个表按照字段分成多表,每个表存储其中一部分字段
分表原则:减少节点数据库的访问,分表字段尤为重要,其决定了节点数据库的访问量。
6.2 分库分表环境准备
6.2.1 修改MyCat集群配置
只保留一主一从
cd /root/software/mycat/conf/clusters
vim prototype.cluster.json
{
"clusterType":"MASTER_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetryCount":3,
"minSwitchTimeInterval":300,
"showLog":false,
"slaveThreshold":0.0
},
"masters":[
"write1"
],
"maxCon":2000,
"name":"prototype",
"readBalanceType":"BALANCE_ALL",
"replicas":[
"read1"
],
"switchType":"SWITCH"
}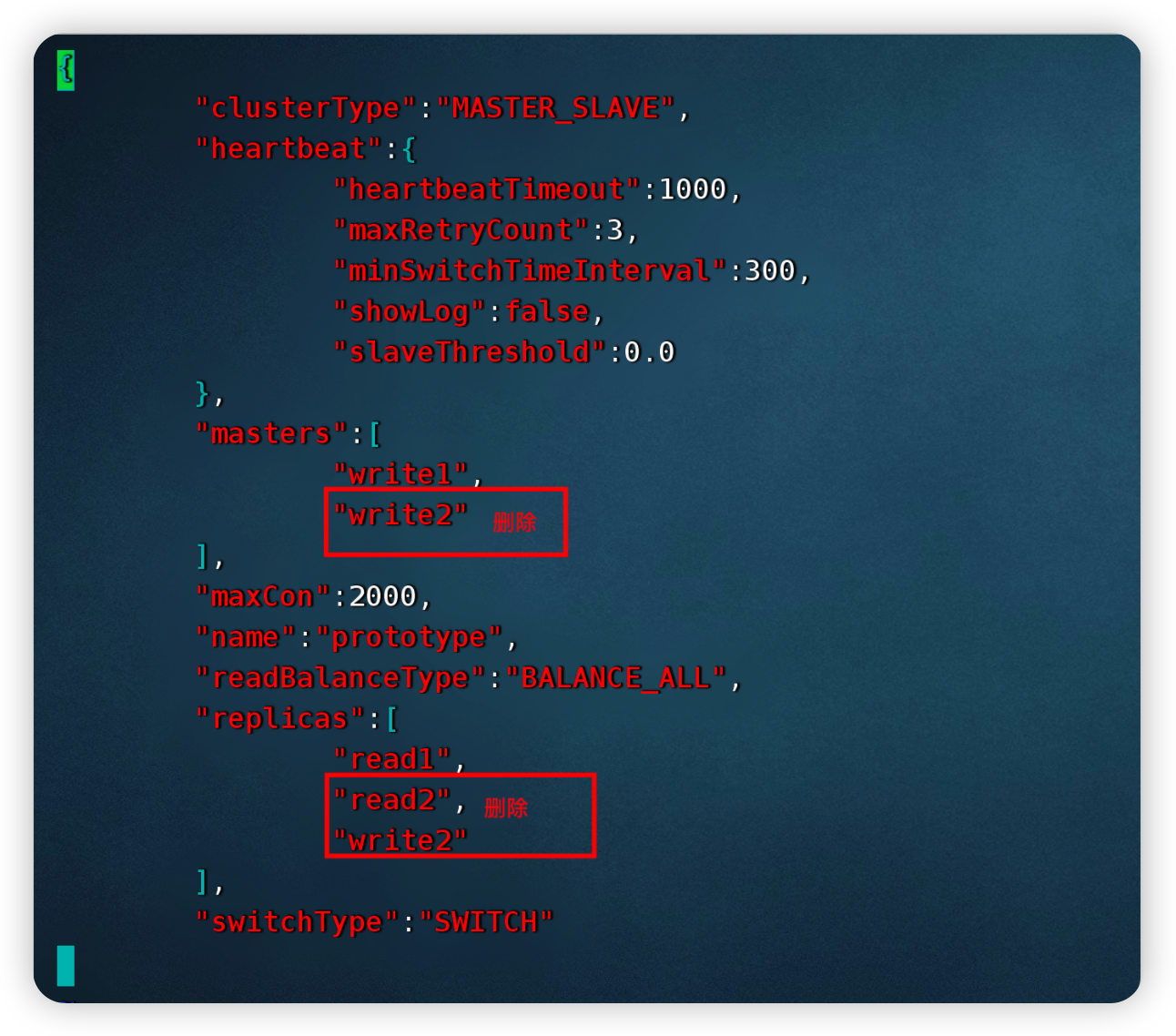
将多余的数据源删除(修改后缀名即可)
cd /root/software/mycat/conf/datasources
mv read2.datasource.json read2.datasource.json_bak
mv write2.datasource.json write2.datasource.json_bak
6.2.2 添加数据源
端口3310的MySQL,同时作为写数据源和读数据源
/*+ mycat:createDataSource{
"name":"db0_w",
"url":"jdbc:mysql://192.168.58.100:3310/mydb?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true",
"user":"root",
"password":"123456" } */;
/*+ mycat:createDataSource{
"name":"db0_r",
"url":"jdbc:mysql://192.168.58.100:3310/mydb?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true",
"user":"root",
"password":"123456" } */;端口3312的MySQL,同时作为写数据源和读数据源
/*+ mycat:createDataSource{
"name":"db1_w",
"url":"jdbc:mysql://192.168.58.100:3312/mydb?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true",
"user":"root",
"password":"123456" } */;
/*+ mycat:createDataSource{
"name":"db1_r",
"url":"jdbc:mysql://192.168.58.100:3312/mydb?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true",
"user":"root",
"password":"123456" } */;查看数据源配置结果
/*+ mycat:showDataSources{} */;通过注释命名添加数据源后,在对应目录会生成相关配置文件,查看数据源配置文件:mycat/conf/datasources
6.2.2 添加集群配置
接下来我们将新添加的数据源配置成集群
注意: HASH型分片算法默认要求集群名字以
c为前缀数字为后缀,c0就是分片表第一个节点,c1就是第二个节点,以此类推。
添加集群节点:c0
/*! mycat:createCluster{"name":"c0","masters":["db0_w"],"replicas":["db0_r"]} */;添加集群节点:c1
/*! mycat:createCluster{"name":"c1","masters":["db1_w"],"replicas":["db1_r"]} */;查看集群配置信息
/*+ mycat:showClusters{} */;
查看集群配置文件
查看集群:c0
{
"clusterType":"MASTER_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetryCount":3,
"minSwitchTimeInterval":300,
"showLog":false,
"slaveThreshold":0.0
},
"masters":[
"db0_w"
],
"maxCon":2000,
"name":"c0",
"readBalanceType":"BALANCE_ALL",
"replicas":[
"db0_r"
],
"switchType":"SWITCH"
}查看集群:c1
{
"clusterType":"MASTER_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetryCount":3,
"minSwitchTimeInterval":300,
"showLog":false,
"slaveThreshold":0.0
},
"masters":[
"db1_w"
],
"maxCon":2000,
"name":"c1",
"readBalanceType":"BALANCE_ALL",
"replicas":[
"db1_r"
],
"switchType":"SWITCH"
}6.3 进行分库分表
6.3.1 实现数据分片
登录Mycat,运行建表语句进行数据分片
CREATE TABLE msb_user (
id BIGINT primary key AUTO_INCREMENT,
username VARCHAR(30) DEFAULT NULL,
age INT,
type INT
) ENGINE = INNODB DEFAULT CHARSET = utf8
dbpartition BY mod_hash(type)
tbpartition BY mod_hash( id )
tbpartitions 1
dbpartitions 2 ;dbpartition:数据库分片规则
tbpartition :表分片规则
mod_hash :分片规则
tbpartitions 1 dbpartitions 2:创建2个库且每个库各创建1个分片表
插入数据
INSERT INTO mydb.msb_user(id,username,age,type)VALUES(1,'mycat1',15,1);
INSERT INTO mydb.msb_user(id,username,age,type)VALUES(2,'mycat2',20,2);
INSERT INTO mydb.msb_user(id,username,age,type)VALUES(3,'mycat3',15,1);
INSERT INTO mydb.msb_user(id,username,age,type)VALUES(4,'mycat4',20,2);6.3.2 分片算法 mod_hash说明
当分库键和分表键是不同键:
分表下标= 分片值%分表数量
分库下标= 分片值%分库数量当分库键和分表键是同一个键:
分表下标=分片值%(分库数量*分表数量)
分库下标=分表下标/分表数量我们使用 mod_hash分片规则,分库键和分表键是不同键,所以
分表下标:
1%1=0;2%1=0;3%1=0;4%1=0;分库下标:
1%2=1; 2%2=0;
查看schema:/mycat/conf/schemas/mydb.schema.json,生成配置信息如下
{
"customTables":{},
"globalTables":{},
"normalProcedures":{},
"normalTables":{
"mytb":{
"createTableSQL":"CREATE TABLE mydb.mytb (\n\t`id` int DEFAULT NULL,\n\t`name` varchar(30) DEFAULT NULL\n) ENGINE = InnoDB CHARSET = utf8mb3",
"locality":{
"schemaName":"mydb",
"tableName":"mytb",
"targetName":"prototype"
}
}
},
"schemaName":"mydb",
"shardingTables":{
"msb_user":{
"createTableSQL":"CREATE TABLE mydb.msb_user (\n\tid BIGINT PRIMARY KEY AUTO_INCREMENT,\n\tusername VARCHAR(30) DEFAULT NULL,\n\tage INT,\n\ttype INT\n) ENGINE = INNODB CHARSET = utf8\nDBPARTITION BY mod_hash(type) DBPARTITIONS 2\nTBPARTITION BY mod_hash(id) TBPARTITIONS 1",
"function":{
"properties":{
"dbNum":"2",
"mappingFormat":"c${targetIndex}/mydb_${dbIndex}/msb_user_${tableIndex}",
"tableNum":"1",
"tableMethod":"mod_hash(id)",
"storeNum":2,
"dbMethod":"mod_hash(type)"
}
},
"shardingIndexTables":{}
}
},
"targetName":"prototype",
"views":{}
}6.3.3 查看分片节点数据
登录master1
[root@localhost ~]# docker exec -it msb-mysql-master1 env LANG=C.UTF-8 /bin/bash
bash-4.4# mysql -uroot -p
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mycat |
| mydb |
| mydb_0 |
| mysql |
| performance_schema |
| sys |
+--------------------+
7 rows in set (0.01 sec)
mysql> use mydb_0;
mysql> show tables;
+------------------+
| Tables_in_mydb_0 |
+------------------+
| msb_user_0 |
+------------------+
1 row in set (0.01 sec)
mysql> select * from msb_user_0;
+----+----------+------+------+
| id | username | age | type |
+----+----------+------+------+
| 2 | mycat2 | 20 | 2 |
| 4 | mycat4 | 20 | 2 |
+----+----------+------+------+
2 rows in set (0.00 sec)
登录slave1
[root@localhost ~]# docker exec -it msb-mysql-slave1 env LANG=C.UTF-8 /bin/bash
bash-4.4# mysql -uroot -p
Enter password:
mysql> use mydb_1;
mysql> select * from msb_user_0;
+----+----------+------+------+
| id | username | age | type |
+----+----------+------+------+
| 1 | mycat1 | 15 | 1 |
| 3 | mycat3 | 15 | 1 |
+----+----------+------+------+
2 rows in set (0.00 sec)6.3.4 实现ER表
ER表回顾
Mycat提出了基于 E-R 关系的数据分片策略,子表的记录与所关联的父表记录存放在同一个数据分片上,即子表依赖于父表,通过表分组(Table Group)保证数据 join 不会跨库操作。
表分组(Table Group)是解决跨分片数据 join 的一种很好的思路,也是数据切分规划的重要一条规则。
mycat2无需指定ER表,是自动识别的,具体看分片算法的接口
登录Mycat,创建ER表
CREATE TABLE msb_user_wx (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
nickname VARCHAR(30) DEFAULT NULL,
user_id INT
) ENGINE = INNODB DEFAULT CHARSET = utf8
dbpartition BY mod_hash(id)
tbpartition BY mod_hash(user_id)
tbpartitions 1
dbpartitions 2;插入数据
INSERT INTO msb_user_wx(id,nickname,user_id) VALUES(1,'幸福生活',1);
INSERT INTO msb_user_wx(id,nickname,user_id) VALUES(2,'风和日丽',2);
INSERT INTO msb_user_wx(id,nickname,user_id) VALUES(3,'雄鹰展翅',3);
INSERT INTO msb_user_wx(id,nickname,user_id) VALUES(4,'出水芙蓉',4);登录master1
mysql> select * from msb_user_wx_0 ;
+----+--------------+---------+
| id | nickname | user_id |
+----+--------------+---------+
| 2 | 风和日丽 | 2 |
| 4 | 出水芙蓉 | 4 |
+----+--------------+---------+
2 rows in set (0.00 sec)登录slave1
mysql> select * from msb_user_wx_0 ;
+----+--------------+---------+
| id | nickname | user_id |
+----+--------------+---------+
| 1 | 幸福生活 | 1 |
| 3 | 雄鹰展翅 | 3 |
+----+--------------+---------+
2 rows in set (0.00 sec)查看配置的表是否具有ER关系,使用 /*+ mycat:showErGroup{}*/查看
group_id表示相同的组,该组中的表具有相同的存储分布,即可以关联查询
/*+ mycat:showErGroup{}*/;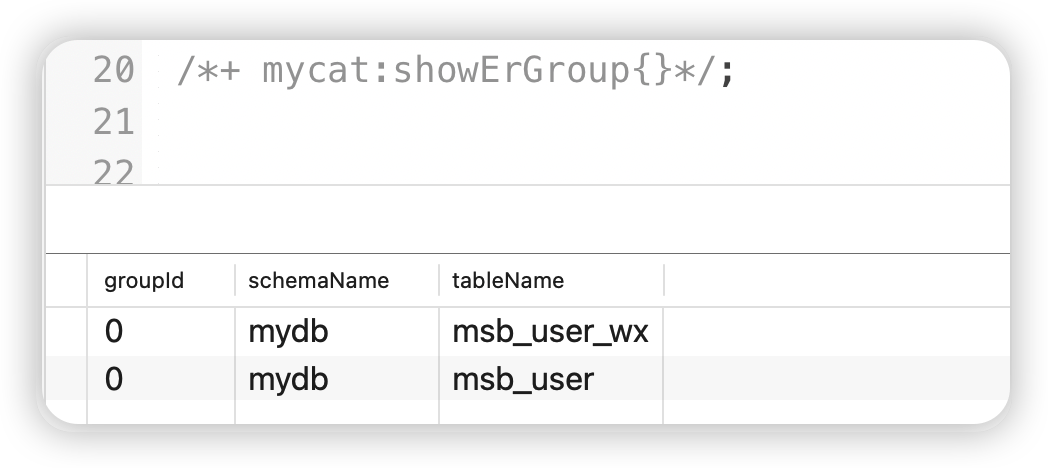 关联查询
关联查询
SELECT * FROM msb_user mu INNER JOIN msb_user_wx muw ON mu.id=muw.user_id;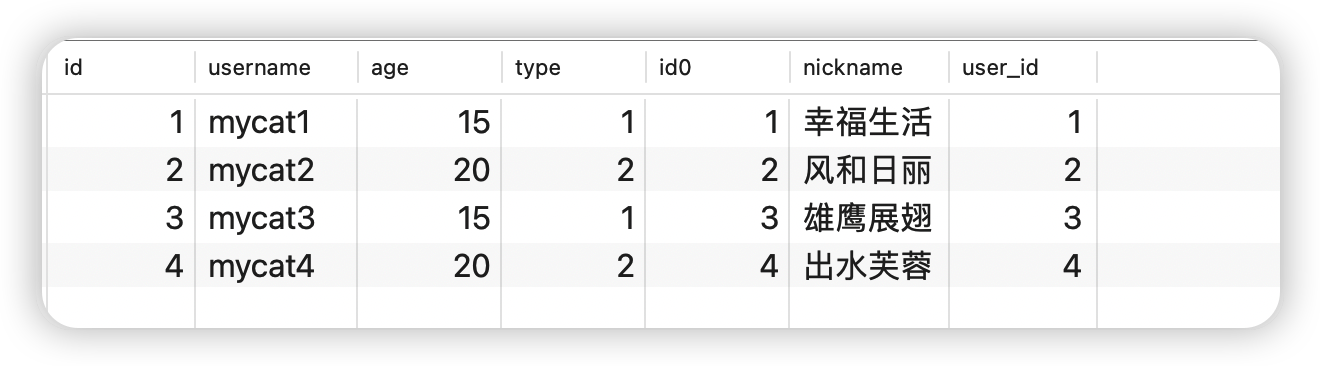
6.3.5 实现广播表
全局表(广播表)回顾:
一个真实的业务系统中,往往存在大量的类似字典表的表,这些表基本上很少变动,字典表具有以下几个特 性:
变动不频繁;
数据量总体变化不大;
数据规模不大,很少有超过数十万条记录。
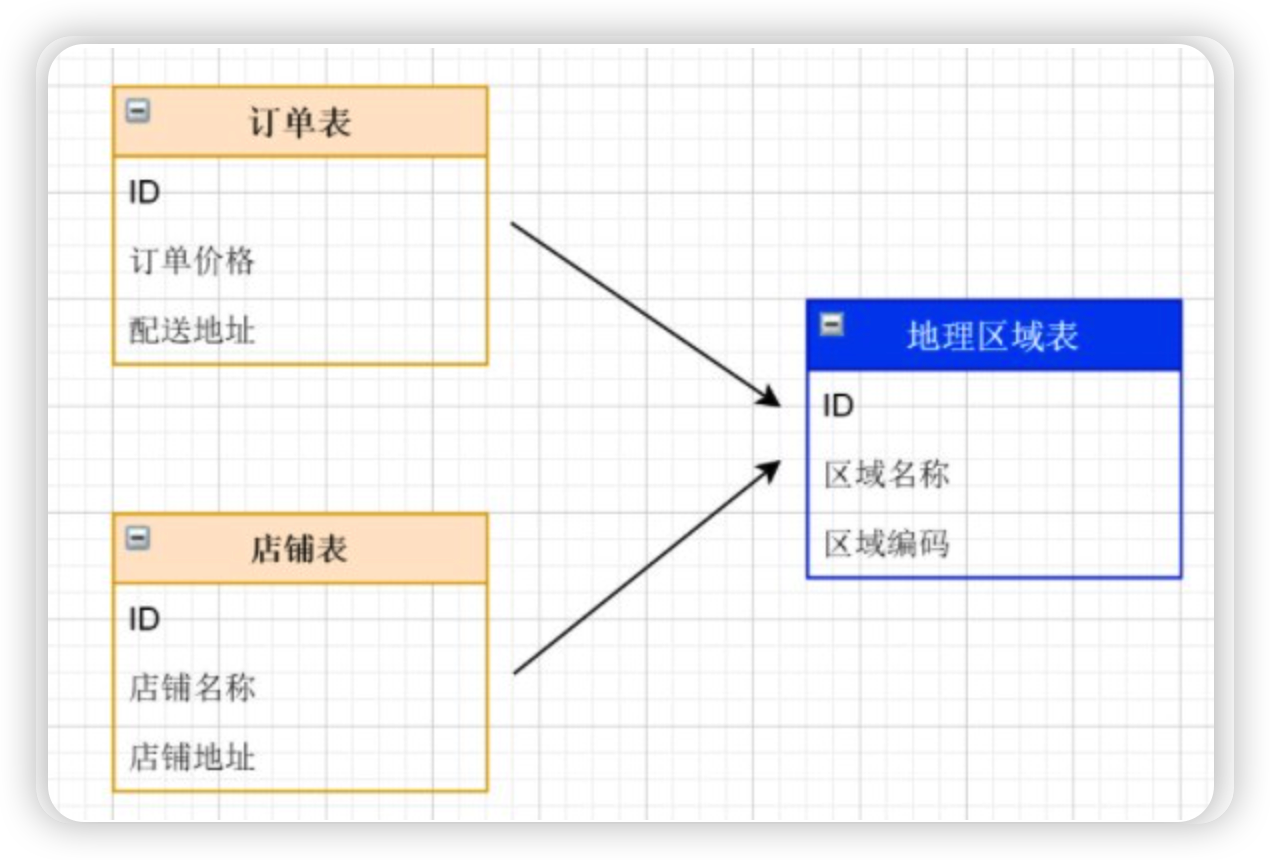
添加数据库msb_db
-- 在MyCat中创建逻辑库msb_db
CREATE DATABASE msb_db character set utf8;创建广播表
-- 创建区域表
CREATE TABLE t_district (
id BIGINT(20) PRIMARY KEY COMMENT '区域ID',
district_name VARCHAR(100) COMMENT '区域名称',
LEVEL INT COMMENT '等级'
)ENGINE=InnoDB DEFAULT CHARSET=utf8 BROADCAST;查看schema配置,自动生成广播表配置信息
{
"customTables":{},
"globalTables":{
"t_district":{
"broadcast":[
{
"targetName":"c0" #广播表对应数据源
},
{
"targetName":"c1"
}
],
"createTableSQL":"CREATE TABLE msb_db.t_district (\n\tid BIGINT(20) PRIMARY KEY COMMENT '区域ID',\n\tdistrict_name VARCHAR(100) COMMENT '区域名称',\n\tLEVEL INT COMMENT '等级'\n) BROADCAST ENGINE = InnoDB CHARSET = utf8"
}
},
"normalProcedures":{},
"normalTables":{},
"schemaName":"msb_db",
"shardingTables":{},
"views":{}
}查看master1
mysql> use msb_db;
Database changed
mysql> show tables;
+------------------+
| Tables_in_msb_db |
+------------------+
| t_district |
+------------------+
1 row in set (0.00 sec)查看slave1
mysql> use msb_db;
Database changed
mysql> show tables;
+------------------+
| Tables_in_msb_db |
+------------------+
| t_district |
+------------------+
1 row in set (0.00 sec)测试广播表,在MyCat中插入数据,然后分区去对应的广播表查看是否插入成功
insert into t_district values(2,'海淀区',1);6.4 常用的分片规则
6.4.1 分片算法介绍
Mycat2支持常用的(自动)HASH型分片算法也兼容1.6的内置的(cobar)分片算法. HASH型分片算法默认要求集群名字以c为前缀,数字为后缀, c0就是分片表第一个节点, c1就是第二个节点.该命名规则允许用户手动改变。
分片规则与适用性
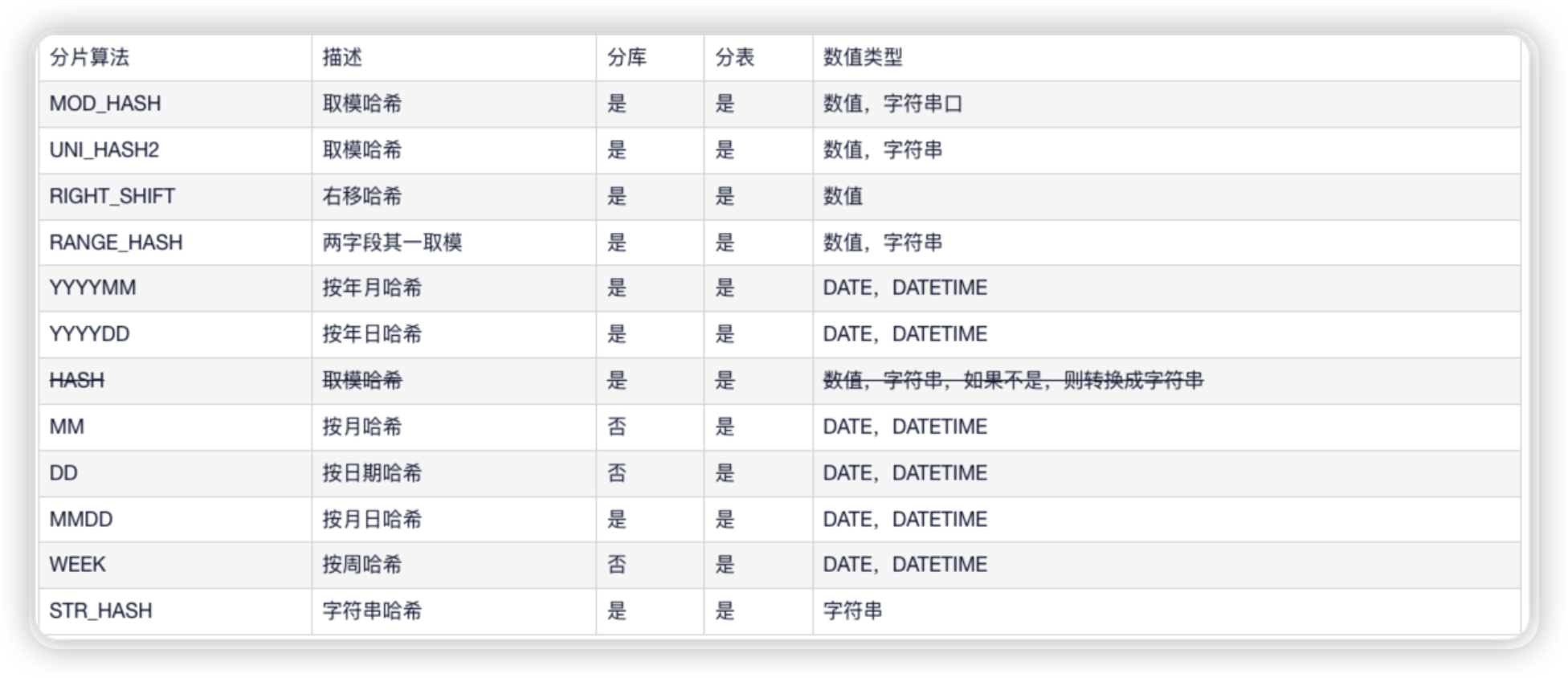
6.4.2 常用分片规则介绍
详细请参考
https://www.yuque.com/ccazhw/ml3nkf/394ccdc29b3813709d41992a0a4e035b?
1.MOD_HASH
如果分片值是字符串则先对字符串进行hash转换为数值类型
1.分库键和分表键是同1个键
分表下标=分片值%(分库数量*分表数量)
分库下标=分表下标/分表数量2.分库键和分表键是不同键
分表下标= 分片值%分表数量
分库下标= 分片值%分库数量
复制代码
create table travelrecord (
....
) ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by MOD_HASH (id) dbpartitions 6
tbpartition by MOD_HASH (id) tbpartitions 6;2.RIGHT_SHIFT
RANGE_HASH(字段1, 字段2, 截取开始下标)仅支持数值类型,字符串类型,分片值右移二进制位数,然后按分片数量取余
当字符串类型时候,第三个参数生效,根据下标截取其后部分字符串(截取下标不能少于实际值的长度),然后该字符串hash成数值
两个字段的数值类型要求一致
create table travelrecord(
...
)ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by RANGE_HASH(id,user_id,3) dbpartitions 3
tbpartition by RANGE_HASH(id,user_id,3) tbpartitions 3;3.RIGHT_SHIFT
RIGHT_SHIFT(字段名,位移数)
仅支持数值类型
分片值右移二进制位数,然后按分片数量取余
create table travelrecord(
...
)ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by RIGHT_SHIFT(id,4) dbpartitions 3
tbpartition by RIGHT_SHIFT(user_id,4) tbpartitions 3;4.YYYYDD (YYYY*366+DD)%分库数
仅用于分库,DD是一年之中的天数
create table travelrecord (
....
) ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by YYYYMM(xxx) dbpartitions 8
tbpartition by xxx(xxx) tbpartitions 12;5.YYYYMM (YYYY*12+MM)%分库数
仅用于分库,MM是1-12
create table travelrecord (
....
) ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by YYYYMM(xxx) dbpartitions 8
tbpartition by xxx(xx) tbpartitions 12;6.MMDD
仅用于分表,仅DATE/DATETIME适用
一年之中第几天%分表数,tbpartitions 不超过 366
create table travelrecord (
....
) ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by xxx(xx) dbpartitions 8
tbpartition by MMDD(xx) tbpartitions 366;